目录
前言
目标
使用scrapy shell测试目标
1 为什么
2 尝试直接进入tieba.baidu.com
3 准备header
3 测试爬取目标
编写item
编写pipeline
编写spider
1 编写start_requests与parse
2 编写invparse
前言
阅读本文中如果发现笔者有讲的不清楚的地方,可以查看scrapy的开发文档(第七节有网址)。
PS:本来的目标是微博,但由于微博的反爬措施太严格了(非要爬也不是不可以,但如果不用splash等包套娃最后八成要变成正则表达式大战),起不到作为示范的作用,我们把目标改成贴吧。
如果有把目标定为微博但惨遭新浪访客系统重定向的读者,可以试着带上抓包的cookie和header再次爬取,或者把爬虫伪装成搜索引擎爬虫。
目标
爬取贴吧首页推送的所有帖子(不包括ajax),并且获取文字评论。
使用scrapy shell测试目标
在开始编写爬虫之前,我们要先使用scrapy shell对爬取的目标进行测试,获取其路径。
1 为什么
如果在项目本体进行测试,每次测试都要运行整个项目。
在scrapy shell中测试,只需要输入爬取的url和测试语句。
2 尝试直接进入tieba.baidu.com
打开cmd,输入scrapy shell www.tieba.baidu.com,可以看到返回了:
2020-11-15 21:47:56 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://tieba.baidu.com/index.html> (referer: None)
状态码为200,链接也正常,输入view(response)让scrapy在浏览器中打开响应,确认页面是正常的。
3 准备header
保险起见,我们还是要准备header。
使用抓包工具(浏览器F12就可以)对贴吧进行抓包,获取header(请求头)。
在settings.py文件下增加USER-AGENT,放入一组UA头(可以使用我们之前介绍过的fake_useragent生成),例如:
USER_AGENT=[
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.517 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.124 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1623.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36'
]
在终端中进入scrapy shell声明header并赋值,然后输入scrapy.http.Request(url=”https://www.tieba.baidu.com”,headers=header)等待,可以看到返回了状态码200。在请求正常返回后,使用view(response)在浏览器中查看返回的页面。
3 测试爬取目标
接上一步,我们使用css选择器测试爬取目标。
浏览器打开贴吧首页,定位推荐贴的css位置,如下:

发现其中比较好定位的是class和rel,但经过比对发现贴吧上方的吧推荐也采用了相同的rel,所以我们用class的值进行定位。
输入response.css(".feed-item-link::attr(href)"),得到选择后的列表如下:
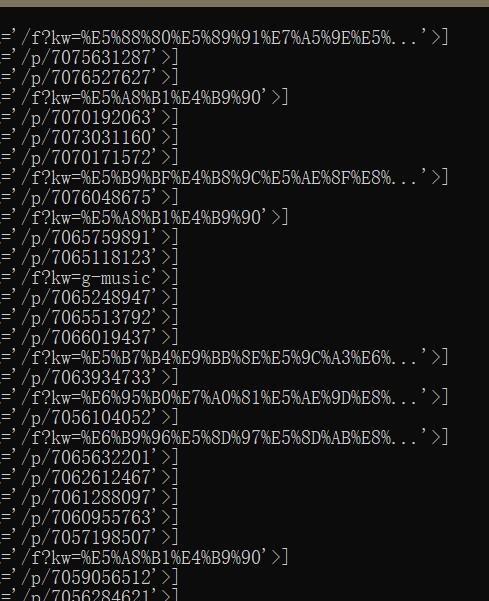
可以看到,在帖子链接里(p开头)仍然有吧链接(含有kw)。输入response.css(".feed-item-link.title::attr(href)")将元素的两个class都纳入选择条件中,然后使用extract()打印出所有的href属性,如下:

可以看到已经没有干扰项了。
输入response.css(“.feed-item-link.title::text”),并用extract()打印出所有内容,可以看到得出了所有的帖子标题。
打开首页推送中任意一个帖子,定位楼层的css位置,如下:

显而易见我们可以通过class进行定位。
输入response.css(“.d_post_content::text”),尝试获取楼层中的文字内容。分析结果,发现其长度与帖子的楼层数不符合,推测带有换行的楼层被分割成了多个内容。改为response.css(“.d_post_content.j_d_post_content”),将定位定在楼层文字的标签处,提取文字在parse中再做进一步处理。
接下来获取所有的层主名,对层主信息进行定位,输入response.css(“[alog-group=’p_author’]::text”),测试其长度比楼层数多2,推测是贴吧的表情昵称在文字昵称之间导致。对response.css(“[alog-group=’p_author’]”)测试,刚好等于楼层数。
最后,获取帖子的下一页url。观察DOM结构可以得知此url中没有特别的标签或者属性,也很难通过父节点定位,所以采用根据标签内容定位的方法。同时,由于css中没有针对标签内容的定位方式,我们采用xpath进行定位。输入response.xpath(“//*[@id='thread_theme_7']/div[1]/ul/li[1]/a[contains(text(),'下一页')]/@href”),定位成功。
至此,我们所有的目标定位成功。
编写item
在确认所有目标都可爬取后,我们就可以开始编写用于规范数据的item类了。
根据上一节中的爬取目标,我们可以整理出如下关系:

所以我们要获取的内容应该是帖子标题(字符串),楼层的作者和内容(列表->字典)。将每一个帖子抽象为一个item对象,则在项目下items.py文件中建立Item类TiebaItem如下所示:
class TiebaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()
content=scrapy.Field()
编写pipeline
在pipelines.py中,我们要实现的目标是:将每个传来的item分别保存到一个文件里,其文件名为帖子的标题。
class TiebaPipeline:
def __init__(self):
self.num=0
def process_item(self, item, spider):
Route="D://TheodorWebsiteWork/tieba/"
with open(Route+str(self.num)+item['title']+".txt","w+",encoding="utf-8",errors="ignore") as f: #加上num是为了防止重名,就怕真有这么巧的事
for i in item['content']:
for r in i.keys():
f.write(r+":\n")
f.write(i[r]+"\n") #写下每层数据
f.close() #关闭文件
self.num+=1
return item
在编写完pipeline后,不要忘记将其加入settings文件中:
ITEM_PIPELINES={
'start01.pipelines.TiebaPipeline':300
}
编写spider
最后,终于进入到我们的重点spider的编写了。在之前的测试中,我们能明显地将spider分为两部分:解析贴吧首页的,以及解析帖子页面的。在书写中,我们将这两类请求的解析器函数名定为parse与invparse。
1 编写start_requests与parse
由于是带头部的爬取,不能采用start_urls的形式简写。
def start_requests(self):
url="https://tieba.baidu.com"
return [Request(url=url,callback=self.parse,headers=self.header)]
这个链接进入贴吧的首页,对于此次请求的响应,我们要找出所有推荐帖的链接和标题,所以其解析器parse的书写如下:
def parse(self,response): #这一步不返回任何item
urllist=response.css(".feed-item-link.title::attr(href)") #帖子链接列表
namelist=response.css(".feed-item-link.title::text") #帖子名列表
for i in range(len(namelist)):
self.item.append(TiebaItem())
self.item[i]['title']=namelist[i].extract() #将帖子名存入item
self.item[i]['content']=[]
for r in urllist:
yield Request(response.urljoin(r.extract()),callback=self.invprase,headers=self.header) #链接生成为请求返回给engine
2 编写invparse
invprase用于帖子的解析,在含有下一页链接时返回其请求,在爬取完毕时返回item。
def invprase(self,response):
storeylist=response.css(".d_post_content.j_d_post_content") #楼层文字回复列表 #其实,这里再加进一步处理可以得到带有图文的回复
authorlist=response.css("[alog-group='p_author']") #楼层作者列表
nexturl=response.xpath("//*[@id='thread_theme_7']/div[1]/ul/li[1]/a[contains(text(),'下一页')]/@href") #下一页的位置,如果没有下一页了就为空列表
content=[]
for i in range(len(storeylist)):
text=""
s=storeylist[i].css("::text") #获取所有文本selector
for m in s:
text+=m.extract() #对每个文本selector,使用extract然后加在一起
author=""
a=authorlist[i].css("::text") #同上
for m in a:
author+=m.extract()
content.append({author:text}) #将作者与内容的字典存入item
self.item[self.index]['content']+=content
if nexturl!=[]: #存在下一页的情况下,当然,存在的情况下只有一个成员
yield Request(url=response.urljoin(nexturl[0].extract()),callback=self.invprase,headers=self.header)
else: #不存在下一页的情况下返回item了
yield self.item[self.index]
self.index+=1
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)