参考文档:https://ruhyadi.github.io/project/computer-vision/yolo3d/
代码:https://github.com/ruhyadi/yolo3d-lightning
本次分享将会从以下四个方面展开:
物体检测模型中的算法选择
单目摄像头下的物体检测神经网络
训练预测参数的设计
模型训练与距离测算
1.物体检测模型中的算法选择
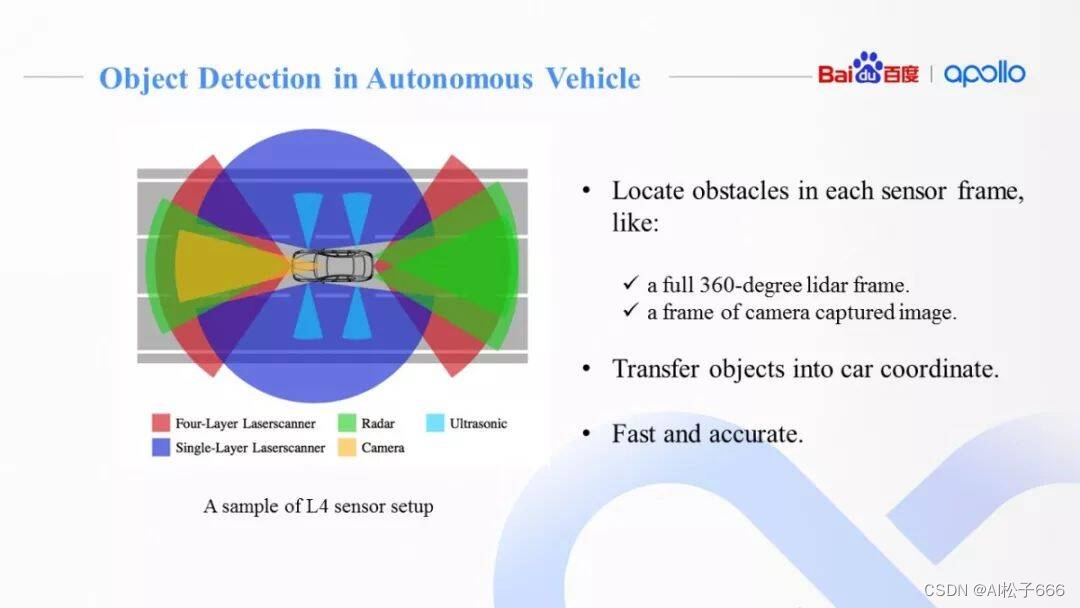
物体检测(Object Detection)是无人车感知的核心问题,要求我们对不同的传感器(如图中覆盖不同观测范围FOV的无人车传感器)设计不同的算法,去准确检测出障碍物。例如在Apollo中,为3D点云而设计的的CNN-SEG深度学习算法,为2D图像而设计的YOLO-3D深度学习算法等。
物体检测要求实时准确的完成单帧的障碍物检测,并借助传感器内外参标定转换矩阵,将检测结果映射到统一的车身坐标系或世界坐标系中。准确率、召回率、算法时耗是物体检测的重要指标。本次分享只覆盖Apollo中基于单目摄像头的物体检测模块。
2.单目摄像头下的物体检测网络

Apollo 2.5和3.0中,我们基于YOLO V2设计了单目摄像头下的物体检测神经网络, 我们简称它 Multi task YOLO-3D, 因为它最终输出单目摄像头3D障碍物检测和2D图像分割所需的全部信息。
它和原始的YOLO V2有以下几种不同:
1.实现多任务输出:
物体体检测: 包括2D框(以像素为单位),3D真实物体尺寸(以米为单位),障碍物类别和障碍物相对偏转角(Alpha Angle,和KITTI数据集定义一致)。下文会详细讲解各个输出的意义。
物体分割:车道线信息,并提供给定位模块,这里不做叙述。
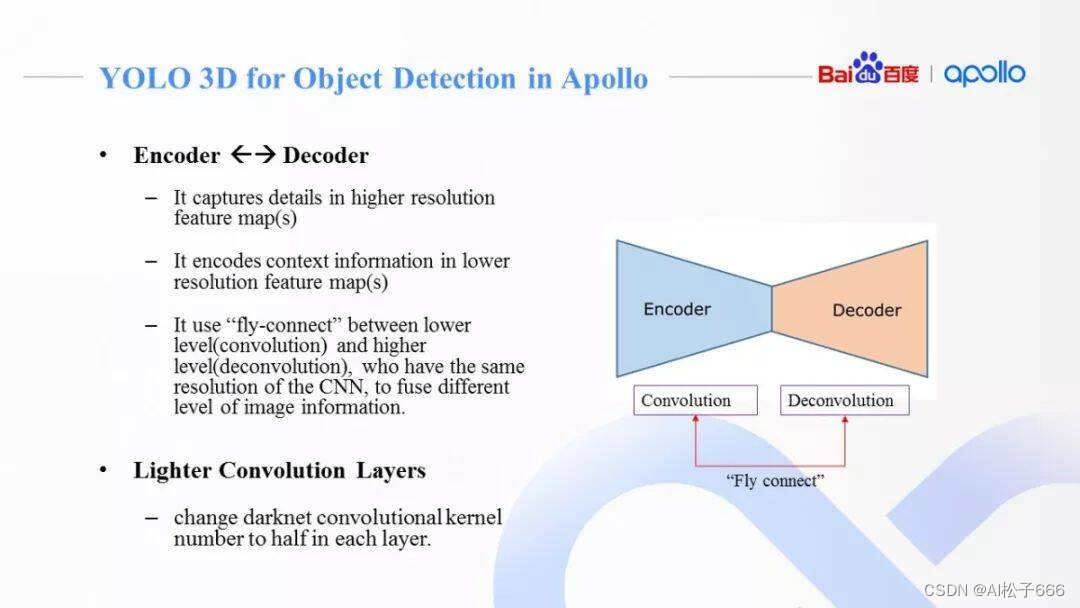
2.特征描述模块引入了类似FPN的Encoder和Decoder设计:
在原始Darknet基础上中,加入了更深的卷积层(Feature Map Size更小)同时添加反卷积层,捕捉更丰富图像上下文信息(Context Information)。高分辨率多通道特征图,捕捉图像细节(例如Edge,Corner),深层低分辨率多通道特征图,编码更多图像上下文信息。和FPN类似的飞线连接,更好的融合了图像的细节和整体信息。
3.降低每层卷积核数目,加快运算速度。例如我们发现卷积核数目减半,实验中准确率基本不变

如前文所述,物体检测最终输出包括2D框(以像素为单位),3D真实物体尺寸(以米为单位),障碍物类别和障碍物相对偏转角(Alpha Angle,和KITTI数据集定义一致)等信息。
和YOLO V2算法一样, 我们在标注样本集中通过聚类,产生一定数目的“锚”模板,去描述不同类别、不同朝向、不同大小的障碍物。例如对小轿车和大货车,我们会定义不同的锚模板,去描述它们的实际物理尺寸。

为什么我们要去训练、预测这些参数呢?我们以相机成像的原理来解释:针孔相机(Pinhole Camera)通过投影变换,可以将三维Camera坐标转换为二维的图像坐标。这个变换矩阵解释相机的内在属性,称为相机内参(Camera Intrinsic) K。
对任意一个相机坐标系下的障碍物的3D框,我们可以用它的中心点 T = {X, Y, Z},长宽高 D = {L, W, H},以及各个坐标轴方向上的旋转角 R = {ϕ, φ , θ}来描述。这种9维的参数描述和3D框8点的描述是等价的,而且不需要冗余的8*3个坐标参数来表示。
因此,对一个相机坐标系下3D障碍物,我们通过相机内参,可以投射到2D图像上,得到2D框[c_x, c_y, h, w]。从图中可以看到,一个障碍物在相机下总共有9维3D描述和4维2D描述,他们之间通过相机内参矩阵联系起来。
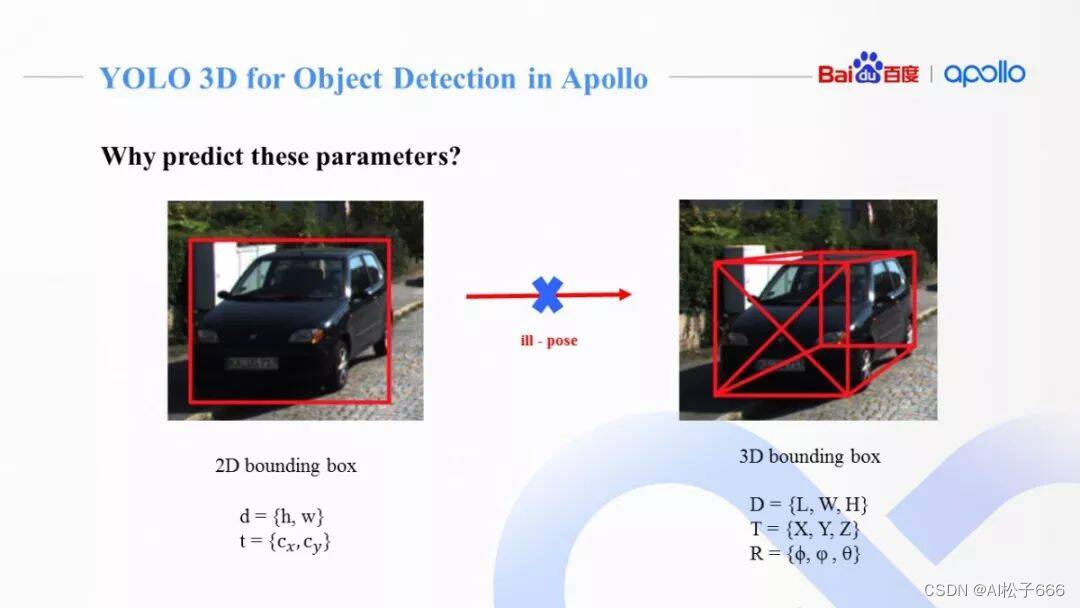
然而,只通过2D框[c_x, c_y, h, w],是没有办法还原成完整的3D障碍物信息。
3.训练预测参数的设计
而通过神经网络直接预测3D障碍物的9维参数,也会比较困难,尤其是预测障碍物3D中心点坐标。所以我们要根据几何学来设计我们到底要训练预测哪些参数。

首先利用地面平行假设,我们可以降低所需要预测的3D参数。
例如:(1)我们假设3D障碍物只沿着垂直地面的坐标轴有旋转,而另外两个方向并未出现旋转,也就是只有yaw偏移角,剩下的Pitch Roll均为0。(2)障碍物中心高度和相机高度相当,所以可以简化认为障碍物的Z=0。
从右图可以看到,我们现在只有6维3D信息需要预测,但还是没有办法避免预测中心点坐标X和Y分量。

第二,我们可以利用成熟的2D障碍物检测算法,准确预测出图像上2D障碍物框(以像素为单位)。
第三,对3D障碍物里的6维描述,我们可以选择训练神经网络来预测方差较小的参数,例如障碍物的真实物理大小,因为一般同一类别的障碍物的物理大小不会出现量级上的偏差(车辆的高度一般在2-5米之间,很少会出现大幅变化)。而yaw 转角也比较容易预测,跟障碍物在图像中的位置关系不大,适合通用物体检测框架来训练和预测。实验中也多次证明此项。
所以现在我们唯一没有训练和预测的参数就是障碍物中心点相对相机坐标系的偏移量X分量和Y分量。需要注意的是障碍物离相机的物理距离Distance=sqrt(X^2 + Y^2)。所以得到X和Y,我们自然就可以得到障碍物离相机的真实距离,这是单目测距的最终要求之一。
综上,我们可以合理的推断出, 实现单目摄像头的3D障碍物检测需要两部分:
训练网络,并预测出大部分参数:
(1)图像上2D障碍物框预测,因为有对应的大量成熟算法文献;
(2)障碍物物理尺寸,因为同类别内方差较小;
(3)不被障碍物在图像上位置所影响,并且通过图像特征(Appearance Feature)可以很好解释的障碍物yaw偏转角。
通过图像几何学,来计算出障碍物中心点相对相机坐标系的偏移量X分量和Y分量。
4.距离测算

当我们训练好相应的神经网络,输出我们需要的各个参数之后,我们需要考虑的是如何计算出障碍物离摄像头的距离。根据之前介绍,通过内参和几何学关系,我们可以链接起图像中3D障碍物大小(单位为像素)和真实3D坐标系下障碍物大小(单位为米)。
Apollo这个课件里面介绍的是建立了一个哈希表,通过障碍物大小、朝向来查询距离,但是我在Apollo源码里面没有看到相关代码,代码里面是通过上图公式来计算出Z这个维度,然后根据相机内参,将障碍物2DBox中心点,投影到相机坐标系中,得到相机坐标系下的X,Y坐标,进而得到障碍物的距离D,在进入具体实践之前,还要对图4网络预测的Yaw角度alpha进行一个细致分析。
5.网络预测参数Yaw
Apollo网络训练严格遵循了kitti数据集格式,可以在kitti数据集.md文档中查阅数据格式,这里具体对其角度alpha进行解析
从上面分析可知,
对任意一个相机坐标系下的障碍物的3D框,我们可以用它的中心点 T = {X, Y, Z},长宽高 D = {L, W, H},以及各个坐标轴方向上的旋转角 R = {ϕ, φ , θ}来描述。
而我们通过问题的简化,只需要去预测与地面垂直的坐标轴旋转角(Kitti是Y轴),所以就有了下图
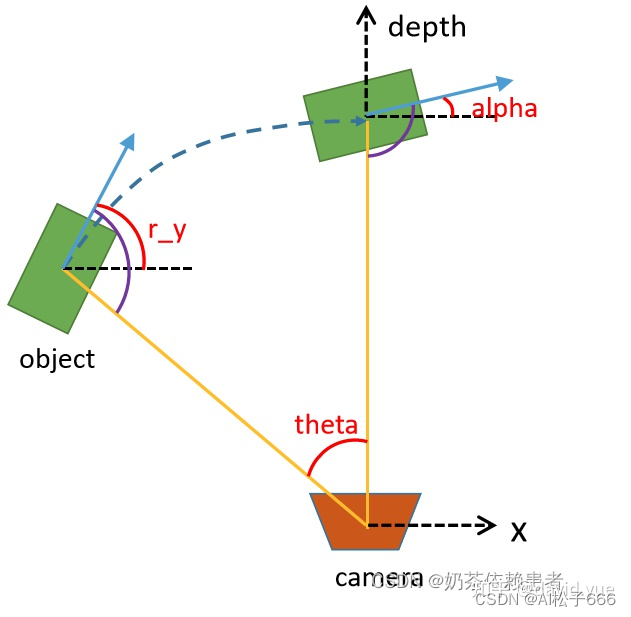
上图中,有三个角度需要特别说明:
alpha:即为模型预测输出,其表示含义为在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,即此时物体方向与相机x轴的夹角
theta:绕Y轴旋转的角度,具体含义为以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴
r_y:障碍物当前时刻朝向与相机坐标系X轴形成的夹角
**在这个旋转过程中,将车辆看成一个刚体,旋转半径(车辆中心点与相机中心点组成的连线)与车辆前进方向组成的夹角在旋转前后是保持不变的,**根据这一个关系,可以得到如下表达式

YOLO3D 原理参考:
3D Bounding Box Estimation Using Deep Learning and Geometry (Deep3DBox) 论文详解
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)