Elasticsearch
一、ES介绍
Redis可以使用内存加载数据并实现数据快速访问,MongoDB可以在内存中存储类似对象的数据并实现数据的快速访问,在企业级开发中对于速度的追求是永无止境的。ES也是一款NoSQL解决方案,只不过他的作用不是为了直接加速数据的读写,而是加速数据的查询的。
ES(Elasticsearch)是一个分布式全文搜索引擎,重点是全文搜索。
那什么是全文搜索呢?比如用户要买一本书,以Java为关键字进行搜索,不管是书名中还是书的介绍中,甚至是书的作者名字,只要包含java就作为查询结果返回给用户查看,上述过程就使用了全文搜索技术。搜索的条件不再是仅用于对某一个字段进行比对,而是在一条数据中使用搜索条件去比对更多的字段,只要能匹配上就列入查询结果,这就是全文搜索的目的。而ES技术就是一种可以实现上述效果的技术。
要实现全文搜索的效果,不可能使用数据库中like操作去进行比对,这种效率太低了。ES设计了一种全新的思想,来实现全文搜索。具体操作过程如下:
-
将被查询的字段的数据全部文本信息进行查分,分成若干个词
- 例如“中华人民共和国”就会被拆分成三个词,分别是“中华”、“人民”、“共和国”,此过程有专业术语叫做分词。分词的策略不同,分出的效果不一样,不同的分词策略称为分词器。
-
将分词得到的结果存储起来,对应每条数据的id
-
例如id为1的数据中名称这一项的值是“中华人民共和国”,那么分词结束后,就会出现“中华”对应id为1,“人民”对应id为1,“共和国”对应id为1
-
例如id为2的数据中名称这一项的值是“人民代表大会“,那么分词结束后,就会出现“人民”对应id为2,“代表”对应id为2,“大会”对应id为2
-
此时就会出现如下对应结果,按照上述形式可以对所有文档进行分词。需要注意分词的过程不是仅对一个字段进行,而是对每一个参与查询的字段都执行,最终结果汇总到一个表格中
| 分词结果关键字 |
对应id |
| 中华 |
1 |
| 人民 |
1,2 |
| 共和国 |
1 |
| 代表 |
2 |
| 大会 |
2 |
- 当进行查询时,如果输入“人民”作为查询条件,可以通过上述表格数据进行比对,得到id值1,2,然后根据id值就可以得到查询的结果数据了。
上述过程中分词结果关键字内容每一个都不相同,作用有点类似于数据库中的索引,是用来加速数据查询的。但是数据库中的索引是对某一个字段进行添加索引,而这里的分词结果关键字不是一个完整的字段值,只是一个字段中的其中的一部分内容。并且索引使用时是根据索引内容查找整条数据,全文搜索中的分词结果关键字查询后得到的并不是整条的数据,而是数据的id,要想获得具体数据还要再次查询,因此这里为这种分词结果关键字起了一个全新的名称,叫做倒排索引。
使用ES其实准备工作还是挺多的,必须先建立文档的倒排索引,然后才能继续使用。
二、安装Elasticsearch
windows版安装包下载地址:https://www.elastic.co/cn/downloads/elasticsearch
将压缩包下载后,解压
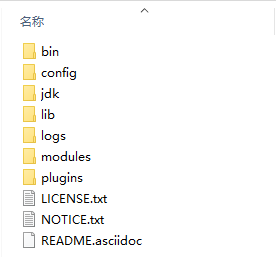
- bin目录:包含所有的可执行命令
- config目录:包含ES服务器使用的配置文件
- jdk目录:此目录中包含了一个完整的jdk工具包,版本17,当ES升级时,使用最新版本的jdk确保不会出现版本支持性不足的问题
- lib目录:包含ES运行的依赖jar文件
- logs目录:包含ES运行后产生的所有日志文件
- modules目录:包含ES软件中所有的功能模块,也是一个一个的jar包。和jar目录不同,jar目录是ES运行期间依赖的jar包,modules是ES软件自己的功能jar包
- plugins目录:包含ES软件安装的插件,默认为空
启动ES(双击即可)
浏览器访问
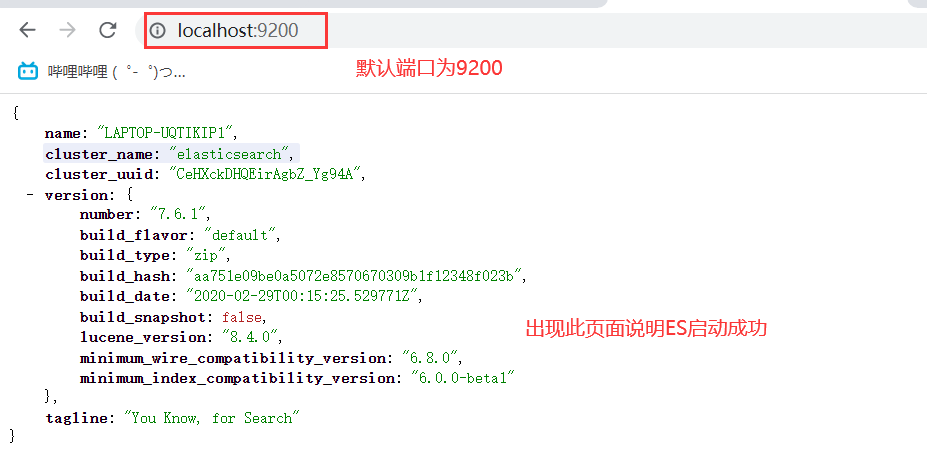
9200:表示公开对外的端口号
9300:表示集群成员之间的端口号
三、安装Kibana
1、kibana是es数据的前端展现,数据分析时,可以方便地看到数据。作为开发人员,可以方便访问es。
https://www.elastic.co/cn/downloads/
历史版本下载:https://www.elastic.co/cn/downloads/past-releases/
2、下载,解压kibana。
3、启动Kibana:bin\kibana.bat
浏览器访问 http://localhost:5601
默认端口为:5601
可能会出现的问题:
运行Kibana.bat,启动失败,报错大概意思是已经存在一个启动的Kibana了,但明明是第一次启动
报错:
[warning][savedobjects-service] Unable to connect to Elasticsearch.
Error: [resource_already_exists_exception] index [.kibana_task_manager_1/_2s2vHazSRqCl7dPlZ_oQQ] already exists, with { index_uuid="_2s2vHazSRqCl7dPlZ_oQQ" & index=".kibana_task_manager_1" }
在cmd中运行如下命令:
curl -X DELETE http://localhost:9200/.kibana*
四、介绍ES中的一些概念
集群
集群这一概念已经遍及天下了,在Elasticsearch中也不例外,可以将多台Elasticsearch节点组成集群使用,可以在任意一台节点上进行搜索。
节点
节点是一台Elasticsearch服务器,可以存储、查询、创建索引,也可以与其它节点一共组成一个集群。
索引—数据库
索引是具有某种相似特性的文档集合,熟悉mysql的应该不会对于这个名词陌生,Elasticsearch使用的是倒排索引。
文档—数据库中表中一条记录
一个文档是一个可以被索引的基础信息单元。
分片
单个索引包含数据太大的话,将会降低索引速度。为此,Elasticsearch提供了将索引细分成多个片段的能力,就是分片。
副本
副本是ElasticSearch索引分片的备份,主要应对与节点故障时保存数据的可用性。副本与它的原始分片不会在同一个节点上,以此来保存单节点故障时的高可用。
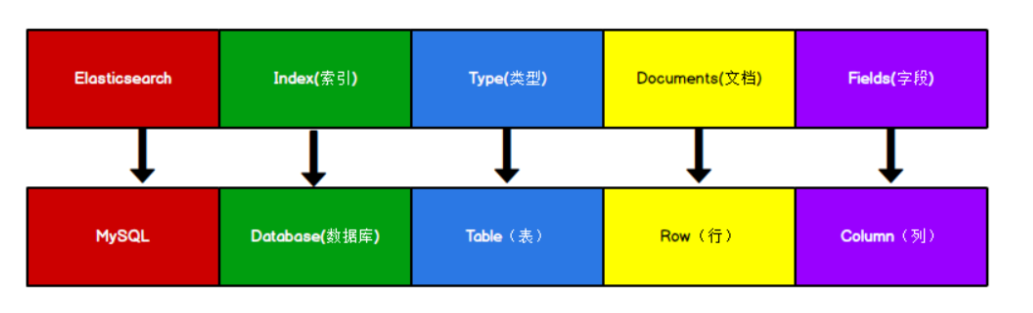
注意: ES6.0以后Type这个概念模糊了,7.0以后不在使用Type. 默认索引的type都是_doc。
五、操作ES
ES中提供了大量的接口—这些接口要想访问必须按照restful风格来访问。
POST 添加操作 DELETE 删除操作 PUT 修改操作 GET 查询操作
可以在地址栏以地址的形式传递参数 /user/1
5.1索引
5.1.1 创建索引
PUT /索引名称
{
"mappings":{
"properties":{
"字段名": {"type":"数据类型"}
"字段名":{"type":"数据类型"},
}
}
}
类型: text字符串类型 数字类型:int double
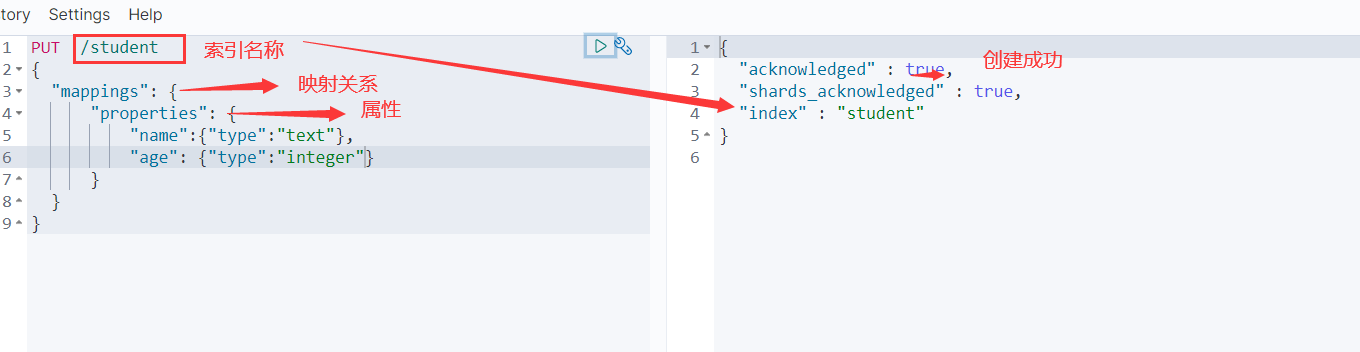
创建索引并指定分词器
前面创建的索引是未指定分词器的,可以在创建索引时添加请求参数,设置分词器。目前国内较为流行的分词器是IK分词器,使用前先在下对应的分词器,然后使用。
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
分词器下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。使用IK分词器创建索引格式:
PUT请求 http://localhost:9200/books
#请求参数如下(注意是json格式的参数)
{
"mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性
"properties":{ #定义索引中包含的属性设置
"id":{ #设置索引中包含id属性
"type":"keyword" #当前属性可以被直接搜索
},
"name":{ #设置索引中包含name属性
"type":"text", #当前属性是文本信息,参与分词
"analyzer":"ik_max_word", #使用IK分词器进行分词
"copy_to":"all" #分词结果拷贝到all属性中
},
"type":{
"type":"keyword"
},
"description":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
创建完毕后返回结果和不使用分词器创建索引的结果是一样的,此时可以通过查看索引信息观察到添加的请求参数mappings已经进入到了索引属性中

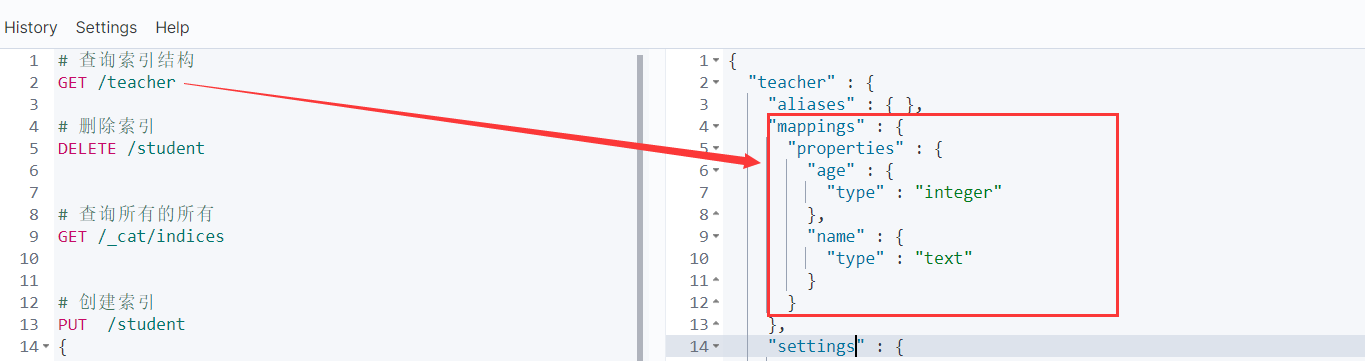
5.1.2 查询所有索引
GET /_cat/indices
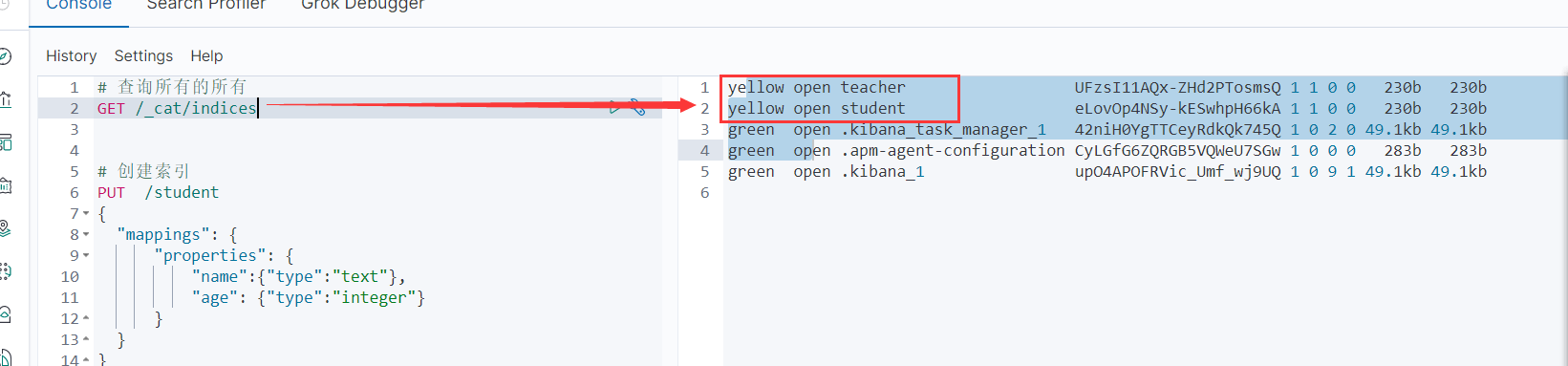
5.1.3 删除索引
DELETE /索引名称

5.1.4 查询索引结构
GET /索引名称
####################索引######################
# 创建索引
PUT /student
{
"mappings": {
"properties": {
"name":{"type": "text"},
"age":{"type": "integer"}
}
}
}
PUT /teacher
{
"mappings": {
"properties": {
"name":{"type": "text"},
"age":{"type": "integer"},
"address":{"type": "text"}
}
}
}
# 查询所有索引
GET /_cat/indices
# 查询索引结构
GET /student
# 删除索引
DELETE /teacher
5.2 文档
5.2.1 添加文档
指定id添加 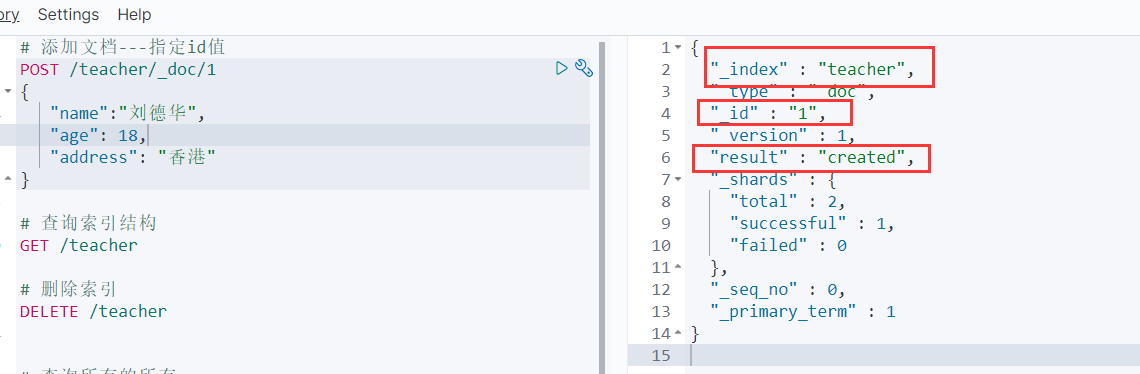
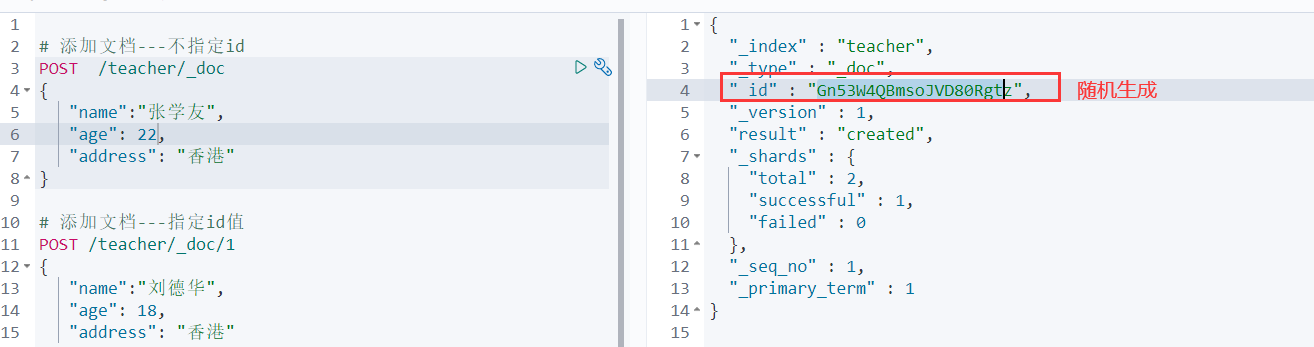
不指定id添加。—ES会生成一个唯一随机的字符串
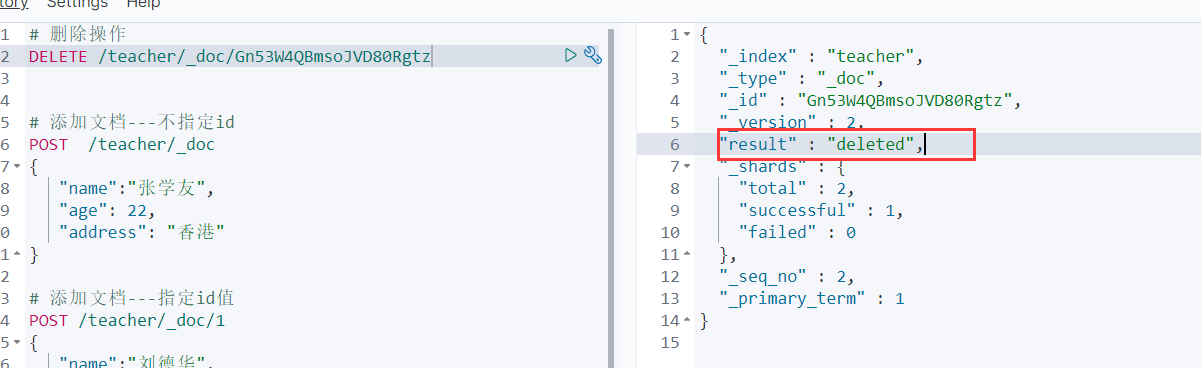
5.2.2 删除文档
DELETE /索引名称/_doc/id值
5.2.3 查询文档
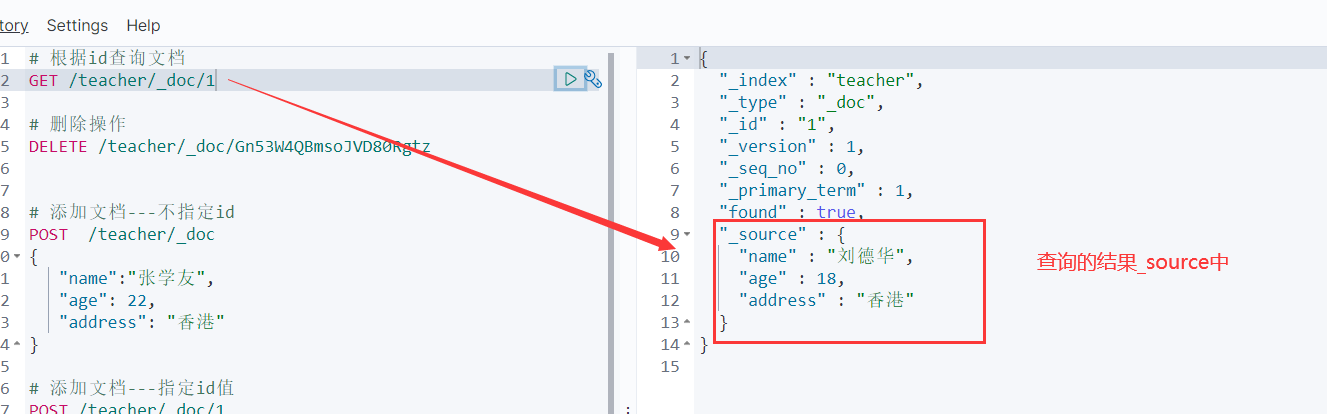
5.2.1 修改文档
第一种: 需要指定所有被修改的字段名,如果没有指明的字段则会消失
# 修改文档(修改为下面的,没有列出的属性,会被删除)
PUT /teacher/_doc/1
{
"name":"尚腾飞",
"age":16
}
没有指明的字段则会消失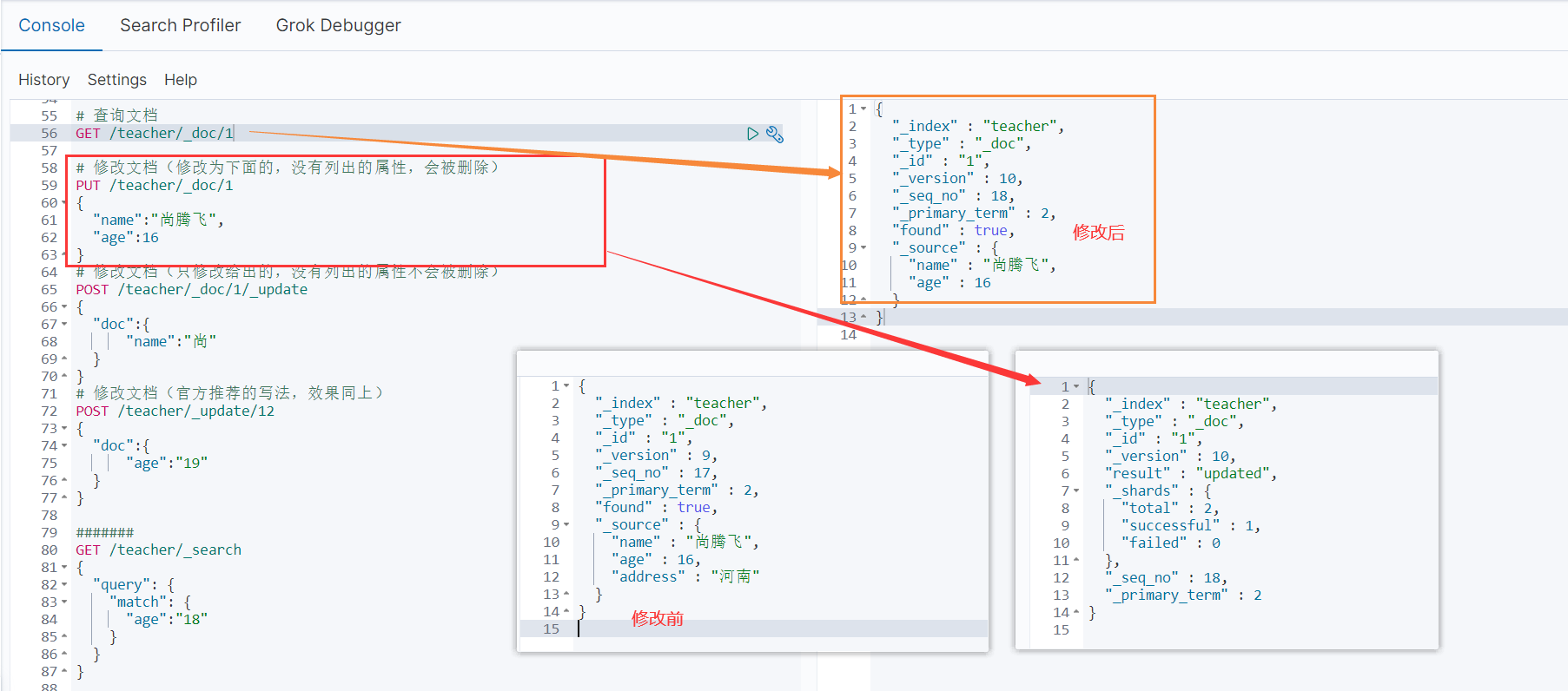
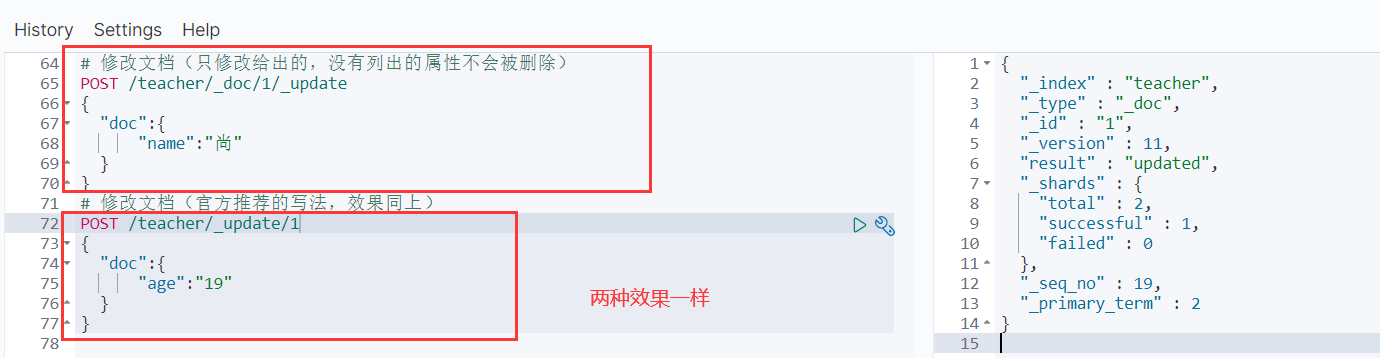
第二种: 修改部分字段。没有指明的字段不会消失
####################文档######################
# 指定id,添加文档
POST /teacher/_doc/1
{
"name":"刘德华",
"age":18,
"address":"香港"
}
# 不指定id添加。---ES会生成一个唯一随机的字符串
POST /teacher/_doc
{
"name":"张学友",
"age":18,
"address":"香港"
}
# 删除文档
DELETE /teacher/_doc/0W2lW4QBTTQOPynSggAc
# 查询文档
GET /teacher/_doc/1
# 修改文档(修改为下面的,没有列出的属性,会被删除)
PUT /teacher/_doc/1
{
"name":"尚腾飞",
"age":16
}
# 修改文档(只修改给出的,没有列出的属性不会被删除)
POST /teacher/_doc/1/_update
{
"doc":{
"name":"尚"
}
}
# 修改文档(官方推荐的写法,效果同上)
POST /teacher/_update/1
{
"doc":{
"name":"尚1"
}
}
5.3 根据其他条件查询文档内容
5.3.1 查询索引中的所有文档内容
MySql : select * from 表名
ES: GET /索引名称/_search
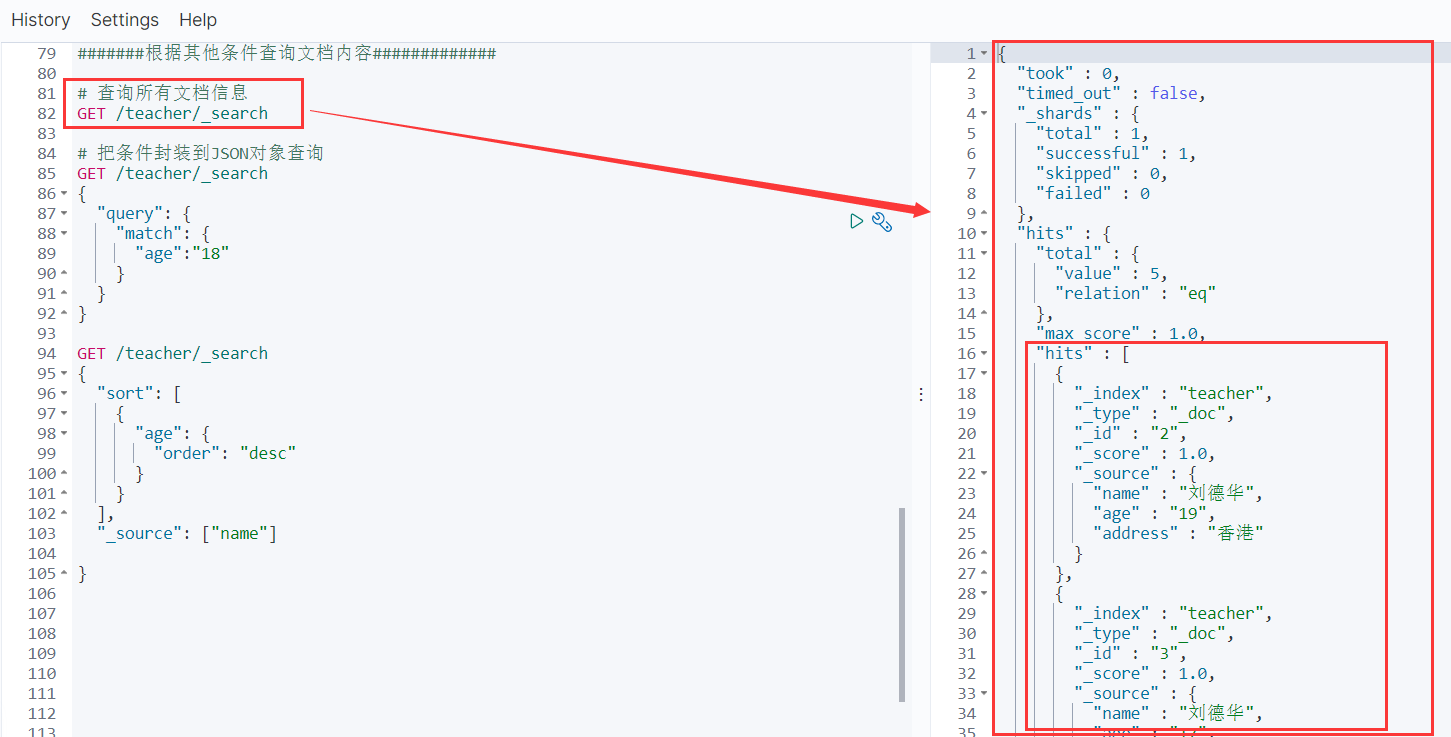
查询所有文档信息,我们想要的结果封装到了hits中
5.4 根据其他条件查询
mysql: select name from 表名 where 其他字段=值
ES: GET /索引名称/_search?q=列名:值
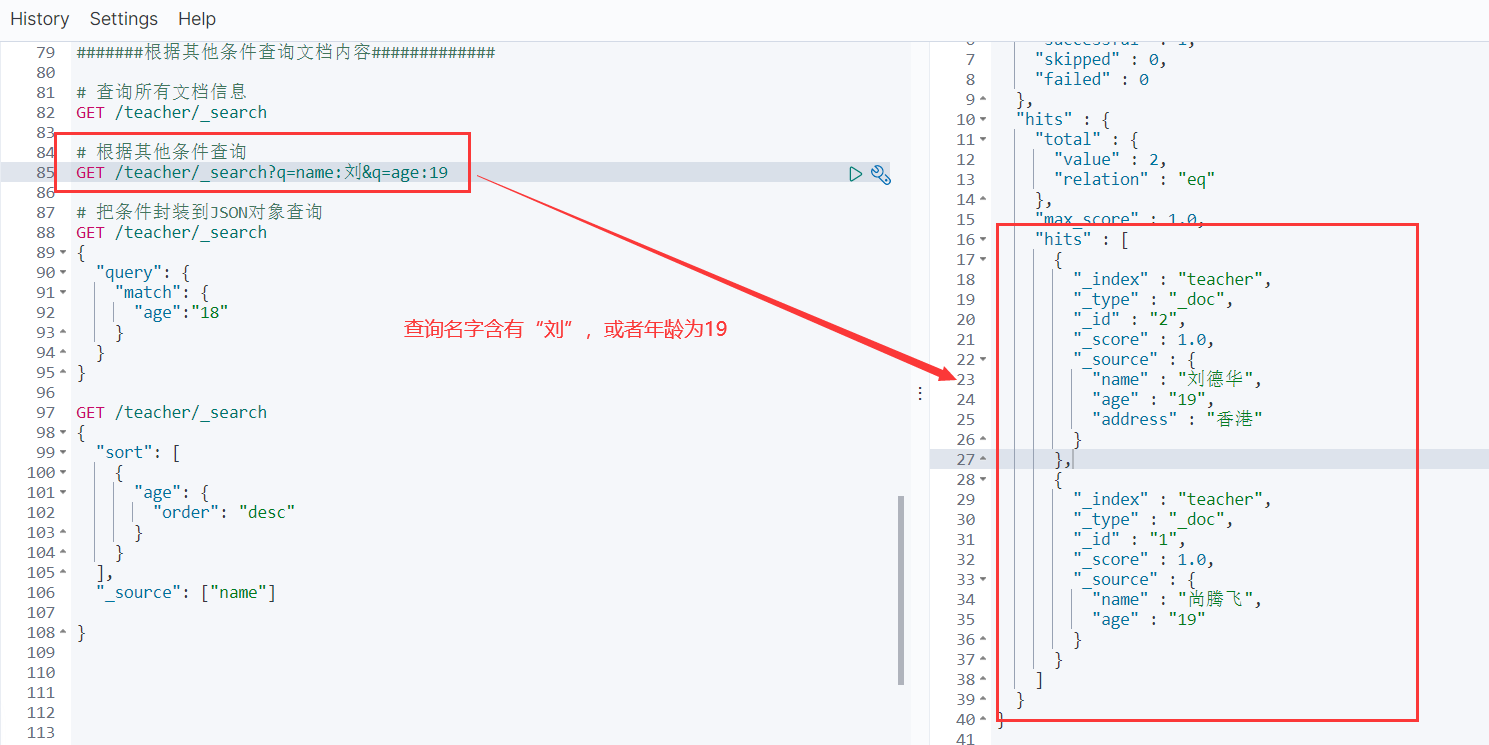
5.5把查询的条件封装到json对象中—重点

注意: 排序按照数字,日期来排序。
mysql: 分页使用limit完成。 select * from 表名 limit (起始记录),每页的条数。
ES: “from”: 起始记录, “size”: 每页的条数
5.6 多条件查询
must等价于and
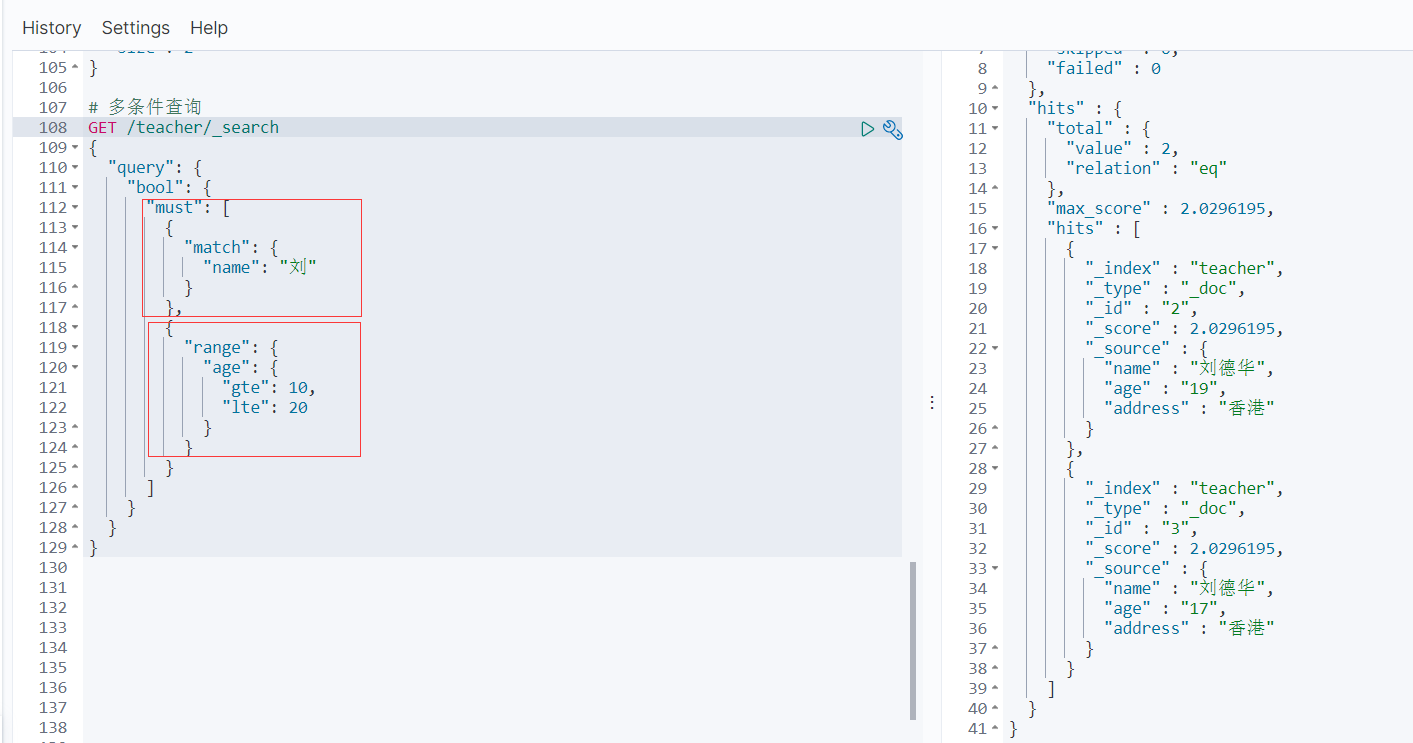
should 等价于 or

must_not 等价于 !

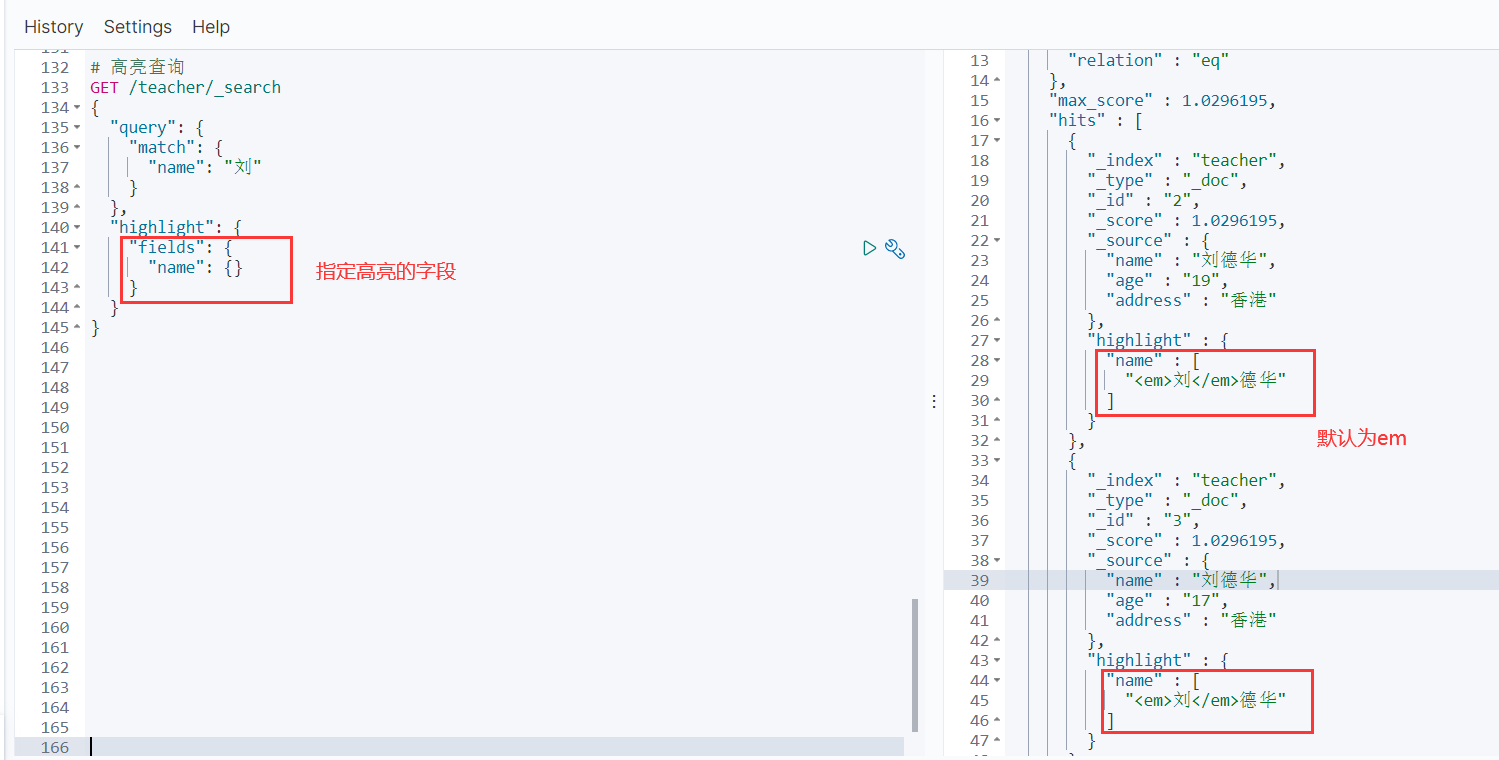
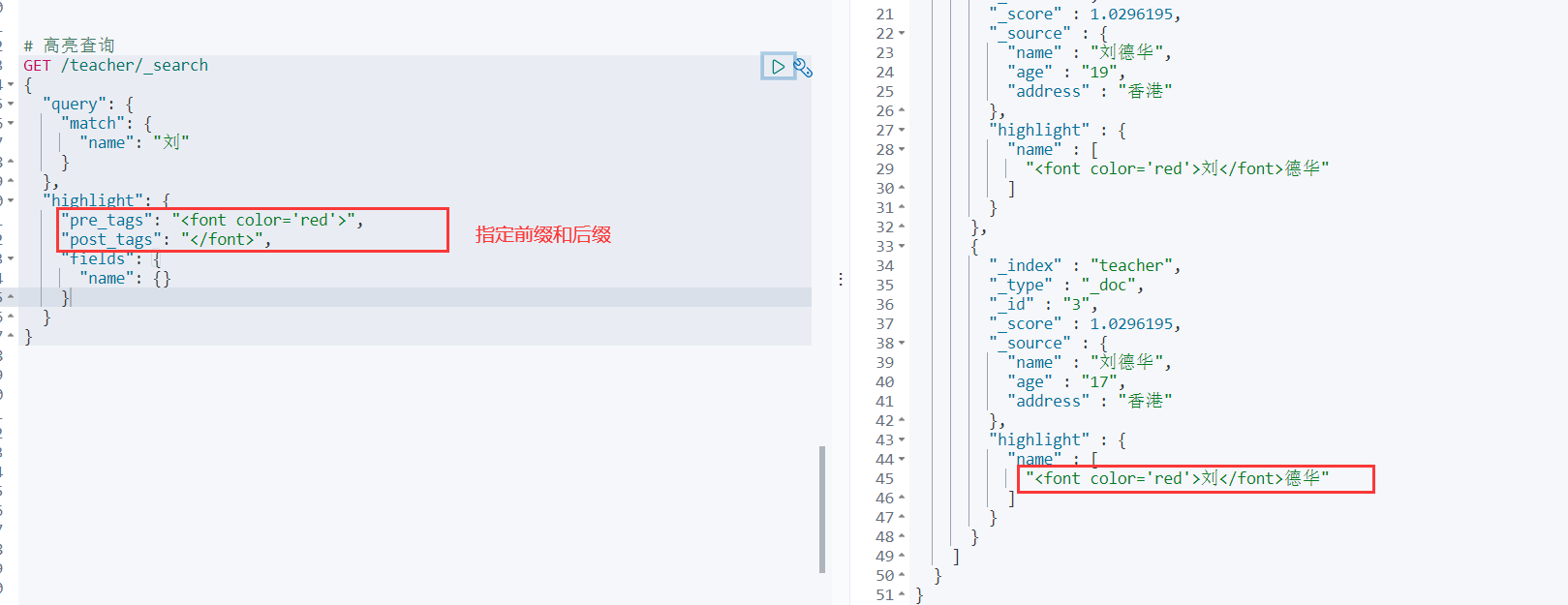
5.7 高亮查询
指定前缀后缀
上面我们把所有对应ES操作的API接口文档测试了一遍。下面使用springboot整合ES
【springboot整合ES】springboot整合ES
springboot整合es