目录
一、决策树剪枝策略
1.1剪枝目的
1.2剪枝策略
1.3判断决策树泛化性能是否提升的方法
二、预剪枝 (prepruning)
2.1概述
2.2预剪枝优缺点
2.3代码实现
三、后剪枝(postpruning)
3.1概述
3.2后剪枝优缺点
3.3代码实现
代码部分参考决策树python源码实现(含预剪枝和后剪枝)_王路ylu的博客-CSDN博客_构建决策树代码
一、决策树剪枝策略
1.1剪枝目的
决策树过拟合(数据在训练集上表现的很好,在测试集上表现的不好)风险很大,理论上可以完全分的开数据(想象一下,如果树足够庞大,每个叶子节点就一个数据)
“剪枝”是决策树学习算法对付“过拟合”的主要手段
可以通过“剪枝”来一定程度避免因决策分支过多,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致的过拟合
1.2剪枝策略
预剪枝:边建立决策树边进行剪枝的操作(更实用)
后剪枝:当建立完决策树后进行剪枝操作
1.3判断决策树泛化性能是否提升的方法
留出法:预留出一部分数据用作“验证集”以进行性能评估
二、预剪枝 (prepruning)
2.1概述
决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点记为叶结点,其类别标记为该结点对应训练样例数最多的类别。
策略:
- 限制深度(例如数据集有十个特征,限制树的深度为3,即只能用其中三个特征创建树)
- 叶子结点个数(最多只能有五个叶子结点)
- 叶子结点样本数(一个叶子结点最少得有20个样本)
- 信息增益
这样说可能还是有点难理解预剪枝怎么做,用西瓜书中的例子简单说明一下
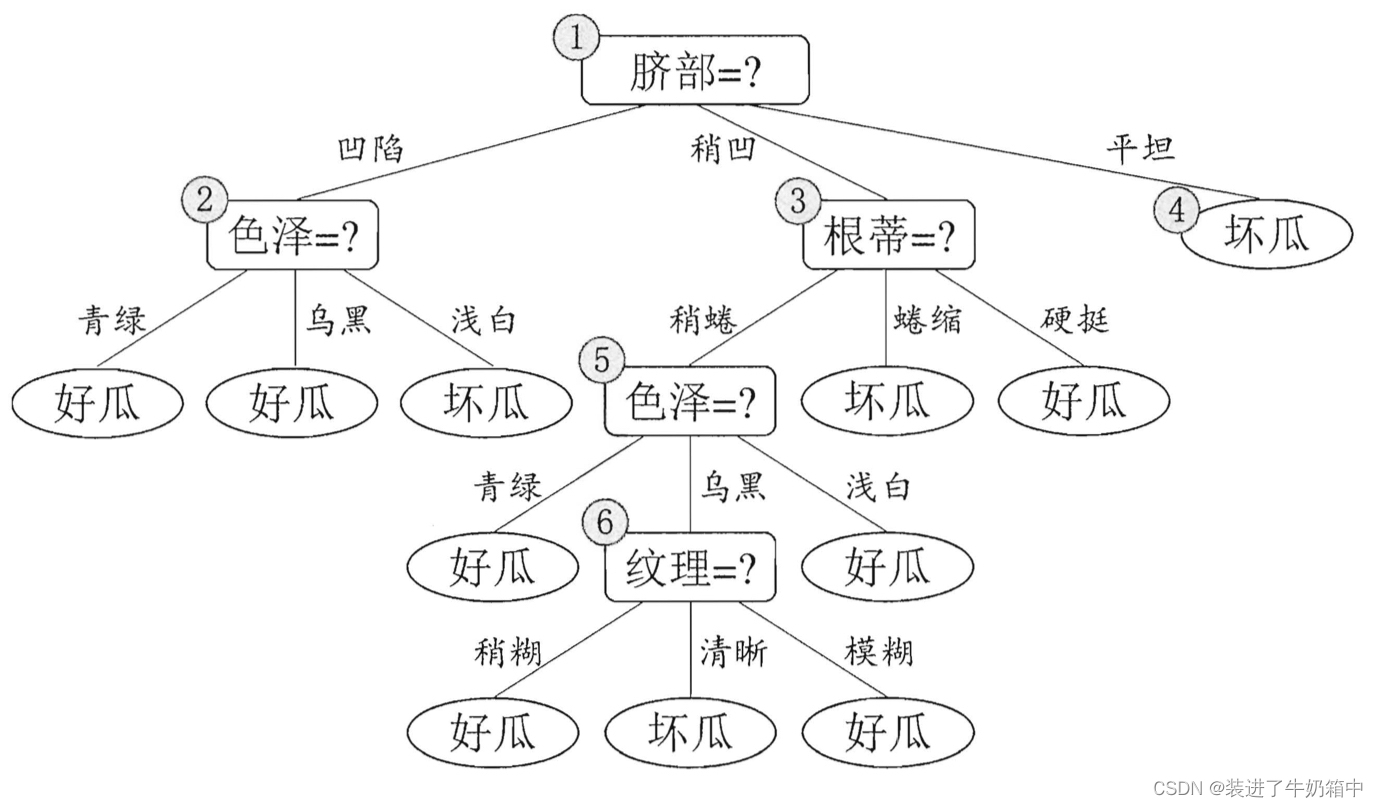
根据信息增益(具体计算过程在机器学习——创建决策树_装进了牛奶箱中的博客-CSDN博客 )我们可以得到一棵未剪枝的树:
(1)首先,我们先判断“脐部”,如果我们不对“脐部”进行划分,也就是说这棵决策树是这样的:

这样下来,也就是说无论你什么瓜过来我都判断它是好瓜。使用验证集进行验证,验证的精准度为: 
如果进行划分(其中红色字体的表示验证集中被划分正确的编号):
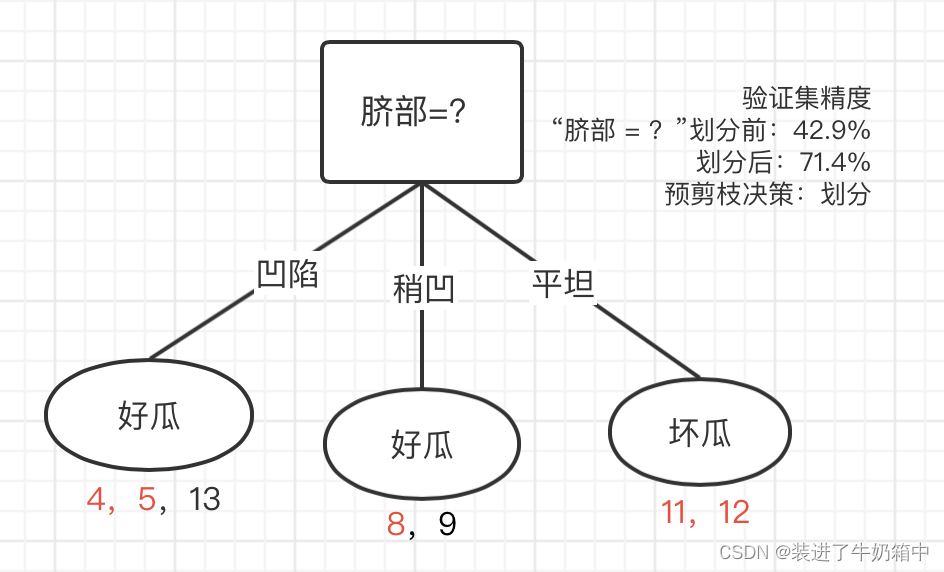
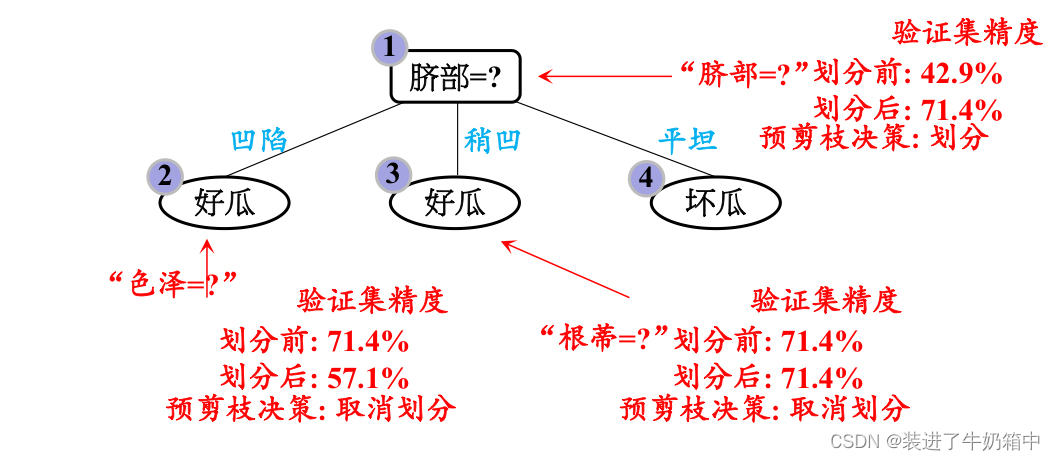
如果只划分脐部这个属性,,我们可以通过其来划分好瓜和坏瓜,通过验证机去测试,我们可以得到划分后的精确度为: ,71.4%>42.9%所以选择划分
,71.4%>42.9%所以选择划分
(2)再看“脐部=凹陷“这个分支
如果不划分,验证集精度为71.4%
如果划分(其中红色字体的表示验证集中被划分正确的编号),验证集中编号为{4,8,11,12}的样例被划分正确:

划分后的精确度为  ,57.1%<71.4%所以选择取消划分
,57.1%<71.4%所以选择取消划分
(3)对每个结点进行剪枝判断,结点2,3都禁止划分,结点4本身为叶子结点。最终得到仅有一层划分的“决策树桩”
2.2预剪枝优缺点
优点:降低过拟合风险,显著减少训练时间和测试时间开销。
缺点:欠拟合风险:有些分支的当前划分虽然不能提神泛化性能,但在其基础上进行的后续划分却有可能显著提高性能。预剪枝基于“贪心”本质禁止这些分支展开,带来了欠拟合分险。
2.3代码实现
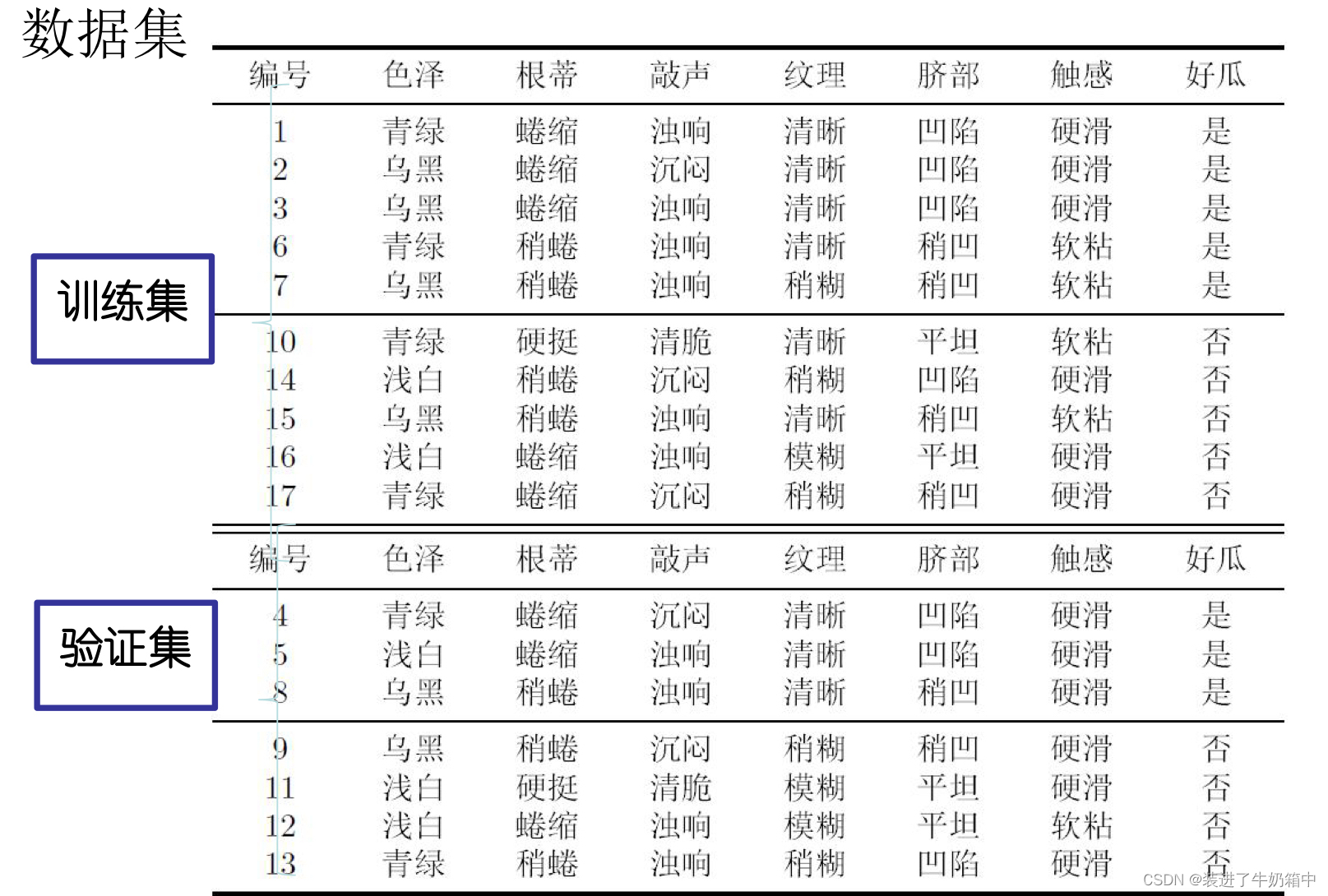
以福建省选调生报考条件和上述判断西瓜好坏为例,选调生数据集如下:
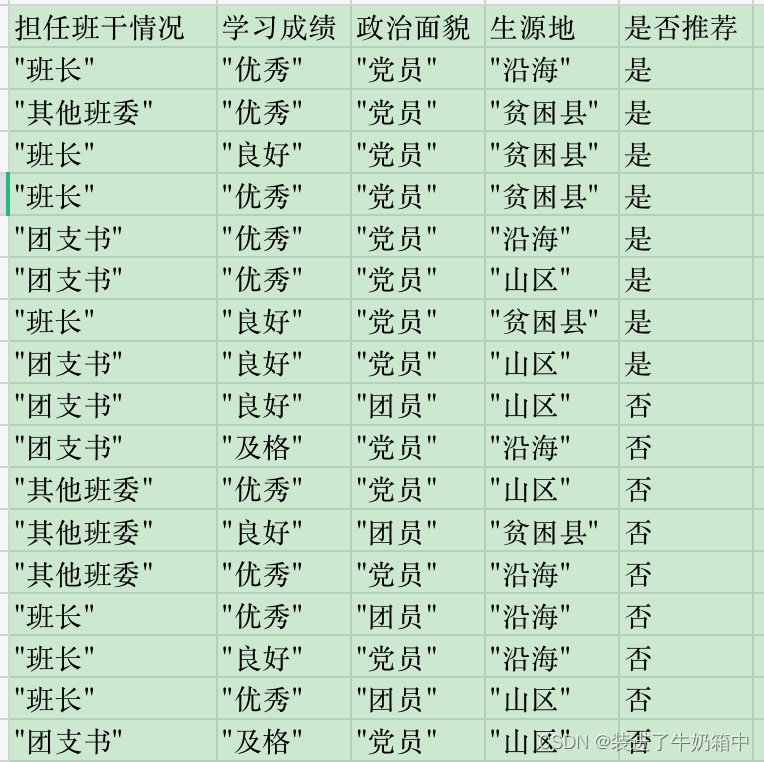
这里只展示预剪枝部分的代码,完整代码可以点击百度网盘链接查看
# 创建预剪枝决策树
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method = 'id3'):
trainData = np.asarray(dataTrain)
labelTrain = np.asarray(labelTrain)
testData = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labelTrain)) == 1:
return labelTrain[0]
# 如果没有待分类特征
elif trainData.size == 0:
return voteLabel(labelTrain)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据最优特征进行分割
dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)
# 预剪枝评估
# 划分前的分类标签
labelTrainLabelPre = voteLabel(labelTrain)
labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.size
# 划分后的精度计算
if dataTest is not None:
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)
# 划分前的测试标签正确比例
labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.size
# 划分后 每个特征值的分类标签正确的数量
labelTrainEqNumPost = 0
for val in labelTrainSet.keys():
labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0
# 划分后 正确的比例
labelTestRatioPost = labelTrainEqNumPost / labelTest.size
# 如果没有评估数据 但划分前的精度等于最小值0.5 则继续划分
if dataTest is None and labelTrainRatioPre == 0.5:
decisionTree = {bestFeatName: {}}
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, None, None, names, method)
elif dataTest is None:
return labelTrainLabelPre
# 如果划分后的精度相比划分前的精度下降, 则直接作为叶子节点返回
elif labelTestRatioPost < labelTestRatioPre:
return labelTrainLabelPre
else :
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, dataTestSet.get(featValue), labelTestSet.get(featValue)
, names, method)
return decisionTree
# 将数据分割为测试集和训练集
myDataTrain, myLabelTrain, myDataTest, myLabelTest = splitMyData20(myData, myLabel)
# 生成不剪枝的树
myTreeTrain = createTree(myDataTrain, myLabelTrain, myName, method = 'id3')
# 生成预剪枝的树
myTreePrePruning = createTreePrePruning(myDataTrain, myLabelTrain, myDataTest, myLabelTest, myName, method = 'id3')
# 画剪枝前的树
print("剪枝前的树")
createPlot(myTreeTrain)
# 画剪枝后的树
print("剪枝后的树")
createPlot(myTreePrePruning)
选调生数据集运行结果
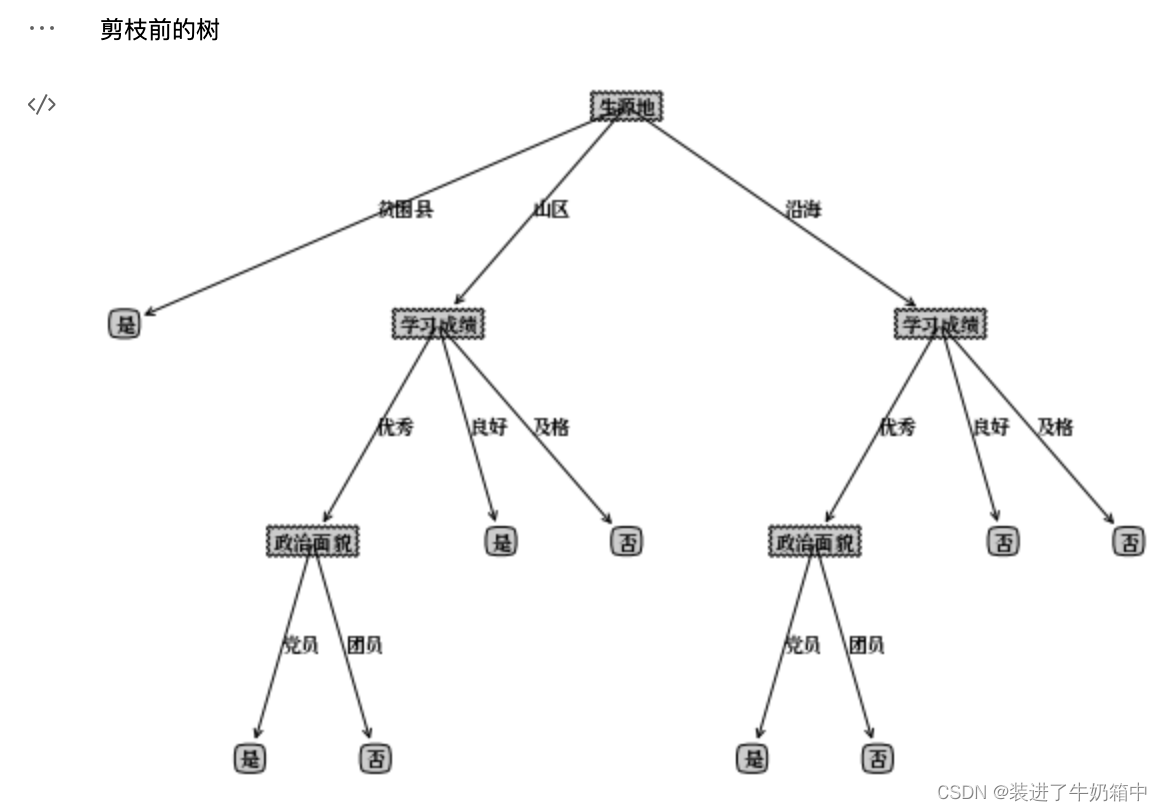
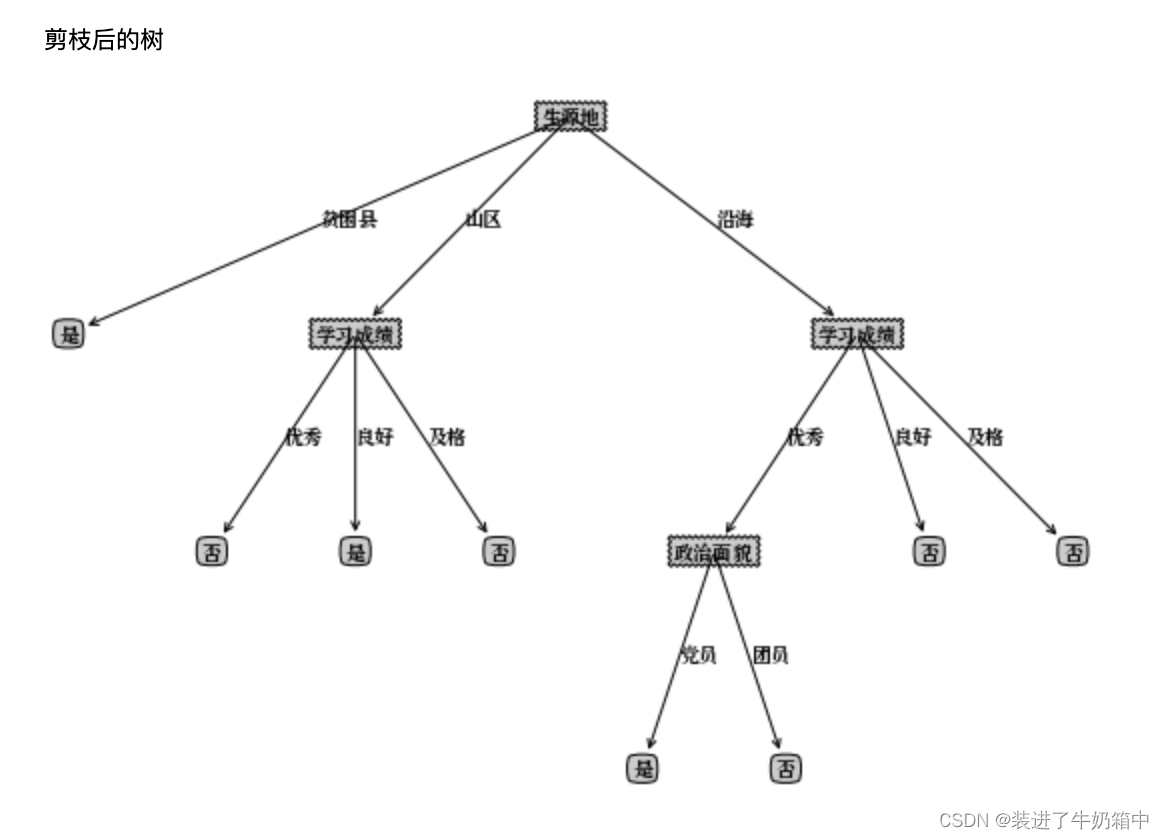
可能是数据集的原因导致剪枝后的树和事实有点不符
# 将西瓜数据2.0分割为测试集和训练集
xgDataTrain, xgLabelTrain, xgDataTest, xgLabelTest = splitXgData20(xgData, xgLabel)
# 生成不剪枝的树
xgTreeTrain = createTree(xgDataTrain, xgLabelTrain, xgName, method = 'id3')
# 生成预剪枝的树
xgTreePrePruning = createTreePrePruning(xgDataTrain, xgLabelTrain, xgDataTest, xgLabelTest, xgName, method = 'id3')
# 画剪枝前的树
print("剪枝前的树")
createPlot(xgTreeTrain)
# 画剪枝后的树
print("剪枝后的树")
createPlot(xgTreePrePruning)
西瓜数据集运行结果
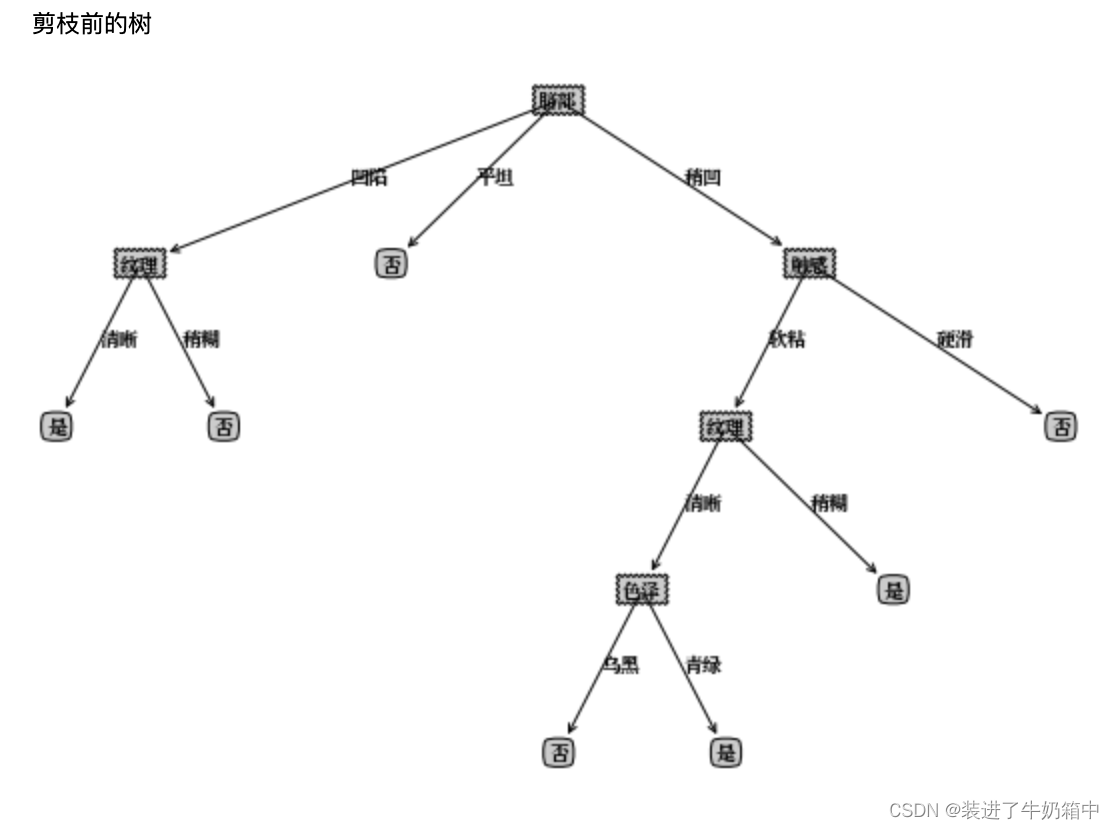
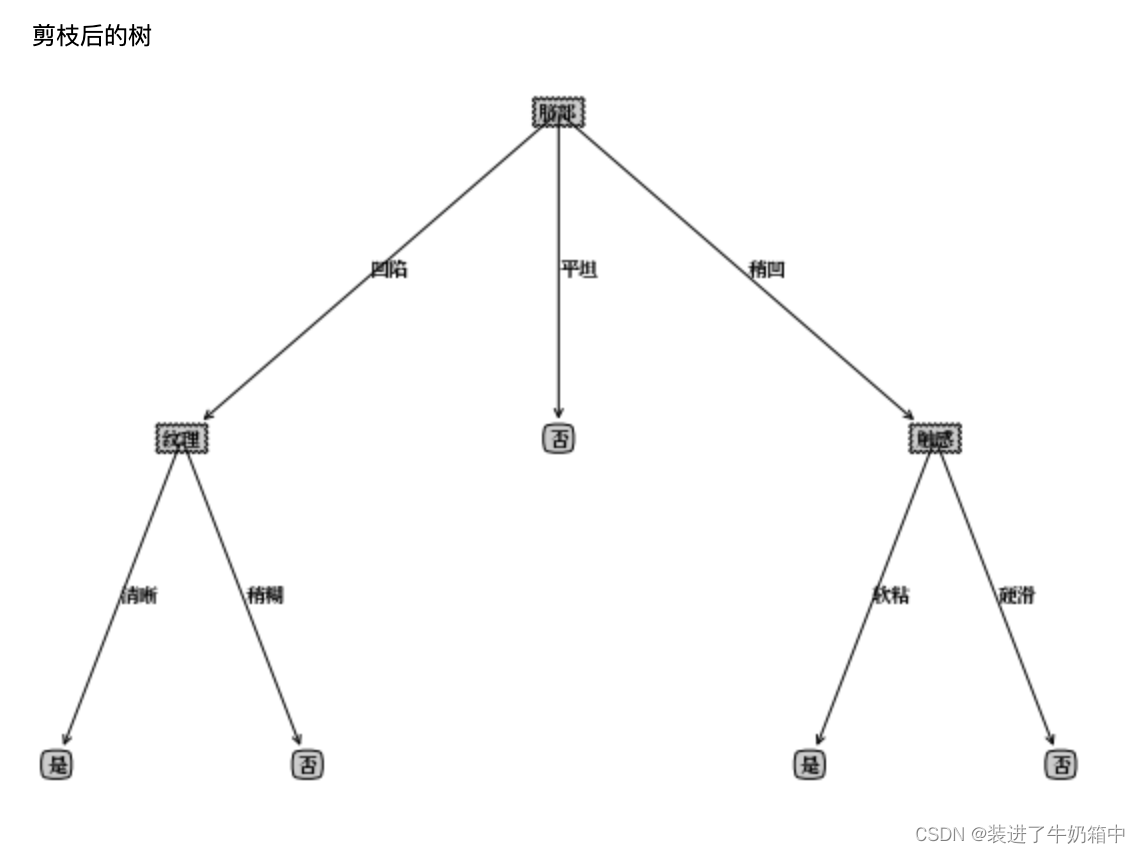
由于特征选择的问题,最后得到的图像和书上的有差异
三、后剪枝(postpruning)
3.1概述
先从训练集生成一棵完整的决策树,然后自底向上地对非叶子结点进行分析计算,若将该结点对应的子树替换为叶结点,能带来决策树泛化性能提升,则将该子树替换为叶结点
同样的,我们使用上诉例子来简单说明一下后剪枝,先从训练集生成一棵完整的决策树
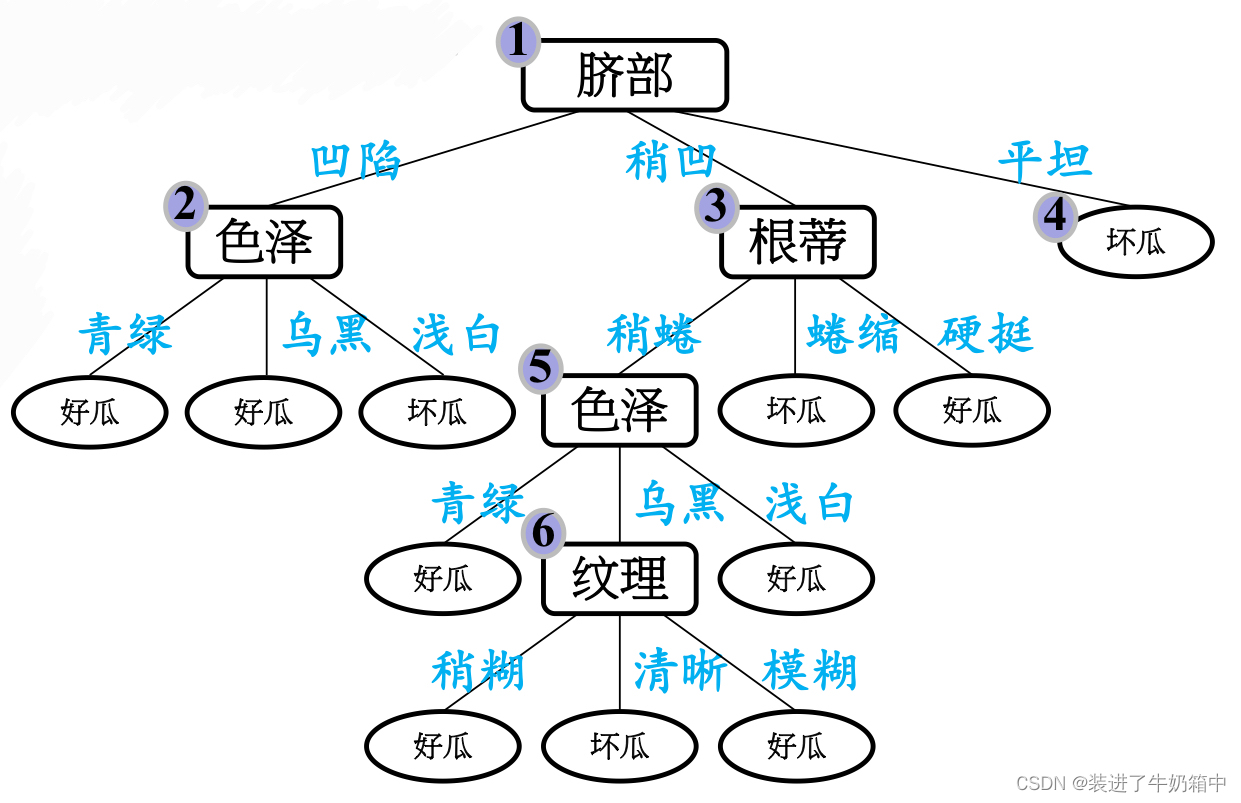
(1)第一步先考察结点6,如果不剪枝,验证集中编号为{4,11,12}的三个样本被正确分类,因此验证集精度为
如果将其替换为叶结点,根据落在其上的训练样本{7,15}将其标记为“好瓜”,进入该分支的验证集样本有{8,9},样本8被正确分类,对整个验证集编号为{4,8,11,12}的四个样本正确分类,因此验证集的精度为,57.1%>42.9%,所以选择剪掉该分支。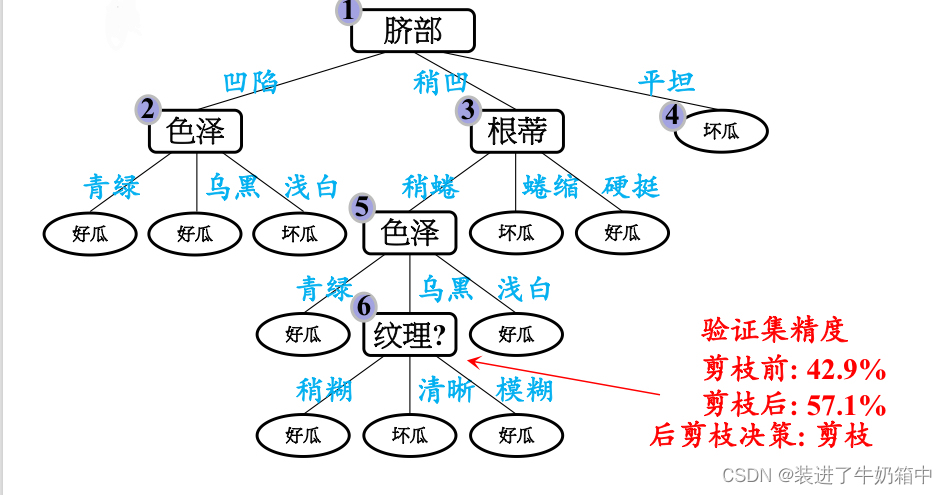
(2)再来考察结点5,如果不剪枝,验证集精度为57.1%
如果将其替换为叶子结点,根据落在其上的训练样本{6,7,15}将其标记为“好瓜”,进入该分支的验证集样本有{8,9},样本8被正确分类,对整个验证集编号为{4,8,11,12}的四个样本正确分类,因此验证集的精度为,57.1%=57.2%,所以不剪枝
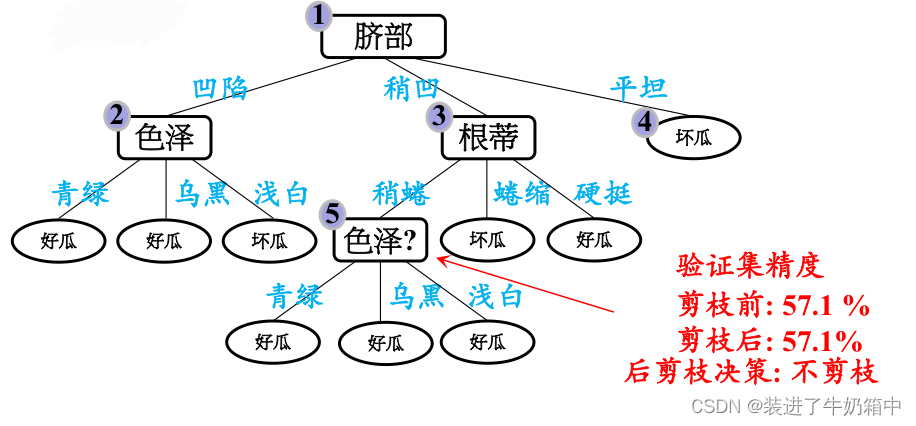
(3)对结点2,如果不剪枝,验证集精度为57.1%
如果将其替换为叶子结点,根据落在其上的训练样本{1,2,3,14}将其标记为“好瓜”,进入该分支的验证集样本有{4,5,13},样本4,5被正确分类,对整个验证集编号为{4,5,8,11,12}的五个样本正确分类,因此验证集的精度为 ,71.4%>57.1%,所以选择剪掉该分支。
,71.4%>57.1%,所以选择剪掉该分支。
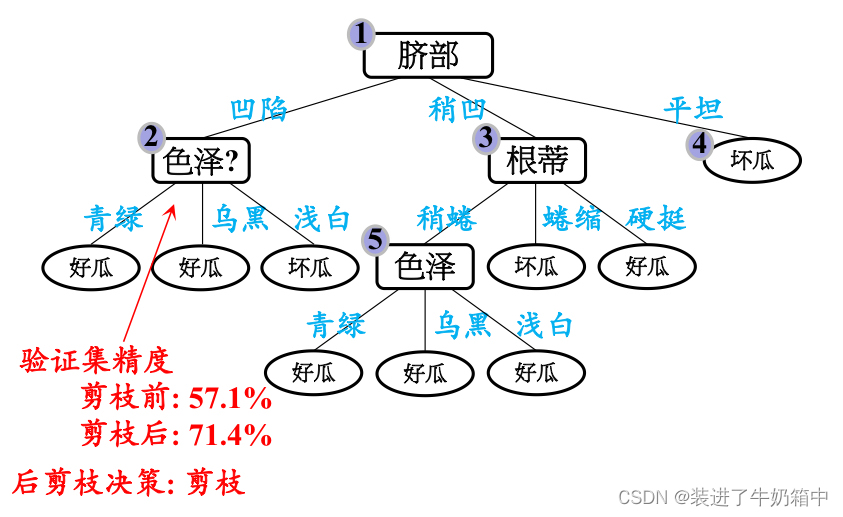
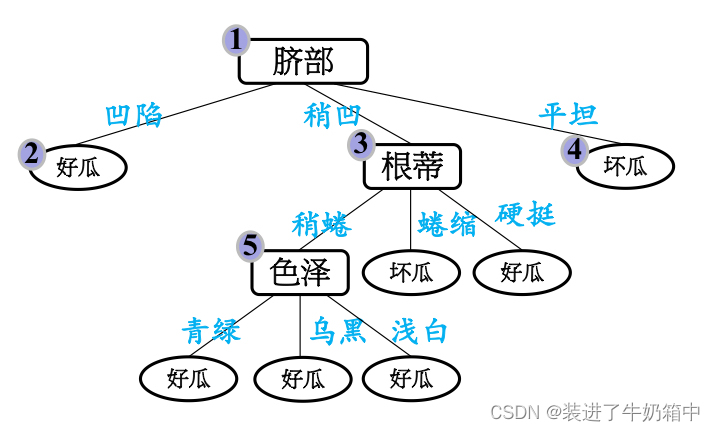
基于 后剪枝策略 得到的最终决策树如图所示
3.2后剪枝优缺点
优点:后剪枝比预剪枝保留了更多的分支,欠拟合分险小,泛化性能往往优于预剪枝决策树
缺点:训练时间开销大:后剪枝过程是在生成完全决策树之后进行的,需要自底向上对所有非叶子结点逐一计算
3.3代码实现
# 创建决策树 带预划分标签
def createTreeWithLabel(data, labels, names, method = 'id3'):
data = np.asarray(data)
labels = np.asarray(labels)
names = np.asarray(names)
# 如果不划分的标签为
votedLabel = voteLabel(labels)
# 如果结果为单一结果
if len(set(labels)) == 1:
return votedLabel
# 如果没有待分类特征
elif data.size == 0:
return votedLabel
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(data, labels, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据选取的特征名称创建树节点 划分前的标签votedPreDivisionLabel=_vpdl
decisionTree = {bestFeatName: {"_vpdl": votedLabel}}
# 根据最优特征进行分割
dataSet, labelSet = splitFeatureData(data, labels, bestFeat)
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataSet.keys():
decisionTree[bestFeatName][featValue] = createTreeWithLabel(dataSet.get(featValue), labelSet.get(featValue), names, method)
return decisionTree
# 将带预划分标签的tree转化为常规的tree
# 函数中进行的copy操作,原因见有道笔记 【YL20190621】关于Python中字典存储修改的思考
def convertTree(labeledTree):
labeledTreeNew = labeledTree.copy()
nodeName = list(labeledTree.keys())[0]
labeledTreeNew[nodeName] = labeledTree[nodeName].copy()
for val in list(labeledTree[nodeName].keys()):
if val == "_vpdl":
labeledTreeNew[nodeName].pop(val)
elif type(labeledTree[nodeName][val]) == dict:
labeledTreeNew[nodeName][val] = convertTree(labeledTree[nodeName][val])
return labeledTreeNew
# 后剪枝 训练完成后决策节点进行替换评估 这里可以直接对xgTreeTrain进行操作
def treePostPruning(labeledTree, dataTest, labelTest, names):
newTree = labeledTree.copy()
dataTest = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 取决策节点的名称 即特征的名称
featName = list(labeledTree.keys())[0]
# print("\n当前节点:" + featName)
# 取特征的列
featCol = np.argwhere(names==featName)[0][0]
names = np.delete(names, [featCol])
# print("当前节点划分的数据维度:" + str(names))
# print("当前节点划分的数据:" )
# print(dataTest)
# print(labelTest)
# 该特征下所有值的字典
newTree[featName] = labeledTree[featName].copy()
featValueDict = newTree[featName]
featPreLabel = featValueDict.pop("_vpdl")
# print("当前节点预划分标签:" + featPreLabel)
# 是否为子树的标记
subTreeFlag = 0
# 分割测试数据 如果有数据 则进行测试或递归调用 np的array我不知道怎么判断是否None, 用is None是错的
dataFlag = 1 if sum(dataTest.shape) > 0 else 0
if dataFlag == 1:
# print("当前节点有划分数据!")
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, featCol)
for featValue in featValueDict.keys():
# print("当前节点属性 {0} 的子节点:{1}".format(featValue ,str(featValueDict[featValue])))
if dataFlag == 1 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
# 如果是子树则递归
newTree[featName][featValue] = treePostPruning(featValueDict[featValue], dataTestSet.get(featValue), labelTestSet.get(featValue), names)
# 如果递归后为叶子 则后续进行评估
if type(featValueDict[featValue]) != dict:
subTreeFlag = 0
# 如果没有数据 则转换子树
if dataFlag == 0 and type(featValueDict[featValue]) == dict:
subTreeFlag = 1
# print("当前节点无划分数据!直接转换树:"+str(featValueDict[featValue]))
newTree[featName][featValue] = convertTree(featValueDict[featValue])
# print("转换结果:" + str(convertTree(featValueDict[featValue])))
# 如果全为叶子节点, 评估需要划分前的标签,这里思考两种方法,
# 一是,不改变原来的训练函数,评估时使用训练数据对划分前的节点标签重新打标
# 二是,改进训练函数,在训练的同时为每个节点增加划分前的标签,这样可以保证评估时只使用测试数据,避免再次使用大量的训练数据
# 这里考虑第二种方法 写新的函数 createTreeWithLabel,当然也可以修改createTree来添加参数实现
if subTreeFlag == 0:
ratioPreDivision = equalNums(labelTest, featPreLabel) / labelTest.size
equalNum = 0
for val in labelTestSet.keys():
equalNum += equalNums(labelTestSet[val], featValueDict[val])
ratioAfterDivision = equalNum / labelTest.size
# print("当前节点预划分标签的准确率:" + str(ratioPreDivision))
# print("当前节点划分后的准确率:" + str(ratioAfterDivision))
# 如果划分后的测试数据准确率低于划分前的,则划分无效,进行剪枝,即使节点等于预划分标签
# 注意这里取的是小于,如果有需要 也可以取 小于等于
if ratioAfterDivision < ratioPreDivision:
newTree = featPreLabel
return newTree
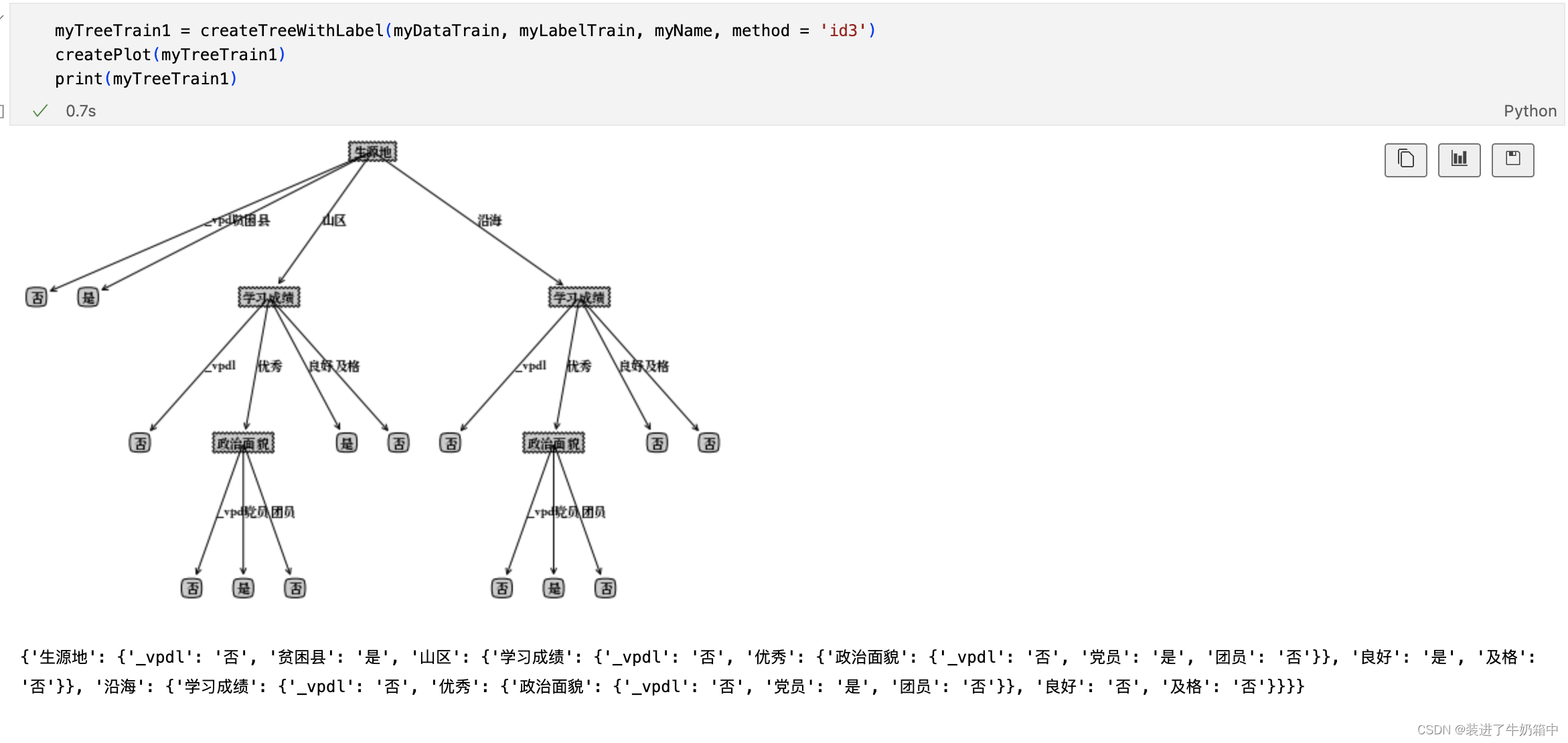
#选调生数据集的树结构
myTreeBeforePostPruning ={'生源地': {'_vpdl': '否', '贫困县': '是', '山区': {'学习成绩':
{'_vpdl': '否', '优秀': {'政治面貌': {'_vpdl': '否', '党员': '是', '团员': '否'}}, '良好': '是', '及格': '否'}}, '沿海':
{'学习成绩': {'_vpdl': '否', '优秀': {'政治面貌': {'_vpdl': '否', '党员': '是', '团员': '否'}}, '良好': '否', '及格': '否'}}}}
myTreePostPruning = treePostPruning(myTreeBeforePostPruning, myDataTest, myLabelTest, myName)
createPlot(convertTree(myTreeBeforePostPruning))
createPlot(myTreePostPruning)
运行结果
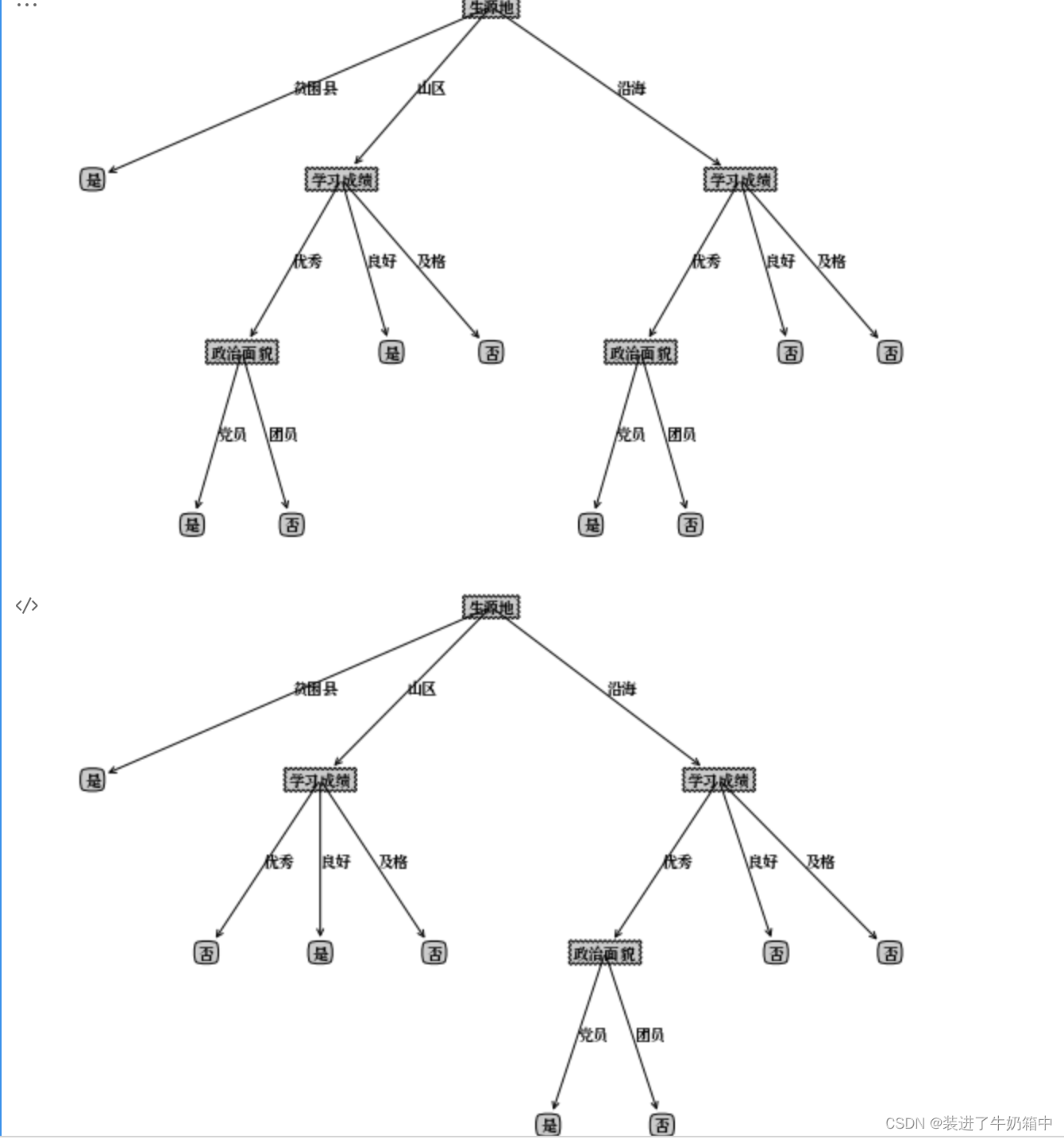
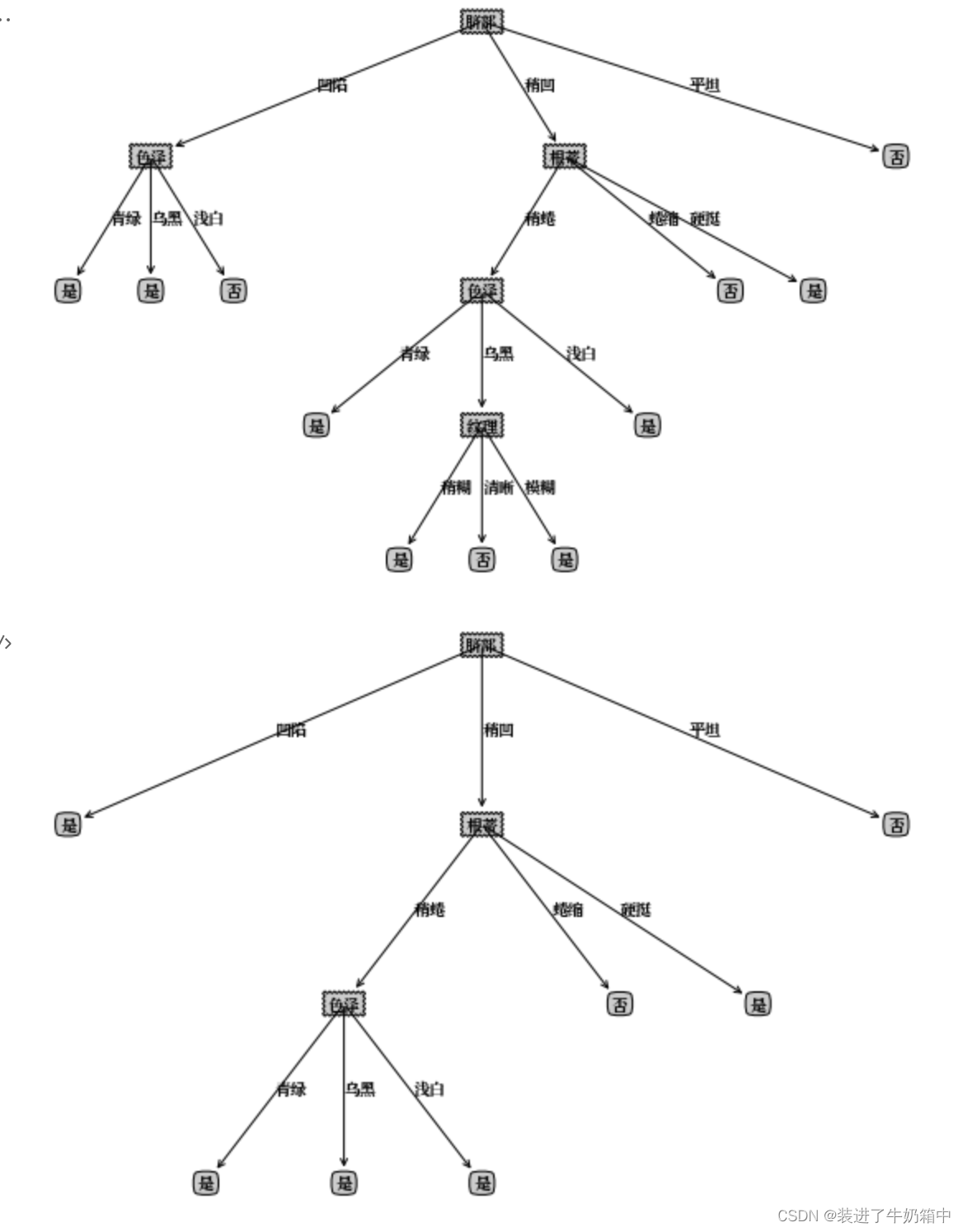
xgTreeBeforePostPruning = {"脐部": {"_vpdl": "是"
, '凹陷': {'色泽':{"_vpdl": "是", '青绿': '是', '乌黑': '是', '浅白': '否'}}
, '稍凹': {'根蒂':{"_vpdl": "是"
, '稍蜷': {'色泽': {"_vpdl": "是"
, '青绿': '是'
, '乌黑': {'纹理': {"_vpdl": "是"
, '稍糊': '是', '清晰': '否', '模糊': '是'}}
, '浅白': '是'}}
, '蜷缩': '否'
, '硬挺': '是'}}
, '平坦': '否'}}
xgTreePostPruning = treePostPruning(xgTreeBeforePostPruning, xgDataTest, xgLabelTest, xgName)
createPlot(convertTree(xgTreeBeforePostPruning))
createPlot(xgTreePostPruning)
运行结果
完整代码
链接: https://pan.baidu.com/s/1jBL03BtDhD0_LOMHSZHluw?pwd=b95u 提取码: b95u