1.unordered系列关联式容器
1.1unordered_map接口
-
在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
-
unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value
unordered_map的容量
bool empty()const 检测unordered_map是否为空
size_t size() const 返回unordered_map的有效元素个数
unordered_map的迭代器
begin() 返回unordered_map的第一个元素的迭代器
end() 返回unordered_map最后一个元素下一个位置的迭代器
cbegin() 返回unordered_map第一个元素的const迭代器
cend() 返回unordered_map最后一个元素下一个位置的const迭代器
unordered_map的元素访问
operator[] 返回与key对应的value
unordered_map的查询
iterator find(const k&key) 返回key在哈希桶的位置
size_t count(const k&key) 返回哈希桶中关键码key的键值对的个数
unordered_map的修改操作
insert 向容器中插入键值对
pair<iterator,bool>insert(const value_type& val)
erase 删除容器中的键值对
iterator erase(const_iterator position)
size_type erase(const key_type& k)
iterator erase(const_iterator first,const_iterator last)
unordered_map操作
size_t bucket_count()const 返回哈希桶中的桶个数
size_t bucket_size(size_t n)const 返回n号桶有效元素的总个数
size_t bucket(const k& key) 返回元素key所在的桶号
1.2unordered_set
接口与unordered_map相似
2.底层原理
unordered系列的关联式容器之所以效率高,是因为其底层使用了hashtable结构。
2.1顺式结构和平衡树
元素关键码key与其存储位置之间没有对应的关系,因此在查找一个元素时,需要进行多次关键码的比较。顺序结构的查找的时间复杂度O(N),平衡树中位数的高度,即O(logn)。
2.2hash结构
可以不经过任何比较,而是通过hash函数,一次直接从表中得到需要搜索的元素。
- 插入元素:根据待插入元素的关键码,通过hash函数得到存储的位置
- 搜索元素:对元素的关键码进行计算,得到关键码对应的存储位置。
- hash中使用的转换函数叫做哈希函数,构造出来的结构叫做hashtable
例如:将数据集合映射在hash表中{1,7,6,4,5,9}
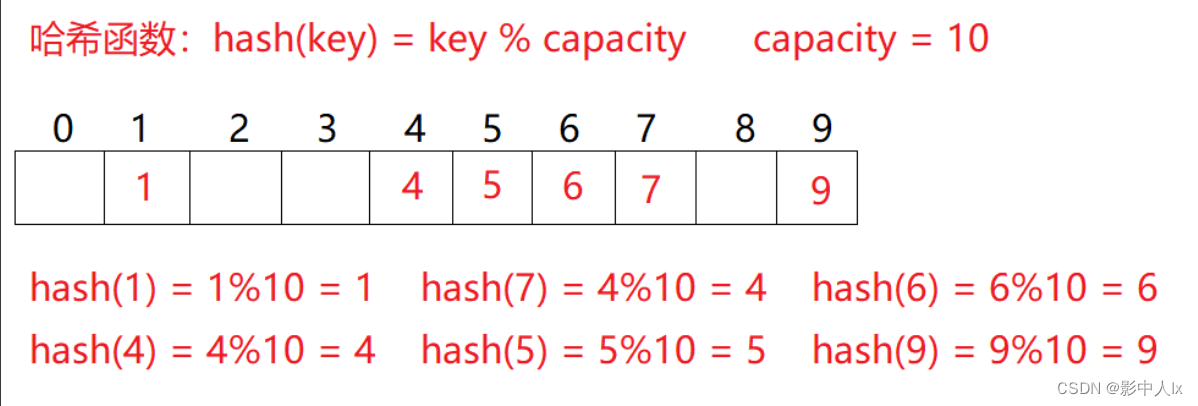
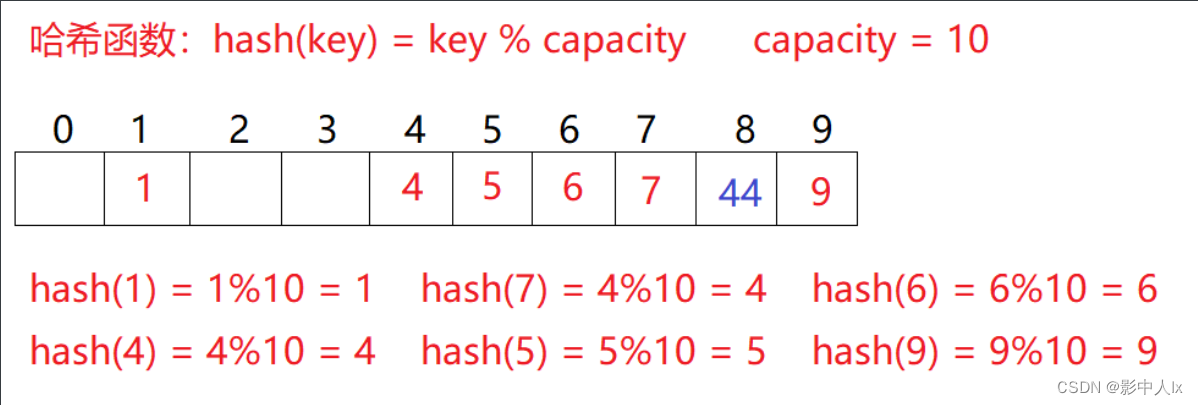
2.3哈希冲突【哈希碰撞】
对于两个不同的关键字key1和key2,通过哈希函数可能映射在同一个位置:即Hash(key1)==Hash(key2);该现象称为哈希冲突或哈希碰撞
2.4合理的哈希函数
引起哈希冲突的一个原因:哈希函数设计不合理
解决哈希冲突的方法:闭散列和开散列
**负载因子:**数组存储元素的个数/数组的长度;负载因子越大,哈希冲突越大,负载因子越小,哈希冲突越小。
2.4.1常见哈希函数
各种字符串Hash函数 - clq - 博客园 (cnblogs.com)
在.net HashTable类的hash函数Hk定义如下:
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) %
(hashsize – 1)))] % hashsize;
在此 (1 + (((GetHash(key) >> 5) + 1) % (hashsize – 1))) 与 hashsize互为素数(两数互为素数表示两者没有共同的质因⼦);
执⾏了 hashsize 次探查后,哈希表中的每⼀个位置都有且只有⼀次被访问到,也就是说,对于给定的 key,对哈希表中的同⼀位置不会同时使⽤ Hi 和 Hj;
2.5闭散列【开发定址法】
闭散列:也叫开放定址法。当发送哈希冲突时,如果哈希表未被装满,说明哈希表中必然还要空位置,那么就可以把key存放在其他没有填放的位置。找未填充的位置也有两种方法:1.线性探测 2.二次探测
2.5.1线性探测
发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
**解决哈希冲突的方法:i+1,i+2,i+3,i+4 … i+n **
2.5.3线性探测哈希结构的实现
封装哈希数据
enum state
{
EMPTY,
EXITS,
DELETE
};
//封装Hash对应的数据
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
state _state = EMPTY;
};
封装减小哈希碰撞的仿函数
template <class K>
struct DefultHash
{
size_t operator()(const K& k)
{
return (size_t)k;
}
};
//模板特化,特化的类型是string类
template<>
struct DefultHash<string>
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto i : key)
{
hash = hash * 131 + i;
}
return (size_t)hash;
}
};
封装哈希表【线性探测】
template<class K,class V,class HashFunc=DefultHash<K>>
class HashTable
{
public:
typedef HashData<K, V> Data;
//支持修改的查找函数
Data* find(const K&key)
{
if (_table.size() == 0)
{
return nullptr;
}
HashFunc func;
size_t starti = func(key);
starti %= _table.size();
size_t hashi = starti;
size_t i = 1;
while (_table[hashi]._state != EMPTY)
{
if (_table[hashi]._state != DELETE &&_table[hashi]._kv.first == key)
{
return &_table[hashi];
}
hashi = starti + i;
i++;
hashi %= _table.size();
}
return nullptr;
}
bool insert(const pair<K,V>& kv)
{
//判断是否存在
if (find(kv.first))
{
return false;
}
//判断是否需要扩容:如果vector为空,或者负载因子过大,就进行扩容
if (_table.size()==0||n*10/_table.size()>7)
{
size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;
//创建新的HashTable
HashTable<K, V,HashFunc> _newtable;
_newtable._table.resize(newsize);
//将原来的数据插入到新的哈希表中
for (auto& e : _table)
{
if (e._state != EMPTY)
{
if (e._state == EXITS)
{
_newtable.insert(e._kv);
}
}
}
_newtable._table.swap(_table);
}
//插入数据
HashFunc func;
size_t hashi = func(kv.first);
hashi %= _table.size();
size_t starti = hashi;
size_t i = 1;
//线性探测
while (_table[hashi]._state == EXITS)
{
hashi = starti + i;
i++;
hashi %= _table.size();
}
_table[hashi]._kv = kv;
_table[hashi]._state = EXITS;
n++;
return true;
}
bool erase(const K& key)
{
Data* ret = find(key);
if (ret)
{
ret->_state = DELETE;
n--;
return true;
}
return false;
}
private:
vector<Data> _table;
size_t n = 0; //存储的关键字个数
};
2.5.2二次探测
解决哈希冲突的方法:i-1^2 ,i+2^2 ,i-3^2 ,1+4^2 …
这两种探测方式都会导致同类hash聚集;也就是近似值它的hash值也近似,那么它的数组槽位也靠近,形成hash聚集;第⼀种同类聚集冲突在前,第⼆种只是将聚集冲突延后;
二次探测的实现:只需要将hashi = starti + i修改为hashi = starti + flagi * i;flag=-1flag即可。
2.6开散列【哈希桶】
开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
哈希的链式结构
在Hash Table下面挂一个桶,桶中存的是发生哈希冲突的元素。
数据量少的时候可以挂链表,数据量大的时候可以挂RBTree。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ge7dqfHJ-1663235810203)(C:/Users/%E5%88%98%E9%91%AB/AppData/Roaming/Typora/typora-user-images/image-20220907005914062.png)]](https://img-blog.csdnimg.cn/7b0117f03d6748bb913ae443ef55cefe.png)
2.7开散列实现哈希结构
我们在哈希表的下面挂上链表存放数据。其他操作和闭散列的实现方式相似。
具体的实现可见码云:哈希 · 影中人/mylx - 码云 - 开源中国 (gitee.com)