目录
步骤
第一步:安装 Anaconda 和 Pycharm 软件
第二步:下载安装CUDA11.3
(1)首先查看自己电脑GPU版本
方式一:搜索框输入nvidia,打开nvidia控制面板
方式二:win+R打开cmd,输入nvidia-smi
(2)根据这个链接查看自己对应的cuda版本
(3)安装
第三步:下载GPU版本下的pytorch和pytorchvision
第四步:验证以上步骤全部安装成功
步骤
如果要使用GPU进行机器学习的训练,那么首先需要支持训练的显卡及驱动即正确安装CUDA、CUDNN,最重要的一点是需要与驱动对应的torch GPU版本,否则大概率使用torch.cuda.is_available()命令检查GPU是否可用时得到False。
检查显卡-显卡驱动CUDA适配版本-下载Anaconda-下载CUDA-检查CUDA是否安装好-下载CuDNN-下载GPU版本的pytorch-pycharm中调试环境-大功告成
第一步:安装 Anaconda 和 Pycharm 软件
如果已经安装好,这一步可忽略。
Anaconda下载可以直接在网上搜教程,很全,都可以用。
下载地址:Anaconda | Individual Edition
推荐使用清华的镜像
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
(1)可以直接从 Anaconda官网
下载,但因为Anaconda的服务器在国外,所以下载速度会很慢,这里 推荐使用清华的镜像
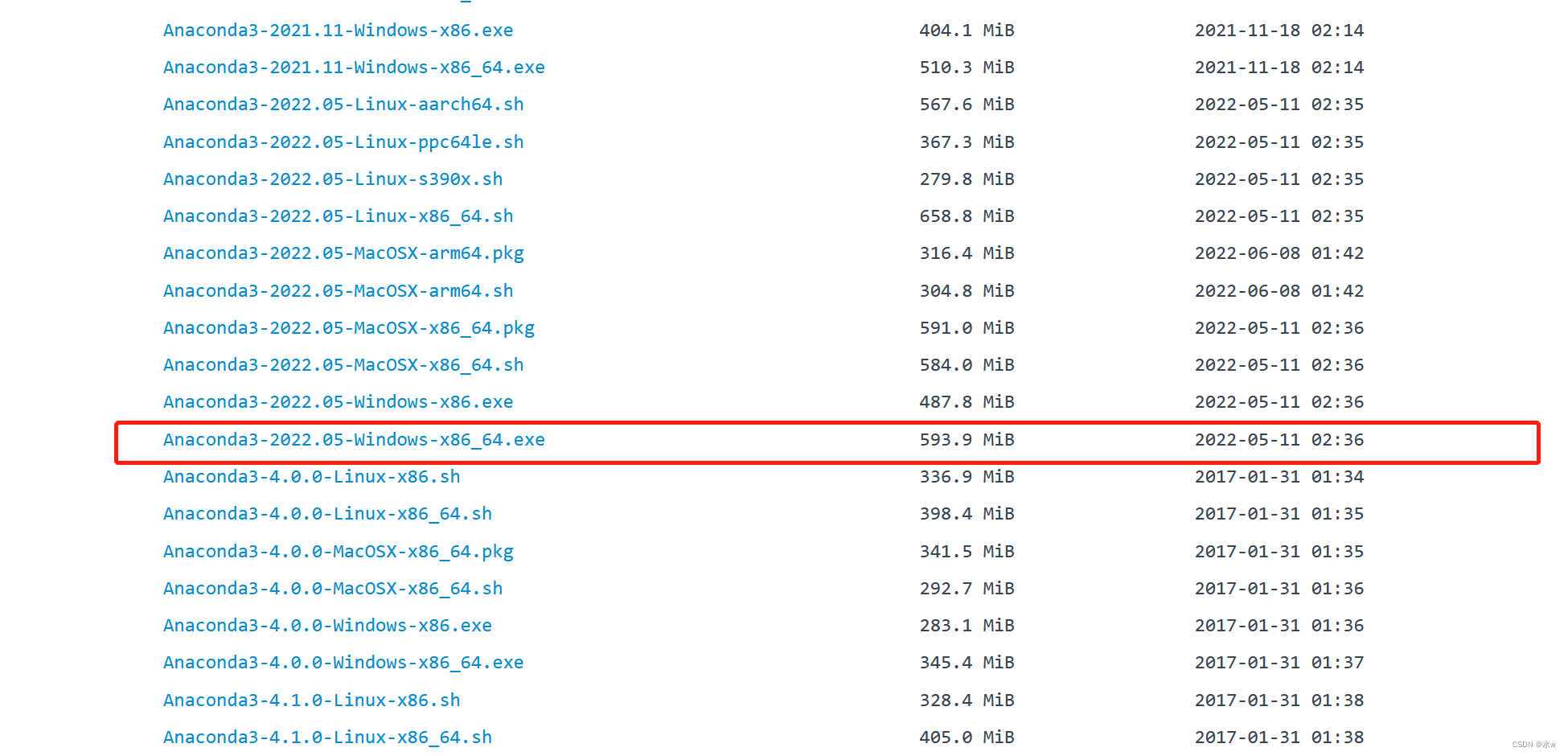
来下载。选择合适你的版本下载,这里选择
Anaconda2022.05-Windowsx86_
64.exe
版本。
(2)
第二步:下载安装CUDA11.3
- cuda: Compute Unified Device Architecture,是一种有NVIDIA推出的通用并行计算架构, 该架构使GPU能够解决复杂的计算问题。
- cudnn: 是NVIDIA 推出的用于深度神经网络的GPU加速库,他强调性能,易用性和低内存开销。
- cuda和cudnn的关系: cudnn是基于cuda架构开发的专门用于深度神经网络的GPU加速库。cuda可以理解为一个大的商圈,但这个商圈是空的,还未装修。cudnn可以理解为装修后的房间,例如负一楼专门针对游乐(深度神经网络)装修成大型游乐厂。
详细了解可参考大神的文章
https://blog.csdn.net/u014380165/article/details/77340765
查看对应版本的CUDA,这部非常关键!!!请一定要重视,避免之后多次重装。
(1)首先查看自己电脑GPU版本
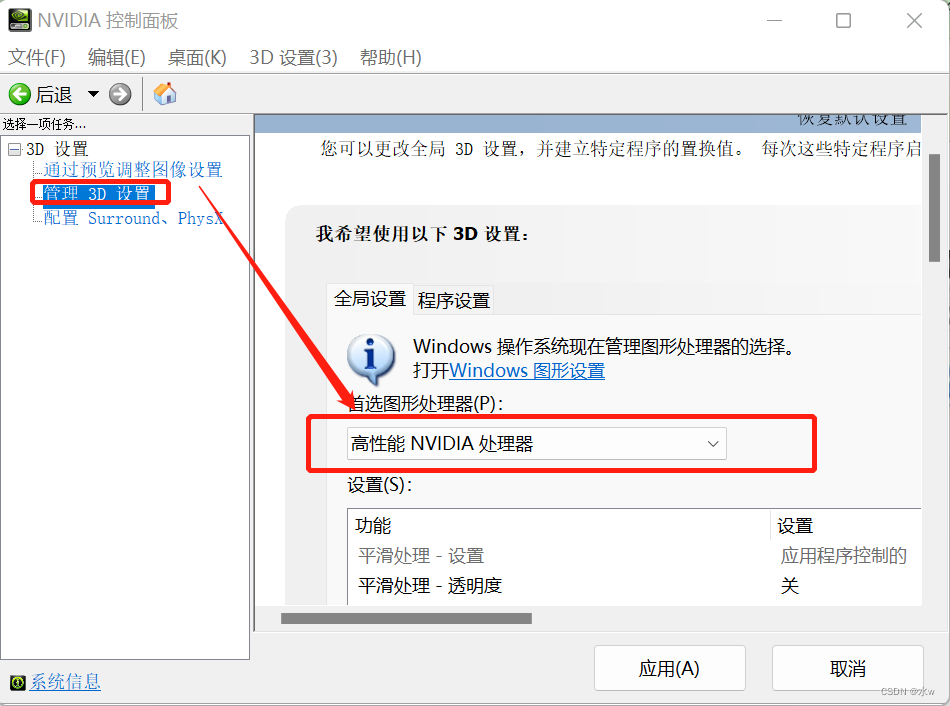
方式一:搜索框输入nvidia,打开nvidia控制面板
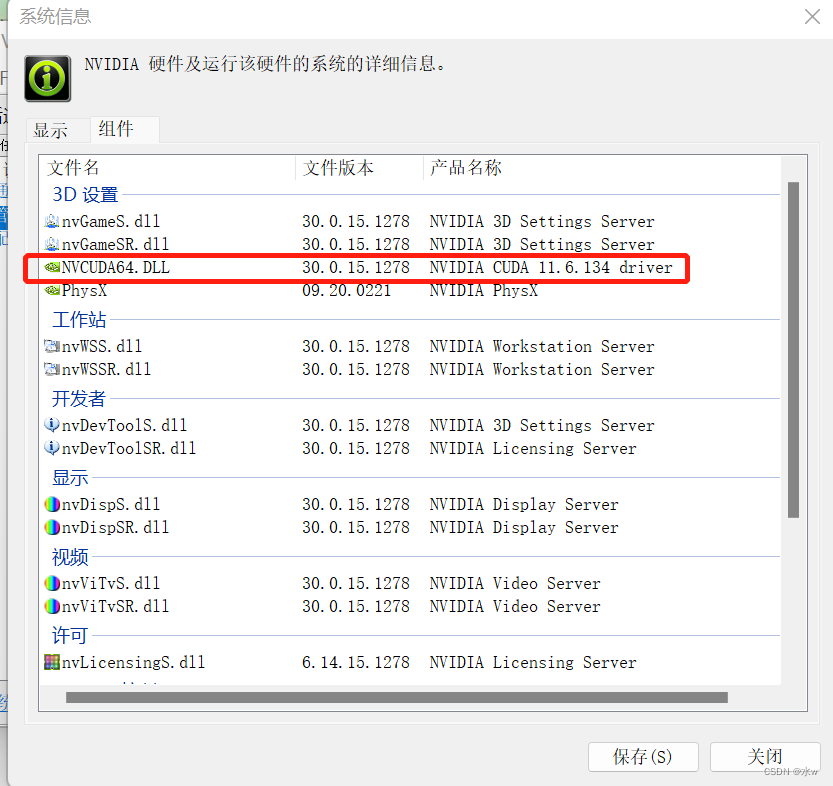
方式二:win+R打开cmd,输入nvidia-smi
nvidia-smi
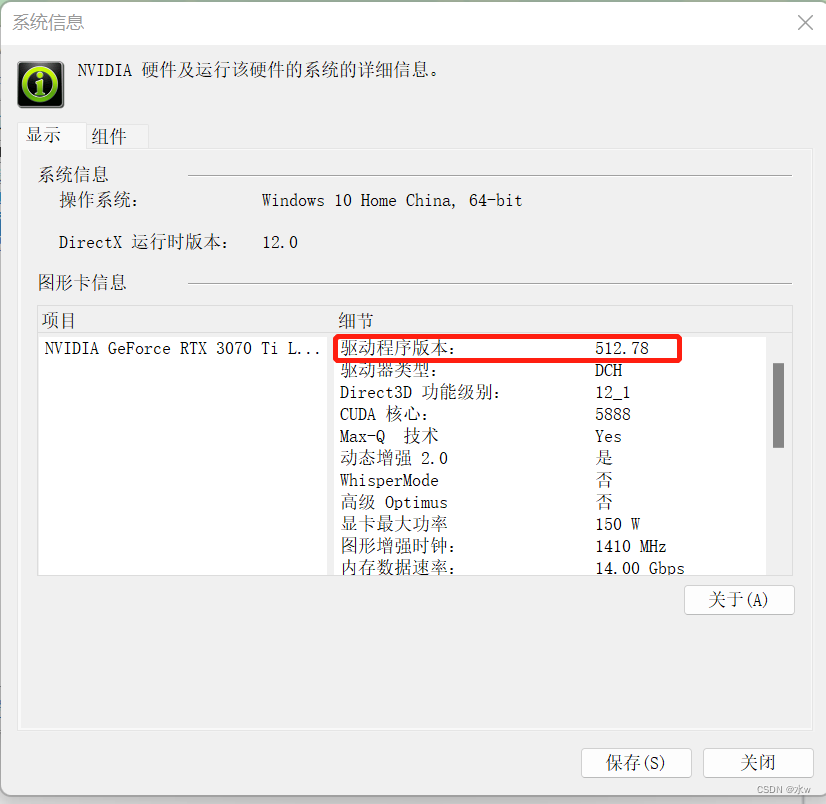
可直接查看自己可安装的最高版本的 CUDA版本,我的电脑是 CUDA11.6。
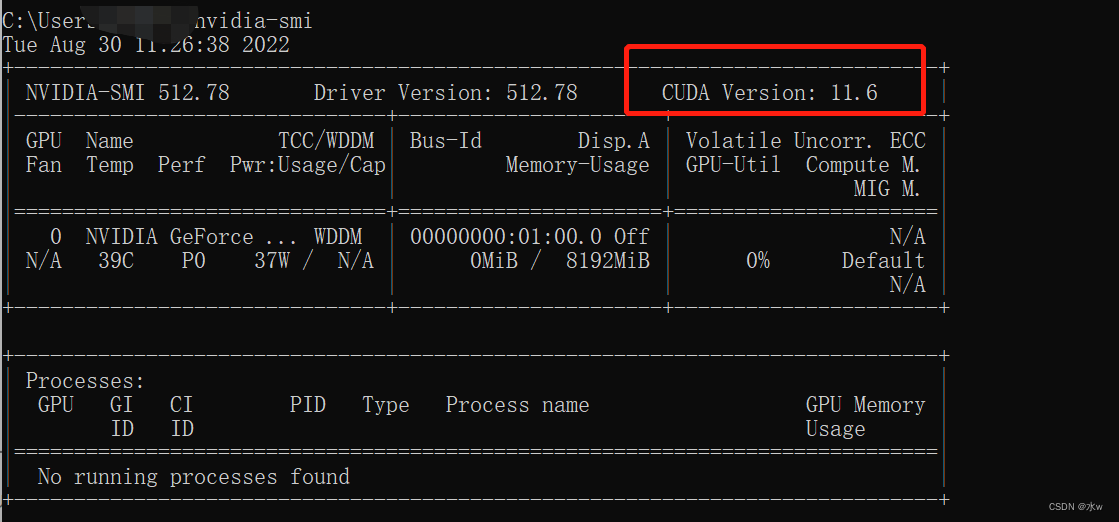
(2)根据这个链接查看自己对应的cuda版本
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
CUDA下载链接:https://developer.nvidia.com/cuda-toolkit-archive
接下来,我们来下载这个CUDA,这里选择的版本不能高于你的显卡驱动里面那个版本号,由于我的是11.6,且系统是win11,所以我这里选择的是11.5
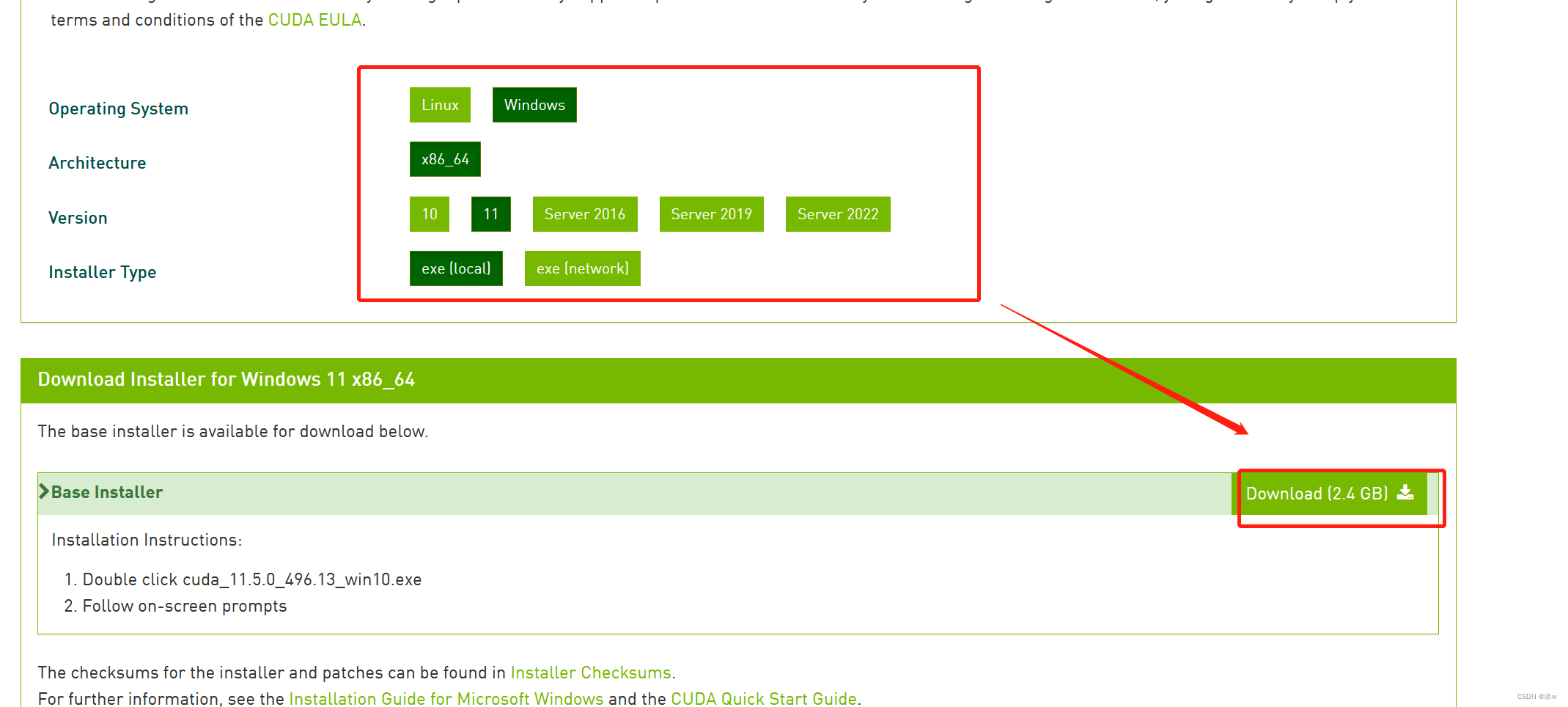
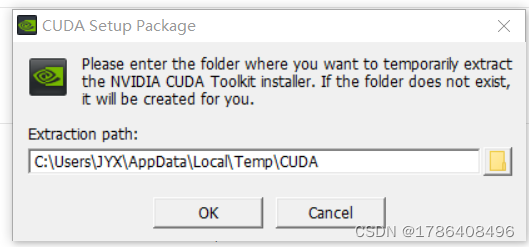
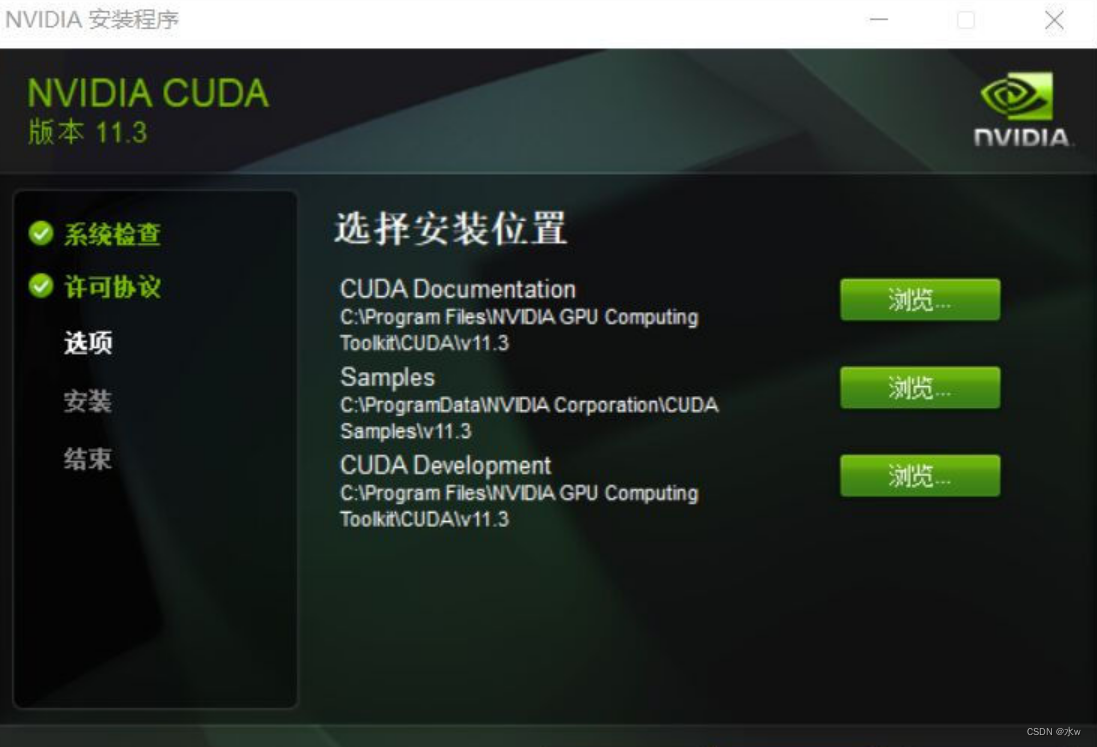
双击运行下载好的CUDA的exe文件,安装时不需要更改路径,这个是压缩包提取的暂存的文件夹,不是最终路径,这里不需要更改。
(3)安装
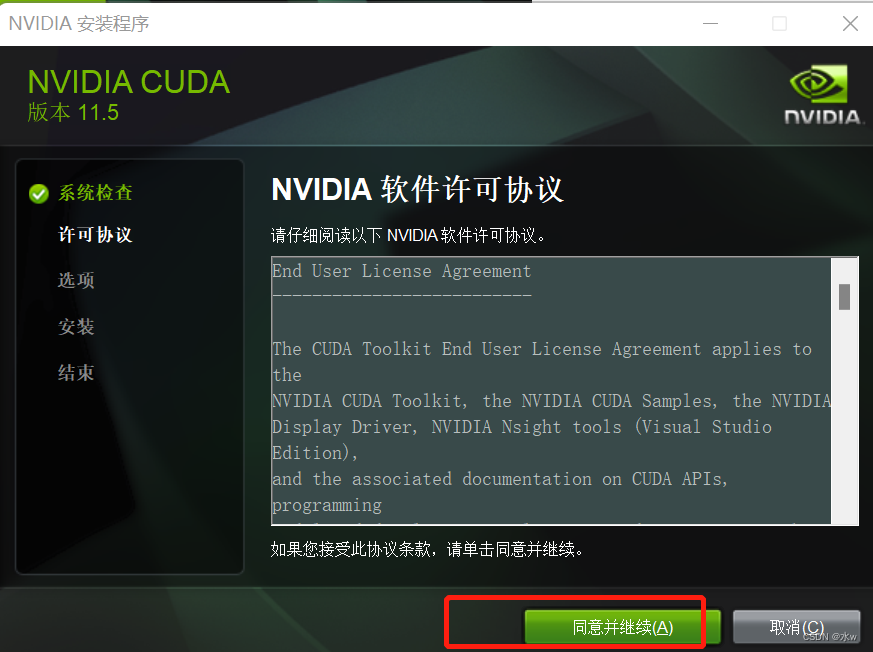
选择自定义安装后,取消勾选 Visual Studio,原因安装耗时较长,也可不需要。后面的路径也不需要更改。
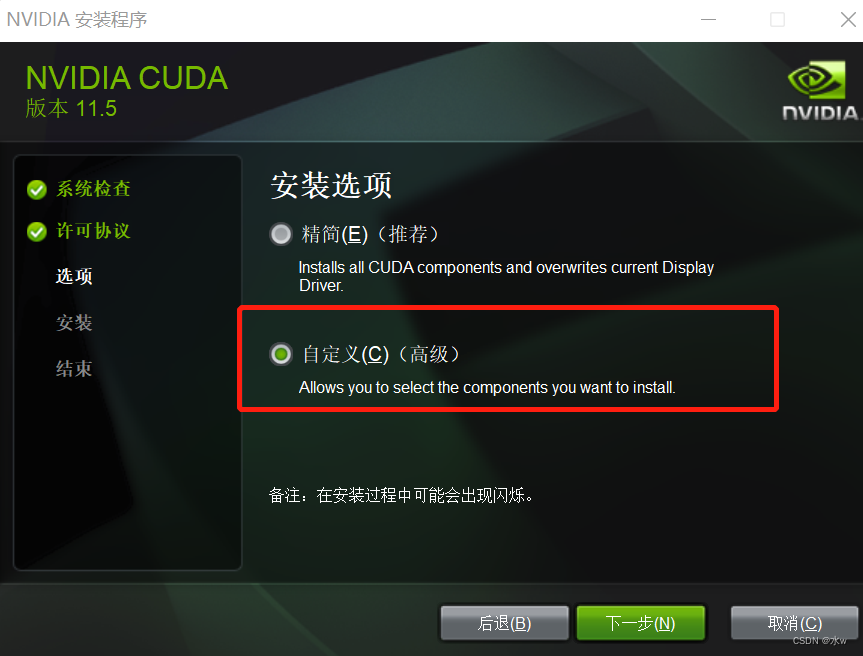
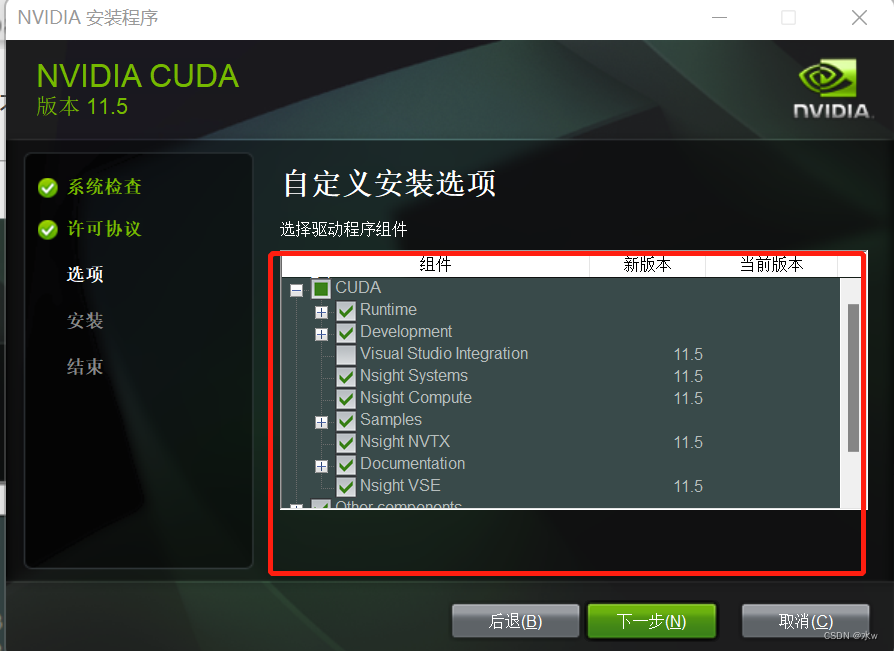
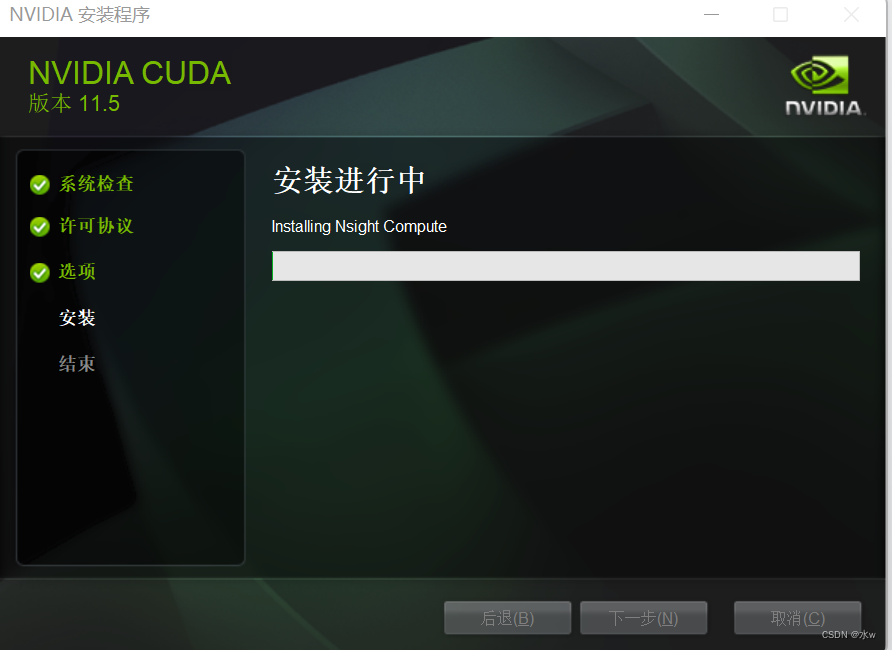
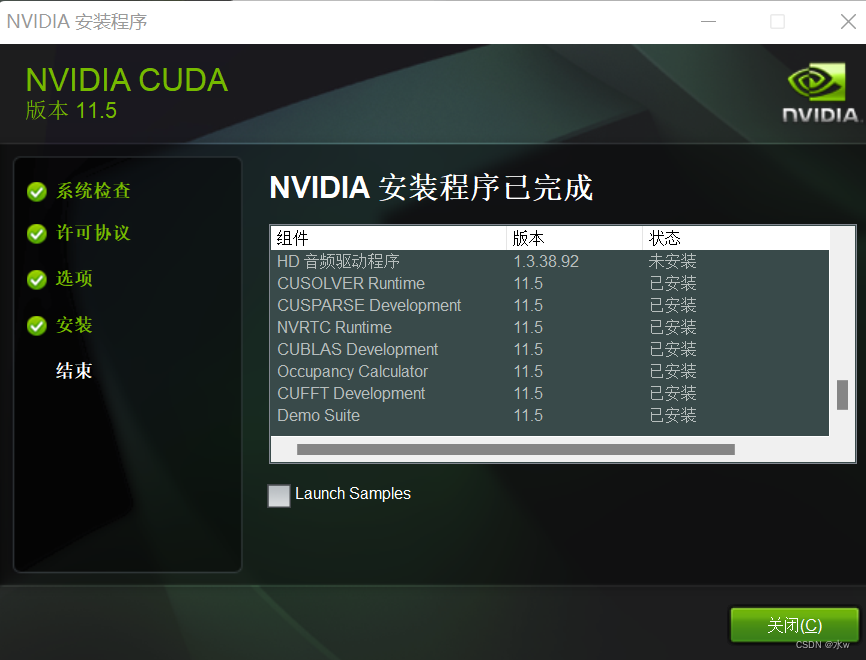
这里与其他安装方法不同的是,我没有安装 cudnn,也没有配置 path ,但是同样也安装成功。
打开 Anaconda prompt 命令,输入命令:
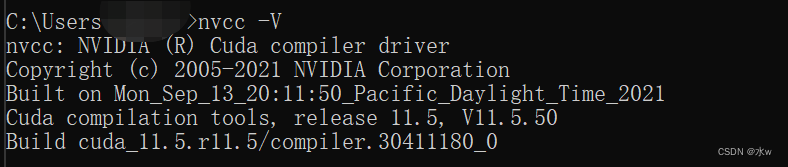
nvcc -V
查看 CUDA11.3是否安装成功。安装成功即可如下所示。
第三步:下载GPU版本下的pytorch和pytorchvision
这里我没有选择直接命令安装,因为安装失败的概率较高。我选择的是下载安装包,再在anaconda里下载whl文件。
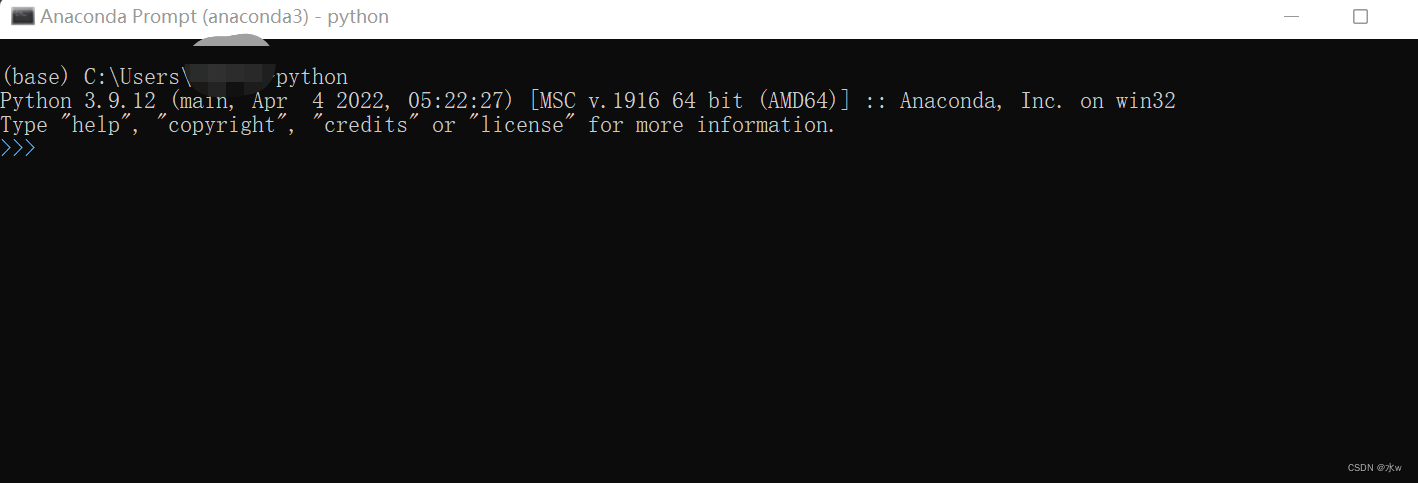
(1)查看自己的python版本,还是在 Anaconda prompt 命令,输入 python,我的 python 版本是3.9.12:
(2)不使用命令行下载 pytorch 的下载链接为:
https://download.pytorch.org/whl/torch_stable.html
里面的文件是cpu开头的是 CPU 版本,cu开头的才是我们要下载的GPU版本。
这里可参考 torch 和 torchvision 的对应图,以免下错对应版本,这里我选择的是红色圈内的,根据自己需求下载。
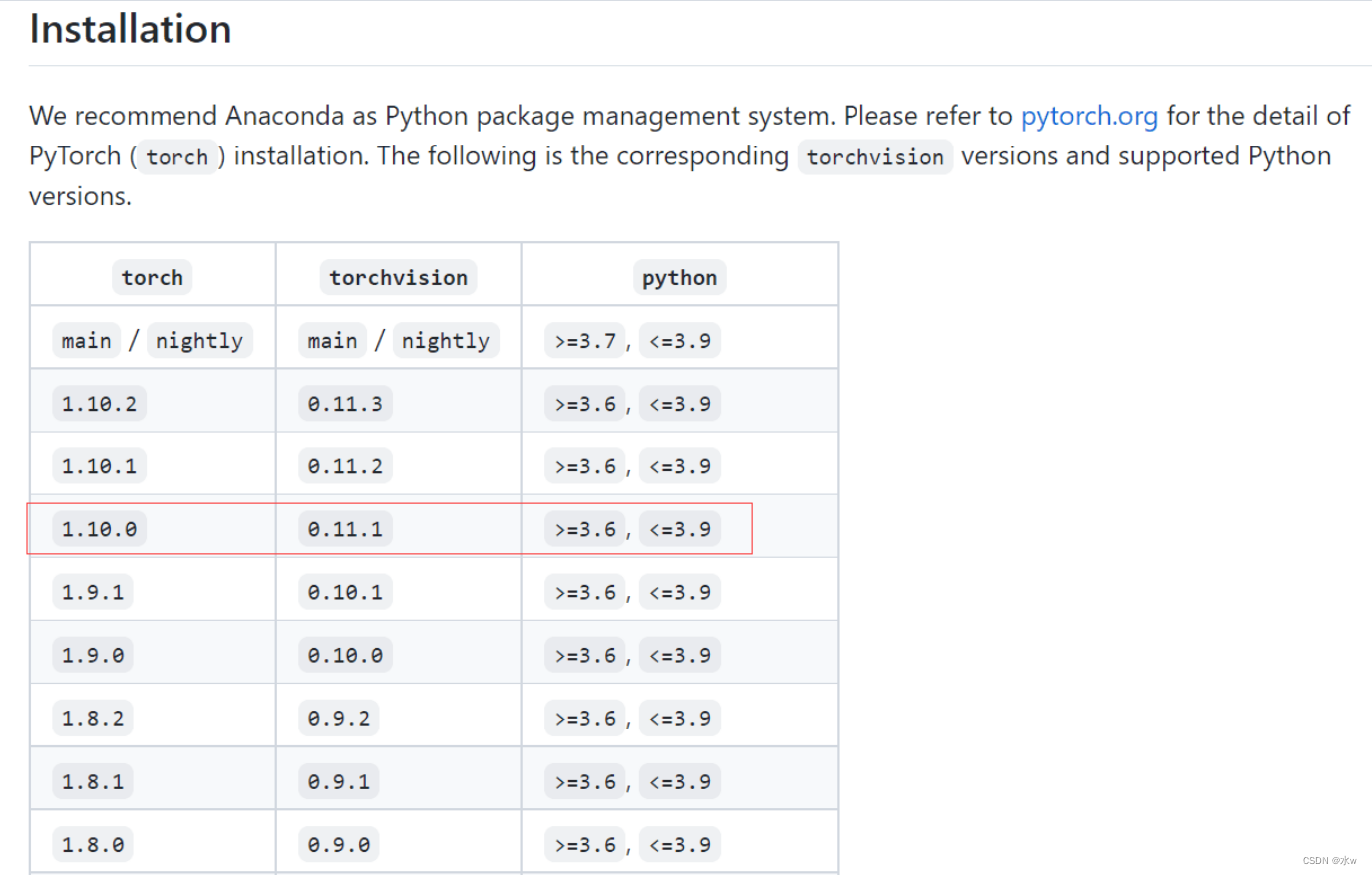
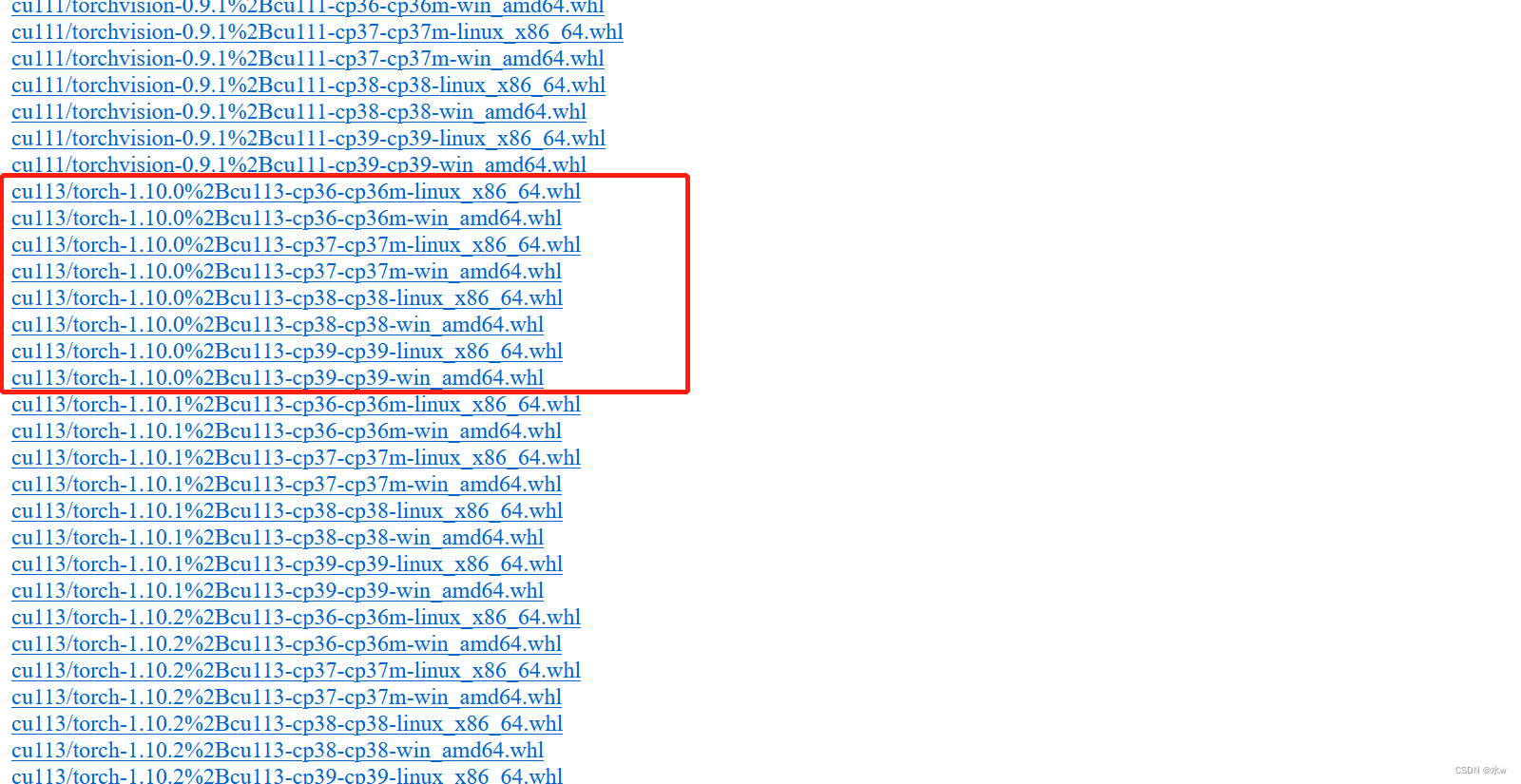
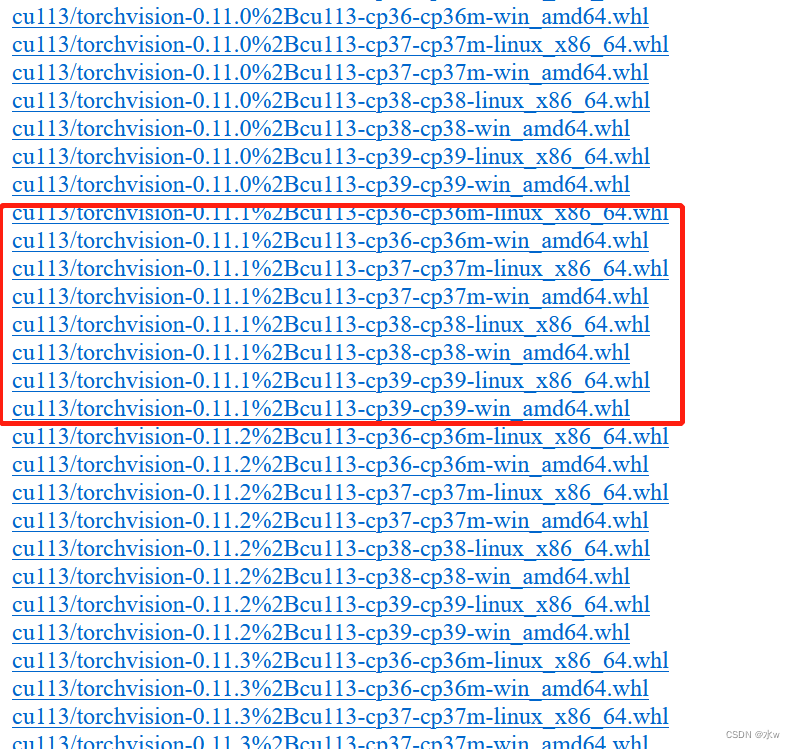
在下载链接里找到的是下载的1.10.0 版本的 torch 和 0.11.1 版本的 torchvision,我的 python版本是3.9,注意后面对应的 win 和 linux:
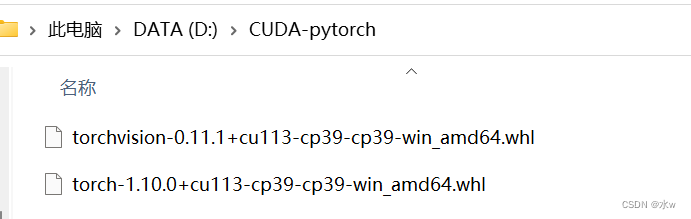
(3)下载后放在同一目录下,我在d盘新建文件夹 CUDA-python,放在了D:\CUDA-pytorch下:
(4)在 Anaconda prompt 里 cd 到你下载好 torch 和 torchvision 的目录下,输入:
pip install “文件名”,torch 和 torchvision 安装方法一样。如:
torch==1.10.0+cu113的包大概有2.27G,比较耗时。下载完成后切换到下载目录,使用pip命令安装。
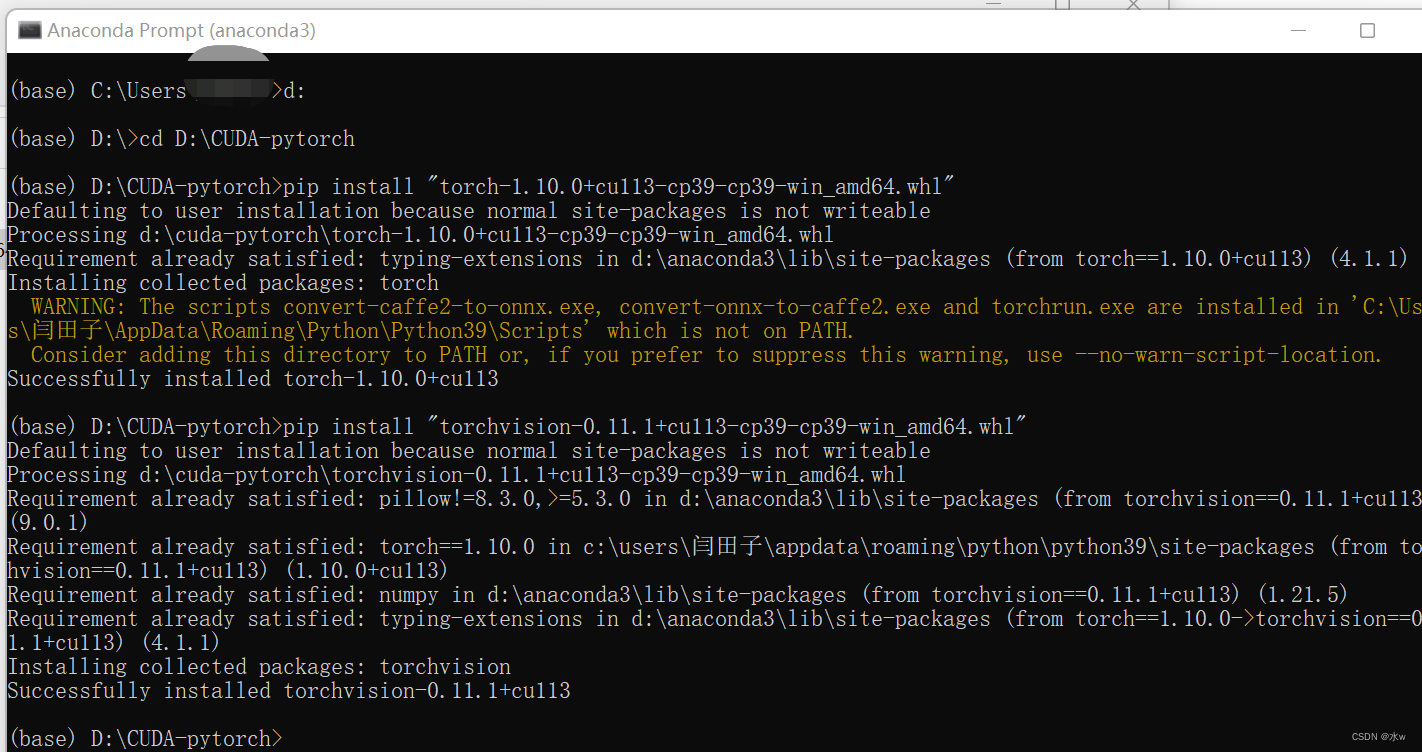
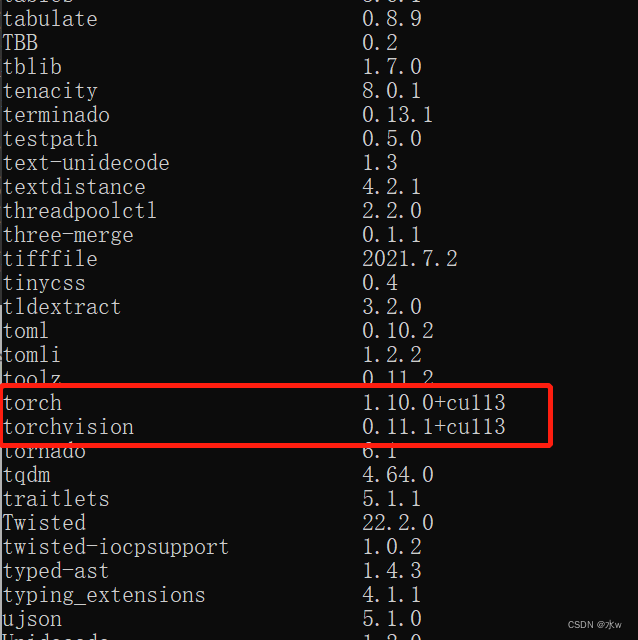
(5)检验方法,输入命令:
pip list
后能看到:
(6)安装完成后使用下面命令查看torch安装结果。
在 Anaconda prompt 里 import导入 torch 和 torchvision库,然后使用命令:
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.get_device_name(0)
'NVIDIA GeForce RTX 3070 Ti Laptop GPU'

第四步:验证以上步骤全部安装成功
跟着这张图上去打开cmd'输入 python,以下步骤:
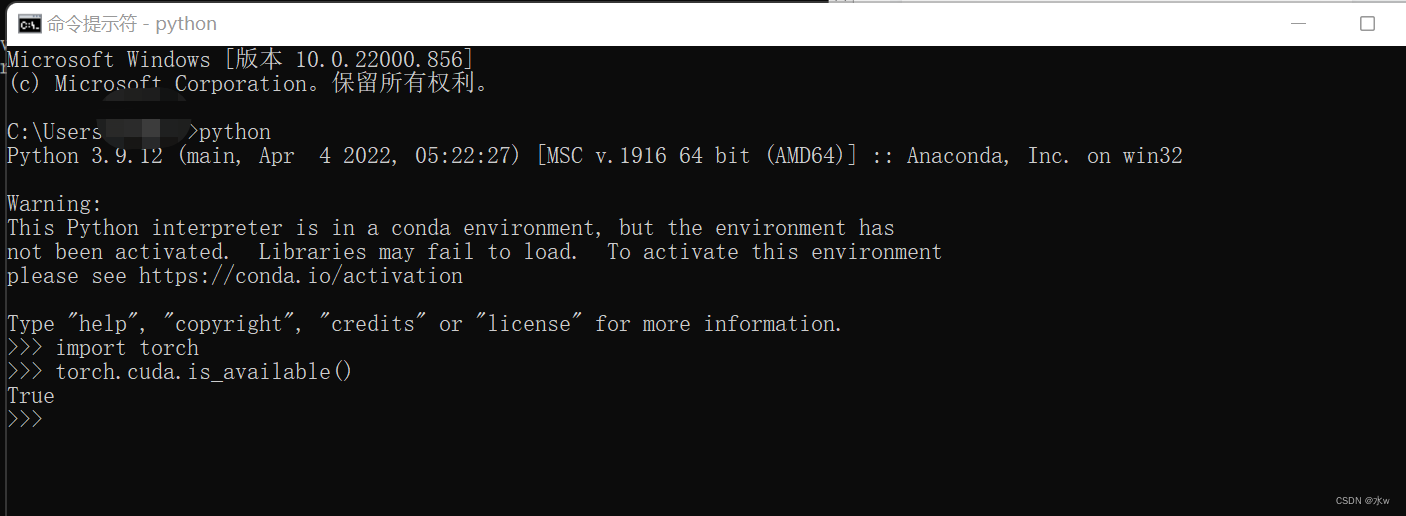
最后得到的是 Ture 说明全部安装已完成。