一、VAR是什么?
以金融价格为例,传统的时间序列模型比如ARIMA,ARIMA-GARCH等,只分析价格自身的变化,模型的形式为:

其中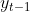 称为自身的滞后项。
称为自身的滞后项。
但是VAR模型除了分析自身滞后项的影响外,还分析其他相关因素的滞后项对未来值产生的影响,模型的形式为:

其中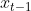 就是其他因子的滞后项。
就是其他因子的滞后项。
总结一下,就是可以把VAR模型看做是集合多元线性回归的优点(可以加入多个因子)以及时间序列模型的优点(可以分析滞后项的影响)的综合模型。
VAR其实是一类模型,以上是最基础的VAR模型形式,其他还有SVAR,CVAR,VECM,同统称为VAR类模型
1.引入库
代码如下(示例):
# 模型相关包
import statsmodels.api as sm
import statsmodels.stats.diagnostic
# 画图包
import matplotlib.pyplot as plt
# 其他包
import pandas as pd
import numpy as np
from sklearn.metrics import precision_score, recall_score, f1_score
import sklearn.metrics as mc
##########################画图############################################
# 在我的 notebook 里,要设置下面两行才能显示中文
plt.rcParams['font.family'] = ['sans-serif']
# 如果是在 PyCharm 里,只要下面一行,上面的一行可以删除
plt.rcParams['font.sans-serif'] = ['SimHei']
2.读入数据
代码如下(示例):
df = pd.read_excel(r'C:\Users\lidongming\Desktop\数据大赛数据\xgboost\宏观因子VAR.xlsx',index_col='指标名称')
df.index = pd.to_datetime(df.index) # 将字符串索引转换成时间索引
# 生成pd.Series对象
df
3.执行程序
#建立对象,1就是你自己定的滞后阶数,这里的矩阵一定要是正定的,就线性无关的
orgMod = sm.tsa.VARMAX(df,order=(1,0),exog=None)
#估计:就是模型
fitMod = orgMod.fit(maxiter=1000,disp=False)
# 打印统计结果
print(fitMod.summary())
# 获得模型残差
resid = fitMod.resid
result = {'fitMod':fitMod,'resid':resid}
YUCE=fitMod.predict()
YUCE
总结
VAR的阶数要看下面这个文章怎么去定义,下面这个文章讲的比较详细,这个方法我初步用于数据创新大赛的VAR预测宏观指标,加XGBOOST预测国债收益率。
这个是VAR模型的比较详细的文章