目录
概念
基于二叉树的堆(二叉堆)
基于动态数组ArrayList实现的最大堆
向堆中添加元素 siftUp
在堆中取出最大值(最大堆)
3.heapify ——堆化
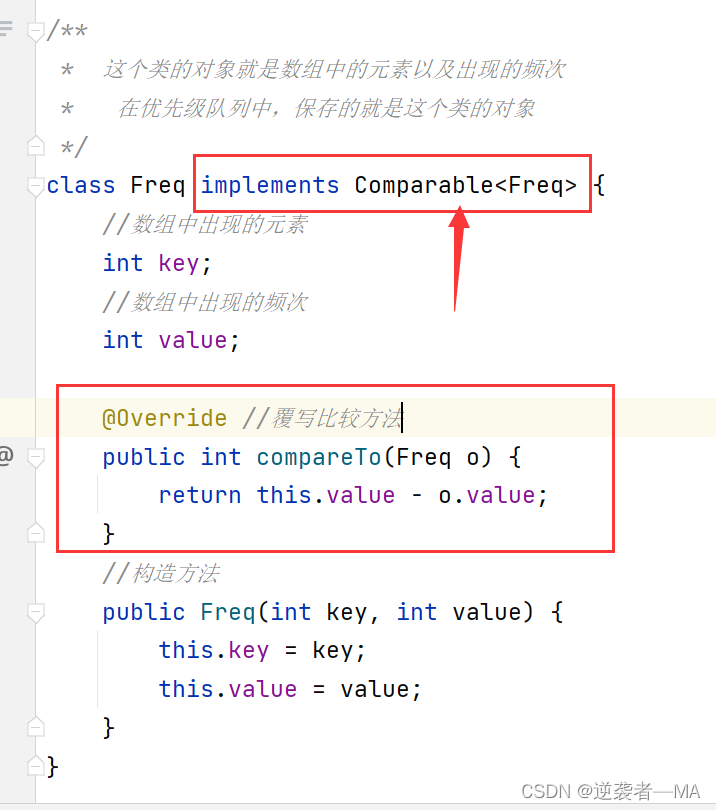
在Java中比较两个元素的大小关系:
基于堆的优先级队列到底如何实现,有啥应用
重点:优先级队列的应用问题
内部类
力扣堆的练习题
关于Map的部分相关知识
原地堆排序
概念
优先级队列(堆):按照优先级的大小动态出队(动态指的是元素个数动态变化,而非固定)
普通队列:FIFO按照元素的入队顺序出队,先入先出。
现实生活中的优先级队列 PriorityQueue
现实生活中举例:
1. 去医院医生根据你的病情安排做手术的时间。
比如说一个人是轻微的咳嗽,一个病人是流血过多。虽然是第一个病人先来的,但医院一般都是先处理时间紧迫,更加严重的病人。
病情相同的情况下,安装排序来安排时间。若病情严重者,优先安排手术。
提问:那么这和排序有啥区别呢?能否按照病情排序,然后排序后的病人数组安排手术?
有区别!排序是数组个数确定的情况。而优先级队列是动态变化的。病人的人数是在变动的。
比如在5.20安排了5.21号这天手术3人。结果到了5.21这天突然来了个病情很长严重的患者需要马上做手术,优先级队列就会安排他先做。人数数据在不停的变化。
排序指的是当前集合个数是确定的,不会发生变化。
2. 操作系统中的任务管理器
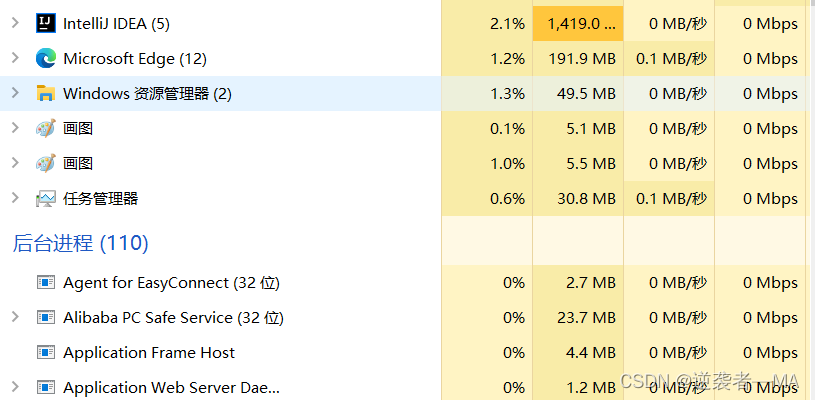
任务管理器应用的也是优先级队列。
一般来说 系统任务进程 比 普通的应用优先级更高。
还有一种情况,CPU和内存在电脑中都是有限的,当资源不够用时,优先让优先级高的的应用获取资源。
优先级队列的核心思想:动态
时间复杂度对比:

原本队列的时间复杂度是O(n)级别,而优先级队列在这方法进行了优化,变成了O(logn)
注释: 在计算机领域,若见到logn时间复杂度,近乎一定和"树"结构相关(并非一定要构造一棵树结构,而是它的算法过程逻辑上一定是一棵树)
快速排序里面的:归并,快速递归过程也是一个"递归"树。时间复杂度:nlogn
基于二叉树的堆(二叉堆)
应用最广泛的堆: d插堆 、 索引堆
本章将的二叉树的特殊:
1.是一课完全二叉树,基于数组存储(元素都是靠左排列,数组中存储时不会浪费空间)
使用数组保存二叉树结构,方式即将二叉树用层序遍历方式放入数组中。
一般只适合表示完全二叉树,因为非完全二叉树会有空间的浪费。 这种方式的主要用法就是堆的表示。
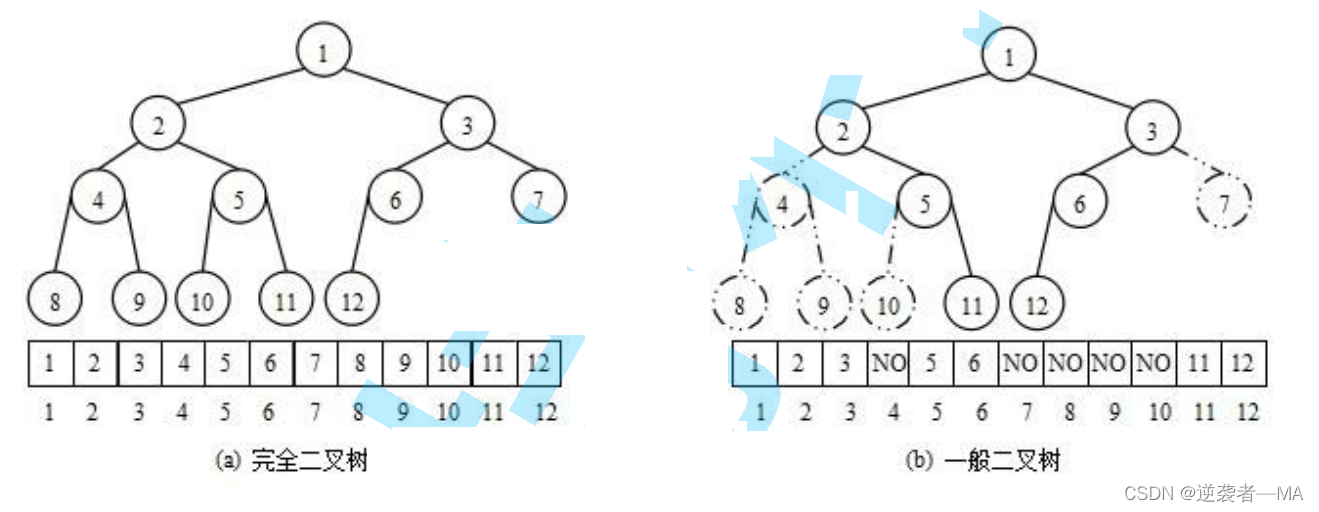
只有完全二叉树适合使用数组这种结构来存,储其他的二叉树都要用链式结构
2.关于节点值:
堆中根节点值 >= 子树节点中的值(最大堆,大根堆)
堆中根节点值 <= 子树中节点的值(最小堆,小根堆)
堆中树根 >= 或者 <= 子树中所有节点所有子树也仍然满足堆的定义
不管根要满足,子树中的根也要满足。
判断一个结构是否满足堆:
1. 必须要是一个完全二叉树
2. 根 >= 子树最大堆 或者 根 <= 子树最小堆(是所以节点)
比如:
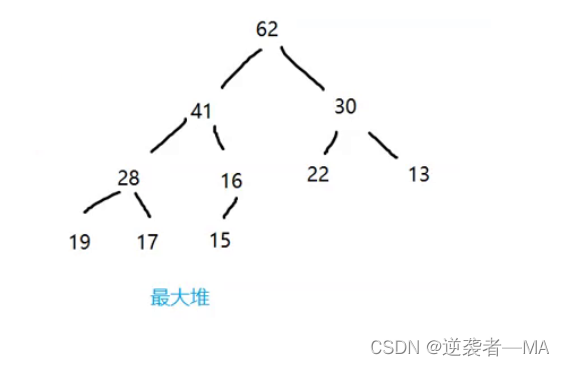
提问:最大堆中是否越"高"的结点—定就比越"低"值大?
答:不一定。节点的层次和节点的大小没有任何关系只能保证当前树中,树根是最大值。其他节点层次大小关系不确定
比如右子树的13虽然比最底层高,却小于左子树。
注释:JDK中的PriorityQueue默认是基于最小堆的实现。
3.因为堆是基于数组来存储的,节点的之间的关系通过数组下标来表示从0开始编号,因为数组下标也是从开始。
假设此时结点编号为i,且存在父子节点。
父节点编号 parent = (i - 1) / 2;
左子树的编号 left = 2 * i + 1;
右子树的编号 left = 2 * i + 2;
举例:给上图完全二叉树编号,下列任意节点编号都满足上面编号的三点关系
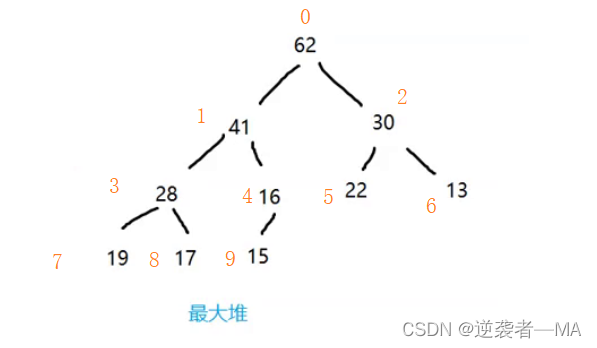
上面的所有节点都是按层序遍历的方式一个个存入数组中的。
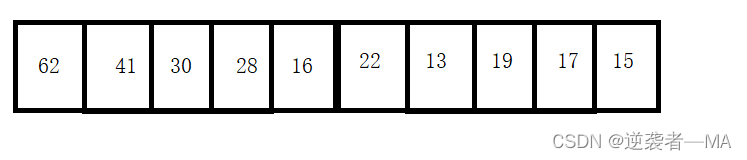
节点之间通过数组的索引下标来找到父子节点
基于动态数组ArrayList实现的最大堆
堆的基础表示:
注释:还没写添加功能。
/**
* 基于动态数组实现的最大堆
*/
public class MaxHeap {
// 实际储存元素的数组
private List<Integer> elementData;
// 当前堆中元素的个数
private int size;
//无参构造,默认创建数组大小为 10
public MaxHeap(){
this(10);
}
//有参构造--设置数组大小
public MaxHeap(int n) {
this.elementData = new ArrayList<>(size);
}
/**
* 传入数组的索引,找到节点k对应的父类的索引
*/
private int parent(int k){
//规则:(k - 1) / 2 ,右移相当于除以 2
return (k - 1) >> 1;
}
/**
* 找对节点 k对应的 左子树的索引
* (2 * k) + 1
*/
public int leftChild(int k){
return (k << 1) + 1;
}
/**
* 找对节点 k对应的 右子树的索引
* (2 * k) + 2
*/
public int rightChild(int k){
return (k << 1) + 2;
}
//返回当前数组的元素个数
public int getSize(){
return size;
}
//判断数组现在是否为 空
public boolean isEmpty(){
return size == 0;
}
}
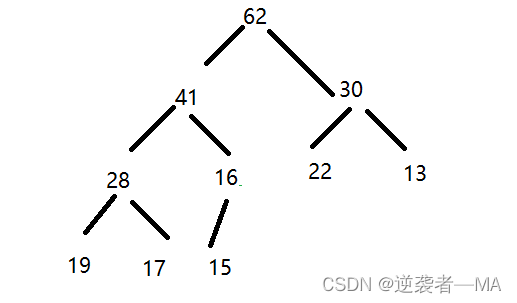
向堆中添加元素 siftUp
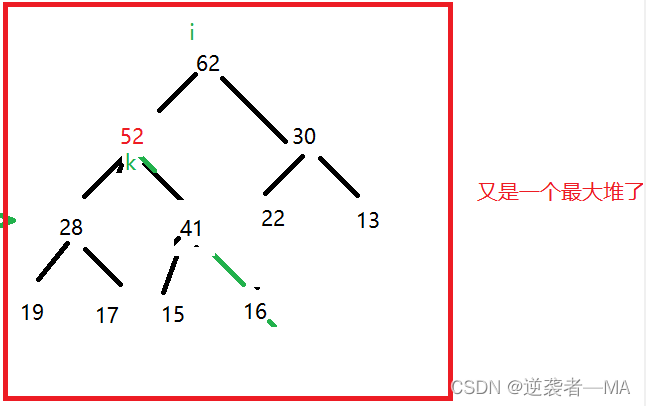
添加一个元素 52
堆是数组实现的,添加元素,数组咋添加元素?
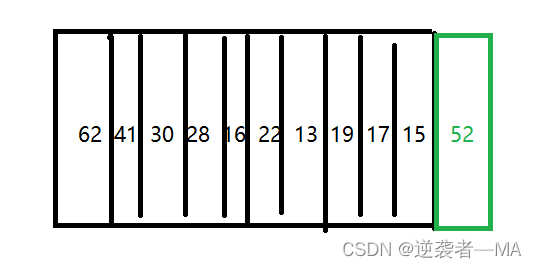
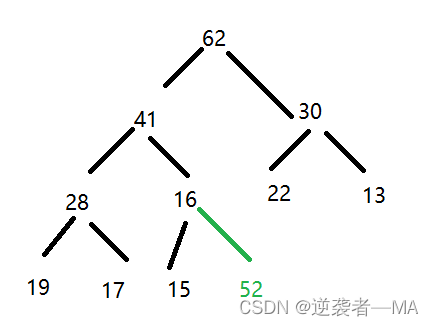
此时的这个堆仍然满足完全二叉树的性质
但是此时这个完全二叉树就不再是一个最大堆了因此需要进行元素的上浮操作,让新添加的元素上浮到合适位置。
不断将此时索引k和父节点的索引 i 对应的元素进行大小关系比较,若大于父节点效换彼此的节点值,直 到当前节点 <= 父节点为止 或者(or) 走到树根


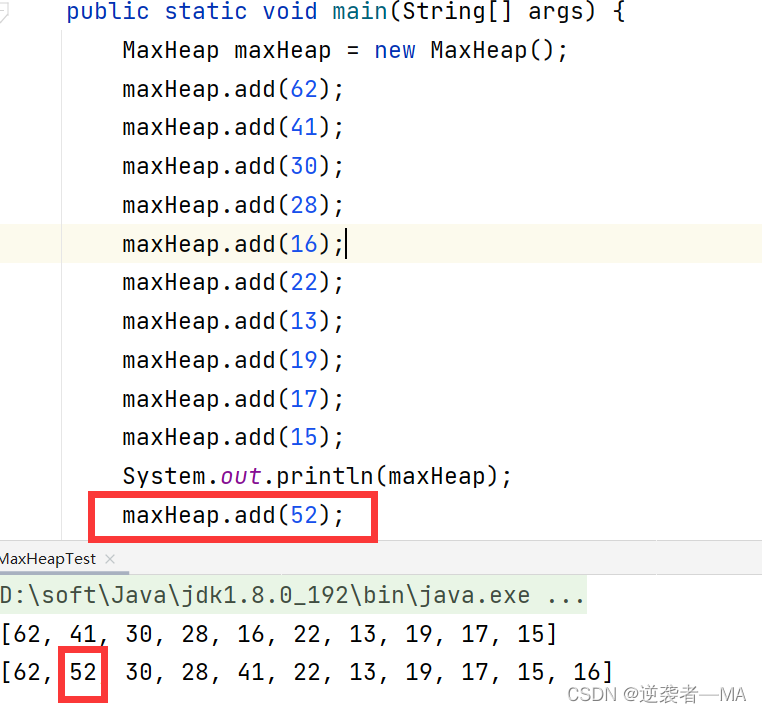
代码实现:
//添加元素
public void add(int val){
//1.直接向数组末尾添加元素
elementData.add(val);
size ++;
//2. 进行元素的上浮操作,设计一个方法
siftUp(size - 1);
}
//传入需要进行上浮操作元素的索引
private void siftUp(int k) {
//小于父类节点和已经是最大根节点就结
// 上浮元素节点值 跟它的 父类节点值比较
while(k > 0 && elementData.get(k) > elementData.get(parent(k)) ){
//进行节点值交换
swap(k, parent(k));
//进行交换后,k节点的父类节点就是新的上浮元素
k = parent(k);//更新上浮元索引
}
}
// 交换两个数字索引节点值
private void swap(int k, int parent) {
int child = elementData.get(k);//保存k节点的val
int pareentVal = elementData.get(parent);//k的父类节点值val
elementData.set(k,pareentVal);//k索引处更换为父类值
elementData.set(parent, child);//父类索引处更换为 k的val值
}
//toStrng方法实现
@Override
public String toString() {
return elementData.toString();
}
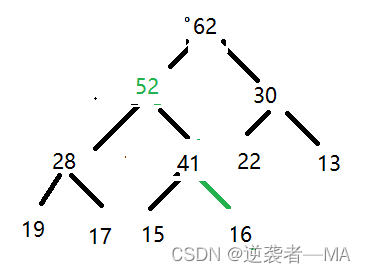
在堆中取出最大值(最大堆)
堆中的最大值是谁?肯定是树的根节点吧
1.最大堆的最大值一定处在数根节点。直接取出树根即可.
取出最大值后
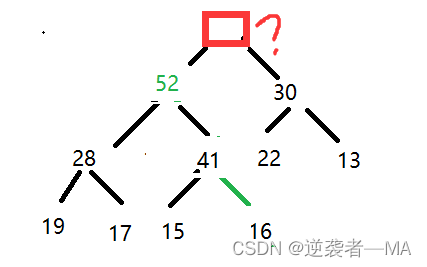
剩下来的左右子树怎么办?
⒉需要融合左右两个子树,使得取出树根后这棵树仍然是最大堆。
此时融合操作还是比较复杂的,因为左右子树大小关系不定,且节点的大小和层次没有必然联系。
怎么融合好呢?.
使用最低的成本来融合左右子树,使其仍然满足最大堆的性质。
比较和移动最少,删除元素 ——> 移除数组的末尾元素
融合方法:
1.直接取数根节点就是当前堆的最大值。
⒉将堆中最后一个元素顶到堆顶,然后进行元素的下沉操作。
siftDown===>使其仍然满足最大堆的性质
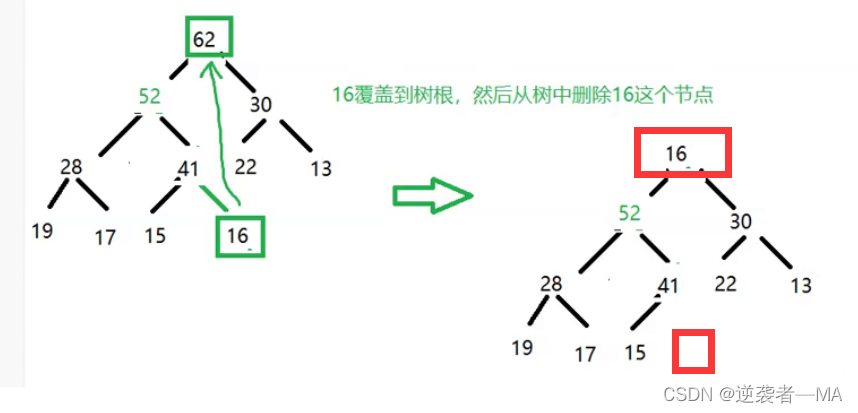
移除16之后这棵树仍然是完全二叉树,但此时不满足最大堆的性质。
解决办法:不断和左右子树的最大值进行交换直到16这个节点落在了最终位置。
完成下层操作:

代码实现:
/**
* 取中当前最大堆的最大值
*/
public int extractMax(){
//如果此时的数组为空,那么就报一个异常警告
if(isEmpty()){
throw new NoSuchElementException("heap is empty!cannot extract!");
}
//不为空,说明此时树根就是最大节点
int max = elementData.get(0);
//将数组末尾元素顶到堆顶
elementData.set(0, elementData.get(size - 1));
// 将数组的最后一位元素从堆中删除
elementData.remove(size - 1);
size --;
//进行元素的下层操作,从索引为 0 的根开始
siftDown(0);
return max;
}
/**
* 从索引k开始进行元素的下沉操作
*/
private void siftDown(int k) {
//因为这堆满足完全二叉树特性,不存在有右子树,没有左子树
//循环条件表示:当前还存在有子树,可以循环判断是否能下层
while(leftChild(k) < size){
//获取左子树的索引
int j = leftChild(k);//用来进行下层交换的索引值
// 表示此时也存在右子树 左子树和右子树索引差 1
if(j + 1 < size) {
//判断此时的右子树是否大于左子树的值
if (elementData.get(j + 1) > elementData.get(j)) {
//表示右子树大于左子树,更新 j 索引值,变成右子树的索引
j++;
}
}
//此时的索引 j 一定对应了左右子树中的最大值索引
//判断索引 k元素是否需要进行下层操作
if (elementData.get(k) < elementData.get(j)) {
//说明需要进行下层
swap(k, j);
//更新此时需要下层元素的索引
k = j;
} else {
// 当前元素 >= 左右子树最大值,下沉结束,元素k落在了最终位置
break;
}
}//while
}
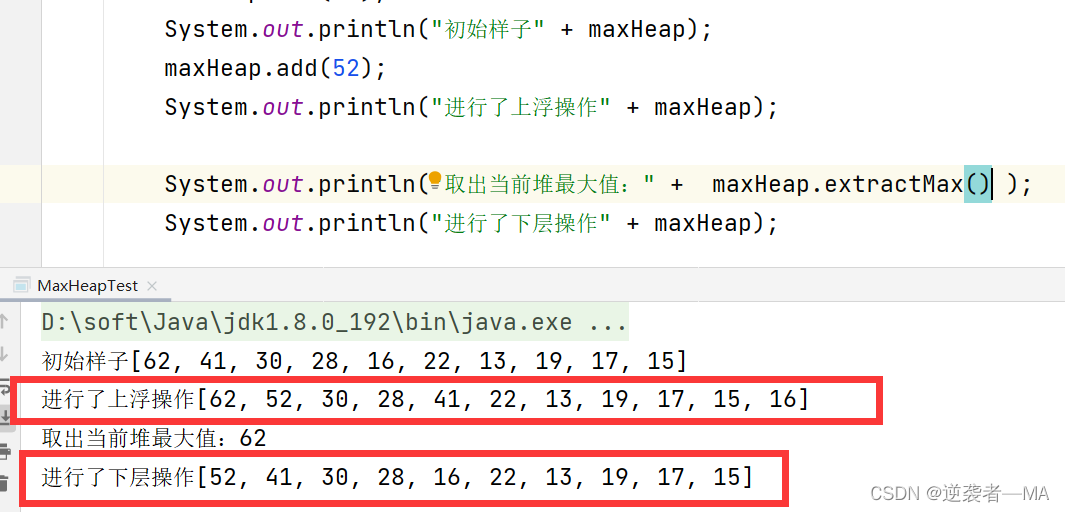
如果此时一直出去最大值并打印会怎么样?
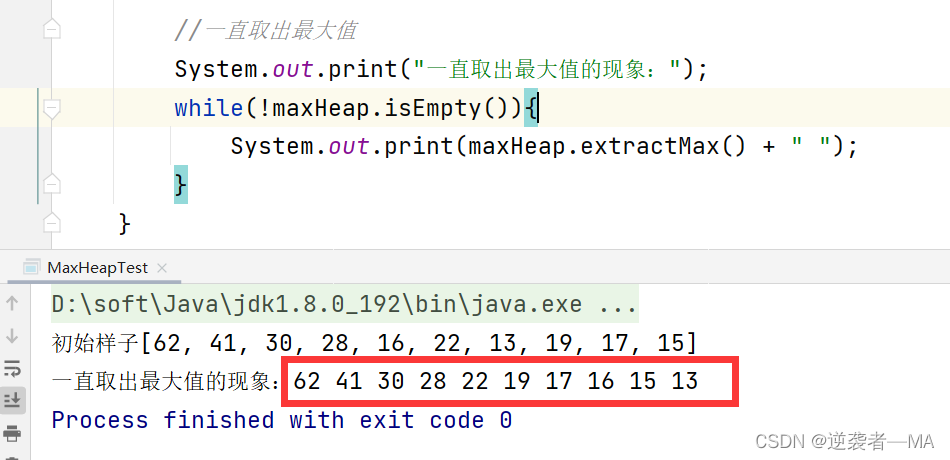
发现这就是个降序结果,如果想要升序,把结果逆序一下就好了
注释:堆排序就是建立最大堆,然后在最大堆的基础上进行调整操作就可以得到一个升序集合~~
3.heapify ——堆化
现在给你一个任意的整型数组 ===》都可以看做是一个完全二叉树,距离最大堆就差元素调整操作。
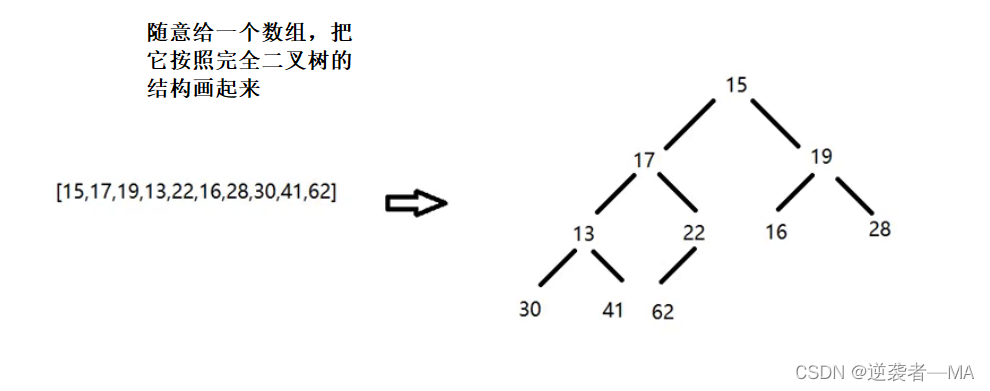
那么怎么进行元素调整,使这个二叉树变成最大堆呢?
方法1 最简单的方法:假设有一个最大堆,每次给这个最大堆添加一个新元素,然后进行下层,那么这个二叉树就任然保存 最大堆特性。
1.将这n个元素依次调用add方法添加到一个新的最大堆中
遍历原数组,创建一个新的最大堆,调用最大堆的add方法即可。
那么这个操作是时间复杂度是多少?
堆优化的时间复杂度,遍历一次是 O(logN) 级别
那么进行 n 次遍历就是 N O(logN) 级别 空间复杂度 O(N)
方法2: 原地heapify(堆化)
它的时间复杂度可以优化到 O(n)
思想:从最后一个非叶子结点开始进行元素siftDown操作
从当前二叉树中最后一个小子树开始调整,不断向前,直到调
整到根节点。
过程:
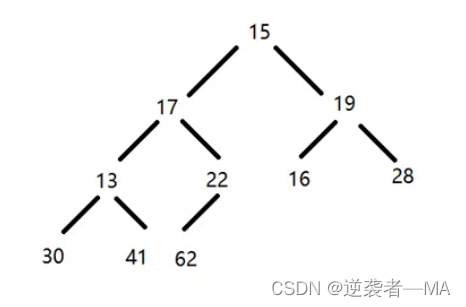
1. 最后一个 非叶子节点 就是 22 那么就从它开始调整
发现此时它的子树 62 比它自己大,那就进行换位子。

此时对于绿色框框圈起来的二叉树来说,它就已经是一个最大堆了
2. 此时继续往前走,再看上一个非叶子节点 13,如果13这个节点存在子树比他大的话,就跟最大值进行交换位置。
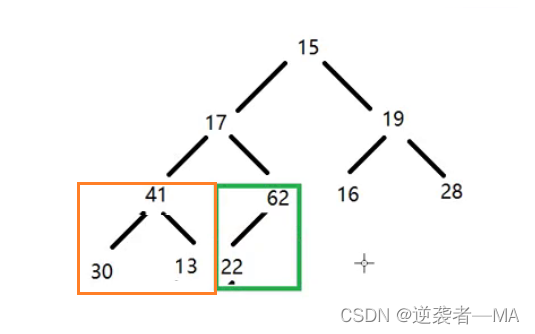
此时对于橙色框框圈起来的二叉树来说,他们就可以看做是一个最大堆了
3. 再重复操作向上走。
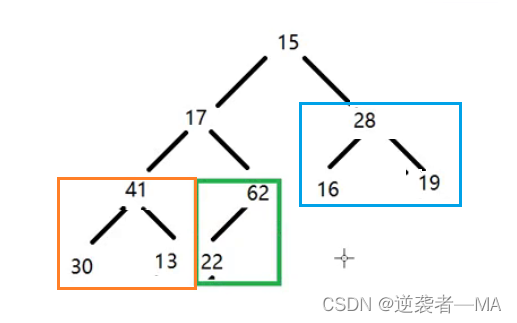
4. 关键点来了,此时17下面都是最大堆了,现在只需要对这个根 17 进行下层操作,这样就会形成最终的最大堆
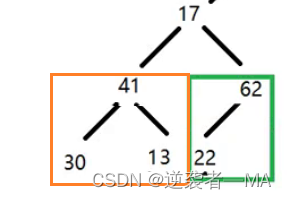
进行下层操作后,这个二叉树就是一个新的最大堆了。
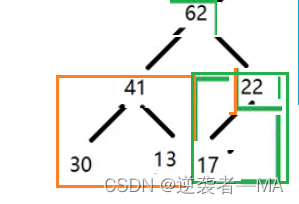
最后树根节点的左右子树都是最大堆了,其需要最后进行一次下层操作就可以了。
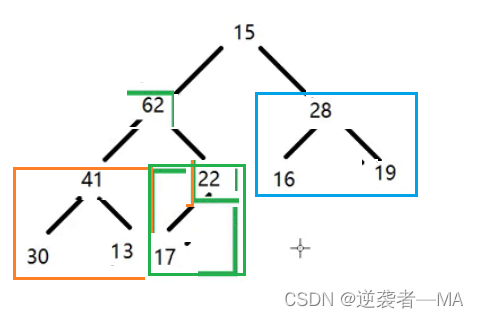
不断将子树调整为最大堆时,最终走到树根时,左右子树已经全都是最大堆
只需最后下沉根节点就能得到最终的最大堆。
代码实现:
/**
* 原地堆化,创建一个构造方法。
* 降任意的整形数组arr 调整了堆
*/
public MaxHeap(int[] arr){
this.elementData = new ArrayList<>(arr.length);//开辟等长的空间
//1. 先将所有元素复制到 Data数组中
for(int i : arr){
elementData.add(i);
size ++;
}
//2. 从最后一个非叶子节点不断进行siftDown操作
// 最后一个非叶子节点就是最后一个元素的父节点
for (int i = parent(size - 1); i >= 0 ; i--) {
//不断下层操作
siftDown(i);
}
}
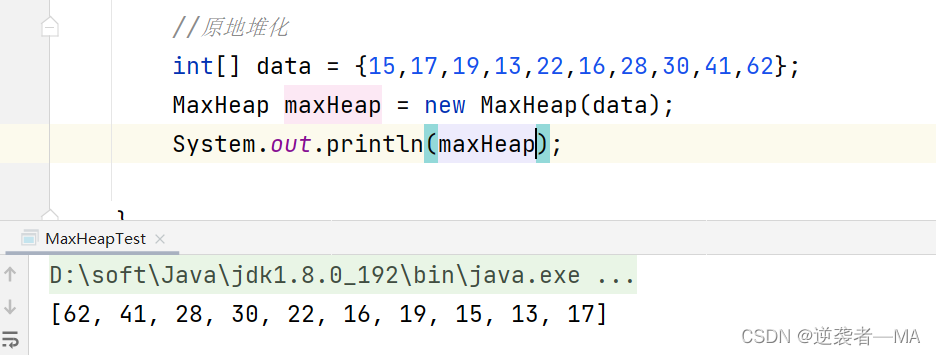
在Java中比较两个元素的大小关系:
在Java中比较两个元素相等equals
在比较两个自定义对象的大小关系,类覆写Comparable接口,实现compareTo方法
若一个类Student implements Comparable,这个类继承Comparable接口,则这个Student类具备可比较的能力。
compareTo方法 具有三大返回值:

实现java.util.comparator接口 ====》 比较器接口

自定义一个Student类,使它具备可比较的能力。
//Comparable接口
import java.util.Arrays;
public class Student implements Comparable<Student> {
private int age;
private String name;
//构造方法
public Student(int age, String name) {
this.age = age;
this.name = name;
}
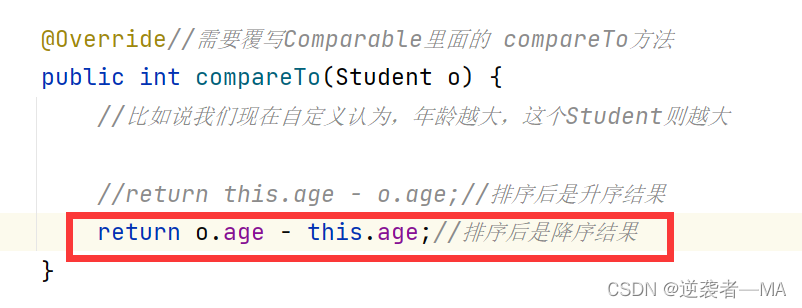
@Override//需要覆写Comparable里面的 compareTo方法
public int compareTo(Student o) {
//比如说我们现在自定义认为,年龄越大,这个Student则越大
return this.age - o.age;
}
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) {
Student[] students = new Student[]{
new Student(19,"小明"),
new Student(17,"小红"),
new Student(18,"小刚"),
};
//快速排序
Arrays.sort(students);
System.out.println(Arrays.toString(students));
}
}
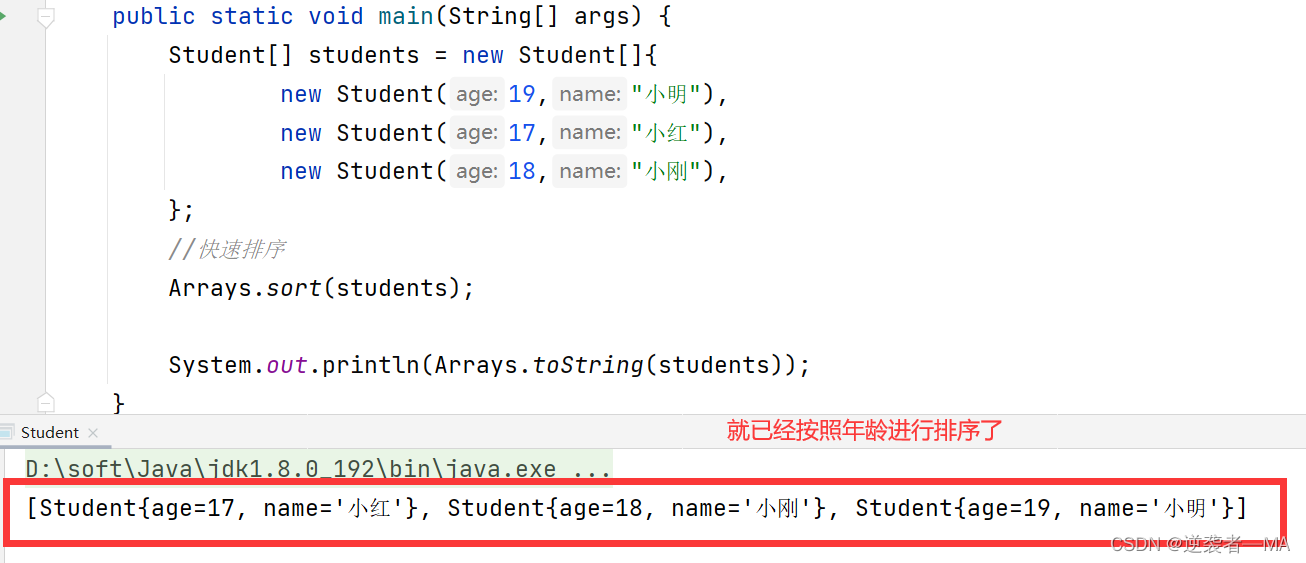
原本我们自定义的这个类是不具备比较能力的,系统怎么知道你怎么样算大。
原因:
1. 我们继续了Comparable接口,往里面穿了我们自定义的类Student

2. 覆写了compareTo方法,定义了一个大小的规则。认为年龄大就算大

提问:现在得到的结果是升序了过程,那怎么变成降序结果呢?
注释:快速排序: Arrays.sort(students); 这个是别人写好的东西,不能修改
很简单,把覆写方法结果反一下就好了。变成我们认为 年龄越大的,是 “小”
运行结果:就是降序


假设哪—天,我又想得到一个按照名字排序的数组,那么又得改compareTo方法。
这样会显得很麻烦,而且非常不好!程序世界中有个说法叫 开闭原则。
开闭原则 : 一段程序应该对扩展开放,对修改关闭。
注释:写好的代码别老改,要有新场景,就拓展新代码,不要影响老代码。
那么我们现在在原来的基础上做下修改。
这样Comparator接口就孕育而生了。

接口的语义:一个类若实现了这个接口,表示这个类天生就是为别的类的大小关系服务的~
修改过程:
1. 先把原来的覆写方法删除。

2. 现在也不需要继承原来的接口了,删除

那么现在这个student 这个类就不具备了比较的能力

3. 但是,我现在定义一个类,专门就是为了比较它Student这个类的大小。
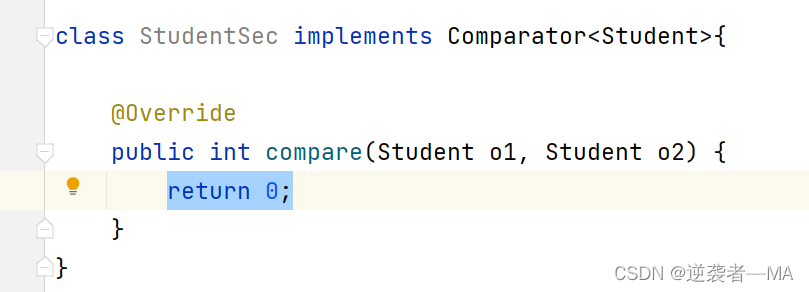
StudentSec这个类天生就是为了Student对象的排序而存在
这个定义的类里面会覆写compare方法(o1,o2) ====> 返回值 int 表示 o1 和 o2 的大小关系
4. 先在原来的Student里面写一个get方法,让外部可以拿到里面的数据

5. 现在就可以在StudentSec 里面覆写 compare 方法了
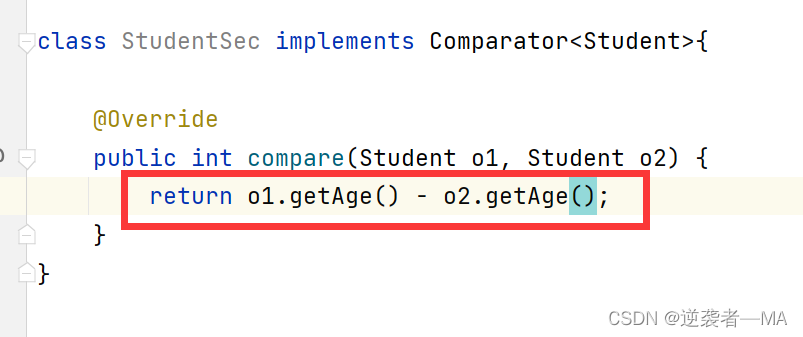
6. 使用比较强
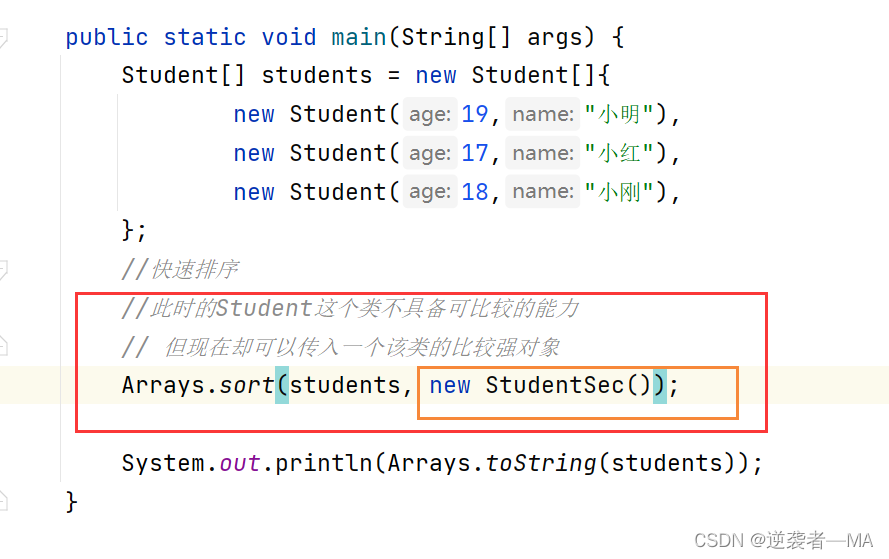 在快速排序里面传入一个该类的 比较器对象
在快速排序里面传入一个该类的 比较器对象
运行结果:使这个Student照样可以进行比较输出

注释:虽然我自己比不成,但有一个类就是给我进行比较的。
7. 刚才我们定义的这个类是根据年龄越大就越大进行比较
现在我再定义一个方法,此时又是根据年龄越小反而越大进行比较
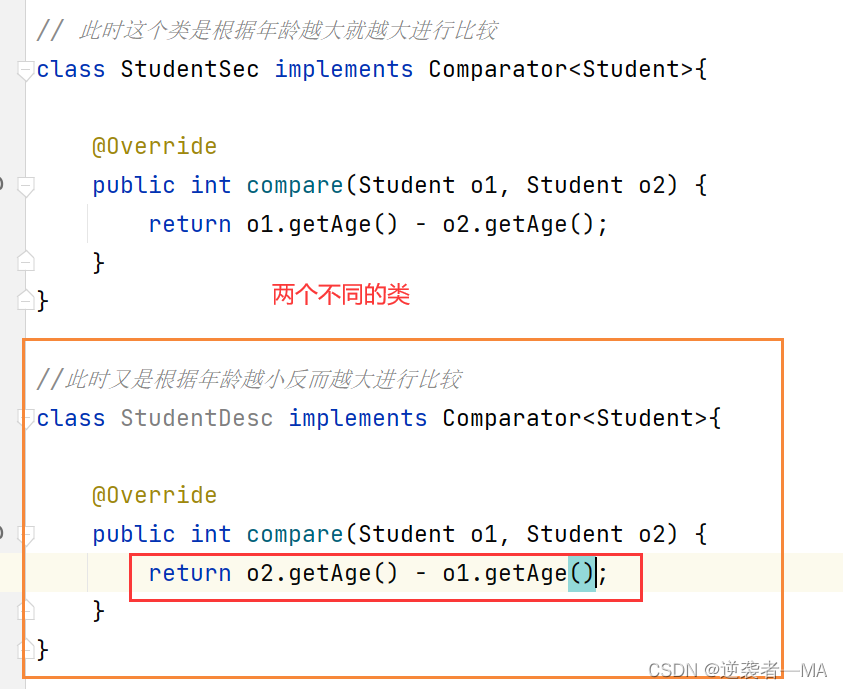
运行结果:

注释:定义这个类对原来的代码没有任何影响,也没有对老代码进行修改。
现在我就可以根据我自己的需求对里面传入不同的比较器对象,这就满足了我们之前说的
程序的开闭原则:对拓展开发,对修改关闭。
注释:这种设计思想就是java中的:策略设计模式
结论:
当把Student类的大小关系比较从Student类中"解耦"此时的比较策略非常灵活,
需要哪种方式,只需要创新─一个新的类实现Comparator接口即可根据此时大小关系的需要传入比较器对象。
这就是:策略模式
解耦:就是从原来的程序中脱离开来
sort方法内部定义:调用了 Comparator
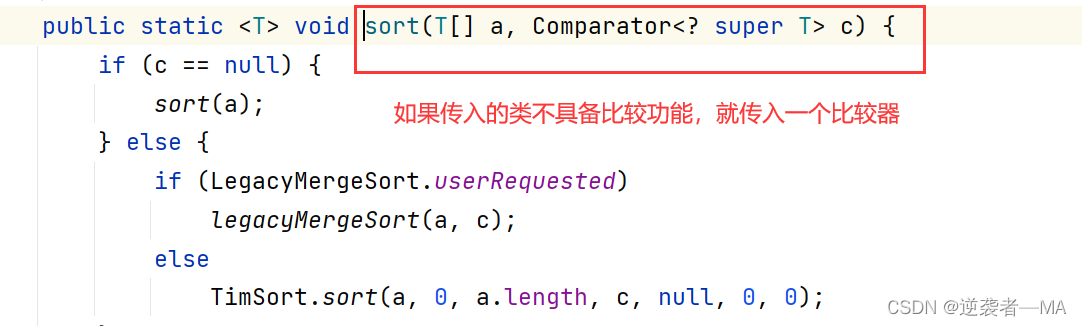
推荐大家以后写代码用 比较器这种方法
基于堆的优先级队列到底如何实现,有啥应用
这就是经典的:TopK问题
优先级队列的实现:其实优先级队列的方法就是应用我们之前写的最大堆的方法,对它进行包装了一层而已。
import seqlist.queue.Queue;
/**
* 基于最大堆的 优先级队列
*/
//其实所谓的优先级队列就是调用最大堆中的方法,包装了一层而已
public class PriorityQueue implements Queue<Integer> {
private MaxHeap heap;
//构造方法
public PriorityQueue() {
this.heap = new MaxHeap();
}
@Override
public void offer(Integer val) {
heap.add(val);
}
@Override
public Integer poll() {
return heap.extractMax();//取中当前最大堆的最大值
}
@Override
public Integer peek() {
return heap.peekMax();//查看当前数组的最大元素
}
@Override
public boolean isEmpty() {
return heap.isEmpty();
}
}
重点:优先级队列的应用问题
以力扣的题目为场景:
这个题,很经典,非常爱考。
面试题 17.14. 最小K个数 - 力扣(LeetCode)
TopK问题:
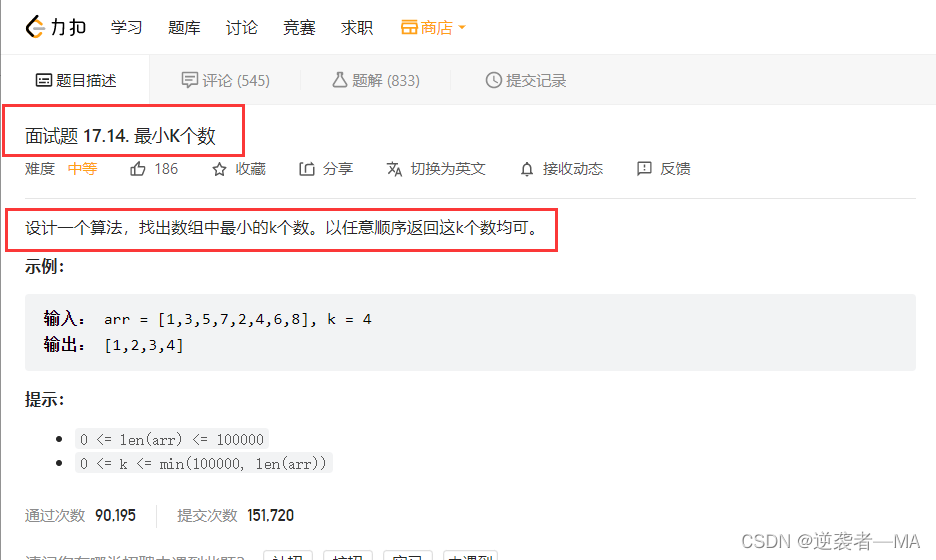
返回一组数里面最小的前几个数,比如一百万个数里面返回前100个最小的数
我们之前碰到这问题怎么做?是直接排序吧!然后输出数组前k元素。
最快的排序算法时间复杂度也要: O(nlogn)
/**
* 最简单的办法就是用快速排序,然后保存前k个
*/
class Solution {
public int[] smallestK(int[] arr, int k) {
Arrays.sort(arr); //快速排序
int[] data = new int[k];
for (int i = 0; i < k; i++) {
data[i] = arr[i];
}
return data;
}
}

如果此时题目要求时间复杂度优于 O(nlogn) ,那么这个算法就不行了。
这种情况就可以去使用优先级队列
知识要点:

比如此时是取出前四个最小元素 ——》构造一个大小为 四 的最大堆
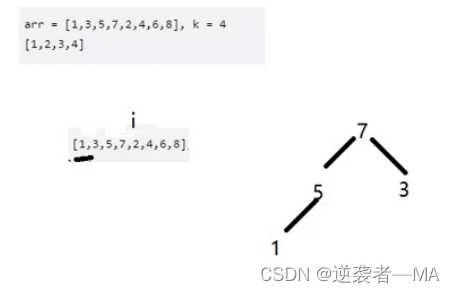
这个最大堆值保存4个元素。
规则:

用的方法就是我们之前写的优先级队列,它是基于动态数组实现的最大堆上包装完成的。
随着堆顶元素不断交换,会把堆顶元素不断变小,最终队列扫描结束就存放了最小的k个数。
这题用优先级队列的时间复杂度为: O(nlog k),k是题目要取的数量。当k远小于n时,
O(nlog k) 跟 O(nlog n) 的差距就越明显
注释:当k 远小于 n时,log k 就很小,那么时间复杂度可以近乎于 O(n)级别,但如果问你是什么复杂度的话还是 O(nlog k)的复杂度,因为 k 是个变量,不能省略。
思路二:用优先级队列解决
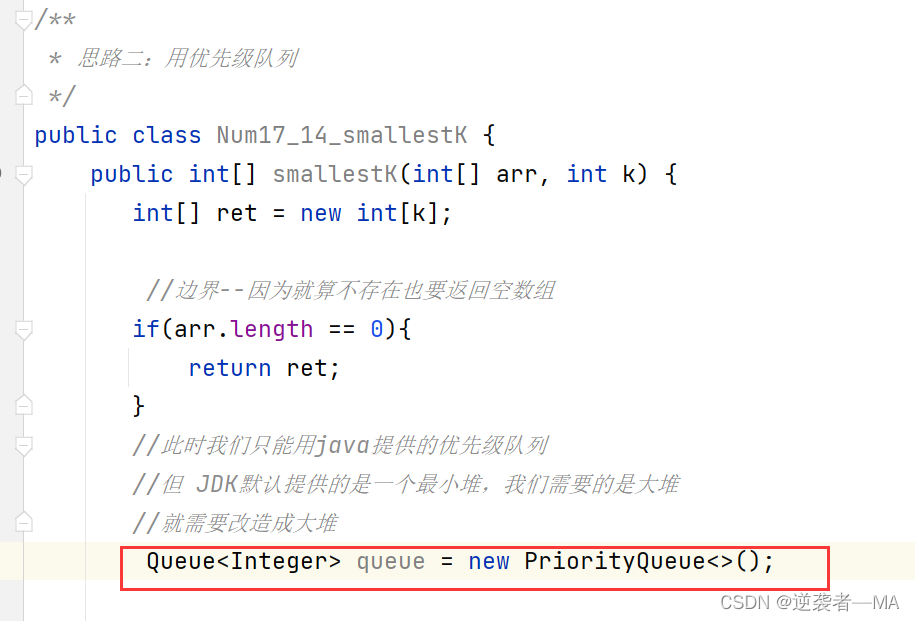
注释:此时我们只能用java提供的优先级队列
但 JDK默认提供的是一个最小堆,我们需要的是大堆 就需要改造成大堆
怎么改造?用之前学的传入 比较器对象 或者传入 匿名内部类
1. 先说匿名内部类怎么弄:
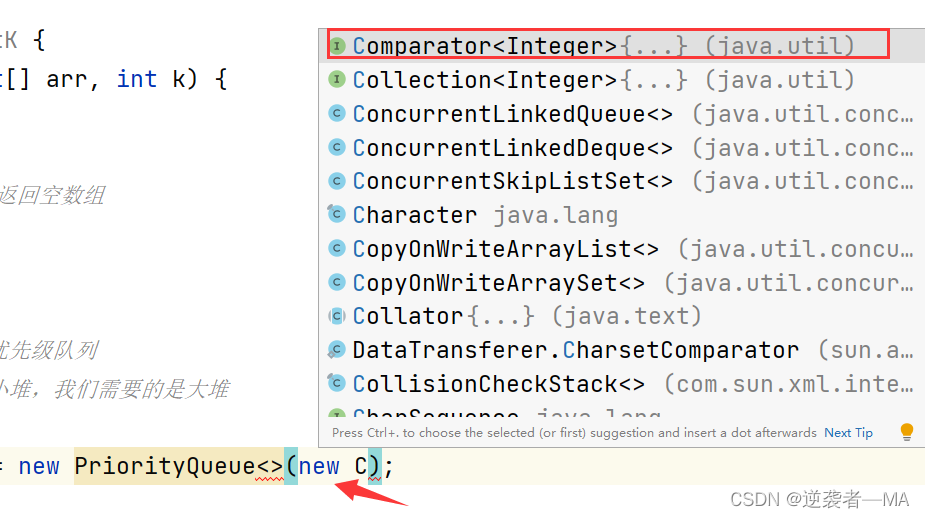 相当于传入了一个 匿名内部类
相当于传入了一个 匿名内部类
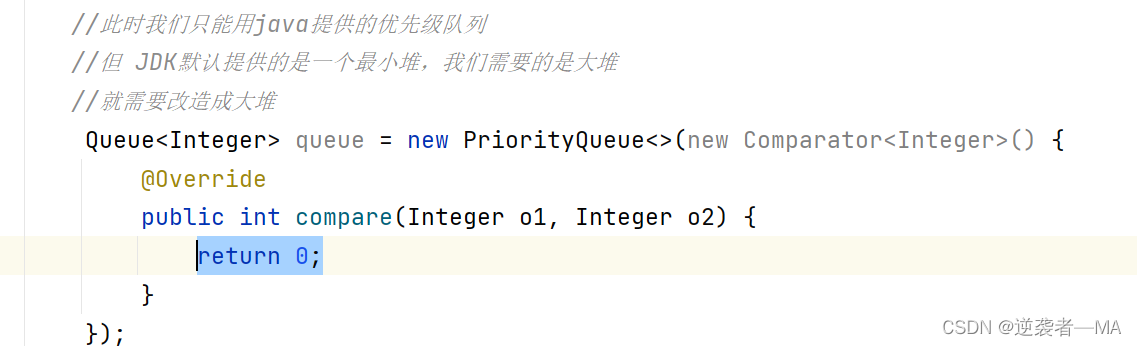 然后开始在覆写方法里面设定。反过来就行
然后开始在覆写方法里面设定。反过来就行
现在改造好了
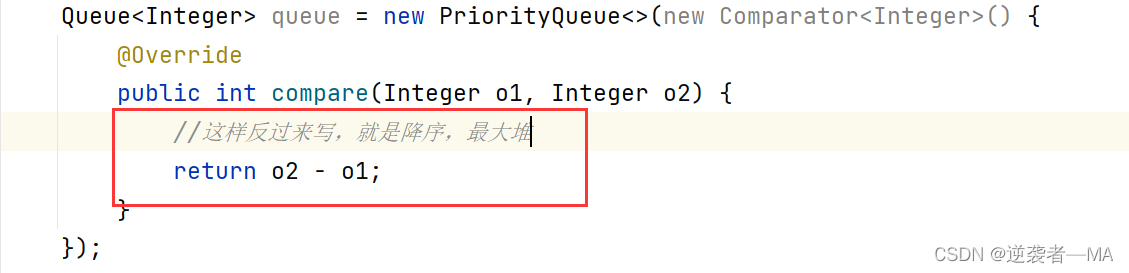
2. 创建比较器类,传入对接比较器对象
在方法的外部创建

在题目方法里面使用:

/**
* 思路二:用优先级队列
*/
//创建一个类 比较器
class Integerreverse implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
//这样反过来写,就是降序,最大堆
return o2 - o1;
}
}
class Solution {
public int[] smallestK(int[] arr, int k) {
int[] ret = new int[k];
//边界--因为就算不存在也要返回空数组
if(arr.length == 0 || k == 0 ){
return ret;
}
//此时我们只能用java提供的优先级队列
//但 JDK默认提供的是一个最小堆,我们需要的是大堆
//就需要改造成大堆
//这是匿名内里类的创建方法
// Queue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() {
// @Override
// public int compare(Integer o1, Integer o2) {
// //这样反过来写,就是降序,最大堆
// return o2 - o1;
// }
// });
Queue<Integer> queue = new PriorityQueue<>(new Integerreverse());
//遍历原数组集合,队列中保存k个元素
for(int i : arr){
//判断队列是有 k 个元素
if(queue.size() < k){
//说明此时队列没有k个元素,就添加
queue.offer(i);
}else{
//说明此时队列不需要继续增加元素了
int max = queue.peek();//查看树顶元素
if(max > i){
queue.poll();//弹出树顶元素
queue.offer(i);//添加max,同时进行下层操作
}
}
}
//此时队列里面就保存了最小的k个元素,依次出队就行
int t = 0;
while(!queue.isEmpty()){
ret[t ++] = queue.poll();
}
return ret;
}
}
内部类
所谓的内部类,就是一个类嵌套到另一个类的内部的操作。
有四种内部类
匿名内部类:
 这个等价于,我们上一题在方法外部写的 比价器,不过我们现在new的这个类是没有名字的,
这个等价于,我们上一题在方法外部写的 比价器,不过我们现在new的这个类是没有名字的,
而且我们直接在方法里面写了,很方便

优化上面题目的代码:
/**
* 思路三:优化,使用匿名内部类
*/
class Solution {
public int[] smallestK(int[] arr, int k) {
int[] ret = new int[k];
//边界--因为就算不存在也要返回空数组
if(arr.length == 0 || k == 0){
return ret;
}
//这是匿名内里类的创建方法 跟上面写的 比较器是等价的,不过这个是没有类名的
Queue<Integer> queue = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
//这样反过来写,就是降序,最大堆
return o2 - o1;
}
});
//遍历原数组集合,队列中保存k个元素
for(int i : arr){
//判断队列是有 k 个元素
if(queue.size() < k){
//说明此时队列没有k个元素,就添加
queue.offer(i);
}else{
//说明此时队列不需要继续增加元素了
int max = queue.peek();//查看树顶元素
if(max > i){
queue.poll();//弹出树顶元素
queue.offer(i);//添加max,同时进行下层操作
}
}
}
//此时队列里面就保存了最小的k个元素,依次出队就行
int t = 0;
while(!queue.isEmpty()){
ret[t ++] = queue.poll();
}
return ret;
}
}
小知识:函数式编程
力扣堆的练习题
做题小知识:
在LeetCode和牛客网中,若碰到某些问题,现有的类型无法解决,自定义一个类。借助自定义对象辅助解决问题
347. 前 K 个高频元素 - 力扣(LeetCode)
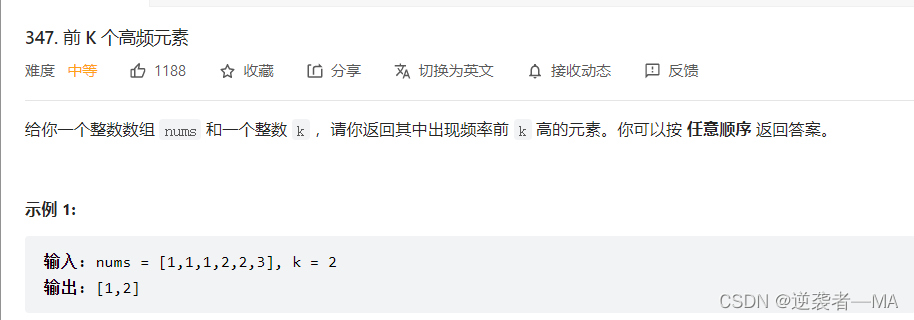
求前k个出现次数最多的。
1. 求大用小,所以现在用最小堆实现,JDK默认的就是最小堆。
2. 难点在于:如何让编译器知道,出现次数多的为 " 大 " 呢?
之前我们是值比较 》《 一下就判断出来了,现在要让编译器知道出现次数多的才算 大
Map接口——存储一个键值对数据
映射结构
key = Value
这题里面 key :不重复的元素
Value :数组元素出现的次数
那么现在优先级队列要保存元素,保存 key? 保存 Value ? 都不合适。
需要保存键值对:出现的 元素以及其 频次
所以现在定义一个类,保存类的对象即可。

实现步骤:
1.
创建Map集合的方法:里面键值对保存的类型的 int
HashMap :哈希Map

2.扫描原数组,保存map

3.扫描 Map集合,将出现频次最高的前k个元素添加到优先级队列中
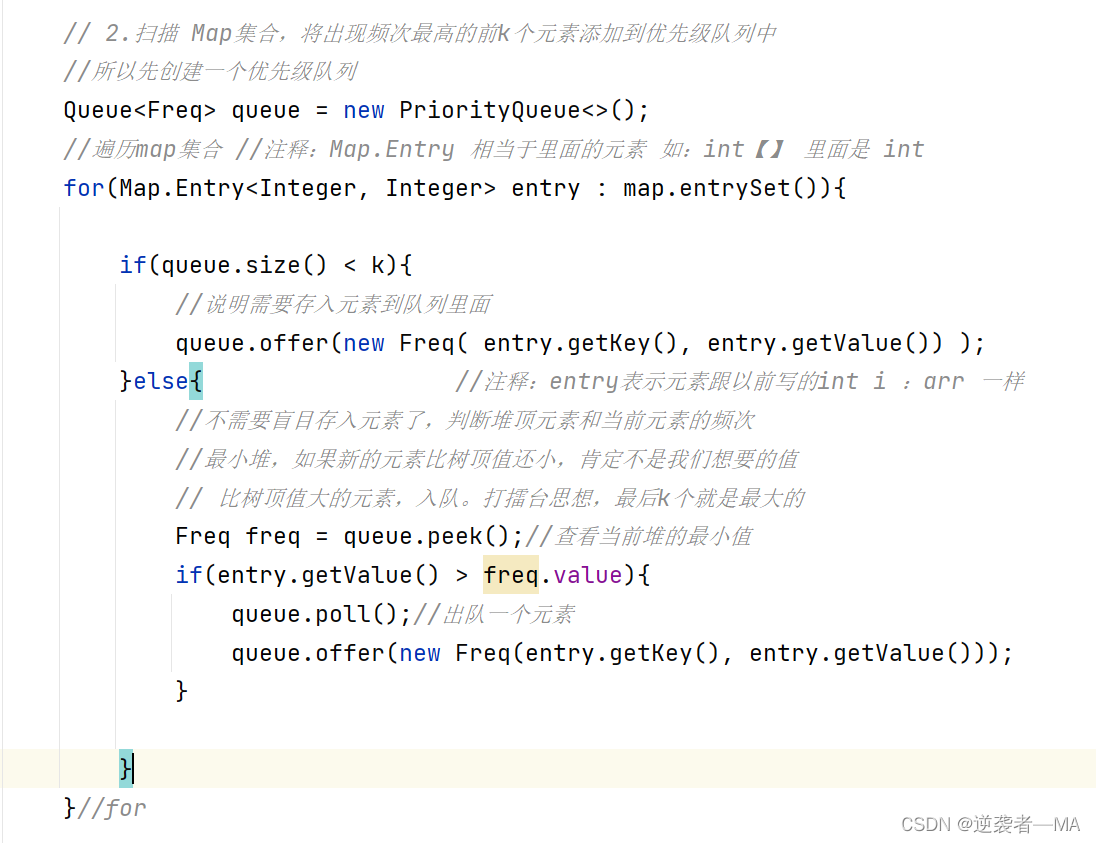
4. 把列表元素放进数组里面
这样就完成了
关于Map的部分相关知识


原地堆排序
给你一个任意的数组,如何就在这个数组的基础上进行堆排序,不创建任何额外空间。
比如:
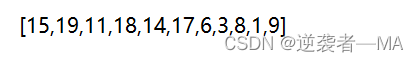
1. 先把这个数组画成二叉树,层序遍历的方法,上到下,左到右。
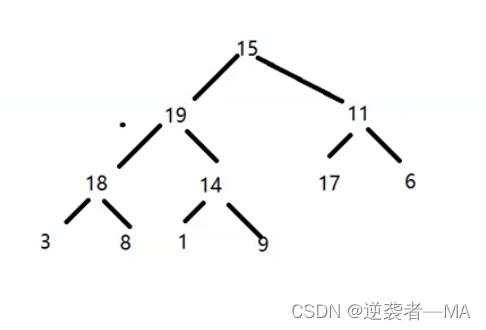
2. 然后进行heapify过程,堆化。变成一个最大堆。就是上面讲的,从最后一个非叶子节点开始进行 siftDown 操作。最后元素的父类就是最后一个非叶子节点,上面都讲了,就是先把这个任意二叉树变成一个最大堆。
这就是跟根据上面给的数组排成的最大堆
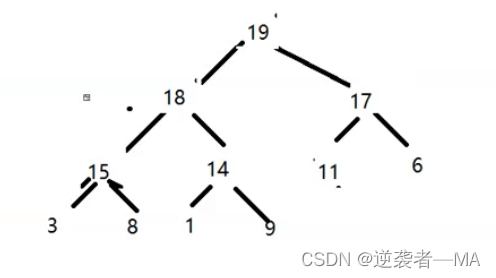
3. .不断交换堆顶元素和最后一个元素的位置,
最大堆什么特性?树根值最大,那么想将这个二叉树排序,把最大值跟最大堆的末尾元素交换位置,这样就把数组内的最大值放在了最终的位置上。然后将堆顶元素再进行siftDown 操作,让堆保持还是最大堆
然后开始倒数第二个元素跟树顶元交换位置。。。。重复此操作,每次确定一个最大值位置。
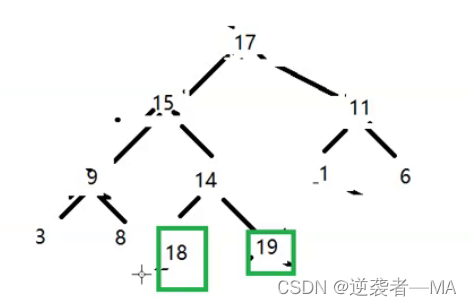
此时就确定了两个最大值的位置。
终止条件:直到数组剩下—个未排序的元素为止。
按照上面的思路,代码实现:原地排序实现
package sort;
import java.util.Arrays;
/**
* 七大排序
*/
//注释:arr. length - 1是最后一个元素的索引
//而 (arr.length - 1 - 1) / 2 是找最后一个元素的父类索引
public class SevenSort {
public static void main(String[] args) {
int[] arr = {19,27,13,22,3,1,6,5,4,2,110,65,70,98,72};
//调用刚刚写的原地排序方法
heapSort(arr);
System.out.println(Arrays.toString(arr));
}
//原地排序
public static void heapSort(int[] arr){
//1.先将任意数组进行heapify调整为最大堆
for(int i = (arr.length - 1 - 1) / 2 ; i >= 0; i--){
//不断进行着 siftDown 操作
siftDown(arr, i, arr.length);
}
//2 不断交换堆顶元素到数组末尾,每交换一个元素,就有一个元落在了最终位置
for (int i = arr.length - 1; i > 0 ; i--) {
// arr[i] 就是未排序数组的最大值,交换末尾
swap(arr,0, i);
siftDown(arr,0, i);//这里数组长度必须传 i 因为每成功一次相当于
//末尾位置确定了,就不需要被下层操作的影响。逻辑上相当于数组没有了这个元素位置。
}
}
/**
* 交换两个元素的位置
*/
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
*
* @param arr
* @param i //当前哪个位置的元素需要跟树顶换位置,进行下层操作
* @param length //左子树大于总长度就不用下层了
*/
private static void siftDown(int[] arr, int i, int length) {
//终止条件,不存在左子树索引就结束
while(2 * i + 1 < length){
int j = 2 * i + 1;
if(j + 1 < length && arr[j + 1] > arr[j] ){
j = j + 1;
}
//此时 j索引就是左右子树中最大值的索引
if(arr[i] > arr[j]){
break;
}else{
swap(arr, i,j);
i = j;
}
}
}
}

注释:这个执行速度是非常快的,是一个稳定了O(nlongn) 级别