简单说几句
- 简单说几句,算法的基本逻辑请看其他文章,很多,不介绍。本文旨在提供一份python代码供各位后来学习者多一些资料理解学习ACO,同时对于那些只需简单使用ACO解决路径规划的人提供一个并不麻烦的途径。
- 注意,非路径规划,非栅格图模型的,本文代码99.99%无法运行!
- 本文所提供ACO实际中已测试过50规格的栅格图任务,若效果不好,请调节算法参数,默认参数在解决20规格栅格问题上效果还行。
python代码
0.预安装库
pip install numpy pandas pygame matplotlib #四个库
pip install lddya==2.0.1 #作者的自用库,里面有一些工具下文会用到
1.调用模版
from lddya.Algorithm import ACO #导入ACO算法
from lddya.Draw import ShanGeTu,IterationGraph #导入栅格图、迭代图的绘制模块
from lddya.Map import Map #导入地图文件读取模块
m = Map()
m.load_map_file('map.txt') # 读取地图文件
aco = ACO(map_data=m.data,start=[0,0],end=[19,19]) #初始化ACO,不调整任何参数的情况下,仅提供地图数据即可,本行中数据由Map.data提供,start跟end都是[y,x]格式,默认[0,0],[19,19]。
aco.run() # 迭代运行
sfig = ShanGeTu(map_data = m.data) # 初始化栅格图绘制模块
sfig.draw_way(aco.way_data_best) # 绘制路径信息,路径数据由ACO.way_data_best提供。
sfig.save('123.jpg') #保存栅格图数据为'123.jpg'
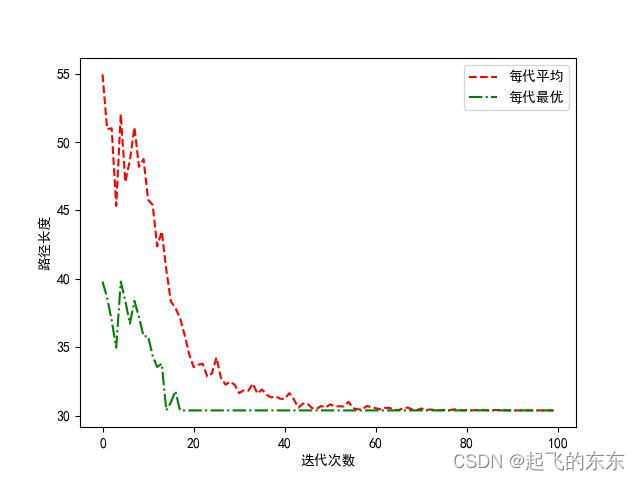
dfig = IterationGraph(data_list= [aco.generation_aver,aco.generation_best], #绘制数据: 每代平均、每代最优路径信息
style_list=['--r','-.g'], # 线型 (规则同plt.plot()中的线型规则)
legend_list=['每代平均','每代最优'], # 图例 (可选参数,可以不写)
xlabel='迭代次数', # x轴标签,默认“x”
ylabel= '路径长度' # y轴标签,默认“y”
) # 初始化迭代图绘制模块
dfig.save('321.jpg') #迭代图保存为321.jpg
2.地图文件
下面为某地图文件内容,数字位置与栅格图的黑白栅格一一对应。
PS: 注意,Map.data本质上是基于numpy的0-1矩阵。
00000000110100000000
00111000100000100000
00100110001100100110
00000011101100000110
00110011100001110000
00110000000111011110
00000010000111011110
00001011110111011110
00001001000000000000
00001101001111000000
00000101101111000000
01110000101111000000
01110011101111000000
01110011100001010000
11000111111001000010
00000011100001110000
00000011100001111000
01100011101100001110
01101000000100000000
00000000000000000000
3.栅格图+迭代图
下图所示的栅格图即为上文的栅格数据文件对应的图,左上角栅格坐标为[0,0],向下y增大,向右x增大。所以右下角为[19,19]。
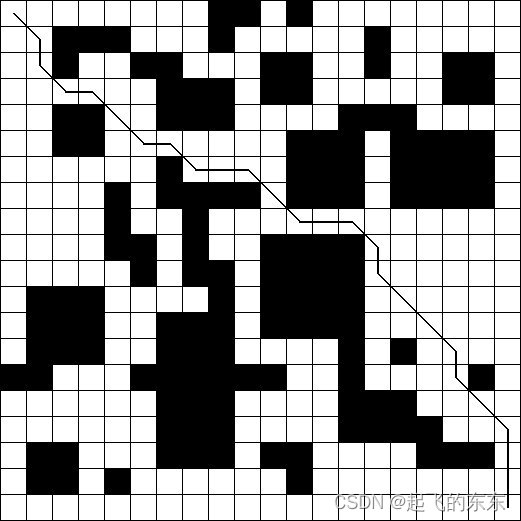
下图就是算法的迭代图。
3.ACO类
如果你只是想使用ACO解决问题,下面的内容就不用看了,效果不好就调参吧。考虑存在朋友仅想阅读代码,这里我附一下ACO的代码供学习参考。
class Ant():
def __init__(self,max_step,pher_imp,dis_imp) -> None:
self.max_step = max_step # 蚂蚁最大行动力
self.pher_imp = pher_imp # 信息素重要性系数
self.dis_imp = dis_imp # 距离重要性系数
self.destination = [19,19] # 默认的终点节点(在run方法中会重新定义该值)
self.successful = True #标志蚂蚁是否成功抵达终点
self.record_way = [[0,0]] #路径节点信息记录
def run(self,map_data,pher_data,posi = None,dest = None):
#Step 0:把蚂蚁放在起点处
if posi == None:
self.position = [0,0] #蚂蚁初始位置[y,x] = [0,0],考虑到列表索引的特殊性,先定y,后定x
if dest == None:
self.destination = [len(map_data)-1,len(map_data)-1]
#Step 1:不断找下一节点,直到走到终点或者力竭
for i in range(self.max_step):
r = self.select_next_node(map_data,pher_data)
if r == False:
self.successful = False
break
else:
if self.position == self.destination:
break
else:
self.successful = False
def select_next_node(self,map_data,pher_data):
'''
Function:
---------
选择下一节点,结果直接存入self.postion,仅返回一个状态码True/False标志选择的成功与否。
'''
y_1 = self.position[0]
x_1 = self.position[1]
#Step 1:计算理论上的周围节点
node_be_selected = [[y_1-1,x_1-1],[y_1-1,x_1],[y_1-1,x_1+1], #上一层
[y_1,x_1-1], [y_1,x_1+1], #同层
[y_1+1,x_1-1],[y_1+1,x_1],[y_1+1,x_1+1], #下一层
]
#Step 2:排除非法以及障碍物节点
node_be_selected_1 = []
for i in node_be_selected:
if i[0]<0 or i[1]<0:
continue
if i[0]>=len(map_data) or i[1]>=len(map_data):
continue
if map_data[i[0]][i[1]] == 0:
node_be_selected_1.append(i)
if len(node_be_selected_1) == 0: # 如果无合法节点,则直接终止节点的选择
return False
if self.destination in node_be_selected_1: # 如果到达终点旁,则直接选中终点
self.position = self.destination
self.record_way.append(copy.deepcopy(self.position))
map_data[self.position[0]][self.position[1]] = 1
return True
#Step 3:计算节点与终点之间的距离,构建距离启发因子
dis_1 = [] # 距离启发因子
for i in node_be_selected_1:
dis_1.append(((self.destination[0]-i[0])**2+(self.destination[1]-i[1])**2)**0.5)
#Step 3.1:倒数反转
for j in range(len(dis_1)):
dis_1[j] = 1/dis_1[j]
#Step 4:计算节点被选中的概率
prob = []
for i in range(len(node_be_selected_1)):
p = (dis_1[i]**self.dis_imp) * (pher_data[y_1*len(map_data)+x_1][node_be_selected_1[i][0]*len(map_data)+node_be_selected_1[i][1]]**self.pher_imp)
prob.append(p)
#Step 5:轮盘赌选择某节点
prob_sum = sum(prob)
for i in range(len(prob)):
prob[i] = prob[i]/prob_sum
rand_key = np.random.rand()
for k,i in enumerate(prob):
if rand_key<=i:
break
else:
rand_key -= i
#Step 6:更新当前位置,并记录新的位置,将之前的位置标记为不可通过
self.position = copy.deepcopy(node_be_selected_1[k])
self.record_way.append(copy.deepcopy(self.position))
map_data[self.position[0]][self.position[1]] = 1
return True
class ACO():
def __init__(self,map_data,max_iter = 100,ant_num = 50,pher_imp = 1,dis_imp = 10,evaporate = 0.7,pher_init = 8) -> None:
'''
Params:
--------
pher_imp : 信息素重要性系数
dis_imp : 距离重要性系数
evaporate: 信息素挥发系数(指保留的部分)
pher_init: 初始信息素浓度
'''
#Step 0: 参数定义及赋值
self.max_iter = max_iter #最大迭代次数
self.ant_num = ant_num #蚂蚁数量
self.ant_gener_pher = 1 #每只蚂蚁携带的最大信息素总量
self.pher_init = pher_init #初始信息素浓度
self.ant_params = { #生成蚂蚁时所需的参数
'dis_imp':dis_imp,
'pher_imp': pher_imp
}
self.map_data = map_data.copy() #地图数据
self.map_lenght = self.map_data.shape[0] #地图尺寸,用来标定蚂蚁的最大体力
self.pher_data = pher_init*np.ones(shape=[self.map_lenght*self.map_lenght,
self.map_lenght*self.map_lenght]) #信息素矩阵
self.evaporate = evaporate #信息素挥发系数
self.generation_aver = [] #每代的平均路径(大小),绘迭代图用
self.generation_best = [] #每代的最短路径(大小),绘迭代图用
self.way_len_best = 999999
self.way_data_best = [] #最短路径对应的节点信息,画路线用
def run(self):
#总迭代开始
for i in range(self.max_iter):
success_way_list = []
print('第',i,'代: ',end = '')
#Step 1:当代若干蚂蚁依次行动
for j in range(self.ant_num):
ant = Ant(max_step=self.map_lenght*3,pher_imp=self.ant_params['pher_imp'],dis_imp=self.ant_params['dis_imp'])
ant.run(map_data=self.map_data.copy(),pher_data=self.pher_data)
if ant.successful == True: #若成功,则记录路径信息
success_way_list.append(ant.record_way)
print(' 成功率:',len(success_way_list),end= '')
#Step 2:计算每条路径对应的长度,后用于信息素的生成量
way_lenght_list = []
for j in success_way_list:
way_lenght_list.append(self.calc_total_lenght(j))
#Step 3:更新信息素浓度
# step 3.1: 挥发
self.pher_data = self.evaporate*self.pher_data
# step 3.2: 叠加新增信息素
for k,j in enumerate(success_way_list):
j_2 = np.array(j)
j_3 = j_2[:,0]*self.map_lenght+j_2[:,1]
for t in range(len(j_3)-1):
self.pher_data[j_3[t]][j_3[t+1]] += self.ant_gener_pher/way_lenght_list[k]
#Step 4: 当代的首尾总总结工作
self.generation_aver.append(np.average(way_lenght_list))
self.generation_best.append(min(way_lenght_list))
if self.way_len_best>min(way_lenght_list):
a_1 = way_lenght_list.index(min(way_lenght_list))
self.way_len_best = way_lenght_list[a_1]
self.way_data_best = copy.deepcopy(success_way_list[a_1])
print('平均长度:',np.average(way_lenght_list),'最短:',np.min(way_lenght_list))
def calc_total_lenght(self,way):
lenght = 0
for j1 in range(len(way)-1):
a1 = abs(way[j1][0]-way[j1+1][0])+abs(way[j1][1]-way[j1+1][1])
if a1 == 2:
lenght += 1.41421
else:
lenght += 1
return lenght
最后,祝后来诸君学习顺利!