Motivation:
- 机器能够利用人看不见的pattern对目标进行分类,当测试时pattern不变,那么这些pattern是有益的,被称为predictive features,而当他们在攻击中被篡改时,他们就是混淆因子。本文希望通过因果干预,去除混淆因子对输入图片的影响。但这是困难的,因为本任务中的混淆因子不可见,因此本文提出用工具变量来实现因果干预。
- 受视网膜成像的启发,本文认为人的视觉系统之所以能够免受混淆因子的影响,是因为存在Retinopic Sampling,简单来说,Retinopic Sampling和成像相关,和混淆因子无关。我们希望通过建立R和X的关系,用R表示的X去除C的影响,进而求得鲁棒的X和Y之间的关系。
实现:
R的详细定义见附录B,本文在4.3推出 ,进一步定义
,进一步定义 ,可得:
,可得:
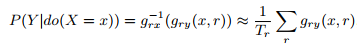
最后本文发现上式收敛困难,因此借用non-linear instrumental variable estimation methods中的Asymptotic-Variance Convergence (AVC) loss帮助收敛:
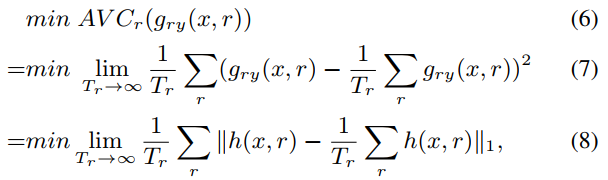
这篇文章6.17挂上arxiv,感觉是用来占坑的半成品。代码在:https://github.com/KaihuaTang/Adversarial-Robustness-by-Causal-Intervention.pytorch
摘要:
- 对抗训练常用于防御对抗样本。但由于是被动防御,因此无法免疫未知攻击。为了积极防御,我们需要对对抗样本有更基础的了解,不能仅限于bounded threat model。
- 本文提供一个因果视角:confounder在学习中无处不在。因此,改善鲁棒性的方法是因果干预。由于confounder是不可见的,我们提出使用工具变量(instrumental variable)来实现干预。
- 本文的鲁棒训练方法叫做:Causal intervention by instrumental Variable (CiiV)。CiiV有一个可导的Retinotopic sampling layer和consistency loss,保证模型不会梯度混淆(Gradient Obfuscation)
- 在MNIST,CIFAR-10和mini-ImageNet数据上,本方法都证明了有效性。
引言:
- 防御存在的问题:(1)lack fair benchmarking (e.g. adaptive adversary);(2)misconduct the attack (e.g., obfuscated gradient),通过给attaker错误的梯度使基于梯度下降的对抗样本失效。因此,大部分有效的防御方法仍然是Adversarial Training。而对抗训练是否有效,又取决于是否有尽可能多的,来自不同攻击方法产生的对抗样本。
- 对抗训练是主动免疫,无法应对不断进化的攻击方法。对抗样本不是bugs,而是predictive features,仅能被机器利用。人类的神经元数量和复杂度远超机器,提取的特征更多,为什么人类可以自动忽略predictive features。
- 本文认为adversarial attacks是confounding effects。一些人无法察觉的模式(pattern),例如局部纹理,small edges和faint shadows等,当和标签相关时,就是confounder;当训练和测试的confounder是一致时,被视作predictive feature。由于它不可能被观测,考虑引入R(Retinotopic sampling)作为工具变量,去除C对X的影响。在工程上的时候,还需要consistency loss。

近期工作:
- Adversarial Examples. Defenders用于提高对抗鲁棒性,一些defenders受biological vision systems启发。整体来说,可以分为五类:(1) adversarial training; (2) data augmentation; (3) generative classifier; (4) de-nosing; (5) certified defense.
- Causality in Computer Vision. 因果推理常用做缓解数据偏见。造成对抗扰动的混淆因子通常是不可见。
Preliminaries
- 因果图:R: retinotopic(Retinotopy,视网膜拓扑映射) sampling;C: confounding perturbation;X: image;Y: prediction;X <- C -> Y: confounder C 会影响X和Y的分布,例如:图片中线条的分布;X -> Y: robust prediction model
- Causal Intervention:存在三种干预:backdoor adjustment,front-door adjustment和instrumental vairable。 前两者假设confounders或mediators是可观测的,因此,鉴于adversarial robustness的特性,本文使用instrumental variable.
-
Instrumental Variable :如Figure 2(b)所示,一个有效的instrumental variable应该满足:(1)和confounder variable是正交的;(2)它仅能通过X来影响Y。因此,instrumental variable能够从R->X->Y中提取X->Y的causal effect(不受C的干扰(已经被d-separated))。感谢colliding junction R-> X <- C。
- 以最常见的2SLS(Two-Stage Least Squares)为例,第一步是用工具变量R做自变量,对X进行回归,得出一系列参数,将X分为由Z决定的,和与Z无关的两部分,这两者是正交的。工具变量的定义是和X相关,和C无关,因此Z决定的部分就是和C无关的部分。之后使用X'=γZ代替原来的X。
- 混淆梯度:这种防御方式可能会导致对对抗样本防御安全感的错误判断;梯度掩码:该机制的核心思想在于构建一个没有有用的梯度的模型,如使用最近邻算法(KNN)而不是深度神经网络(DNN)。
Approach
biological reitna:photoreceptors,bipolar cell和多种神经元。
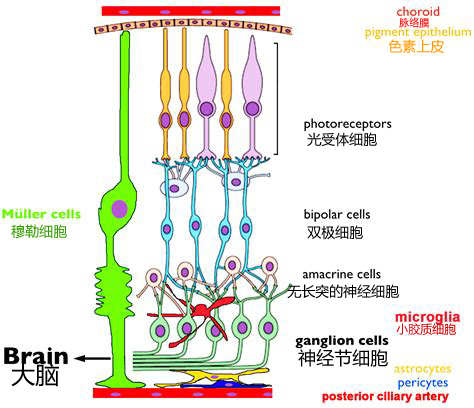


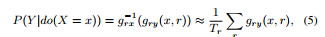
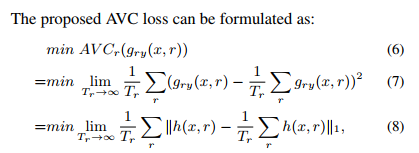
实验
- Threat models: FGSM,PGD-20,PGD-20 (l2)和C&W
- Defenders:Adversarial Training (AT):FGSM-AT,PGD-20-AT,PGD-20-AT(l2)。Non-AT:Mixup、BPFC和RS (参考:https://blog.csdn.net/mtandhj/article/details/108738418)。
- Anti-Obfuscated-Gradient Attack:一般不对抗训练就不容易出现混淆梯度。一般来说混淆梯度的防御方法是将测试梯度和原始求得的梯度区分开,使他们不像。而BPDA就是怼混淆梯度的攻击方法。
- Adaptive Attack