1.什么是JVM
JVM是 java Virtual Machine(java虚拟机)的缩写,JVM是作用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际计算机上仿真模拟各种计算机功能来实现的。java虚拟机包括一套字节码指令集,一组寄存器,一个栈,一个垃圾回收堆,一个存储方法域。JVM屏蔽了与具体操作系统相关的信息,使java程序只需生成在java虚拟机上运行的目标代码(字节码),就可以在多个平台上去运行。实现跨平台。JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行的。
2.JRE/JDK/JVM是什么关系
JRE(javaRuntimeEnvironment,java运行环境),也就是java平台,所有的java程序都要在JRE下才能运行。
JDK(java development kit) java 开发环境,开发工具包,开发者用来编译,调试。JDK也是需要JRE才可以运行的。
JVM 是JRE的一部分。
3.JVM的原理
JVM是java核心和基础,在java编译器和OS平台直接的虚拟处理器。它是一个利用软件方法实现的一个抽象的计算机基于下层操作系统和硬件平台,可以在上面执行java字节码程序。
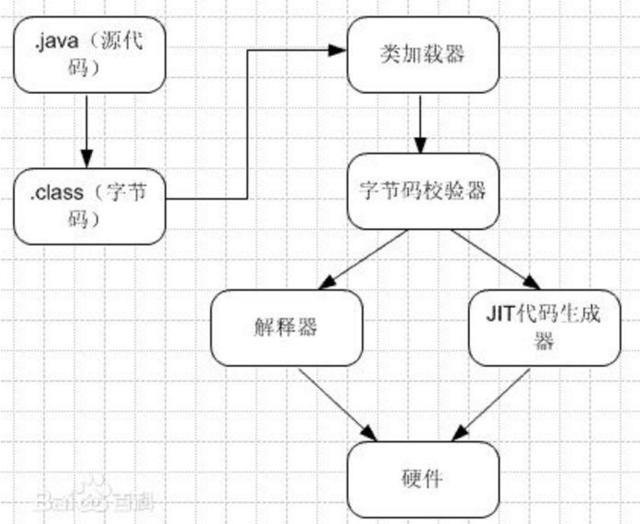
java编译器只要面向JVM,生成JVM能理解的代码或字节码文件。Java源文件经编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。
JVM的体系结构
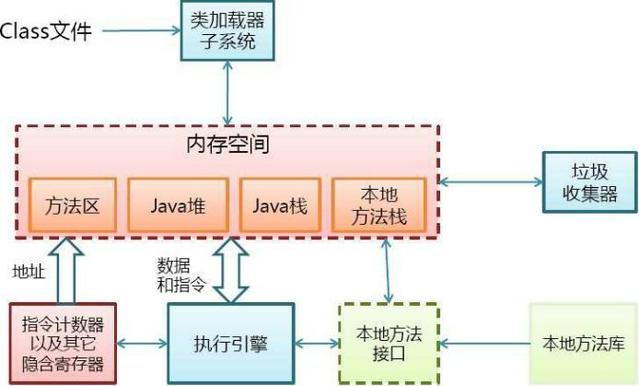
类加载器(ClassLoader):用来加载.class文件
执行引擎(执行字节码,或者执行本地方法)
运行是数据区(方法区,堆,栈,pc寄存器,本地方法栈)
PC寄存器
PC寄存器是用来存储每一个线程下一步将执行的JVM指令,如该方法为native的,则PC寄存器中不存储任何信息。
JVM栈
JVM栈是线程私有的,每个线程创建的同时都会创建JVM栈,JVM栈中存放的为当前线程中局部基本类型的变量(java中定义的八种基本类型:boolean、char、byte、short、int、long、float、double)、部分的返回结果以及Stack Frame,非基本类型的对象在JVM栈上仅存放一个指向堆上的地址。
栈溢出(StackOverflowError)
栈是线程私有的,他的生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口灯信息。局部变量表又包含基本数据类型,对象引用类型(局部变量表编译器完成,运行期间不会变化)
所以我们可以理解为栈溢出就是方法执行时创建的栈帧超过了栈的深度。那么最有可能的就是方法递归调用产生这种结果。
public class JvmTest {
private int i = 0;
public void a(){
System.out.println(i++);
a();
}
public static void main(String[] args) {
JvmTest j = new JvmTest();
j.a();
}
}
如何解决:
我们需要使用参数 -Xss 去调整JVM栈的大小。
堆(Heap)
它是JVM用来存储对象实例以及数组值的区域,可以认为Java中所有通过new创建的对象的内存都在此分配,Heap中的对象的内存需要等待GC进行回收。
堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的
堆内存溢出(OutOfMemoryError:java heap space)
heap space表示堆空间,堆中主要存储的是对象。如果不断的new对象则会导致堆中的空间溢出
public class JvmTest {
public static void main(String[] args) {
List<String> aList = new ArrayList<String>();
try{
while(true){
aList.add("asdasdasdas");
}
}catch(Throwable e){
System.out.println(aList.size());
e.printStackTrace();
}
}
}
可以通过 -Xmx4096M 调整堆的总大小
有两种算法可以判定对象是否存活:
1.引用计数算法:给对象中添加一个引用计数器,每当一个地方应用了对象,计数器加1;当引用失效,计数器减1;当计数器为0表示该对象已死、可回收。但是它很难解决两个对象之间相互循环引用的情况
2.可达性分析算法:通过一系列称为“GC Roots”的对象作为起点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连(即对象到GC Roots不可达),则证明此对象已死、可回收。Java中可以作为GC Roots的对象包括:虚拟机栈中引用的对象、本地方法栈中Native方法引用的对象、方法区静态属性引用的对象、方法区常量引用的对象。(java使用)
JVM垃圾回收
GC (Garbage Collection)的基本原理:将内存中不再被使用的对象进行回收,GC中用于回收的方法称为收集器,由于GC需要消耗一些资源和时间,Java在对对象的生命周期特征进行分析后,按照新生代、旧生代的方式来对对象进行收集,以尽可能的缩短GC对应用造成的暂停
(1)对新生代的对象的收集称为minor GC;
(2)对旧生代的对象的收集称为Full GC;
(3)程序中主动调用System.gc()强制执行的GC为Full GC。
不同的对象引用类型, GC会采用不同的方法进行回收,JVM对象的引用分为了四种类型:
(1)强引用:默认情况下,对象采用的均为强引用(这个对象的实例没有其他对象引用,GC时才会被回收)
(2)软引用:软引用是Java中提供的一种比较适合于缓存场景的应用(只有在内存不够用的情况下才会被GC)
(3)弱引用:在GC时一定会被GC回收
(4)虚引用:由于虚引用只是用来得知对象是否被GC
垃圾回收算法
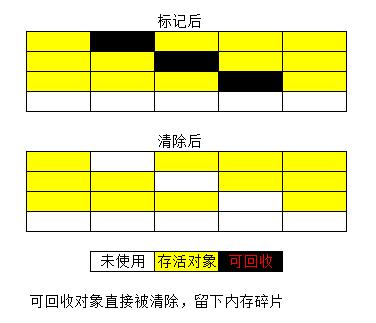
1、标记-清除算法
最基础的算法,分标记和清除两个阶段:首先标记处所需要回收的对象,在标记完成后统一回收所有被标记的对象。
它有两点不足:一个效率问题,标记和清除过程都效率不高;一个是空间问题,标记清除之后会产生大量不连续的内存碎片(类似于我们电脑的磁盘碎片),空间碎片太多导致需要分配大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾回收动作。
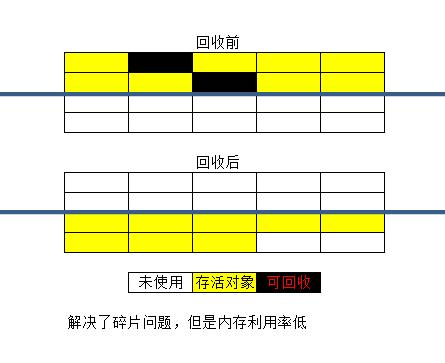
2、复制算法
为了解决效率问题,出现了“复制”算法,他将可用内存按容量划分为大小相等的两块,每次只需要使用其中一块。当一块内存用完了,将还存活的对象复制到另一块上面,然后再把刚刚用完的内存空间一次清理掉。这样就解决了内存碎片问题,但是代价就是可以用内容就缩小为原来的一半。
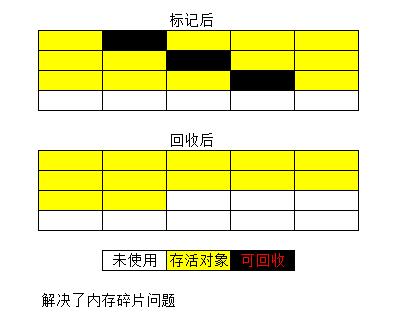
3、标记-整理算法
复制算法在对象存活率较高时就会进行频繁的复制操作,效率将降低。因此又有了标记-整理算法,标记过程同标记-清除算法,但是在后续步骤不是直接对对象进行清理,而是让所有存活的对象都向一侧移动,然后直接清理掉端边界以外的内存。
4、分代收集算法
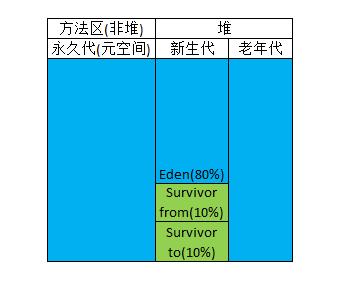
当前商业虚拟机的GC都是采用分代收集算法,这种算法并没有什么新的思想,而是根据对象存活周期的不同将堆分为:新生代和老年代,方法区称为永久代(在新的版本中已经将永久代废弃,引入了元空间的概念,永久代使用的是JVM内存而元空间直接使用物理内存)。
这样就可以根据各个年代的特点采用不同的收集算法。