总结: 1. [SCNN](Spatial as deep: Spatial cnn for traffic scene understanding)和[RESA](Resa: Recurrent feature-shift aggregator for lane detection)提出了一个消息传递机制来收集全局上下文,但是这些方法执行逐像素预测并且不采取车道作为一个整体。
[Line-CNN](Line-cnn:End-to-end traffic line detection with line proposal unit)是在车道检测中使用线锚的开创性工作。
[LaneATT](Keep your eyes on the lane: Real-time attention-guided lane detection)提出了一种新颖的聚合全局的基于锚的注意力机制信息。
[SGNet](Structure guided lane detection)介绍了一个新颖的消失点引导锚生成器,并增加了多个结构引导以提高性能。
2. 基于行锚的方法
预测可能的单元格对于图像上的每个预定义行。
[UFLD]((Ultra fast structure-aware deep lane detection))首先提出了一种基于行锚的车道检测方法,并采用轻量级骨干网以实现高推理速度。尽管简单快速,但它的整体性能并不好。
[CondLaneNet](Cond-lanenet: a top-to-down lane detection framework based on conditional convolution)引入了一种基于条件卷积和基于行锚的公式的条件车道检测策略。即它首先定位车道的起点,然后执行基于行锚的车道检测。但在一些复杂场景下,起点难以识别,导致性能相对较差。
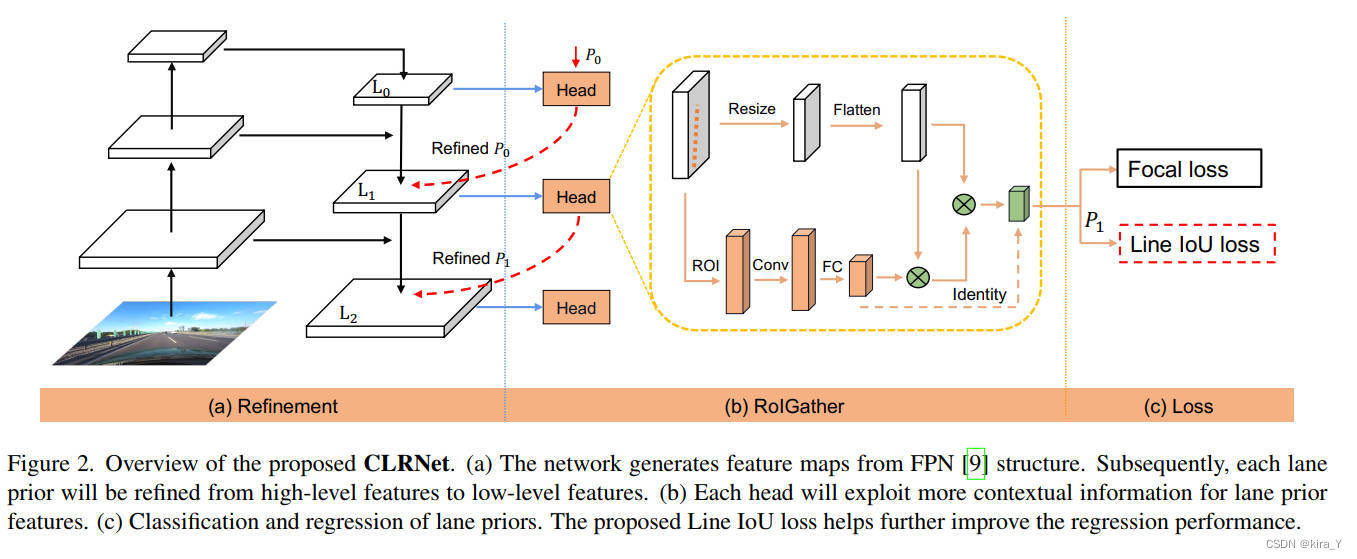
利用ConvNet的金字塔特征层次结构,它具有从低到高的语义,并构建一个贯穿始终具有高级语义的特征金字塔。从具有高语义的最高层执行检测。Pt是车道先验的参数(起点坐标x、y和角度theta)。受[Sparse r-cnn](Sparse r-cnn: End-to-end object detection with learnable proposals)启发,对于第一层L0,P0均匀分布在像平面上。细化Rt以Pt作为输入得到ROI车道特征,然后执行两个FC层得到细化参数Pt。逐步细化车道先验和特征提取对于跨层细化的成功非常重要。
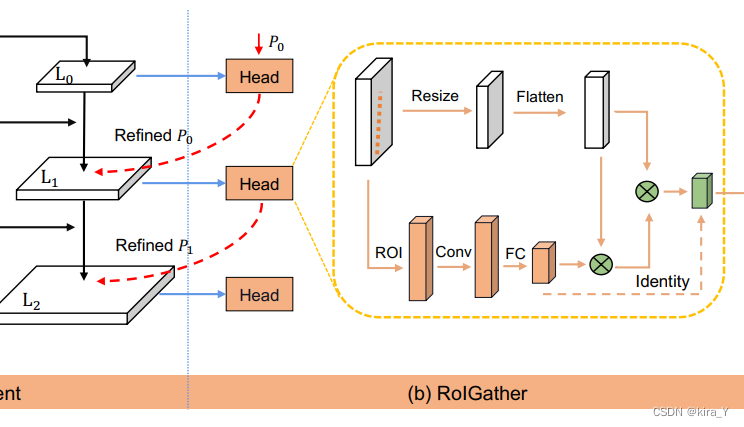
ROIGather
ROIGather structure
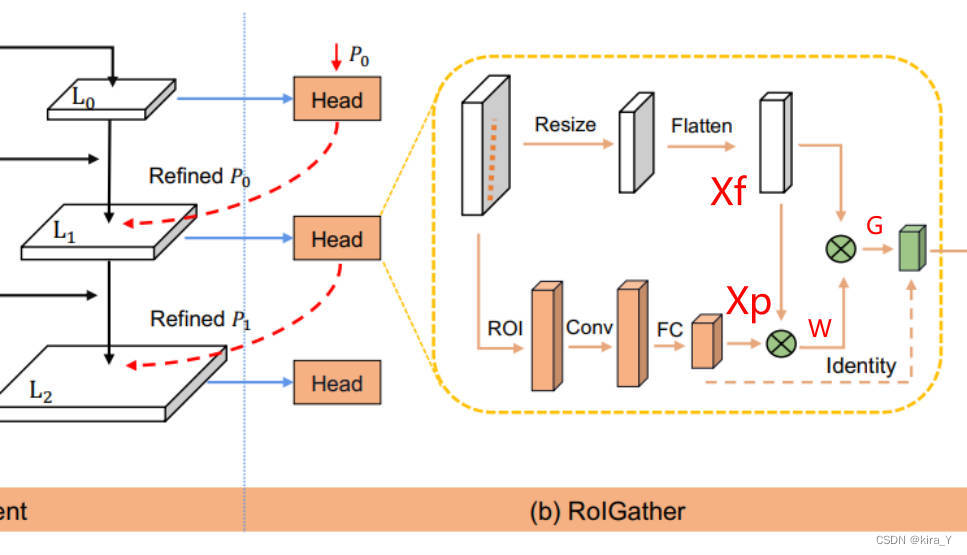
ROIGather模块是轻量级的且易于实现。它以特征图和车道先验作为输入,每个车道先验有N个点。
对于每个车道先验,按照ROIAlign得到车道先验的ROI特征(
X
p
∈
R
C
⋅
N
p
X_p \in R^{C \cdot N_p}
Xp∈RC⋅Np)。与边界框的 ROIAlign 不同,从车道先验中统一采样 Np 个点,并使用双线性插值来计算这些位置处输入特征的精确值。(理解: 也就是把车道先验映射到Feature map中)。
对于 L1、L2 的 ROI 特征,将前一层的 ROI 特征连接起来以增强特征表示。
对提取的 ROI 特征进行卷积,以收集每个车道像素的附近特征。为了节省内存,使用全连接来进一步提取车道先验特征(
X
p
∈
R
C
⋅
1
X_p \in R^{C \cdot 1}
Xp∈RC⋅1)。将特征图调整为
X
f
∈
R
C
⋅
H
⋅
W
X_f \in R^{C \cdot H \cdot W}
Xf∈RC⋅H⋅W并展平为
X
f
∈
R
C
⋅
H
W
X_f \in R^{C \cdot HW}
Xf∈RC⋅HW 。
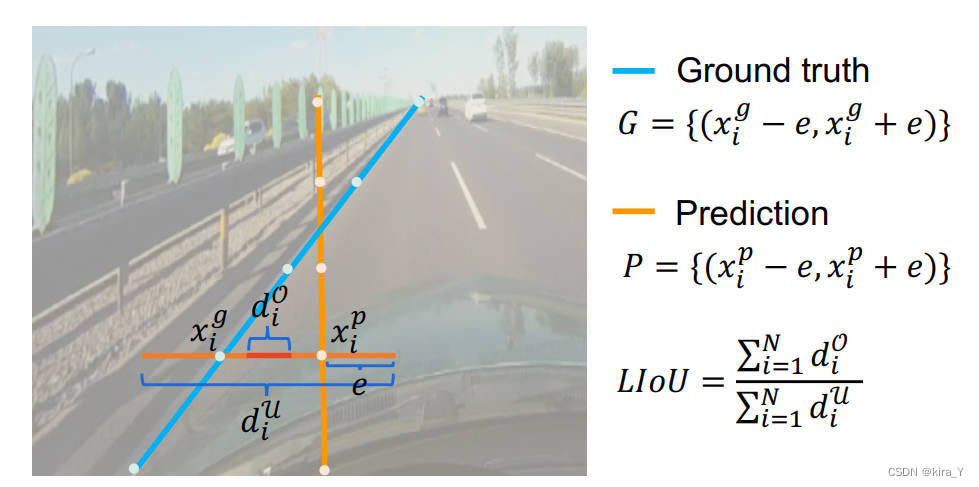
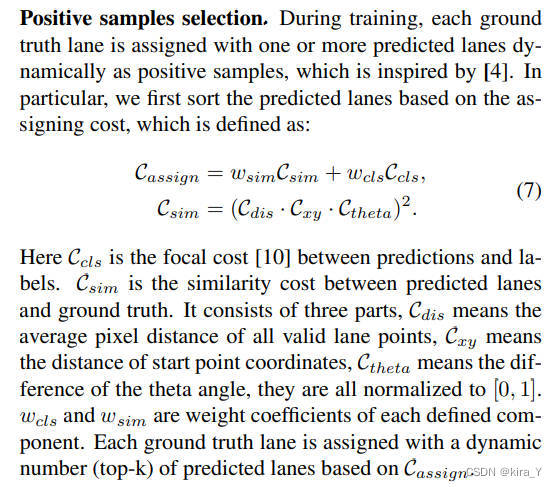
Lcls 是预测和标签之间的焦点损失,Lxytl 是起点坐标、theta 角和车道长度回归的 smooth-l1 损失,LIoU 是预测车道和地面实况之间的 Line IoU 损失。 或者,可以在 [Ultra fast structure-aware deep lane detection](Ultra fast structure-aware deep lane detection) 之后添加辅助分割损失。 它只在训练期间使用,在推理上没有成本。
Inference
设置了一个带有分类分数的阈值来过滤背景车道(低分车道先验),使用 nms 去除 [Keep your eyes on the lane: Real-time attention-guided lane detection](Keep your eyes on the lane: Real-time attention-guided lane detection)之后的高重叠车道。 如果使用一对一的分配,CLRNet的方法也可以是无 nms 的,即设置 top-k = 1。
采用 ResNet 和 DLA 作为预训练骨干。 所有输入图像的大小都调整为 320 × 800。对于数据增强,类似于 [[Cond-lanenet](Cond-lanenet: a top-to-down lane detection framework based on conditional convolution), [Focus on local](Focus on local: Detecting lane marker from bottom up via key point.)],使用随机仿射变换(平移、旋转和缩放)、随机水平翻转。