- GLM paper:https://arxiv.org/pdf/2103.10360.pdf
- chatglm 130B:https://arxiv.org/pdf/2210.02414.pdf
前置知识补充
双流自注意力
Two-stream self-attention mechanism(双流自注意机制)是一种用于自然语言处理任务的注意力机制。它是基于自注意力机制(self-attention)的扩展,通过引入两个独立的注意力流来处理不同类型的信息。
-
在传统的自注意力机制中,输入序列中的每个位置都会计算一个注意力权重,用于对其他位置的信息进行加权聚合。而在双流自注意力机制中,会引入两个注意力流,分别用于处理不同类型的信息。
-
双流自注意力,一个注意力流用于处理位置信息(position-based),另一个注意力流用于处理内容信息(content-based)。位置信息可以帮助模型捕捉序列中的顺序和结构,而内容信息可以帮助模型理解不同位置的语义关联。
- 具体来说,双流自注意力机制会为每个注意力流维护一个独立的注意力矩阵,用于计算注意力权重。然后,通过将两个注意力流的输出进行加权融合,得到最终的注意力表示。
- 通过引入两个注意力流,双流自注意力机制可以更好地捕捉不同类型信息之间的关系,提高模型在语义理解和推理任务中的性能。它在机器翻译、文本分类、问答系统等任务中都有应用,并取得了一定的效果提升。
Transformer修改
层归一化是一种归一化技术,用于在网络的每一层对输入进行归一化处理。它可以帮助网络更好地处理梯度消失和梯度爆炸问题,提高模型的训练效果和泛化能力。
残差链接是一种跳跃连接技术,通过将输入直接添加到网络的输出中,使得网络可以学习残差信息。这有助于网络更好地传递梯度和学习深层特征,提高模型的训练效果和收敛速度。
在一般情况下,层归一化应该在残差链接之前应用。这是因为层归一化对输入进行归一化处理,而残差链接需要将输入直接添加到网络的输出中。如果将残差链接放在层归一化之前,会导致输入的归一化被破坏,从而影响模型的训练和性能。
关键术语
MLM:条件独立性假设,预测每个mask的时候是并行的,没有考虑mask之间的关系
Mask:一个单词一个mask,mask可以知道长度信息
Span:几个单词(或者更多个)一起mask掉,span不知道长度信息
把标签映射成词语,进行分类:
- 标成mask,放在最后一个位置,X和Y可以形成一个流畅的语句,接近于自然语言
GLM130B
1)架构选择
通用语言模型GLM
组件改进:旋转位置编码、DeepNorm、GeGLU
2)工程实现
并行策略:数据、张量、流水线3D并行
多平台高效适配
3)训练策略改进
梯度爆炸的问题,采用了嵌入层梯度缩减策略
解决注意力数值溢出问题,采用了FP32的softmax计算策略,训练稳定性有提升
GLM是一种基于Transformer的语言模型,它以自回归空白填充为训练目标。
对于一个文本序列
x
=
[
x
1
,
⋅
⋅
⋅
,
x
n
]
x=[x1, · · · ,xn]
x=[x1,⋅⋅⋅,xn],从其中采样文本span{s1,· · ·,sm},其中每个si表示连续令牌的跨度,并用单个掩码替换si,要求模型对它们进行自回归恢复。
与GPT类模型不同的是,它在不Mask的位置使用双向注意力,因此它混合了两种Mask,以支持理解和生成:
[MASK]:句子中的短空白,长度加总到输入的某一部分
[MASK]根据泊松分布 (λ=3)对输入中标识符进行短跨度的采样,主要服务对文本的理解能力目标
- 将长度相加达到输入的一定部分的句子中的短空白填充。
[gMASK]:随机长度的长空白,加在提供前缀上下文的句子末尾
掩盖一个长的跨度,从其位置到整个文本的结束,主要服务对文本的生成目标能力目标。
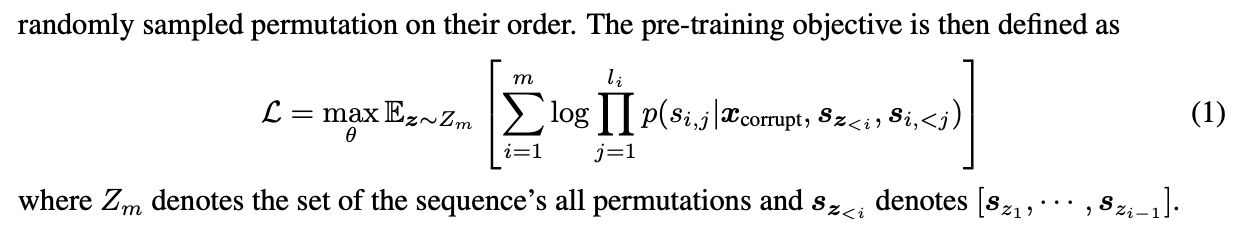
关于LN:
pre-LN(数百亿,混合多模态也不稳定),post-LN(容易发散),SandWish-LN 都在GLM上表现不稳定,所以采用了DeepNorm
D
e
e
p
L
a
y
e
r
(
x
)
=
L
a
y
e
r
N
o
r
m
(
α
∗
x
+
N
e
t
w
o
r
k
(
x
)
)
DeepLayer(x) = LayerNorm(\alpha*x + Network(x))
DeepLayer(x)=LayerNorm(α∗x+Network(x))
关于编码:
1)当序列长度增长时,RoPE的实现速度更快。
2)RoPE对双向注意力更友好,在下游微调实验中效果更好
关于mask:
- 【mask】30% 的training token,占总输入的15%
- 对于其他70%的标记,每个序列的前缀被保留为上下文,并使用[gMASK]来屏蔽其余部分。
FFN改成GLU:
GLM-130B中改进transformer结构中的前馈网络(FFN),用GLU(在PaLM中采用)取代它,实验效果表明选择带有GeLU激活的GLU训练更稳定.(对比了另一个新提出的门控单元GAU)
-
GeGLU需要三个投影矩阵;为了保持相同数量的参数,与只利用两个矩阵的FFN相比,我们将其隐藏状态减少到2/3