1.深度优先遍历(DFS)
(1)从某个顶点V出发,访问顶点并标记为已访问
(2)访问V的其中一个邻接点(通常最左边的那个),如果没有访问过,访问该顶点并标记为已访问,然后再访问该顶点的邻接点,递归执行
先一直往后走,如果该顶点已访问过,退回上一个顶点,再检查该顶点的邻接点是否都被访问过,如果有没有访问过的继续向下访问,如果全部都访问过继续退回到上一个顶点,继续同样的步骤。
深度优先遍历类似于树的先序遍历,深度优先遍历算法结果不唯一。
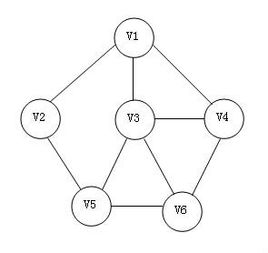
选择V1为出发点,访问V1,然后访问V1的邻接点,邻接点有V2 V3和V4,假设都从左边的邻接点开始访问
访问V1的最左边的邻接点V2,访问V2的邻接点V5
访问V5的邻接点V3,V3的左边邻接点是V1,V1已经访问过,所以访问V4
V4的左边邻接点V6,访问V6,V6的所有邻接点都已访问过,退回V4,V4的所有邻接点也都访问过退回V3,V3的邻接点全部访问过退回V5,
V5的邻接点全部访问过退回V2,V2的邻接点全部访问过退回到出发点V1,V1的全部邻接点访问过,遍历结束。
遍历序列为V1→V2→V5→V3→V4→V6
2.广度优先遍历(BFS)
(1)从某个顶点V出发,访问该顶点的所有邻接点V1,V2..VN
(2)从邻接点V1,V2...VN出发,再访问他们各自的所有邻接点
(3)重复上述步骤,直到所有的顶点都被访问过
(1)从顶点V1出发,v1入队,访问V1,V1的邻接点有V2 V3 V4,将它们入队,v1出队
队列:V2 V3 V4
(2)访问队头V2,V2的邻接点为V1(已访问过,忽略)和V5,将V5入队,V2出队
队列:V3 V4 V5
(3)访问V3,V3的邻接点为V1(访问过忽略) V4(已在队列忽略) V6 V5(已在队列,忽略),V6入队,V3出队
队列:V4 V5 V6
/* 邻接矩阵的广度遍历算法 */
void BFSTraverse(MGraph G)
{
int i, j;
Queue Q;
for(i = 0; i < G.numVertexes; i++)
visited[i] = FALSE;
InitQueue(&Q); /* 初始化一辅助用的队列 */
for(i = 0; i < G.numVertexes; i++) /* 对每一个顶点做循环 */
{
if (!visited[i]) /* 若是未访问过就处理 */
{
visited[i]=TRUE; /* 设置当前顶点访问过 */
printf("%c ", G.vexs[i]);/* 打印顶点,也可以其它操作 */
EnQueue(&Q,i); /* 将此顶点入队列 */
while(!QueueEmpty(Q)) /* 若当前队列不为空 */
{
DeQueue(&Q,&i); /* 将队对元素出队列,赋值给i */
for(j=0;j<G.numVertexes;j++)
{
/* 判断其它顶点若与当前顶点存在边且未访问过 */
if(G.arc[i][j] == 1 && !visited[j])
{
visited[j]=TRUE; /* 将找到的此顶点标记为已访问 */
printf("%c ", G.vexs[j]); /* 打印顶点 */
EnQueue(&Q,j); /* 将找到的此顶点入队列 */
}
}
}
}
}
}
https://blog.csdn.net/lom9357bye/article/details/46604657