
1.Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,我们已经安装好了Hadoop 2.7.1,其中已经包含了HDFS组件,不需要另外安装
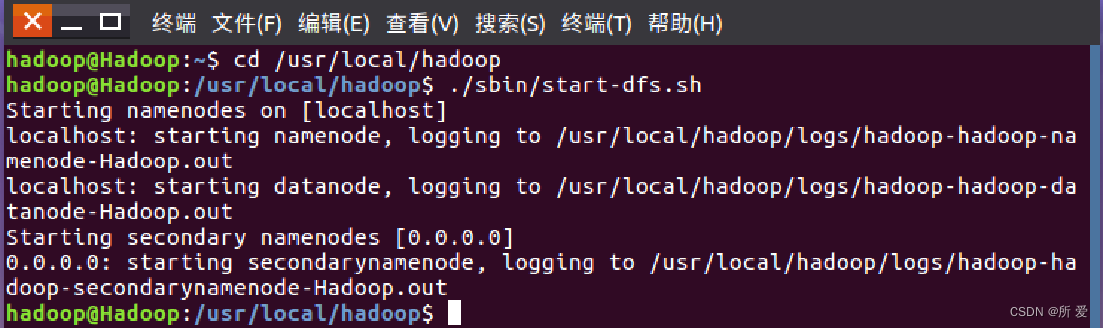
最基本的shell命令: HDFS既然是Hadoop的组件,那么首先需要启动Hadoop:启动虚拟机,打开终端,输入以下命令:
cd /usr/local/hadoop #进入 hadoop安装目录
./sbin/start-dfs.sh #启动 hadoop
可以看到,输入启动Hadoop的命令之后,在本地主机 localhost上面开始启动名称节点,然后启动数据节点,第二名称节点
2.Hadoop启动成功之后,可以开始在终端使用常用的shell命令与HDFS进行交互了: Hadoop支持很多Shell命令,其中 fs 是HDFS最常用的命令,利用 fs 可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
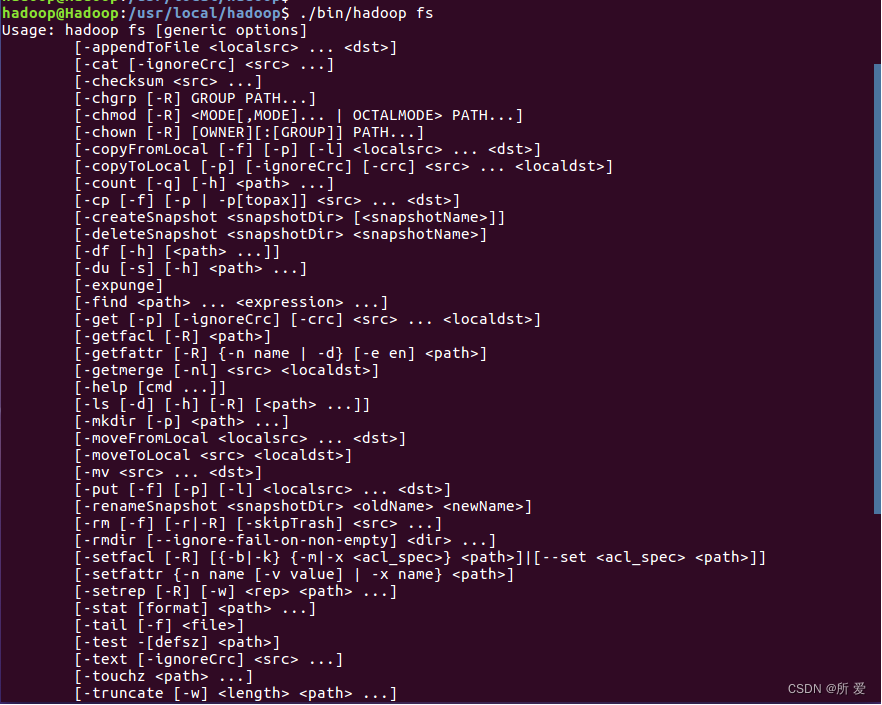
在终端输入如下命令,查看fs总共支持了哪些命令:
./bin/hadoop fs
在终端输入如下命令,可以查看具体某个命令的作用:
./bin/hadoop fs -help 某个命令的名称
比如大家喜欢的 cp:
./bin/hadoop fs -help cp

而实际上,HDFS有三种shell命令方式:
hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs:只能适用于HDFS文件系统
hdfs dfs:跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
尝试以”./bin/hadoop dfs”开头的Shell命令方式
输入了”./bin/hadoop dfs”命令之后,同样,给出了fs 总共支持了哪些命令,但是这里红框里多出了一行提示:

根据提示,尝试以”./bin/hdfs dfs”开头的Shell命令方式:
没有再出现提示:

在HDFS中,shell命令的统一格式是类似“hdfs dfs -ls”这种形式,即在“-”后面跟上具体的操作
下面开始常用的Shell操作:
1.目录操作
Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录,由于我是采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,即 user/hadoop,命令如下:
./bin/hdfs dfs –mkdir –p /user/hadoop

此命令表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。 此时,“/user/hadoop”目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:
./bin/hdfs dfs –ls .

该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录,也就是“/user/hadoop”目录,因此,上面的命令和下面的命令是等价的:
./bin/hdfs dfs –ls /user/hadoop

这个带“.”的命令 “./bin/hdfs dfs –ls . ”与下面这个命令等价:
./bin/hdfs dfs –ls

这里我们发现,这几个命令得到的结果都一样,是因为我们的HDFS使用(且只使用)过一次,时间在上面有标注,里面已经有了input和output两个文件夹,这是我们上次装hadoop伪分布式模式的时候,第五步,运行伪分布式实例的操作,我们一起来回顾一下:
运行Hadoop伪分布式实例: 单机模式下,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录
./bin/hdfs dfs -mkdir -p /user/hadoop

然后,在当前目录,即/user/hadoop/下面创建一个文件夹input,用如下命令:
./bin/hdfs dfs -mkdir input
接着用如下命令将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中: 即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中:
./bin/hdfs dfs -put ./etc/hadoop/*.xml input

复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input

可以看到其中有8个xml文件。
刚才是在/user/hadoop/下面创建了一个文件夹input,使用的命令是:
./bin/hdfs dfs –mkdir input
如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
./bin/hdfs dfs –mkdir /input
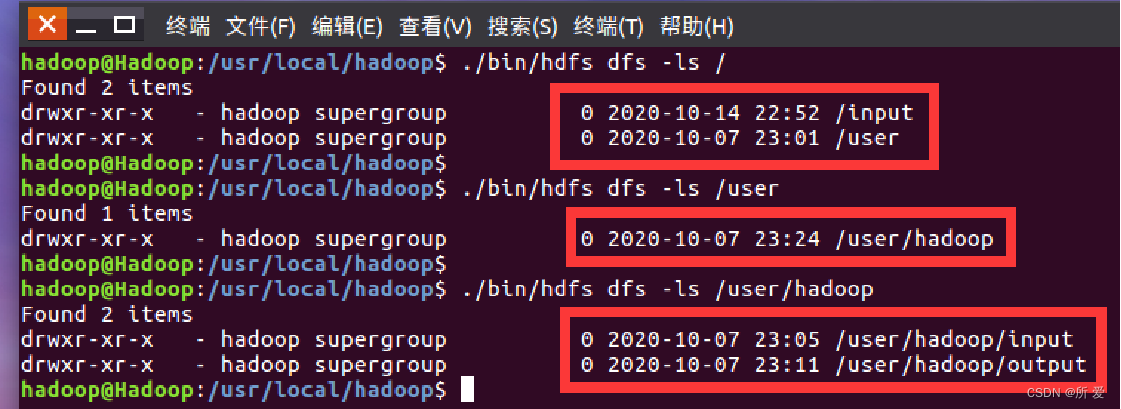
此时,我们再来对当前HDFS的各级目录里面的内容进行查看,使用如下三个命令:
./bin/hdfs dfs -ls / #查看HDFS的根目录
./bin/hdfs dfs -ls /user
./bin/hdfs dfs -ls /user/hadoop
查看的结果如下:请注意各级目录里面的内容
可以使用 rm 命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(在根目录中创建的,不是“/user/hadoop/input”目录)
./bin/hdfs dfs –rm –r /input

2. 文件操作
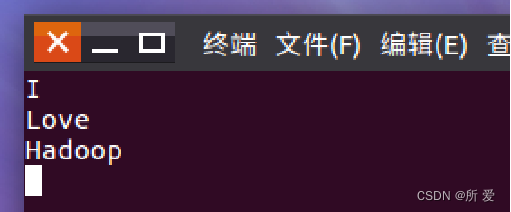
在实际应用中,经常需要从本地文件系统,即Linux的本地文件系统,向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。 首先,使用vim编辑器,在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:
这个 myLocalFile.txt 文件创建完成之后,我们使用 ls 命令可以查看到它,注意,/home/hadoop这个目录就是我们当前登录Linux的账户hadoop的主文件夹:

然后,可以使用如下命令把本地文件系统的“/home/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input

然后,使用 ls 命令查看一下文件是否成功上传到HDFS中,具体如下:
./bin/hdfs dfs –ls input

如上图红框,文件 myLocalFile.txt 已成功上传到HDFS中
下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
./bin/hdfs dfs –cat input/myLocalFile.txt

下面把HDFS中的 myLocalFile.txt 文件下载到本地文件系统中的“/home/hadoop/下载/”这个目录下,命令如下:
./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载

这里虽然报了一个警告信息,但是我们去查看一下下载这个目录,发现本次操作是成功完成了的: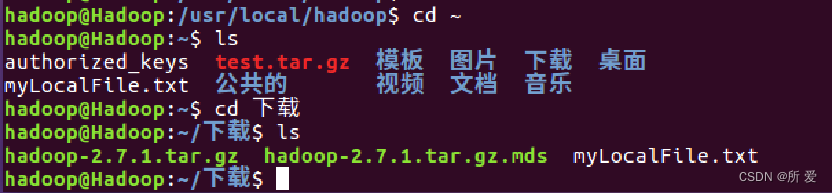
以上为本文全部内容。
由于我是新手小白,如有错误请斧正。
