决策树
我们将学习一种更流行的机器学习算法——决策树,我们将使用此算法从患者的历史数据以及他们对不同药物的反应大数据中,用训练过的决策树来构建分类模型预测未知患者的类别,或者说为新患者找到合适的药物。
导入以下包
- numpy (as np)
- pandas
- DecisionTreeClassifier from sklearn.tree
import sys
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import sklearn.tree as tree
数据集的说明
假设你是一名医学研究院,收集了一组患有相同疾病患者的数据。在这些患者的治疗过程中,每位患者会对5种药物种的一种做出反应:A、B、C、X、Y。
你的一部分工作是建立一个模型,找出那种药物可能适合未来患有相同疾病的患者。这个数据集的几个指标(特征)是患者的年龄、性别、血压和胆固醇,标签是每个患者反应的药物。
这个数据是一个多分类器的样本,我们用训练集来构建决策树,然后用它来预测未知患者的类别,也就是为患者开药。
下载数据
点我下载
读取数据
my_data = pd.read_csv("drug200.csv", delimiter=",")
my_data[0:5]
|
Age |
Sex |
BP |
Cholesterol |
Na_to_K |
Drug |
| 0 |
23 |
F |
HIGH |
HIGH |
25.355 |
drugY |
| 1 |
47 |
M |
LOW |
HIGH |
13.093 |
drugC |
| 2 |
47 |
M |
LOW |
HIGH |
10.114 |
drugC |
| 3 |
28 |
F |
NORMAL |
HIGH |
7.798 |
drugX |
| 4 |
61 |
F |
LOW |
HIGH |
18.043 |
drugY |
数据的大小
my_data.shape
(200, 6)
数据预处理
用 my_data 作为 Drug.csv 的数据,声明以下变量:
- X 是 特征矩阵(Feature Matrix)
- y 是 响应向量(response vector)
把目标列的名称给删了。
X = my_data[['Age', 'Sex', 'BP', 'Cholesterol', 'Na_to_K']].values
X[0:5]
array([[23, 'F', 'HIGH', 'HIGH', 25.355],
[47, 'M', 'LOW', 'HIGH', 13.093],
[47, 'M', 'LOW', 'HIGH', 10.113999999999999],
[28, 'F', 'NORMAL', 'HIGH', 7.797999999999999],
[61, 'F', 'LOW', 'HIGH', 18.043]], dtype=object)
你可能会发现,此数据集中的某些特征是分类的,例如 Sex 或 BP。 不幸的是,Sklearn 决策树不处理分类变量。 我们仍然可以使用 pandas.get_dummies() 将这些特征转换为数值
将分类变量转换为虚拟/指标变量。
from sklearn import preprocessing
le_sex = preprocessing.LabelEncoder()
le_sex.fit(['F','M'])
X[:,1] = le_sex.transform(X[:,1])
le_BP = preprocessing.LabelEncoder()
le_BP.fit([ 'LOW', 'NORMAL', 'HIGH'])
X[:,2] = le_BP.transform(X[:,2])
le_Chol = preprocessing.LabelEncoder()
le_Chol.fit([ 'NORMAL', 'HIGH'])
X[:,3] = le_Chol.transform(X[:,3])
X[0:5]
array([[23, 0, 0, 0, 25.355],
[47, 1, 1, 0, 13.093],
[47, 1, 1, 0, 10.113999999999999],
[28, 0, 2, 0, 7.797999999999999],
[61, 0, 1, 0, 18.043]], dtype=object)
把因变量给提出来
y = my_data["Drug"]
y[0:5]
0 drugY
1 drugC
2 drugC
3 drugX
4 drugY
Name: Drug, dtype: object
构建决策树
让我们从 sklearn.cross_validation 导入train_test_split,来拆分训练集和测试集。
from sklearn.model_selection import train_test_split
train_test_split 将返回 4 个不同的参数。 我们将它们命名为:
X_trainset, X_testset, y_trainset, y_testset
train_test_split 需要以下参数:
X, y, test_size=0.3, and random_state=3.
X 和 y 是拆分前需要的数组,test_size 表示测试数据集的比例,random_state 确保我们获得相同的拆分。
X_trainset, X_testset, y_trainset, y_testset = train_test_split(X, y, test_size=0.3, random_state=3)
打印训练集和测试集的大小。 确保大小匹配。
print('Shape of X training set {}'.format(X_trainset.shape),'&',' Size of Y training set {}'.format(y_trainset.shape))
Shape of X training set (140, 5) & Size of Y training set (140,)
print('Shape of X training set {}'.format(X_testset.shape),'&',' Size of Y training set {}'.format(y_testset.shape))
Shape of X training set (60, 5) & Size of Y training set (60,)
构建模型
我们将首先创建一个
DecisionTreeClassifier的实例,称为
drugTree.
在分类器内部,指定
criterion="entropy" ,这样我们就可以看到每个节点的信息增益。
drugTree = DecisionTreeClassifier(criterion="entropy", max_depth = 4)
drugTree # it shows the default parameters
DecisionTreeClassifier(criterion='entropy', max_depth=4)
接下来,我们将使用训练特征矩阵 X_trainset 和训练响应向量 y_trainset 对数据进行拟合
drugTree.fit(X_trainset,y_trainset)
DecisionTreeClassifier(criterion='entropy', max_depth=4)
预测表
让我们在测试数据集中做一些
预测,并将其存储到一个名为
predTree的变量中。
predTree = drugTree.predict(X_testset)
如果希望直观地比较预测与实际值,可以打印出predTree和y_testset。
print (predTree [0:5])
print (y_testset [0:5])
['drugY' 'drugX' 'drugX' 'drugX' 'drugX']
40 drugY
51 drugX
139 drugX
197 drugX
170 drugX
Name: Drug, dtype: object
评估
接下来,让我们从sklearn导入
metrics,并检查我们的模型的准确性。
from sklearn import metrics
import matplotlib.pyplot as plt
print("DecisionTrees's Accuracy: ", metrics.accuracy_score(y_testset, predTree))
DecisionTrees's Accuracy: 0.9833333333333333
准确率分类分数计算子集的准确率:为一个样本预测的标签集必须精确匹配y_true中对应的标签集。
在多标签分类中,函数返回子集精度。 如果样本的整个预测标签集与真实标签集严格匹配,则子集精度为1.0; 否则为0.0。
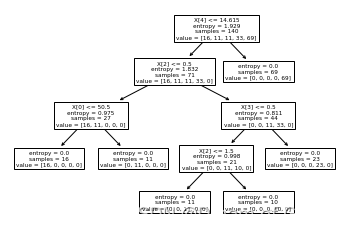
可视化
让我们来可视化这棵树
# Notice: You might need to uncomment and install the pydotplus and graphviz libraries if you have not installed these before
#!conda install -c conda-forge pydotplus -y
#!conda install -c conda-forge python-graphviz -y
tree.plot_tree(drugTree)
plt.show()