用户画像及项目实例
所谓用户画像就是标签的汇总,从用户不同方面信息中提取有价值特征来构建标签库,并从标签库中探索信息,从而构建用户画像。
用户画像建模:
-
第一步:统一用户唯一标识
- 用户唯一标识是整个用户画像的核心,方便跟踪和分析一个用户的特征。
- 设计唯一标识的选择:用户名、注册手机号、联系人手机号、邮箱、设备号、CookieID等。
-
第二步:给用户打标签,即用户画像
用户消费行为分析,可从4个维度来进行标签划分。
- 用户标签:用户基本属性,包括性别、年龄、地域、收入、学历、职业等。
- 消费标签:消费习惯、购买意向、是否对促销敏感等。
- 行为标签:分析用户行为,包括时间段、频次、时长、访问路径等。
- 内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,分析出用户对哪些内容感兴趣,如金融、娱乐、教育、体育、时尚、科技等。
-
第三步:将用户画像与业务关联
从用户生命周期的三个阶段来对业务进行划分:获客、粘客和留客
- 获客:通过精准营销获取客户。
- 粘客:个性化推荐,搜索排序,场景运营等。
- 留客:流失率预测,分析关键节点降低流失率。
从数据流处理阶段划分用户画像建模过程,可分为数据层、算法层和业务层
- 数据层:用户消费行为里的标签,可以打上事实标签,作为数据客观的记录
- 算法层:透过行为算出的用户建模,可以打上模型标签,作为用户画像的分类标识。
- 业务层:获客、粘客、留客的手段,可以打上预测标签,作为业务关联的结果。
流程:通过数据层的“事实标签”,在算法层进行计算,打上“模型标签”的分类结果,最后指导业务层,得出“预测标签”。
例:美团外卖的用户画像设计
第一步:统一用户唯一标识
第二步:给用户打标签,即用户画像
- 按照用户消费行为分析的准则来进行设计
- 用户标签:性别、年龄、家乡、居住地、收货地址、婚姻、子女、通过何种渠道进行的注册等。
- 消费标签:餐饮口味、消费均价、团购等级、预定使用等级、排队使用等级、外卖等级等。
- 行为标签:点外卖时间段、使用频次、平均点餐用时、访问路径等。
- 内容分析:基于用户平时浏览的内容进行统计,包括餐饮口味、优惠敏感度等。
第三步:将用户画像与业务关联
- 在获客上,可以找到优势宣传渠道,如何通过个性化宣传手段,吸引具有潜在需求的用户,并刺激转化。
- 在粘客上,如何提升用户的单价和消费频次,方法可以包括购买后的个性化推荐、针对优质用户进行优质高价商品的推荐、以及重复购买,比如通过红包、优惠等方式激励对优惠敏感的人群,提升购买频次。
- 在留客上,预测用户是否可能会从平台上流失。用户流失可能由用户体验,竞争对手,需求变化等因素导致,通过预测用户流失率可大幅降低用户留存的运营成本。
项目实例:电商用户画像及行为分析
一,数据背景
以淘宝APP数据为原始数据集,通过行业常见行业指标对淘宝用户行为进行分析,从而构建用户画像。
二,数据来源
三,数据解释
数据集共计2300多万数据量,时间范围为2014-11-18~2014-12-18,共计6个字段,字段释义如下:
| 字段名 |
释义 |
| user_id |
用户ID |
| item_id |
商品ID |
| behavior_type |
用户行为类型(1:点击,2:收藏,3:加购物车,4:购买 |
| user_geohash |
地理位置信息 |
| item_category |
商品类别 |
| time |
用户行为发生时间 |
四,分析过程
1.数据预处理
#导入所需库
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
from datetime import datetime
%matplotlib inline
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
# 导入数据集,查看数据量
df = pd.read_csv('taobao_persona.csv')
df.shape

可以看到数据量总计2300多万,因此抽样选取部分样本进行后续分析
# 数据抽样,并预览数据结构
df = df.sample(frac=0.3,random_state=None).reset_index()
df.head()

查看字段缺失情况
# 查看是否存在缺失值
df.isnull().sum()

地理信息字段存在大量缺失,且对后续分析无用,因此我们删除此字段
# 删除缺失字段
df.drop('user_geohash',axis=1,inplace=True)
同时在数据预览中可以看到time字段是由日期和小时组成,为了后续分析,在此将其拆分为两个字段
# 将time日期拆分为日期和时间
df['date'] = df['time'].str[0:10]
df['date'] = pd.to_datetime(df['date'],format='%Y-%m-%d')
df['time'] = df['time'].str[11:]
df['time'] = df['time'].astype(int)
df.head()

为了后续的用户标签,在此基于time字段构造面板数据
# 构造面板数据,按时间分为凌晨,上午,中午,下午,晚上
df['hour'] = pd.cut(df['time'],bins=[-1,5,10,13,18,24],
labels=['凌晨','上午','中午','下午','晚上'])
df.head()

生成用户标签
# 生成用户标签列表
users = df['user_id'].unique()
labels = pd.DataFrame(users,columns=['user_id'])
2.1 用户行为标签
2.1.1 用户浏览活跃时间段标签
# 对用户和时段进行分组,统计浏览次数
time_browse = df[df['behavior_type']==1].groupby(['user_id','hour']).item_id.count().reset_index()
time_browse.rename(columns={'item_id':'hour_counts'},inplace=True)
time_browse.head()

# 统计每个用户浏览次数最多的时间段
time_browse_max = time_browse.groupby('user_id').hour_counts.max().reset_index()
time_browse_max.rename(columns={'hour_counts':'read_counts_max'},inplace=True)
# 两个结果做连接
time_browse = pd.merge(time_browse,time_browse_max,how='left',on='user_id')
time_browse.head()

# 选取每个用户浏览次数最多的时间段
time_browse_hour = time_browse.loc[time_browse['hour_counts']==time_browse['read_counts_max'],'hour']
# 存在并列多个时用逗号连接,得到用户活跃时间段标签
time_browse_hour = time_browse_hour.groupby(time_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_browse_hour.head()

# 将用户浏览活跃时间加入用户标签中
labels = pd.merge(labels,time_browse_hour,how='left',on='user_id')
labels.rename(columns={'hour':'time_browse'},inplace=True)
labels.head()
2.1.2 用户购买活跃时间段标签
time_buy = df[df['behavior_type']==4].groupby(['user_id','hour']).item_id.count().reset_index().rename(columns={'item_id':'hour_counts'})
time_buy_max = time_buy.groupby('user_id').hour_counts.max().reset_index().rename(columns={'hour_counts':'buy_counts_max'})
time_buy = pd.merge(time_buy,time_buy_max,how='left',on='user_id')
time_buy_hour = time_buy.loc[time_buy['hour_counts']==time_buy['buy_counts_max'],'hour']
time_buy_hour = time_buy_hour.groupby(time_buy['user_id']).aggregate(lambda x:','.join(x)).reset_index()
time_buy_hour.head()

# 将用户购买活跃时间段加入到用户标签表中
labels = pd.merge(labels,time_buy_hour,how='left',on='user_id').rename(columns={'hour':'time_buy'})
labels.head()

2.1.3 用户浏览最多的商品类别
# 对用户与类别进行分组,统计浏览次数
df_browse = df.loc[df['behavior_type']==1,['user_id','item_id','item_category']]
df_cate_most_browse = df_browse.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_browse.rename(columns={'item_id':'item_category_counts'},inplace=True)
# 每个用户浏览最多的商品类别
df_cate_most_browse_max = df_cate_most_browse.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_browse_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_browse = pd.merge(df_cate_most_browse,df_cate_most_browse_max,how='left',on='user_id')
df_cate_most_browse['item_category'] = df_cate_most_browse['item_category'].astype(str)
# 选取每个用户浏览次数最多的类别,存在并列时,用逗号连接
df_cate_browse = df_cate_most_browse.loc[df_cate_most_browse['item_category_counts']==
df_cate_most_browse['item_category_counts_max'],
'item_category'].groupby(df_cate_most_browse['user_id']).aggregate(lambda x:','.join(x)).reset_index()
# 将用户浏览量最多的类目加入到用户标签中
labels = pd.merge(labels,df_cate_browse,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_browse'},inplace=True)
labels.head()

2.1.4 用户收藏最多的商品类别
# 过程与上述类似
df_collect = df.loc[df['behavior_type']==2,['user_id','item_id','item_category']]
df_cate_most_collect = df_collect.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_collect.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_collect_max = df_cate_most_collect.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_collect_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_collect = pd.merge(df_cate_most_collect,df_cate_most_collect_max,how='left',on='user_id')
df_cate_most_collect['item_category'] = df_cate_most_collect['item_category'].astype(str)
df_cate_collect = df_cate_most_collect.loc[
df_cate_most_collect['item_category_counts']==df_cate_most_collect[
'item_category_counts_max'],'item_category'].groupby(
df_cate_most_collect['user_id']).aggregate(lambda x:','.join(x)).reset_index()
labels = pd.merge(labels,df_cate_collect,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_collect'},inplace=True)
labels.head()

2.1.5 用户加购物车最多的商品类别
# 同上
df_cart = df.loc[df['behavior_type']==3,['user_id','item_id','item_category']]
df_cate_most_cart = df_cart.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_cart.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_cart_max = df_cate_most_cart.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_cart_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_cart = pd.merge(df_cate_most_cart,df_cate_most_cart_max,how='left',on='user_id')
df_cate_most_cart['item_category'] = df_cate_most_cart['item_category'].astype(str)
df_cate_cart = df_cate_most_cart.loc[df_cate_most_cart['item_category_counts']==df_cate_most_cart['item_category_counts_max'],'item_category'].groupby(df_cate_most_cart['user_id']).aggregate(lambda x:','.join(x)).reset_index()
labels = pd.merge(labels,df_cate_cart,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_cart'},inplace=True)
labels.head()

2.1.6 用户购买最多的商品类别
# 同上
df_buy = df.loc[df['behavior_type']==4,['user_id','item_id','item_category']]
df_cate_most_buy = df_buy.groupby(['user_id','item_category']).item_id.count().reset_index()
df_cate_most_buy.rename(columns={'item_id':'item_category_counts'},inplace=True)
df_cate_most_buy_max = df_cate_most_buy.groupby('user_id').item_category_counts.max().reset_index()
df_cate_most_buy_max.rename(columns={'item_category_counts':'item_category_counts_max'},inplace=True)
df_cate_most_buy = pd.merge(df_cate_most_buy,df_cate_most_buy_max,how='left',on='user_id')
df_cate_most_buy['item_category'] = df_cate_most_buy['item_category'].astype(str)
df_cate_buy = df_cate_most_buy.loc[df_cate_most_buy['item_category_counts']==df_cate_most_buy['item_category_counts_max'],'item_category'].groupby(df_cate_most_buy['user_id']).aggregate(lambda x:','.join(x)).reset_index()
labels = pd.merge(labels,df_cate_buy,how='left',on='user_id')
labels.rename(columns={'item_category':'cate_most_buy'},inplace=True)
labels.head()

2.2 关于时间的用户行为标签
2.2.1 近30天用户行为
2.2.1.1 近30天购买次数
# 近30天购买次数
# 将购买行为按用户进行分组,统计次数
df_counts_30_buy = df[df['behavior_type']==4].groupby('user_id').item_id.count().reset_index()
labels = pd.merge(labels,df_counts_30_buy,how='left',on='user_id').rename(columns={'item_id':'counts_30_buy'})
labels.head()

2.2.1.2 近30天加购物车次数
df_counts_30_cart = df[df['behavior_type']==3].groupby('user_id').item_id.count().reset_index()
labels = pd.merge(labels,df_counts_30_cart,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_30_cart'},inplace=True)
2.2.1.3 近30天活跃天数
counts_30_active = df.groupby('user_id')['date'].agg(['nunique']).reset_index()
labels = pd.merge(labels,counts_30_active,how='left',on='user_id')
labels.rename(columns={'nunique':'counts_30_active'},inplace=True)
labels.head()
2.2.2 近7天用户行为
2.2.2.1 近7天购买次数
# 取出最后7天的数据
df_near_7 = df[df['date']>datetime.strptime('2014-12-11','%Y-%m-%d')]
# 近7天购买次数
df_counts_7_buy = df_near_7[df_near_7['behavior_type']==4].groupby('user_id').item_id.count().reset_index()
labels = pd.merge(labels,df_counts_7_buy,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_7_buy'},inplace=True)
labels.head(10)
2.2.2.2 近7天加购物车次数
# 近七天加购物车次数
df_counts_7_cart = df_near_7[df_near_7['behavior_type']==3].groupby('user_id').item_id.count().reset_index()
labels = pd.merge(labels,df_counts_7_cart,how='left',on='user_id')
labels.rename(columns={'item_id':'counts_7_cart'},inplace=True)
labels.head(10)
2.2.2.3 近7天活跃天数
# 近7天活跃天数
counts_7_active = df_near_7.groupby('user_id')['date'].agg(['nunique']).reset_index()
labels = pd.merge(labels,counts_7_active,how='left',on='user_id')
labels.rename(columns={'nunique':'counts_7_active'},inplace=True)
labels.head(10)
2.2.3 最后一次行为距今天数
2.2.3.1 最后一次浏览距今天数
# 最后一次浏览距今的天数
days_browse = df[df['behavior_type']==1].groupby('user_id')['date'].max().agg([lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days]).reset_index()
labels= pd.merge(labels,days_browse,how='left',on='user_id')
labels.rename(columns={'<lambda>':'days_browse'},inplace=True)
labels.head(10)
2.2.3.2 最后一次加购物车距今天数
# 最后一次加购物车距今的天数
days_cart = df[df['behavior_type']==3].groupby('user_id')['date'].max().agg([lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days]).reset_index()
labels= pd.merge(labels,days_cart,how='left',on='user_id')
labels.rename(columns={'<lambda>':'days_cart'},inplace=True)
labels.head()
2.2.3.3 最后一次购买距今天数
# 最后一次购买距今天数
days_buy = df[df['behavior_type']==4].groupby('user_id')['date'].max().agg([lambda x:(datetime.strptime('2014-12-19','%Y-%m-%d')-x).days])
labels = pd.merge(labels,days_buy,how='left',on='user_id')
labels.rename(columns={'<lambda>':'days_buy'},inplace=True)
labels.head()
2.2.3.4 最后两次购买的时间间隔天数
# 最近两次购买间隔天数
df_interval_buy = df[df['behavior_type']==4].groupby(['user_id','date']).item_id.count().reset_index()
interval_buy = df_interval_buy.groupby('user_id')['date'].apply(lambda x:x.sort_values().diff(1).dropna().head(1)).reset_index()
interval_buy['date'] = interval_buy['date'].apply(lambda x:x.days)
interval_buy.drop('level_1',axis=1,inplace=True)
interval_buy.rename(columns={'date':'interval_buy'},inplace=True)
labels = pd.merge(labels,interval_buy,how='left',on='user_id')
labels.head()
2.3 关于是否购买的用户行为
2.3.1 用户是否存在浏览未下单行为
# 用户是否存在浏览未下单行为
df_browse_buy = df.loc[(df['behavior_type']==1) | (df['behavior_type']==4),['user_id','item_id','behavior_type','time']]
browse_not_buy = pd.pivot_table(df_browse_buy,index=['user_id','item_id'],columns=['behavior_type'],values=['time'],aggfunc=['count'])
browse_not_buy.fillna(0,inplace=True)
browse_not_buy.columns=['browse','buy']
browse_not_buy['browse_not_buy']=0
browse_not_buy.loc[(browse_not_buy['browse']>0) & (browse_not_buy['buy']==0),'browse_not_buy']=1
browse_not_buy = browse_not_buy.groupby('user_id')['browse_not_buy'].sum().reset_index()
labels = pd.merge(labels,browse_not_buy,how='left',on='user_id')
labels['browse_not_buy'] = labels['browse_not_buy'].apply(lambda x:'是' if x>0 else '否')
labels.head()
2.3.2 用户是否存在加购物车未下单行为
# 是否存在加购物车未下单行为
df_cart_buy = df.loc[(df['behavior_type']==3) | (df['behavior_type']==4),['user_id','item_id','behavior_type','time']]
cart_not_buy = pd.pivot_table(df_cart_buy,index=['user_id','item_id'],columns=['behavior_type'],values=['time'],aggfunc=['count'])
cart_not_buy.columns = ['cart','buy']
cart_not_buy.fillna(0,inplace=True)
cart_not_buy['cart_not_buy']=0
cart_not_buy.loc[(cart_not_buy['cart']>0) & (cart_not_buy['buy']==0),'cart_not_buy']=1
cart_not_buy = cart_not_buy.groupby('user_id')['cart_not_buy'].sum().reset_index()
labels = pd.merge(labels,cart_not_buy,how='left',on='user_id')
labels['cart_not_buy'] = labels['cart_not_buy'].apply(lambda x: '是' if x>0 else '否')
labels.head()
2.4 用户属性标签
2.4.1 是否复购用户
# 是否复购用户
buy_again = df[df['behavior_type']==4].groupby('user_id')['item_id'].count().reset_index()
buy_again.rename(columns={'item_id':'buy_again'},inplace=True)
labels=pd.merge(labels,buy_again,how='left',on='user_id')
labels['buy_again'].fillna(-1,inplace=True)
labels['buy_again'] = labels['buy_again'].apply(lambda x:'是' if x>1 else '否' if x==1 else '未购买')
labels.head()
2.4.2 访问活跃度
# 访问活跃度
user_active_level = labels['counts_30_active'].value_counts().sort_index(ascending=False)
plt.figure(figsize=(16,9))
user_active_level.plot(title='30天内访问次数与访问人数的关系',fontsize=18)
plt.xlabel('访问次数',fontsize=15)
plt.ylabel('访问人数',fontsize=15)

从图中可以看出,访问次数和访问人数成正相关关系,这里取访问次数20以上的定义为活跃用户。
labels['user_active_level']='高'
labels.loc[labels['counts_30_active']<=20,'user_active_level'] = '低'
labels.head()
2.4.3 购买活跃度
# 购买活跃度
buy_active_level = labels['counts_30_buy'].value_counts().sort_index(ascending=False)
plt.figure(figsize=(16,9))
buy_active_level.plot(title='30天内购买次数与购买人数的关系',fontsize=18)
plt.xlabel('购买次数',fontsize=15)
plt.ylabel('购买人数',fontsize=15)

从图中曲线可以看出拐点大约是15,因此定义购买次数在15次以下为低活跃度,15次以上为高活跃度。
# 定义购买活跃度标签
labels['buy_active_level'] = '高'
labels.loc[labels['counts_30_buy']<=15,'buy_active_level'] = '低'
labels.head()
2.4.4购买品类是否单一
# 购买品类是否单一
buy_single = df[df['behavior_type']==4].groupby('user_id').item_category.nunique().reset_index()
buy_single.rename(columns={'item_category':'buy_single'},inplace=True)
labels = pd.merge(labels,buy_single,how='left',on='user_id')
labels['buy_single'].fillna(-1,inplace=True)
labels['buy_single'] = labels['buy_single'].apply(lambda x:'是' if x>1 else '否' if x==1 else '未购买')
labels.head()
2.4.5 用户价值分组RFM
# 用户价值分组RFM
last_buy_days = labels['days_buy'].value_counts().sort_index()
plt.figure(figsize=(16,9))
last_buy_days.plot(title='最后一次购买距今天数与购买人数的关系',fontsize=18)
plt.xlabel('距今天数',fontsize=15)
plt.ylabel('购买人数',fontsize=15)

从图中可以看出,最后一次购买距今天数为7天的购买人数最多,分析其原因是因为当天双十二促销活动,因此定义最后一次购买行为距今8天以上的为低活跃用户。
labels['buy_days_level'] = '高'
labels.loc[labels['days_buy']>8,'buy_days_level'] = '低'
labels.head()
# 利用用户活跃程度和最近购买两个指标来计算RFM
labels['rfm_value'] = labels['user_active_level'].str.cat(labels['buy_days_level'])
def trans_value(x):
if x=='高高':
return '重要价值客户'
elif x=='低高':
return '重要深耕客户'
elif x=='高低':
return '重要召回客户'
else:
return '即将流失客户'
labels['rfm'] = labels['rfm_value'].apply(trans_value)
labels.head()
labels.drop(['buy_days_level','rfm_value'],axis=1,inplace=True)
labels['rfm'].value_counts()

# 作柱状图
labels['rfm'].value_counts().plot.bar()
plt.xticks(rotation=0)
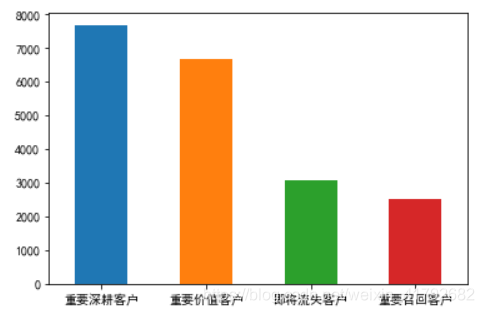
可以看到淘宝用户高价值客户较多。