一、内存管理简述
在Linux内核中,RAM会将其中一部分永远分配给内核,用来存放Linux内核源码以及一些静态的数据结构。而剩余部分则被称之为动态内存,是进程和内核本身所需的宝贵资源。事实上,整个系统的性能就取决于如何能高效地管理动态内存。因此,现在所有多任务操作系统都在优化对动态内存的使用,通俗讲就是,尽可能的做到当需要时分配,不需要时释放。
二、物理内存和虚拟内存
操作系统中存在虚拟内存和物理内存两种概念。在虚拟内存出现之前,程序寻址用的都是物理地址,因此程序能寻址的范围是有限的,具体程序可以寻址的范围有多大取决于CPU的地址线条数。
在内存作为宝贵资源的计算机中,为了充分利用和管理系统内存资源,Linux采用虚拟内存管理技术。虚拟内存为每个进程提供了一个一致的、私有的地址空间(每个进程拥有一片连续完整的内存空间),它让每个进程都产生了一种自己在独享内存的错觉,而这样的管理能更有效的减少内存中的出错。
首先虽然userspace 是0-3G 的地址空间, 但是这个实际上是虚拟的, userspace 进程无法直接去映射任何物理内存, 分配真正的物理页给进程完全是靠内核去做的, 所以内核必须在内核空间控制所有的物理内存。简单说 0-3G是虚拟的有很多份,3-4G就一份。
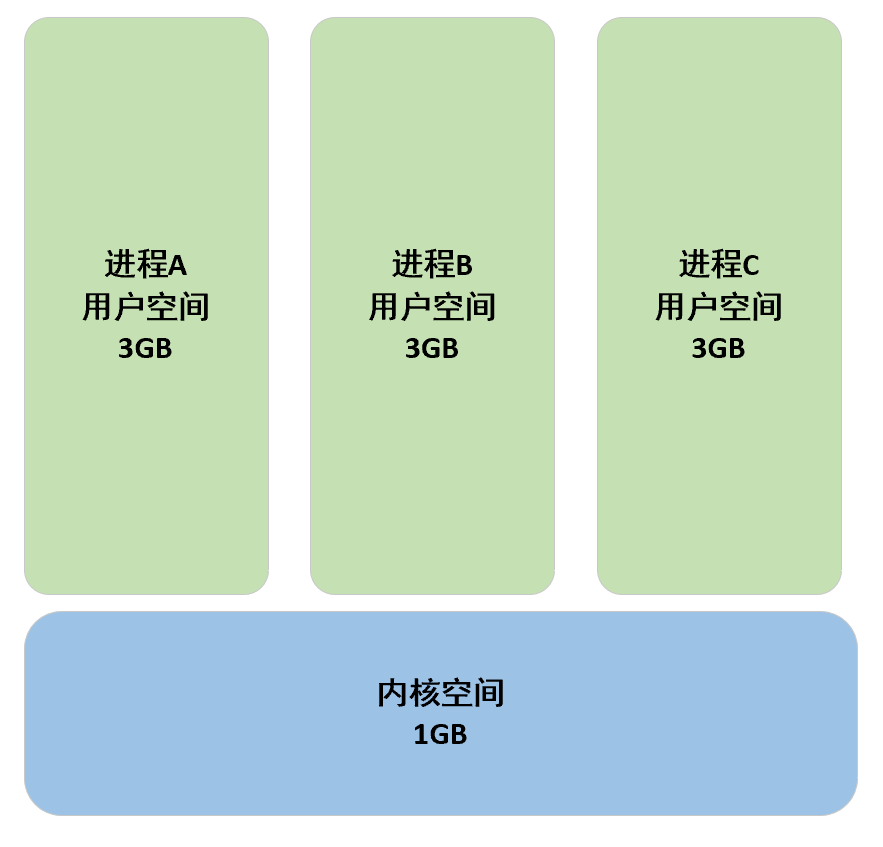
用户空间和内核空间的典型划分比例是3:1,当然,这也是可以配置的。
所有进程共享内核虚拟地址空间,每个进程拥有独立的用户虚拟地址空间(如下图),同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
三、用户虚拟地址空间布局
用户空间是用户进程所能访问的区域,每个进程都有自己独立的用户空间。用户进程通常只能访问用户空间的虚拟地址,只有在执行陷阱操作或系统调用时才能访问内核空间。
进程的用户虚拟地址空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。
linux上可以通过 cat /proc/pid/maps 或者 pmap pid 来查看某个进程的实际虚拟内存布局。
用户虚拟地址空间有两种布局,区别是内存映射区域的起始位置和增长方向不同。
(1)传统布局:内存映射区域自底向上增长,起始地址是TASK_UNMAPPED_BASE,每种处理器架构都要定义这个宏,ARM64架构定义为 TASK_SIZE/4。默认启用内存映射区域随机化,需要把起始地址加上一个随机值。传统布局的缺点是堆的最大长度受到限制,在32位系统中影响比较大,但是在64位系统中这不是问题。
(2)新布局:内存映射区域自顶向下增长,起始地址是(STACK_TOP − 栈的最大长度 − 间隙)。默认启用内存映射区域随机化,需要把起始地址减去一个随机值。

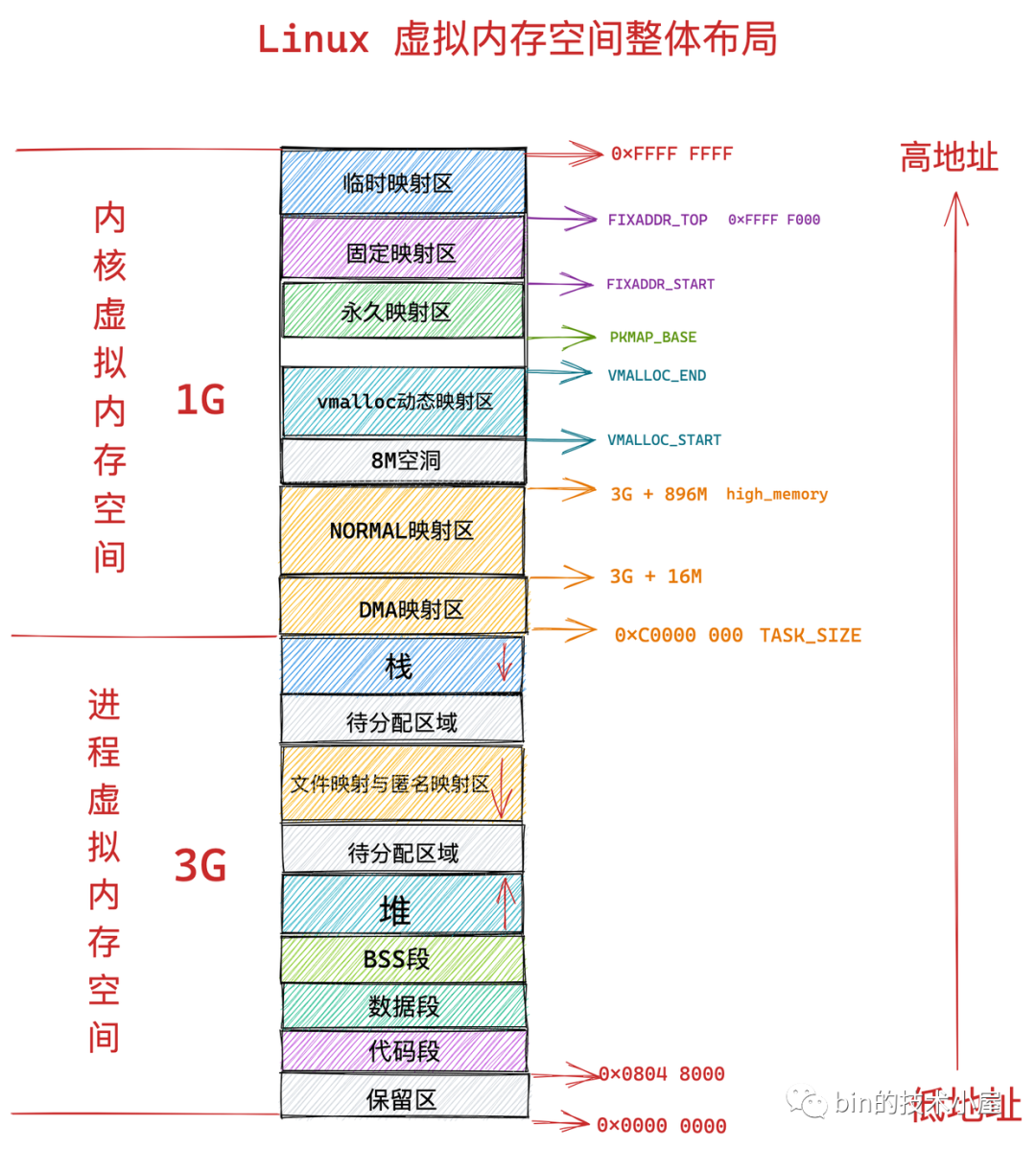
3.1、32 位机器上进程虚拟内存空间分布
在 32 位机器上,指针的寻址范围为 2^32,所能表达的虚拟内存空间为 4 GB。所以在 32 位机器上进程的虚拟内存地址范围为:0x0000 0000 - 0xFFFF FFFF。
其中用户态虚拟内存空间为 3 GB,虚拟内存地址范围为:0x0000 0000 - 0xC000 000 。
内核态虚拟内存空间为 1 GB,虚拟内存地址范围为:0xC000 000 - 0xFFFF FFFF。

0x0000 0000 到 0x0804 8000 这段虚拟内存地址是一段不可访问的保留区,因为在大多数操作系统中,数值比较小的地址通常被认为不是一个合法的地址,这块小地址是不允许访问的。比如在 C 语言中我们通常会将一些无效的指针设置为 NULL,指向这块不允许访问的地址。
保留区的上边就是代码段和数据段,它们是从程序的二进制文件中直接加载进内存中的,BSS 段中的数据也存在于二进制文件中,因为内核知道这些数据是没有初值的,所以在二进制文件中只会记录 BSS 段的大小,在加载进内存时会生成一段 0 填充的内存空间。
紧挨着 BSS 段的上边就是我们经常使用到的堆空间,我们程序在运行期间往往需要动态的申请内存,所以在虚拟内存空间中也需要一块区域来存放这些动态申请的内存,这块区域就叫做堆。注意这里的堆指的是 OS 堆并不是 JVM 中的堆。从图中的红色箭头我们可以知道在堆空间中地址的增长方向是从低地址到高地址增长。内核中使用 start_brk 标识堆的起始位置,brk 标识堆当前的结束位置。当堆申请新的内存空间时,只需要将 brk 指针增加对应的大小,回收地址时减少对应的大小即可。比如当我们通过 malloc 向内核申请很小的一块内存时(128K 之内),就是通过改变 brk 位置实现的。
堆空间的上边是一段待分配区域,用于扩展堆空间的使用。
接下来就来到了文件映射与匿名映射区域。我们的程序在运行过程中还需要依赖动态链接库,这些动态链接库以 .so 文件的形式存放在磁盘中,比如 C 程序中的 glibc,里边对系统调用进行了封装。glibc 库里提供的用于动态申请堆内存的 malloc 函数就是对系统调用 sbrk 和 mmap 的封装。这些动态链接库也有自己的对应的代码段,数据段,BSS 段,也需要一起被加载进内存中。还有用于内存文件映射的系统调用 mmap,会将文件与内存进行映射,那么映射的这块内存(虚拟内存)也需要在虚拟地址空间中有一块区域存储。这些动态链接库中的代码段,数据段,BSS 段,以及通过 mmap 系统调用映射的共享内存区,在虚拟内存空间的存储区域叫做文件映射与匿名映射区。
接下来就是栈空间了,在这里会保存函数运行过程所需要的局部变量以及函数参数等函数调用信息。栈空间中的地址增长方向是从高地址向低地址增长。每次进程申请新的栈地址时,其地址值是在减少的。在内核中使用 start_stack 标识栈的起始位置,RSP 寄存器中保存栈顶指针 stack pointer,RBP 寄存器中保存的是栈基地址。
在栈空间的下边也有一段待分配区域用于扩展栈空间,在栈空间的上边就是内核空间了,进程虽然可以看到这段内核空间地址,但是就是不能访问。
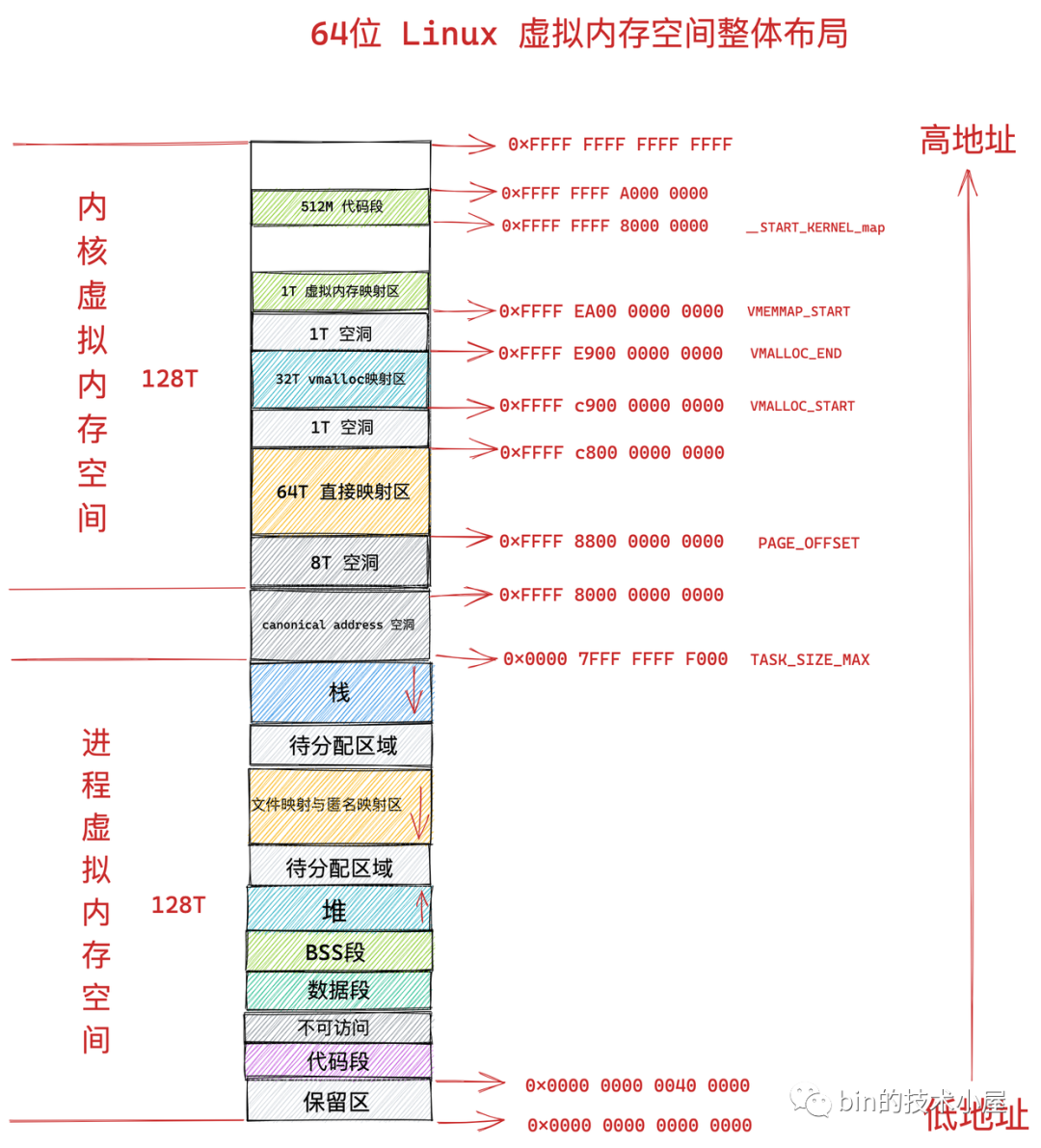
3.2、64 位机器上进程虚拟内存空间分布
我们知道在 32 位机器上,指针的寻址范围为 2^32,所能表达的虚拟内存空间为 4 GB。
在 64 位机器上,指针的寻址范围为 2^64,所能表达的虚拟内存空间为 16 EB 。
但事实上在目前的 64 位系统下只使用了 48 位来描述虚拟内存空间,寻址范围为 2^48 ,所能表达的虚拟内存空间为 256TB。
其中低 128 T 表示用户态虚拟内存空间,虚拟内存地址范围为:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 。(高 16 位全部为 0)
高 128 T 表示内核态虚拟内存空间,虚拟内存地址范围为:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 。(高 16 位全部为 1)
我们都知道在 64 位机器上的指针寻址范围为 2^64,但是在实际使用中我们只使用了其中的低 48 位来表示虚拟内存地址,那么这多出的高 16 位就形成了这个地址空洞。
这样一来,这多出的高 16 位就在用户态虚拟内存空间与内核态虚拟内存空间之间形成了一段 0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000 的地址空洞,我们把这个空洞叫做 canonical address 空洞。
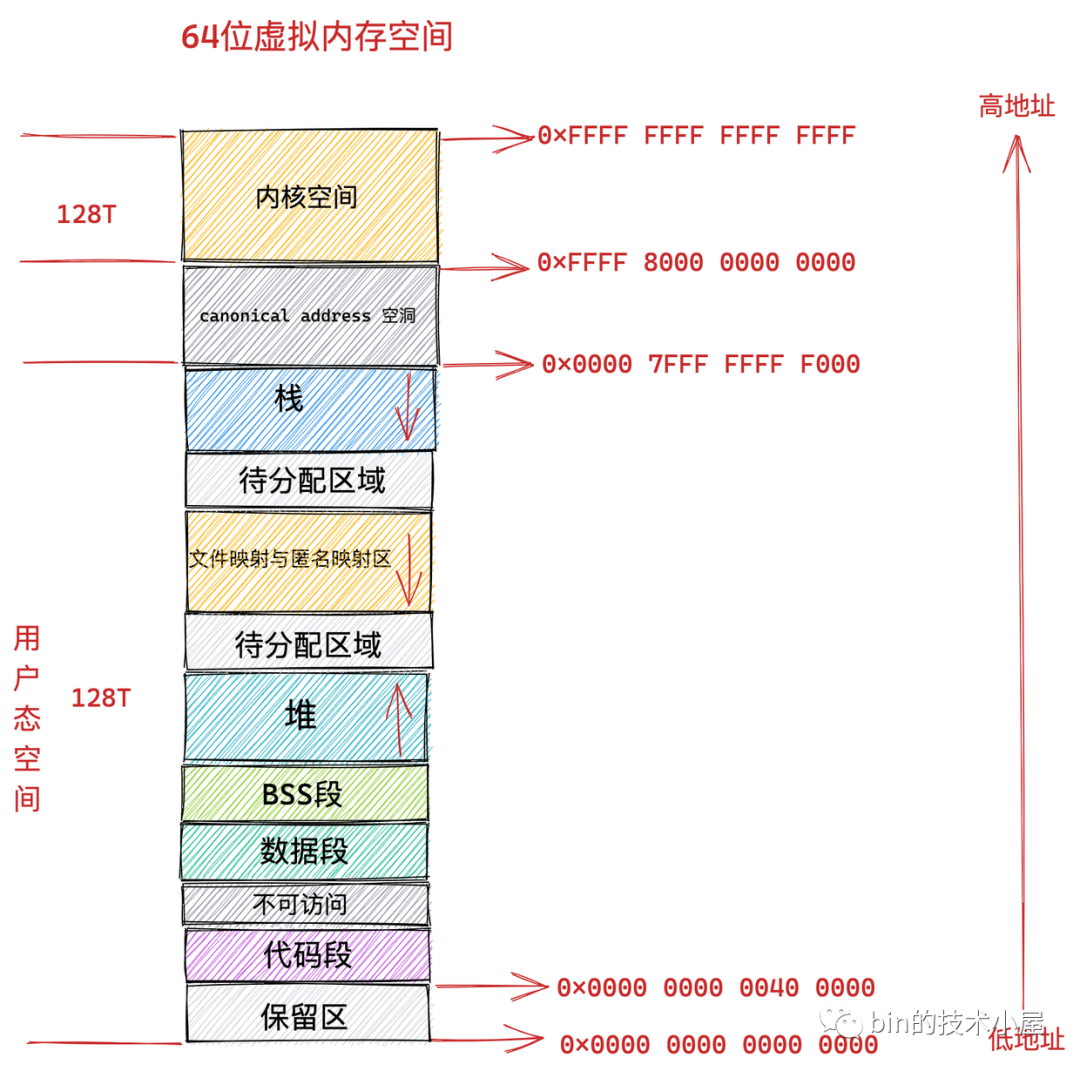
从上图中我们可以看出 64 位系统中的虚拟内存布局和 32 位系统中的虚拟内存布局大体上是差不多的。主要不同的地方有:
-
canonical address 空洞。在这段范围内的虚拟内存地址是不合法的,因为它的高 16 位既不全为 0 也不全为 1,不是一个 canonical address,所以称之为 canonical address 空洞。
-
在代码段跟数据段的中间还有一段不可以读写的保护段,它的作用是防止程序在读写数据段的时候越界访问到代码段,这个保护段可以让越界访问行为直接崩溃,防止它继续往下运行。
四、内核地址空间布局
内核接管所有的物理内存,但是内核的地址空间只有1G, 那么最多也就是直接映射1G的物理内存到内核空间,而且这1G空间还要保留一些做其它用途,DMA etc ,所以内核空间最多也无法映射1G的物理内存, 那么怎么办呢, 只好折中一下, 设定一个上限 HIGH_MEM(896M,应该是个经验值)内存低于这个上限就全部直接映射, 高于这个上限 就把剩余部分间接映射。
内核视角下的物理内存划分如下:

4.1、直接映射区
线性空间中从3G开始最大896M的区间,为直接内存映射区,该区域的线性地址和物理地址存在线性转换关系:线性地址=3G+物理地址。比如说,内核中某个变量地址为3G+24M,那么这个变量所在的物理地址必然是24M。
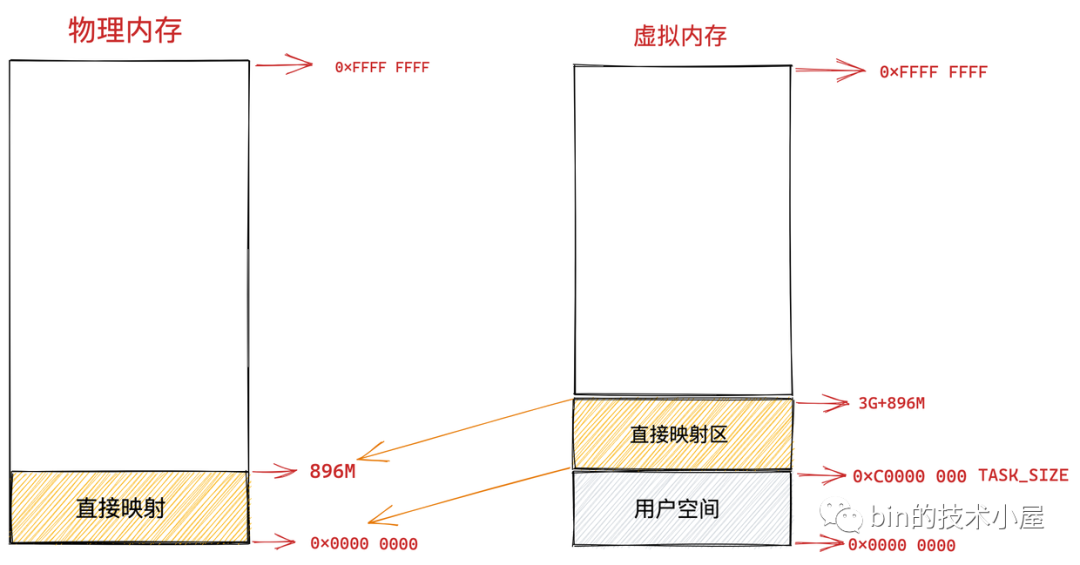
虽然这块区域中的虚拟地址是直接映射到物理地址上,但是内核在访问这段区域的时候还是走的虚拟内存地址,内核也会为这块空间建立映射页表。关于页表的概念笔者后续会为大家详细讲解,这里大家只需要简单理解为页表保存了虚拟地址到物理地址的映射关系即可。
明白了这个关系之后,我们接下来就看一下这块直接映射区域在物理内存中究竟存的是什么内容~~~
在这段 896M 大小的物理内存中,前 1M 已经在系统启动的时候被系统占用,1M 之后的物理内存存放的是内核代码段,数据段,BSS 段(这些信息起初存放在 ELF格式的二进制文件中,在系统启动的时候被加载进内存)。
我们可以通过 cat /proc/iomem 命令查看具体物理内存布局情况。
当我们使用 fork 系统调用创建进程的时候,内核会创建一系列进程相关的描述符,比如之前提到的进程的核心数据结构 task_struct,进程的内存空间描述符 mm_struct,以及虚拟内存区域描述符 vm_area_struct 等。
这些进程相关的数据结构也会存放在物理内存前 896M 的这段区域中,当然也会被直接映射至内核态虚拟内存空间中的 3G -- 3G + 896m 这段直接映射区域中。
当进程被创建完毕之后,在内核运行的过程中,会涉及内核栈的分配,内核会为每个进程分配一个固定大小的内核栈(一般是两个页大小,依赖具体的体系结构),每个进程的整个调用链必须放在自己的内核栈中,内核栈也是分配在直接映射区。
与进程用户空间中的栈不同的是,内核栈容量小而且是固定的,用户空间中的栈容量大而且可以动态扩展。内核栈的溢出危害非常巨大,它会直接悄无声息的覆盖相邻内存区域中的数据,破坏数据。
通过以上内容的介绍我们了解到内核虚拟内存空间最前边的这段 896M 大小的直接映射区如何与物理内存进行映射关联,并且清楚了直接映射区主要用来存放哪些内容。
写到这里,笔者觉得还是有必要再次从功能划分的角度为大家介绍下这块直接映射区域。
我们都知道内核对物理内存的管理都是以页为最小单位来管理的,每页默认 4K 大小,理想状况下任何种类的数据页都可以存放在任何页框中,没有什么限制。比如:存放内核数据,用户数据,缓冲磁盘数据等。
但是实际的计算机体系结构受到硬件方面的限制制约,间接导致限制了页框的使用方式。
比如在 X86 体系结构下,ISA 总线的 DMA (直接内存存取)控制器,只能对内存的前16M 进行寻址,这就导致了 ISA 设备不能在整个 32 位地址空间中执行 DMA,只能使用物理内存的前 16M 进行 DMA 操作。
因此直接映射区的前 16M 专门让内核用来为 DMA 分配内存,这块 16M 大小的内存区域我们称之为 ZONE_DMA。
用于 DMA 的内存必须从 ZONE_DMA 区域中分配。
而直接映射区中剩下的部分也就是从 16M 到 896M(不包含 896M)这段区域,我们称之为 ZONE_NORMAL。从字面意义上我们可以了解到,这块区域包含的就是正常的页框(使用没有任何限制)。
ZONE_NORMAL 由于也是属于直接映射区的一部分,对应的物理内存 16M 到 896M 这段区域也是被直接映射至内核态虚拟内存空间中的 3G + 16M 到 3G + 896M 这段虚拟内存上。
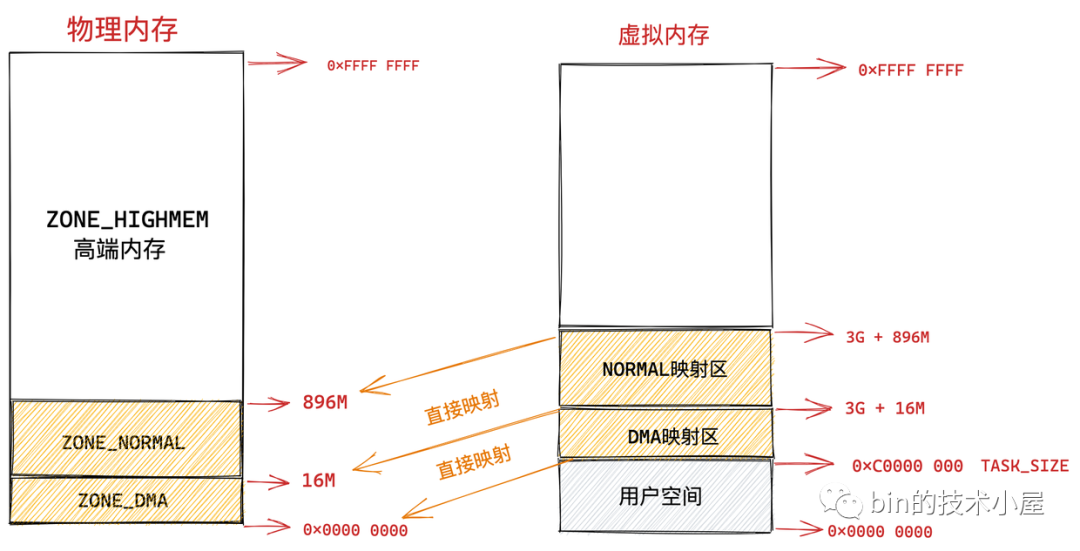
注意这里的 ZONE_DMA 和 ZONE_NORMAL 是内核针对物理内存区域的划分。
现在物理内存中的前 896M 的区域也就是前边介绍的 ZONE_DMA 和 ZONE_NORMAL 区域到内核虚拟内存空间的映射笔者就为大家介绍完了,它们都是采用直接映射的方式,一比一就行映射。
4.2、高端内存(ZONE_HIGHMEM 区域)
物理内存 896M 以上的区域被内核划分为 ZONE_HIGHMEM 区域,我们称之为高端内存。
我们的物理内存假设为 4G,高端内存区域为 4G - 896M = 3200M,那么这块 3200M 大小的 ZONE_HIGHMEM 区域该如何映射到内核虚拟内存空间中呢?
由于内核虚拟内存空间中的前 896M 虚拟内存已经被直接映射区所占用,而在 32 体系结构下内核虚拟内存空间总共也就 1G 的大小,这样一来内核剩余可用的虚拟内存空间就变为了 1G - 896M = 128M。
显然物理内存中 3200M 大小的 ZONE_HIGHMEM 区域无法继续通过直接映射的方式映射到这 128M 大小的虚拟内存空间中。
这样一来物理内存中的 ZONE_HIGHMEM 区域就只能采用动态映射的方式映射到 128M 大小的内核虚拟内存空间中,也就是说只能动态的一部分一部分的分批映射,先映射正在使用的这部分,使用完毕解除映射,接着映射其他部分。
知道了 ZONE_HIGHMEM 区域的映射原理,我们接着往下看这 128M 大小的内核虚拟内存空间究竟是如何布局的?
4.2.1、 vmalloc 动态映射区
内核虚拟内存空间中的 3G + 896M 这块地址在内核中定义为 high_memory,high_memory 往上有一段 8M 大小的内存空洞。空洞范围为:high_memory 到 VMALLOC_START 。
VMALLOC_START 定义在内核源码 /arch/x86/include/asm/pgtable_32_areas.h 文件中:
-
#define VMALLOC_OFFSET (8 * 1024 * 1024)
-
-
#define VMALLOC_START ((unsigned long)high_memory + VMALLOC_OFFSET)
-
-
-
# define VMALLOC_END (PKMAP_BASE - 2 * PAGE_SIZE)
-
-
# define VMALLOC_END (LDT_BASE_ADDR - 2 * PAGE_SIZE)
-
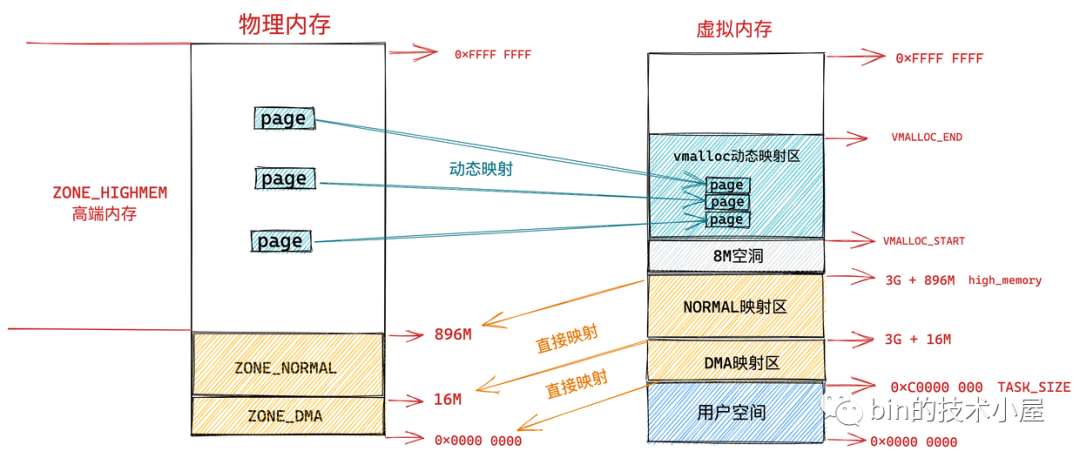
和用户态进程使用 malloc 申请内存一样,在这块动态映射区内核是使用内核函数 vmalloc 进行内存分配。由于之前介绍的动态映射的原因,vmalloc 分配的内存在虚拟内存上是连续的,但是物理内存是不连续的。通过页表来建立物理内存与虚拟内存之间的映射关系,从而可以将不连续的物理内存映射到连续的虚拟内存上。
由于 vmalloc 获得的物理内存页是不连续的,因此它只能将这些物理内存页一个一个地进行映射,在性能开销上会比直接映射大得多。
4.2.2、 永久映射区

而在 PKMAP_BASE 到 FIXADDR_START 之间的这段空间称为永久映射区。在内核的这段虚拟地址空间中允许建立与物理高端内存的长期映射关系。比如内核通过 alloc_pages() 函数在物理内存的高端内存中申请获取到的物理内存页,这些物理内存页可以通过调用 kmap 映射到永久映射区中。
LAST_PKMAP 表示永久映射区可以映射的页数限制。
-
-
((LDT_BASE_ADDR - PAGE_SIZE) & PMD_MASK)
-
-
4.2.3、固定映射区

内核虚拟内存空间中的下一个区域为固定映射区,区域范围为:FIXADDR_START 到 FIXADDR_TOP。
FIXADDR_START 和 FIXADDR_TOP 定义在内核源码 /arch/x86/include/asm/fixmap.h 文件中:
-
#define FIXADDR_START (FIXADDR_TOP - FIXADDR_SIZE)
-
-
extern
unsigned
long __FIXADDR_TOP;
// 0xFFFF F000
-
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
在固定映射区中的虚拟内存地址可以自由映射到物理内存的高端地址上,但是与动态映射区以及永久映射区不同的是,在固定映射区中虚拟地址是固定的,而被映射的物理地址是可以改变的。也就是说,有些虚拟地址在编译的时候就固定下来了,是在内核启动过程中被确定的,而这些虚拟地址对应的物理地址不是固定的。采用固定虚拟地址的好处是它相当于一个指针常量(常量的值在编译时确定),指向物理地址,如果虚拟地址不固定,则相当于一个指针变量。
那为什么会有固定映射这个概念呢 ? 比如:在内核的启动过程中,有些模块需要使用虚拟内存并映射到指定的物理地址上,而且这些模块也没有办法等待完整的内存管理模块初始化之后再进行地址映射。因此,内核固定分配了一些虚拟地址,这些地址有固定的用途,使用该地址的模块在初始化的时候,将这些固定分配的虚拟地址映射到指定的物理地址上去。
4.2.4、固定映射区 临时映射区
在内核虚拟内存空间中的最后一块区域为临时映射区,那么这块临时映射区是用来干什么的呢?

笔者在之前文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 的 “ 12.3 iov_iter_copy_from_user_atomic ” 小节中介绍在 Buffered IO 模式下进行文件写入的时候,在下图中的第四步,内核会调用 iov_iter_copy_from_user_atomic 函数将用户空间缓冲区 DirectByteBuffer 中的待写入数据拷贝到 page cache 中。

但是内核又不能直接进行拷贝,因为此时从 page cache 中取出的缓存页 page 是物理地址,而在内核中是不能够直接操作物理地址的,只能操作虚拟地址。
那怎么办呢?所以就需要使用 kmap_atomic 将缓存页临时映射到内核空间的一段虚拟地址上,这段虚拟地址就位于内核虚拟内存空间中的临时映射区上,然后将用户空间缓存区 DirectByteBuffer 中的待写入数据通过这段映射的虚拟地址拷贝到 page cache 中的相应缓存页中。这时文件的写入操作就已经完成了。
由于是临时映射,所以在拷贝完成之后,调用 kunmap_atomic 将这段映射再解除掉。
-
size_t iov_iter_copy_from_user_atomic(struct page *page,
-
struct iov_iter *i,
unsigned
long offset,
size_t bytes)
-
-
// 将缓存页临时映射到内核虚拟地址空间的临时映射区中
-
char *kaddr =
kmap_atomic(page),
-
-
// 将用户缓存区 DirectByteBuffer 中的待写入数据拷贝到文件缓存页中
-
iterate_all_kinds(i, bytes, v,
-
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
-
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
-
-
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
-
-
// 解除内核虚拟地址空间与缓存页之间的临时映射,这里映射只是为了临时拷贝数据用
-
-
-
五、总结
放两个图总结下吧
五、linux内存管理的组织逻辑
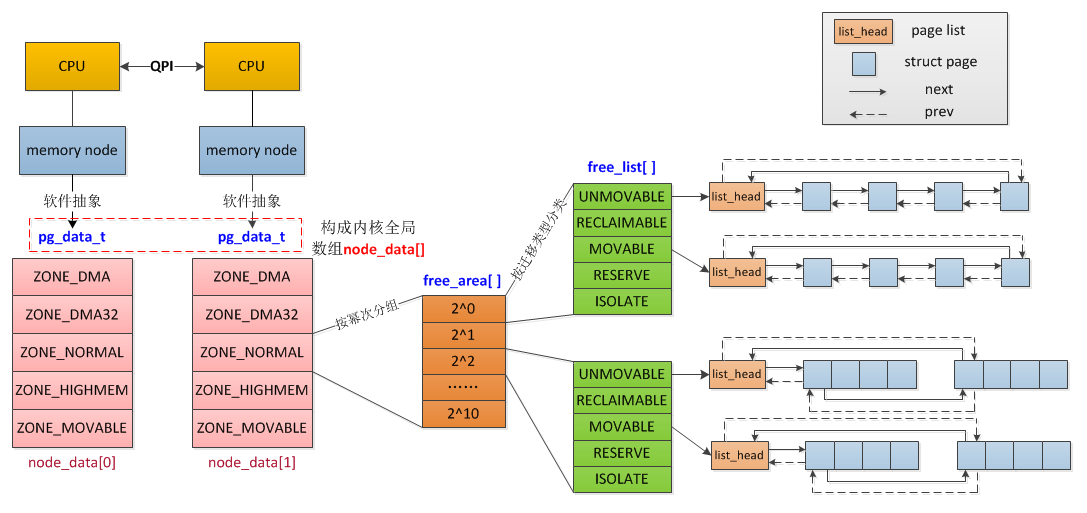
对于物理内存内存,linux对内存的组织逻辑从上到下依次是:node,zone,page,这些page是根据buddy分配算法组织的,看下面两张图:

上面的概念做下简单的介绍:
-
Node:每个CPU下的本地内存节点就是一个Node,如果是UMA架构下,就只有一个Node0,在NUMA架构下,会有多个Node
-
Zone:每个Node会划分很多域Zone,大概有下面这些:
- ZONE_DMA:定义适合DMA的内存域,该区域的长度依赖于处理器类型。比如ARM所有地址都可以进行DMA,所以该值可以很大,或者干脆不定义DMA类型的内存域。而在IA-32的处理器上,一般定义为16M。
- ZONE_DMA32:只在64位系统上有效,为一些32位外设DMA时分配内存。如果物理内存大于4G,该值为4G,否则与实际的物理内存大小相同。
- ZONE_NORMAL:定义可直接映射到内核空间的普通内存域。在64位系统上,如果物理内存小于4G,该内存域为空。而在32位系统上,该值最大为896M。
- ZONE_HIGHMEM:只在32位系统上有效,标记超过896M范围的内存。在64位系统上,由于地址空间巨大,超过4G的内存都分布在ZONE_NORMA内存域。
- ZONE_MOVABLE:伪内存域,为了实现减小内存碎片的机制。
- 分配价值链
- 除了只能在某个区域分配的内存(比如ZONE_DMA),普通的内存分配会有一个“价值”的层次结构,按分配的“廉价度”依次为:ZONE_HIGHMEM > ZONE_NORMAL > ZONE_DMA。
- 即内核在进行内存分配时,优先从高端内存进行分配,其次是普通内存,最后才是DMA内存
-
Page:zone下面就是真正的内存页了,每个页基础大小是4K,他们维护在一个叫free_area的数组结构中
- order:数组的index,也叫order,实际对应的是page的大小,比如order为0,那么就是一堆1个空闲页(4K)组成的链表,order为1,就是一堆2个空闲页(8K)组成的链表,order为2,就是一堆4个空闲页(16K)组成的链表
overcommit机制
Memory Overcommit的意思是操作系统承诺给进程的内存大小超过了实际可用的内存。
在实际申请内存的时候,比如申请1G,并不会在物理区域中分配1G的真实物理内存,而是分配1G的虚拟内存,等到需要的时候才去真正申请物理内存,也就是说申请不等于分配
所以说,可以申请比物理内存实际大的内存,也就是overcommit,这样会面临一个问题,就是当真的需要这么多内存的时候怎么办—>oom killer!
vm.overcommit_memory 接受三种值:
- 0 – Heuristic overcommit handling. 这是缺省值,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存
- 1 – Always overcommit. 允许overcommit,对内存申请来者不拒。
- 2 – Don’t overcommit. 禁止overcommit。
关于禁止overcommit (vm.overcommit_memory=2) ,需要知道的是,怎样才算是overcommit呢?kernel设有一个阈值,申请的内存总数超过这个阈值就算overcommit,在/proc/meminfo中可以看到这个阈值的大小:
| 1 2 3 |
# grep -i commit /proc/meminfo CommitLimit: 5967744 kB Committed_AS: 5363236 kB |
CommitLimit 就是overcommit的阈值,申请的内存总数超过CommitLimit的话就算是overcommit。
这个阈值是如何计算出来的呢?它既不是物理内存的大小,也不是free memory的大小,它是通过内核参数vm.overcommit_ratio或vm.overcommit_kbytes间接设置的,公式如下:
【CommitLimit = (Physical RAM * vm.overcommit_ratio / 100) + Swap】
注:
vm.overcommit_ratio 是内核参数,缺省值是50,表示物理内存的50%。如果你不想使用比率,也可以直接指定内存的字节数大小,通过另一个内核参数 vm.overcommit_kbytes 即可;
如果使用了huge pages,那么需要从物理内存中减去,公式变成:
CommitLimit = ([total RAM] – [total huge TLB RAM]) * vm.overcommit_ratio / 100 + swap
参见What is the formula to calculate "CommitLimit" value on Red Hat Enterprise Linux 5 and 6 ? - Red Hat Customer Portal
/proc/meminfo中的 Committed_AS 表示所有进程已经申请的内存总大小,(注意是已经申请的,不是已经分配的),如果 Committed_AS 超过 CommitLimit 就表示发生了 overcommit,超出越多表示 overcommit 越严重。Committed_AS 的含义换一种说法就是,如果要绝对保证不发生OOM (out of memory) 需要多少物理内存。
“sar -r”是查看内存使用状况的常用工具,它的输出结果中有两个与overcommit有关,kbcommit 和 %commit:
kbcommit对应/proc/meminfo中的 Committed_AS;
%commit的计算公式并没有采用 CommitLimit作分母,而是Committed_AS/(MemTotal+SwapTotal),意思是_内存申请_占_物理内存与交换区之和_的百分比。
-
-
-
05:00:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
-
-
05:10:01 PM 160576 3648460 95.78 0 1846212 4939368 62.74 1390292 1854880 4
ref:
一步一图带你深入理解 Linux 物理内存管理 - 掘金
一步一图带你深入理解 Linux 虚拟内存管理 - 掘金
内存管理 | 基础一 - 知乎
oom killer 详解 - xibuhaohao - 博客园
/proc/meminfo分析(一)
理解Linux的memory overcommit | Linux Performance
896M 的谜思_superwiles的博客-CSDN博客
物理内存低于896M各个区到底是怎么映射的_牛哥的技术博客_51CTO博客