高性能计算实验——矩阵乘法基于OpenMP的实现及优化
1.实验目的
1.1.通过OpenMP实现通用矩阵乘法
熟练掌握OpenMP原理,完成通用矩阵乘法的OpenMP实现,为后续实验打下基础。
1.2.基于OpenMP的通用矩阵乘法优化
进一步熟悉OpenMP的任务调度机制,分别采用OpenMP的默认任务调度机制、静态调度和动态调度实现#pragma omp for,比较性能。
1.3.构造基于Pthreads的并行for循环分解、分配和执行机制
学习Pthreads多线程库提供的函数,构建parallel_for 函数对循环分解、分配和执行机制,将基于 OpenMP 的通用矩阵乘法的omp parallel for 并行,改造成基于parallel_for 函数并行化的矩阵乘法。
2.实验过程和核心代码
2.1.通过OpenMP实现通用矩阵乘法
2.1.1.问题描述
通过OpenMP 实现通用矩阵乘法(实验1)的并行版本,OpenMP 并行线程从 1 增加至 8,矩阵规模从 512 增加至 2048。
通用矩阵乘法(GEMM)通常定义为:
C = AB
输入:M , N, K 三个整数(512 ~2048)
问题描述:随机生成 MN 和NK 的两个矩阵 A,B,对这两个矩阵做乘法得到矩阵 C.
输出:A,B,C 三个矩阵以及矩阵计算的时间
2.1.2.实现过程
这里可以根据GEMM公式进行核心代码矩阵乘法部分的实现,将OpenMP多线程的核心#pragma omp parallel制导语句加在函数前面。
#pragma omp parallel num_threads(thread_count)
- #pragma omp pallel
使用parallel是用来表明之后的结构化代码块(一个结构化代码块时一条C语句或者只有一个入口和一个出口的一组复合C语句)应该被多个线程并行执行。完成代码块前会有一个隐式路障,先完成的线程必须等待线程组其他线程完成代码块。
- num_threads 子句
允许程序员指定执行后代码块的线程数,程序可以启动的线程数可能会受系统定义的限制。OpenMP标准并不保证实际能够启动thread_count个线程。
输入方面根据输入的矩阵信息分配对应的空间并产生随机数。
2.1.3.核心代码
①矩阵生成
void Gen_Matrix(){
for(int i=0;i<M;i++){
for(int j=0;j<N;j++){
a[i][j] = rand()%10;
}
…
}
for(int i=0;i<N;i++){
for(int j=0;j<K;j++){
b[i][j] = rand()%10;
}
…
}
}
②矩阵乘法

首先需要获取线程编号,根据编号得到起始和结束行,这里按照a矩阵的行数M进行线程任务划分。
③Main函数主要代码
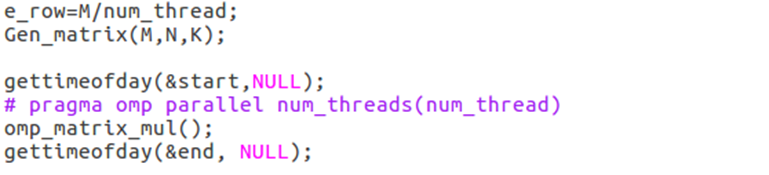
首先计算出每个线程的执行的行数,接着将制导语句#pragma omp parallel标在函数前表示使用多线程并行执行。
2.2.通用矩阵乘法优化
2.2.1.问题描述
分别采用OpenMP 的默认任务调度机制和静态调度schedule(static, 1) 和动态调度schedule(dynamic,1)的性能,实现#pragma omp for,并比较其性能。
2.2.2.实现过程
-
#pragma omp for:
#pragma omp parallel for是OpenMP中的一个指令,表示接下来的for循环将被多线程执行,另外每次循环之间不能有关系。
-
OpenMP的任务调度机制:
OpenMP中,任务调度主要用于并行的for循环中,当循环中每次迭代的计算量不相等时,如果简单地给各个线程分配相同次数的迭代的话,会造成各个线程计算负载不均衡,这会使得有些线程先执行完,有些后执行完,造成某些CPU核空闲,影响程序性能。
-
schedule的使用格式为:
schedule(type[,size])
schedule有两个参数:type和size,size参数是可选的。
- 静态调度(static) #pragma omp parallel for schedule(static, N)
当parallel for编译指导语句没有带schedule子句时,大部分系统中默认采用static调度方式,这种调度方式非常简单。假设有n次循环迭代,t个线程,那么给每个线程静态分配大约n/t次迭代计算。
- 动态调度(dynamic) #pragma omp parallel for schedule(dynamic, N)
动态调度是动态地将迭代分配到各个线程,动态调度可以使用size参数也可以不使用size参数,不使用size参数时是将迭代逐个地分配到各个线程,使用size参数时,每次分配给线程的迭代次数为指定的size次。
2.2.3.核心代码
静态调度大致与任务一类似,制导语句以及位置改变:

制导语句从函数上移动到for循环上,此时不需要像是任务1需要在函数内进行需要处理的行数计算,这是根据调度策略自动决定的。
Static调度:

Dynamic调度:

可以看到只需要修改制导语句即可。
2.3.大规模矩阵计算优化
2.3.1.问题描述
- 基于pthreads 的多线程库提供的基本函数,如线程创建、线程join、线程同步等。构建parallel_for 函数对循环分解、分配和执行机制,函数参数包括但不限于(int start, int end, int increment, void *(functor)(void), void *arg , in num_threads);其中 start 为循环开始索引;end 为结束索引; increment 每次循环增加索引数;functor 为函数指针,指向的需要被并行执行循环程序块;arg 为 functor 的入口参数; num_threads 为并行线程数。
- 在Linux 系统中将parallel_for 函数编译为.so 文件,由其他程序调用。
- 将基于 OpenMP 的通用矩阵乘法的omp parallel for 并行,改造成基于parallel_for 函数并行化的矩阵乘法,注意只改造可被并行执行的 for 循环(例如无 race condition、无数据依赖、无循环依赖等。
2.3.2.实现思想
这里我的理解比较简单,只要自己完成parallel_for函数(实现for循环Pthreads并行化),在parallel_for函数内完成分行(划分任务),创建任务,分配任务给线程执行即可。
将parallel_for函数打包为.so文件,在调用该函数时需要指定线程的工作函数,所以需要自己完成functor函数,较为简单,直接完成矩阵乘法就行。
2.3.3.核心代码
①Parallel_for函数
这里需要根据总行数和线程数进行划分,有可能出现不均匀的情况,所以划分的时候需要注意最后一个线程要处理的行数。之后为划分后的任务创建工作线程。

②For_index结构体

这个结构体用于表示线程需要处理的工作行数和跨度。(这里的跨度其实可以实现的很灵活,比如在矩阵乘法的最内层进行for_parallel函数调用时可以通过指定跨度轻松实现矩阵乘法)
③Functor函数

这里就是简单的将线程需要的行数从结构体中拿出来之后进行矩阵乘法。
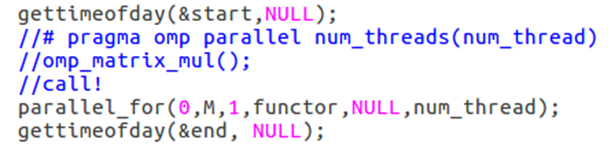
Main函数里只需要调用parallel_for函数即可。
3.实验结果
3.1.基于OpenMP实现通用矩阵乘法

可以看到,计算结果正确;
矩阵大小从512-1024,线程从1~8所需要的时间:
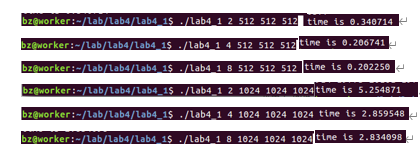
可以看到线程在2到4时效率有明显提升,但是4至8却没有,主要原因还是虚拟机核心数不足。
3.2.基于OpenMP的通用矩阵优化
这里为了体现出OpenMP的任务调度机制,选择使用2线程。

可以看到static和dynamic差距并不大,我觉得是矩阵乘法任务本身for循环中的计算量大致相同的原因。
3.3.构造基于 Pthreads 的并行 for 循环分解、分配和执行机制。

成功生成.so文件;

成功生成可执行文件;

执行结果正确。
4.实验感想
本次实验是高性能实验OpenMP部分,由简入深掌握了OpenMP大致内容,同时任务三提高了实验的难度,更好的锻炼了编程能力。