决策树
引言
决策树是什么?怎样利用决策树来帮助我们分类?怎样构建自己的决策树?
决策树是一种类似流程图的结构,其中每个内部节点代表一个属性的“测试”(例如硬币翻转出现正面朝上或反面朝上),每个分支代表测试的结果,每个叶节点代表一个类标签(在计算所有属性后做出的决策)。从根到叶的路径代表分类规则。
以例说法
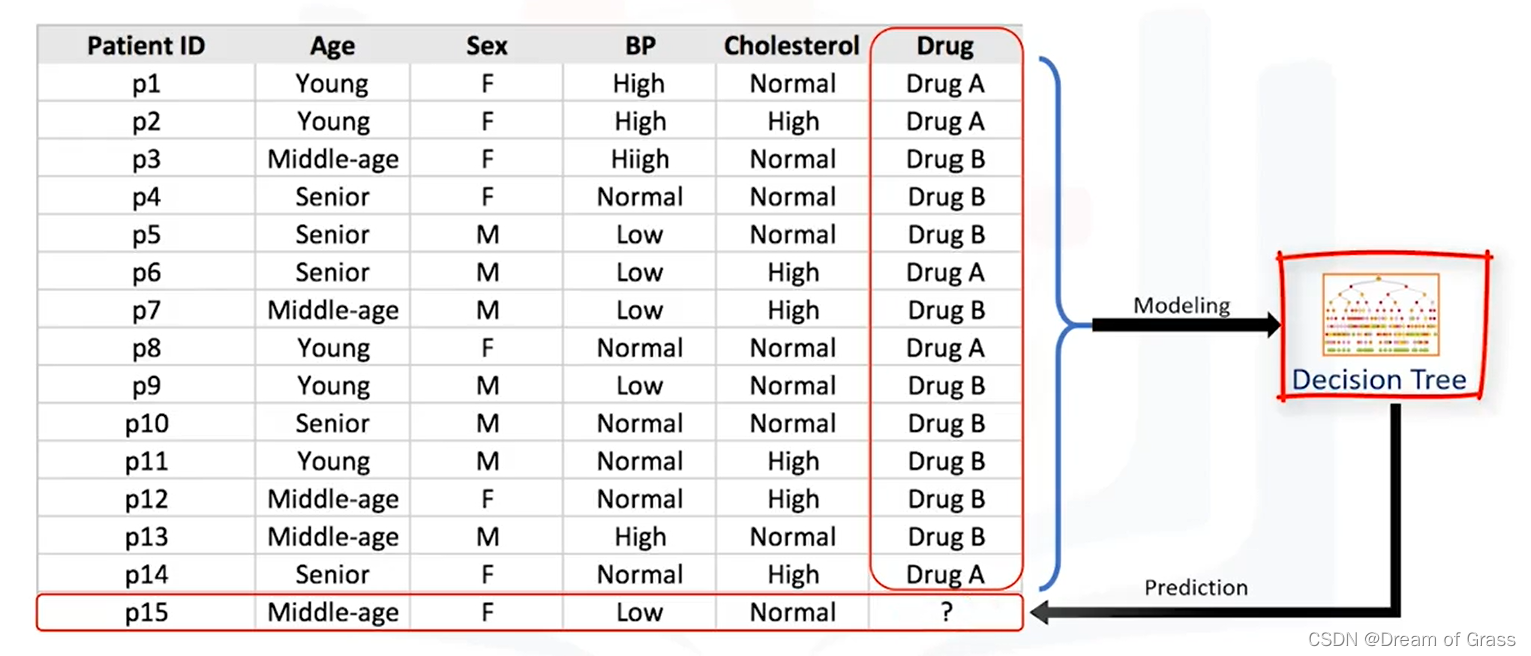
想象一下,您是一名医学研究人员,正在为一项研究编制数据。您已经收集了一组患有相同疾病的患者的数据。在治疗过程中,每位患者对两种药物中的一种都有反应。我们称它们为药物 A 和药物 B。您的部分工作是建立一个模型,以找出哪种药物可能适合未来患有相同疾病的患者。该数据集的特征集是我们患者组的年龄、性别、血压和胆固醇,目标是每个患者反应的药物。它是一个二元分类器的样本,您可以使用数据集的训练部分来构建决策树,然后使用它来预测未知患者的类别。从本质上讲,就是要决定给新病人开哪种药。
决策树的结构
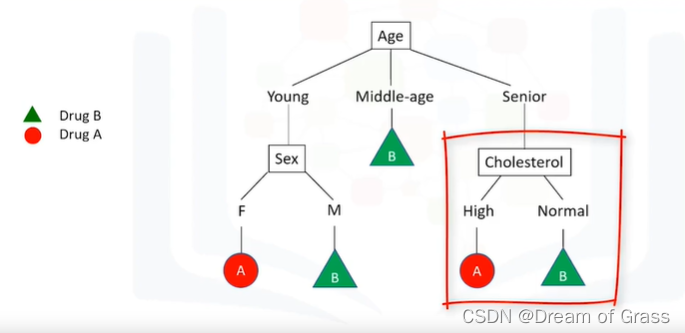
决策树是通过将训练集拆分为不同的节点来构建的,其中一个节点包含所有或大部分数据类别。来看这个图,我们可以看到它是一个病人的分类器。所以如前所述,我们想给一个新病人开药,但选择药物 A 或 B 的决定会受到病人情况的影响。我们从年龄开始,可以是年轻、中年或老年。如果患者是中年,那我们肯定会选择B药。反之,如果他有年轻或老年患者,则需要更多细节来帮助我们确定开哪种药。额外的决策变量可以是胆固醇水平、性别或血压等。
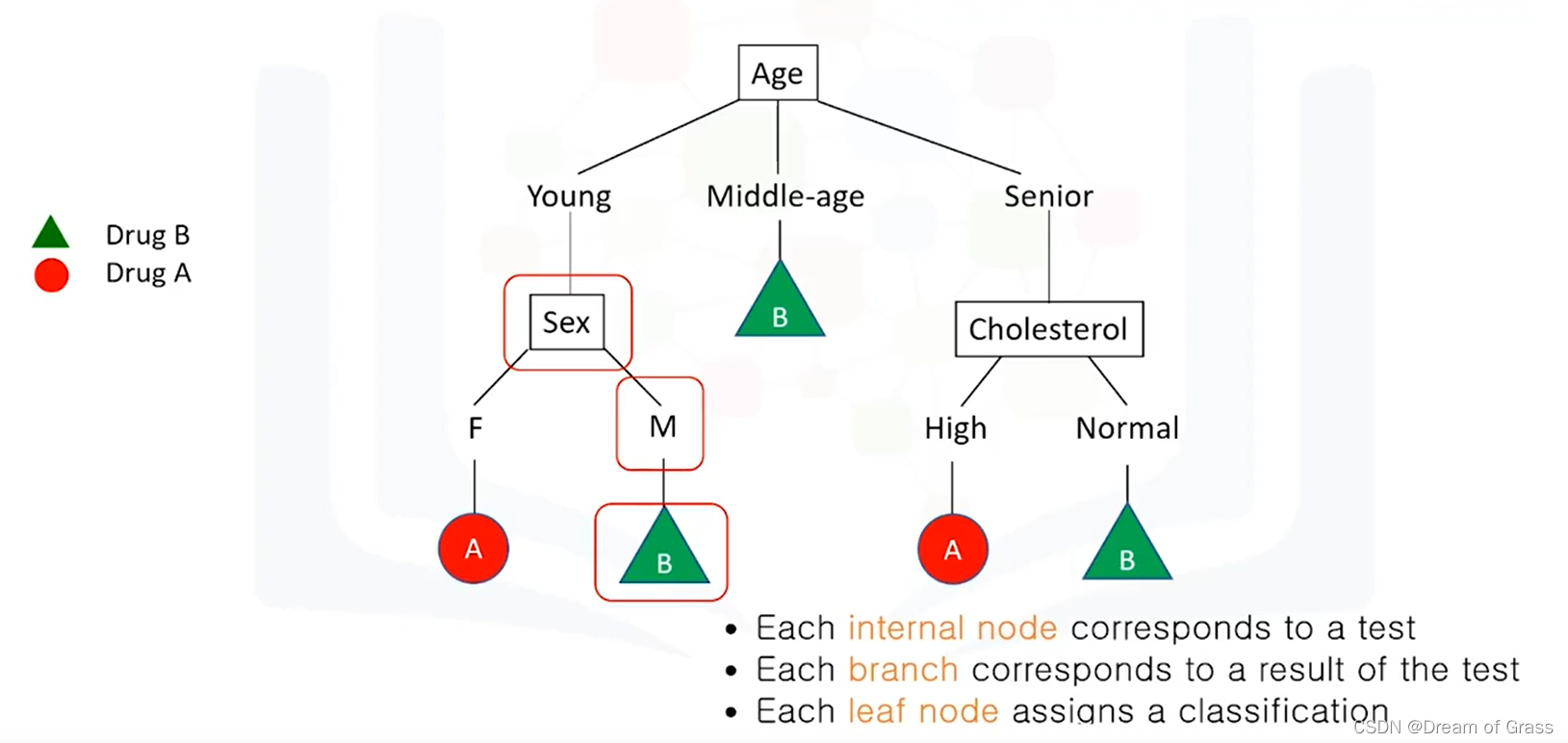
例如,如果患者是女性,那么我们会推荐药物 A,但如果患者是男性,那么我们会推荐药物 B。如您所见,决策树是关于测试一个属性并根据结果对案例进行分支的测试。每个内部节点对应一个测试,每个分支对应一个测试结果,每个叶节点将一个患者分配到一个类。
如何构建决策树
现在的问题是,我们如何构建这样的决策树?这是构建决策树的方式。可以通过逐个考虑属性来构建决策树。
具体步骤如下:
- 从数据集里面选择一个特征
- 计算这个属性在拆分数据上的重要性(后面会讲如何计算)
- 用最好的属性来分割数据
- 返回步骤1
构建决策树
构建决策树的关键点,就是选择哪个属性作为分类节点,也可以说是如何计算每个属性在拆分数据上的重要性。

下面我来举几个例子,假设选择胆固醇作为分割数据的第一个属性,它将我们的数据分成了两份。
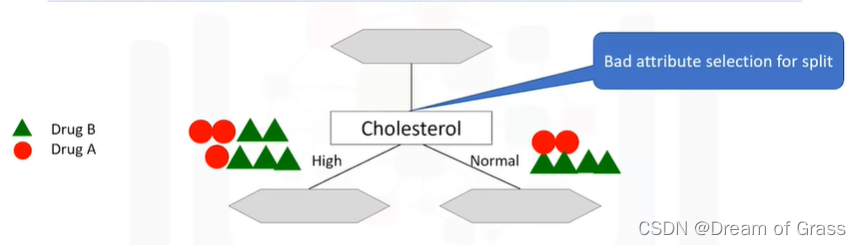
如上图所示,如果患者胆固醇含量高,我们不能很有把握地认为B药物适合他,同样的,如果含量正常,也不好说要用哪个药。也就是说,用胆固醇来分割数据,分了和没分差不了多少,故认为这不是一个好的特征。
下面我们换一个特征试试。
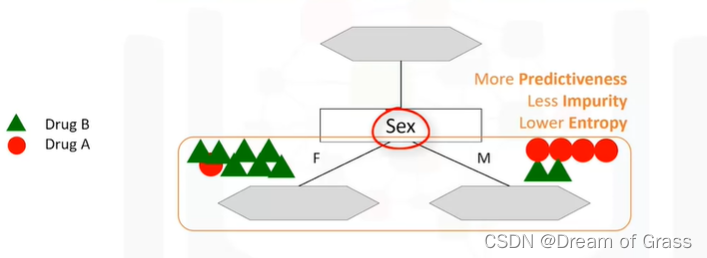
这次我们选择性别,如上图所示,如果患者性别为女,那么很大概率上就该用B药,如果是男性,则是A药。虽然说没有百分百的把握确定药物是否合适,但相比于胆固醇来说,性别这一属性任然是更好的选择,因为分类后的结果更纯净。也就是说性别属性比胆固醇更重要、更有预测性。
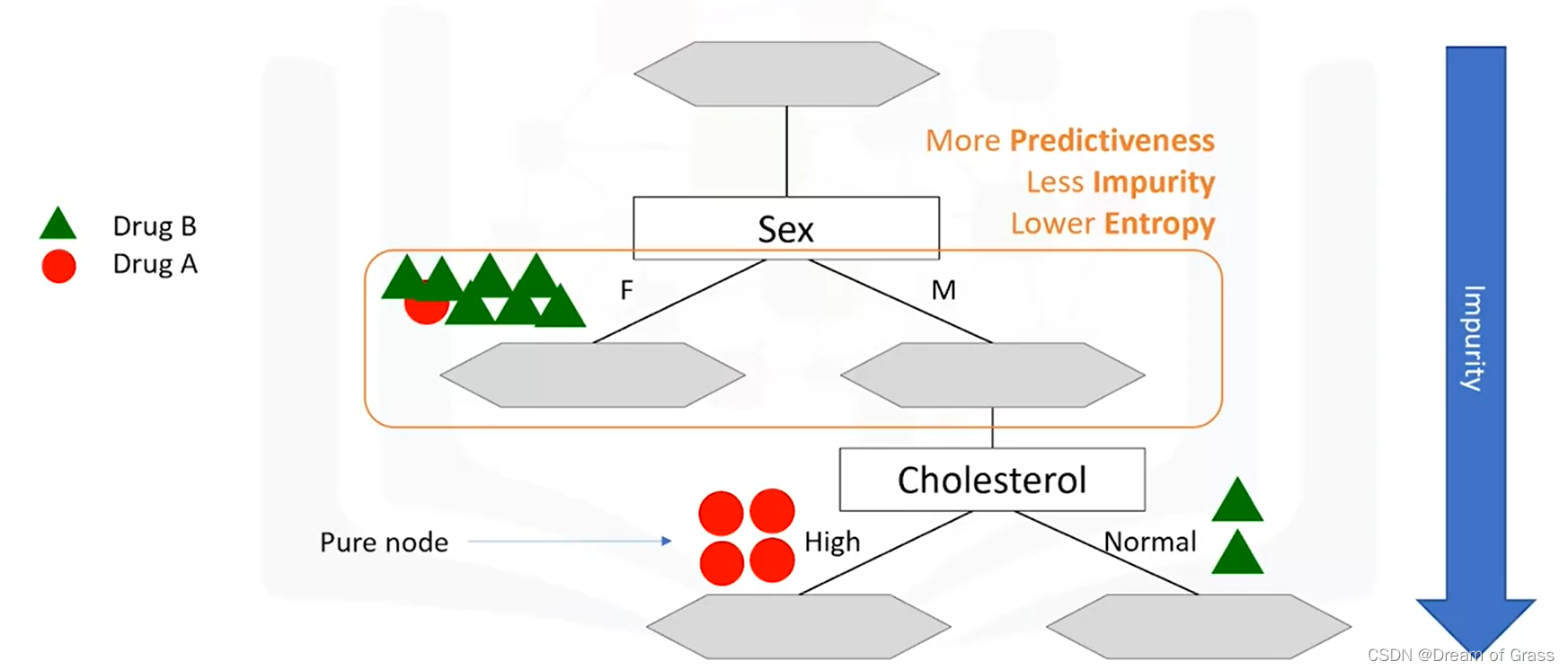
对于男性患者分支,我们再次测试其他属性来拆分子树。我们在这里再次测试胆固醇,您可以看到它会产生更纯净的叶子。所以我们可以在这里轻松地做出决定。例如,如果患者是男性,他的胆固醇高,我们当然可以开药A,但如果是正常的,我们可以很有把握地开药B。您可能会注意到,拆分数据的属性选择非常重要,这完全取决于拆分后叶子的纯度。如果在 100% 的情况下,节点属于目标字段的特定类别,则认为树中的节点是纯净节点。事实上,该方法使用递归分区通过最小化每一步的杂质将训练记录分割成段。节点的杂质是通过节点中数据的熵来计算的。
熵
什么是熵?熵是衡量信息的无序程度,也可以说是混乱都的,如果熵越大则混乱都越大。
熵用于计算该节点中样本的同质性。如果样本完全同质(只有一种表现形式),则熵为零,如果样本均分,则熵为 1。这意味着如果节点中的所有数据都是药物 A 或药物 B,则熵为零,但如果数据的一半是药物 A,另一半是 B,则熵为 1。

我们来计算一下原始数据的熵
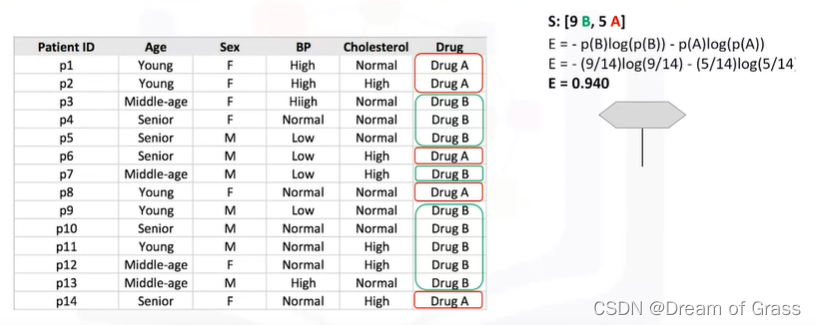
可以看到又9B 5A,代到熵的计算公式里面算就可以了。
这个公式和我之前上生物物理课的时候计算信息熵的公式一模一样。
然后再算算用胆固醇分割数据后的熵
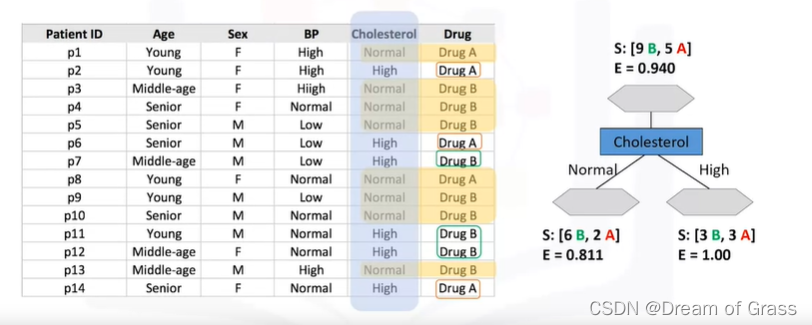
同样,算算性别分割数据后的熵
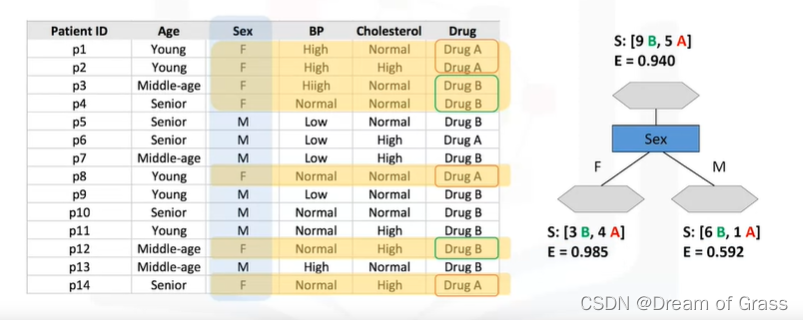
哪一个特征更好呢?
现在,问题是在胆固醇和性别属性之间,哪一个是更好的选择?将数据集分为两个分支的第一个属性哪个更好?或者换句话说,哪个属性会为我们的药物带来更纯的节点?或者,在哪棵树中,我们在分裂之后而不是分裂之前的熵更少?其分支中熵为 0.98 和 0.59 的性别属性或熵为 0.81 和 1.0 的胆固醇属性。答案是分裂后信息增益更高的树。

什么是信息增益
信息增益就是一个衡量分裂后熵有没有减少的一个指标。
我们知道熵越大不确定性越大,所以我们希望熵要逐渐减小,所以
信息增益
=
熵
分裂前
−
熵
分裂后加权
信息增益=熵_{分裂前}-熵_{分裂后加权}
信息增益=熵分裂前−熵分裂后加权
由此可见,如果熵减小,则信息增益越大,我们要选择信息增益大的特征作为分类节点。
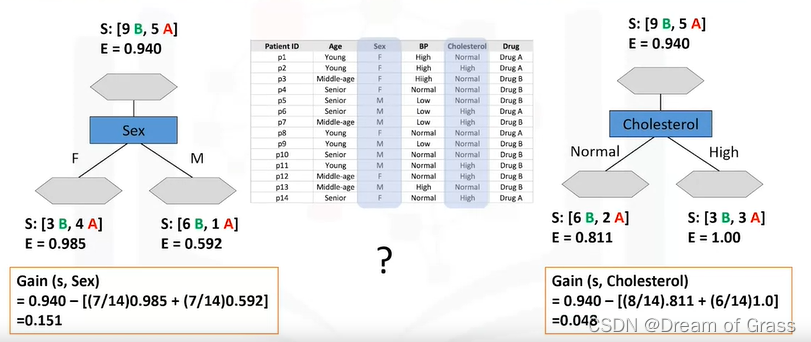
由上图可见,sex比cholesterol的信息增益要大,所以我们就选择sex。
结语
决策树的原理大概了解的差不多了,后面就是要对其进行代码实现。大家可以看这篇文章【机器学习】通俗易懂决策树(实战篇)python实现(为新患者找到合适的药物)