高性能计算实验——矩阵乘法基于MPI的并行实现及优化
1.实验目的
1.1.通过MPI实现通用矩阵乘法
熟练掌握MPI编程方法,并将通用矩阵乘法转为MPI并行实现,进一步加深MPI的使用与理解。
1.2.基于MPI的通用矩阵乘法优化
进一步熟悉MPI矩阵乘法的实现,学习MPI点对点通信与集合通信的异同点和各自的优缺点,学会比较二者的性能以及各自使用的情形。
1.3.改造实验1成矩阵乘法库函数
学习如何将自己编写的代码改造为标准库函数,供其他程序调用。
理解动态链接的过程。
2.实验过程和核心代码
2.1.通过MPI实现通用矩阵乘法
2.1.1.问题描述
通过 MPI 实现通用矩阵乘法(实验1)的并行版本,MPI并行进程(rank size)从 1 增加至 8,矩阵规模从 512 增加至 2048.
问题描述:随机生成 MN 和NK 的两个矩阵 A,B,对这两个矩阵做乘法得到矩阵 C.
输入:M , N, K 三个整数(512 ~2048)
输出:A,B,C 三个矩阵以及矩阵计算的时间
2.1.2.实现过程
这里可以选择点对点通信或者集合通信的方式实现,这里选择点对点方式,使用MPI_Send、MPI_Recv函数进行进程通信。
思想:
最简单的实现,按行并行:
主进程不参与计算,只负责分发和收集数据。在主进程中,A根据处理器数按行划分为大致相等的N部分,然后将部分的A和全部的B传递给子进程。子进程计算部分乘法并返回结果,主进程收集并整合报告结果。使用最简单的Send和Recv进行通信。
2.1.3.核心代码
①矩阵生成
void Gen_Matrix(int m,int n,int k){
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
A[i][j] = rand()%5;
}
}
for(int i=0;i<n;i++){
for(int j=0;j<k;j++){
B[i][j] = rand()%5;
}
}
}
②MPI初始化

③获得进程数(通过bash)

④获得时间
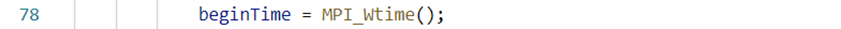
⑤主处理器

这里主处理器通过Send传递给每一个处理器n/pnum行A、与整个的B,接着接受所有子处理器返回的结果进行拼接。
⑥子处理器

这里子处理器需要相应的接受Recv主处理器Send的过来的A部分行与整个的B,接着进行计算,即matMulti函数,最后Send回结果。
⑦矩阵乘法

这里就是简单的使用朴素计算方法,为了方便,直接将结果存在了部分结果矩阵返回。
2.2.通用矩阵乘法优化
2.2.1.问题描述
分别采用 MPI 点对点通信和 MPI 集合通信实现矩阵乘法中的进程之间通信,并比较两种实现方式的性能。
上面已经采用点对点通信的方式进行了实现,接下来针对集合通信来进行实验。
2.2.2.实现过程
这里分发A时,是将A平均的分配给了各个进程,使用Scatter分发比较何时,而B要完整的分发给所有处理器,所以使用Broadcast通信更为方便,收集计算结果使用Gather。



广播是最简单但也是最有用的集体操作之一。
改用Scatter分配数据后,每个进程分配的部分矩阵具有完全相等的规模。因此。记comm_sz为进程数,矩阵的维度需要是comm_sz的倍数。我们将矩阵的维度扩展到comm_sz的倍数,多余的部分用0填充,保证正确性。
改用Scatter分配数据后,计算任务平均地分配给每一个进程,所以主进程不仅要分发收集结果,也要参与计算。如果分发的行数不够,就不能保证结果正确;如果分发的行数超出,就会出现很多不同类型的内存错误(大多都源于free时内存泄漏等原因)。
2.2.3.核心代码
①给A、B矩阵赋初值

这里必须要平均分配给各个处理器,因此有必要在不够分配时扩大矩阵,就需要在无数据的位置补零。
②获取矩阵大小,这里需要假设矩阵大小相同(通过bash)
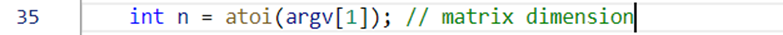

后续处理,将真实矩阵大小扩展到处理器个数的倍数。
③MPI初始化
同上第一部分;
④主线程

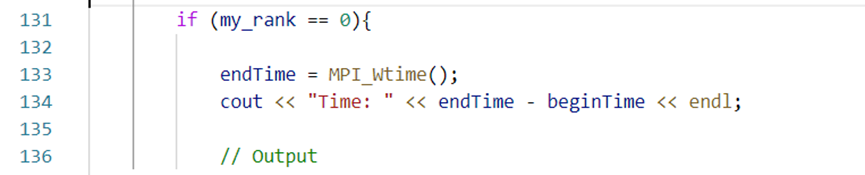
主线程额外进行初始化矩阵以及计算并输出时间的工作

使用Scatter平均分发A的行,Bcast分发B。

使用Gather收集结果。
⑤所有处理器计算

MatMulti函数与上面实验相同。
2.3.改造实验1成矩阵乘法库函数
2.3.1.问题描述
将Lab1 的矩阵乘法改造为一个标准的库函数 matrix_multiply(函数实现文件和函数头文件),输入参数为三个完整定义矩阵(A,B,C),定义方式没有具体要求,可以是二维矩阵,也可以是 struct 等。在 Linux 系统中将此函数编译为.so 文件,由其他程序调用。
2.3.2.实验过程
通常情况下,对函数库的链接是放在编译时期(compile)完成的。所有相关的对象文件(object file)与牵涉到的函数库(library)被链接合成一个可执行文件(executable file)。程序在运行时,与函数库再无关系,因为所有需要的函数已拷贝到自己门下。所以这些函数库被称为静态库(static libaray),通常文件名为“libxxx.a”的形式。
由于动态链接库函数的共享特性,它们不会被拷贝到可执行文件中。在编译的时候,编译器只会做一些函数名之类的检查。在程序运行的时候,被调用的动态链接库函数被安置在内存的某个地方,所有调用它的程序将指向这个代码段。因此,这些代码必须使用相对地址,而不是绝对地址。在编译的时候,我们需要告诉编译器,这些对象文件是用来做动态链接库的,所以要用地址无关代码(Position Independent Code (PIC))。
对gcc编译器,只需添加上 -fPIC 标签,如:=
gcc -fPIC -c file1.c
gcc -fPIC -c file2.c
gcc -shared libxxx.so file1.o file2.o
注意到最后一行,-shared 标签告诉编译器这是要建立动态链接库。这与静态链接库的建立很不一样,后者用的是 ar 命令。也注意到,动态链接库的名字形式为 “libxxx.so” 后缀名为 “.so”
2.3.3.核心代码
①Mat_mul.h头文件

这里自定义矩阵,包括行、列、矩阵体,同时声明需要的函数。
②Mat_mul.c头文件

Malloc_matrix函数用于根据矩阵rows\cols分配矩阵并进行初始化。

Free_matrix函数用于释放相应空间。

Mul_matrix函数是核心计算函数,会首先检查是否满足乘法条件。
3.实验结果
3.1.通过MPI实现通用矩阵乘法

编译得到相应的MPI程序;

执行得到2048大小的矩阵使用2个处理器时间消耗为186s

执行得到2048大小的矩阵使用4个处理器时间消耗为75s
结果可以看出在处理器足够的情况下,增加处理器数目可以大大提高运算速度,符合预期。
3.2.基于MPI的通用矩阵乘法优化
编译程序:


执行得到2048大小的矩阵使用4个处理器时间消耗为87s,2048大小的矩阵使用2个处理器时间消耗为140s。
结果可以看出在处理器足够的情况下,增加处理器数目可以大大提高运算速度,符合预期。
3.3.改造实验1成矩阵乘法库函数

编译为.so文件

改变当前动态库路径为当前目录

编写的测试文件;
测试结果:

查看链接:

自己的.so文件成功链接。
4.实验感想
本次实验是高性能实验的核心,主要是使用MPI进行矩阵乘法的实现与优化,总体来说并不是很难,需要掌握点对点与集群通信两种方式的MPI。
其中还有很多可以优化的点,比如传递给处理器的整个的B是没有必要的,我们可以简单的对B矩阵进行转置,接着把与传递A相同的几行传递给处理器即可,可以大大减少通信量。