NLP领域,可以想象我们在做阅读理解的时候,我们在看文章的时候,往往是带着问题去寻找答案,所以文章中的每个部分是需要不同的注意力的。例如我们在做评论情感分析的时候,一些特定的情感词,例如amazing等,我们往往需要特别注意,因为它们是很重要的情感词,往往决定了评论者的情感。如下图(Yang et al., 何老师团队 HAN
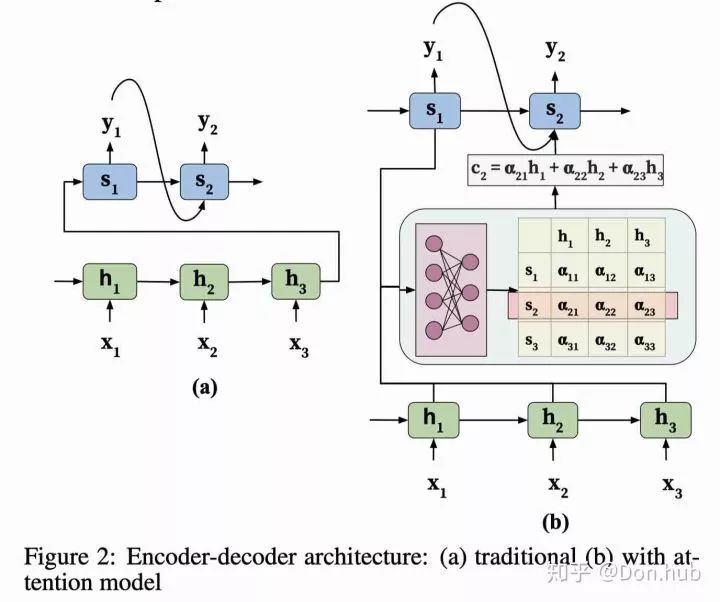
Seq2Seq model 是有encoder和decoder组成的,它主要的目的是将输入的文字翻译成目标文字。其中encoder和decoder都是RNN,(可以是RNN/LSTM/或者GRU或者是双向RNN)。模型将source的文字编码成一串固定长度的context编码,之后利用这段编码,使用decoder解码出具体的输出target。这种转化任务可以适用于:翻译,语音转化,对话生成等序列到序列的任务。
但是这种模型的缺点也很明显:- 首先所有的输入都编码成一个固定长度的context vector,这个长度多少合适呢?很难有个确切的答案,一个固定长度的vector并不能编码所有的上下文信息,导致的是我们很多的长距离依赖关系信息都消失了。- decoder在生成输出的时候,没有一个与encoder的输入的匹配机制,对于不同的输入进行不同权重的关注。- Second, it is unable to model alignment between input and output sequences, which is an essential aspect of structured output tasks such as translation or summarization [Young et al., 2018]. Intuitively, in sequence-to-sequence tasks, each output token is expected to be more influenced by some specific parts of the input sequence. However, decoder lacks any mechanism to selectively focus on relevant input tokens while generating each output token.
输入经过encoder之后得到的hidden states 的形状为 (batch_size, max_length, hidden_size) , decoder的 hidden state 形状为 (batch_size, hidden_size).
以下是被implement的等式:
This tutorial uses Bahdanau attention for the encoder. Let's decide on notation before writing the simplified form:
FC = Fully connected (dense) layer
EO = Encoder output
H = hidden state
X = input to the decoder
And the pseudo-code:
score = FC(tanh(FC(EO) + FC(H)))
attention weights = softmax(score, axis = 1). Softmax by default is applied on the last axis but here we want to apply it on the 1st axis, since the shape of score is (batch_size, max_length, hidden_size). Max_length is the length of our input. Since we are trying to assign a weight to each input, softmax should be applied on that axis.
context vector = sum(attention weights * EO, axis = 1). Same reason as above for choosing axis as 1.
embedding output = The input to the decoder X is passed through an embedding layer.
def call(self, query, values): # hidden shape == (batch_size, hidden size) # hidden_with_time_axis shape == (batch_size, 1, hidden size) # we are doing this to perform addition to calculate the score hidden_with_time_axis = tf.expand_dims(query, 1)
# score shape == (batch_size, max_length, 1) # we get 1 at the last axis because we are applying score to self.V # the shape of the tensor before applying self.V is (batch_size, max_length, units) score = self.V(tf.nn.tanh( self.W1(values) + self.W2(hidden_with_time_axis)))
Below is a summary table of several popular attention mechanisms and corresponding alignment score functions:
(*) Referred to as “concat” in Luong, et al., 2015 and as “additive attention” in Vaswani, et al., 2017. (^) It adds a scaling factor 1/n‾√1/n, motivated by the concern when the input is large, the softmax function may have an extremely small gradient, hard for efficient learning.
我们可以看看bert的self attention的实现的函数说明,其中如果from tensor= to tensor,那就是self attention
def attention_layer(from_tensor, to_tensor, attention_mask=None, num_attention_heads=1, size_per_head=512, query_act=None, key_act=None, value_act=None, attention_probs_dropout_prob=0.0, initializer_range=0.02, do_return_2d_tensor=False, batch_size=None, from_seq_length=None, to_seq_length=None): """Performs multi-headed attention from `from_tensor` to `to_tensor`. This is an implementation of multi-headed attention based on "Attention is all you Need". If `from_tensor` and `to_tensor` are the **same**, then this is self-attention. Each timestep in `from_tensor` attends to the corresponding sequence in `to_tensor`, and returns a fixed-with vector """
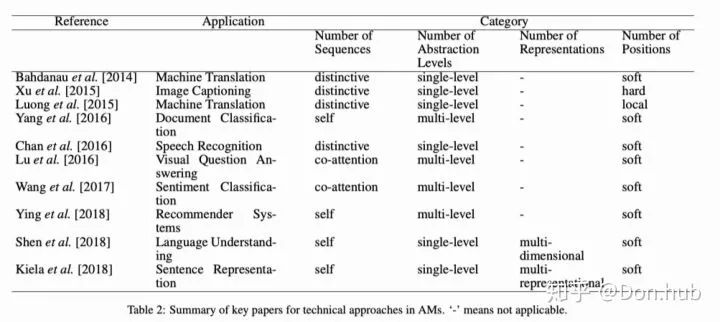
QA:problems have made use of attention to (i) better understand questions by focusing on relevant parts of the question [Hermann et al., 2015], (ii) store large amount of information using memory networks to help find answers [Sukhbaatar et al., 2015], and (iii) improve performance in visual QA task by modeling multi-modality in input using co-attention [Lu et al., 2016].
Multimedia Description(MD):is the task of generating a natural language text description of a multimedia input sequence which can be speech, image and video [Cho et al., 2015]. Similar to QA, here attention performs the function of finding relevant acoustic signals in speech input [Chorowski et al., 2015] or relevant parts of the input image [Xu et al., 2015] to predict the next word in caption. Further, Li et al. [2017] exploit the temporal and spatial structures of videos using multi-level attention for video captioning task. The lower abstraction level extracts specific regions within a frame and higher abstraction level focuses on small subset of frames selectively.
7.2 Classification
Document classification:HAN
Sentiment Analysis:
Similarly, in the sentiment analysis task, self attention helps to focus on the words that are important for determining the sentiment of input. A couple of approaches for aspect based sentiment classification by Wang et al. [2016] and Ma et al. [2018] incorporate additional knowledge of aspect related concepts into the model and use attention to appropriately weigh the concepts apart from the content itself. Sentiment analysis application has also seen multiple architectures being used with attention such as memory networks [Tang et al., 2016] and Transformer [Ambartsoumian and Popowich, 2018; Song et al., 2019].
7.3 Recommendation Systems
Multiple papers use self attention mechanism for finding the most relevant items in user’s history to improve item recommendations either with collaborative filtering framework [He et al., 2018; Shuai Yu, 2019], or within an encoderdecoder architecture for sequential recommendations [Kang and McAuley, 2018; Zhou et al., 2018].
Recently attention has been used in novel ways which has opened new avenues for research. Some interesting directions include smoother incorporation of external knowledge bases, pre-training embeddings and multi-task learning, unsupervised representational learning, sparsity learning and prototypical learning i.e. sample selection.




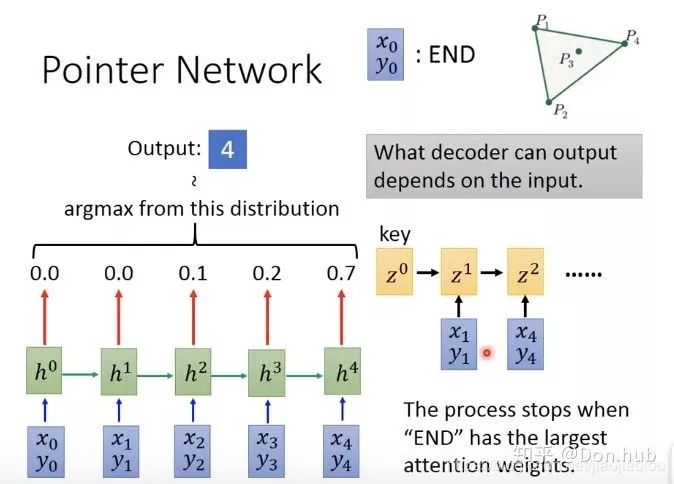
 是decoder的初始化hidden state,是随机初始化的,相比于seq2seq(他是用context vector作为decoder的hidden 初始化),
是decoder的初始化hidden state,是随机初始化的,相比于seq2seq(他是用context vector作为decoder的hidden 初始化),  是decoder的hidden states。
是decoder的hidden states。 代表的是第j个encoder位置的输出hidden states
代表的是第j个encoder位置的输出hidden states 代表的是第i个decoder的位置对对j个encoder位置的权重
代表的是第i个decoder的位置对对j个encoder位置的权重 是第i个decoder的位置的输出,就是经过hidden state输出之后再经过全连接层的输出
是第i个decoder的位置的输出,就是经过hidden state输出之后再经过全连接层的输出 代表的是第i个decoder的context vector,其实输出hidden output的加权求和
代表的是第i个decoder的context vector,其实输出hidden output的加权求和 这两个的concat结果
这两个的concat结果


 以及
以及  都是随机初始化,然后跟着模型一起训练的,score方法用的也是Dense方法,但是这边和NMT不同的是,他是self attention。
都是随机初始化,然后跟着模型一起训练的,score方法用的也是Dense方法,但是这边和NMT不同的是,他是self attention。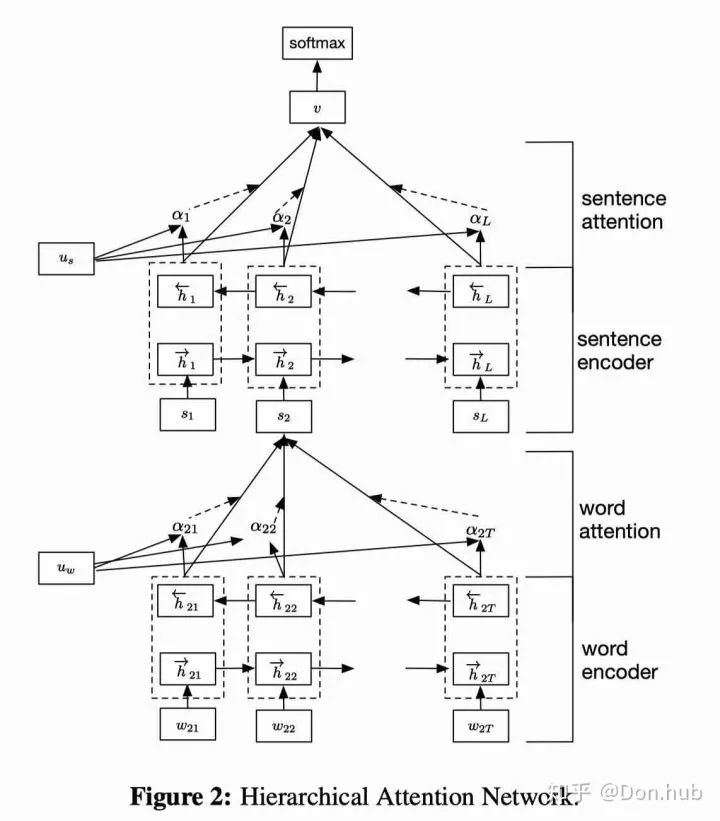
 最后输出的是
最后输出的是 
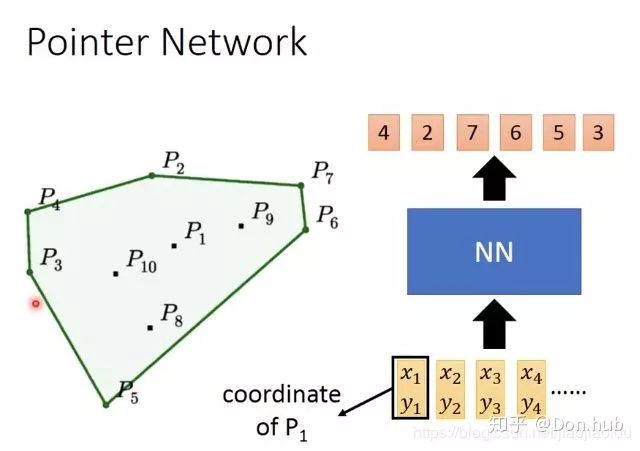
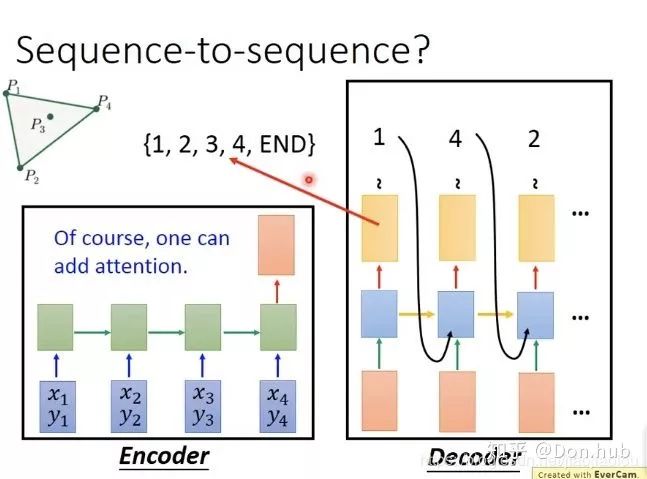
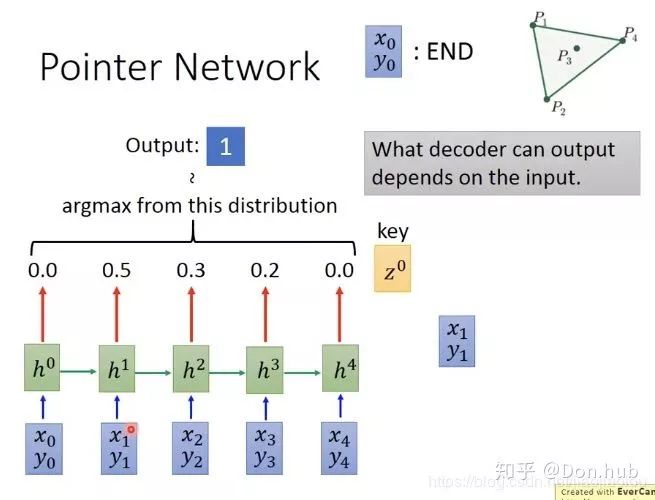
 点的概率最高
点的概率最高