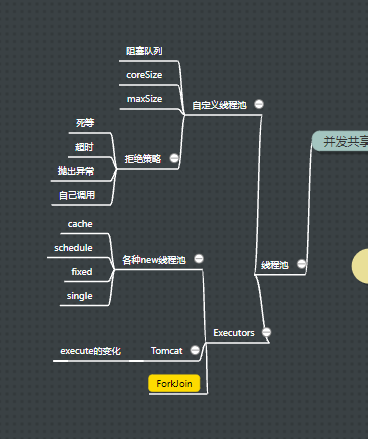
8.线程池
1.自定义线程池
阻塞队列
思路
包括双向队列,让任务从一个方向出来,一个方向进入,相当于就是模仿消息队列,并且需要一个ReentrantLock来保证消息出去的是一个,存入消息的时候也只能有一个线程操作。而且需要两个条件变量控制消费者线程和生产者线程的消费和生产的数量以及阻塞时机。
class BlockedQueue<T>{
//阻塞队列
private Deque<T> queue=new ArrayDeque<>();
//锁
private ReentrantLock lock=new ReentrantLock();
//空队列条件
private Condition emptyCondition=lock.newCondition();
//满队列条件
private Condition fullCondition=lock.newCondition();
private int capcity;
public BlockedQueue(int capcity) {
this.capcity = capcity;
}
public T take(){
lock.lock();
try{
while(queue.isEmpty()){
try {
emptyCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
//唤醒满队列
fullCondition.signal();
return t;
}finally {
lock.unlock();
}
}
public void put(T t){
lock.lock();
try{
while(queue.size()==capcity){
try {
fullCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
queue.addLast(t);
emptyCondition.signal();
}finally {
lock.unlock();
}
}
public int getCapcity(){
lock.lock();
try{
return this.capcity;
}finally {
lock.unlock();
}
}
}
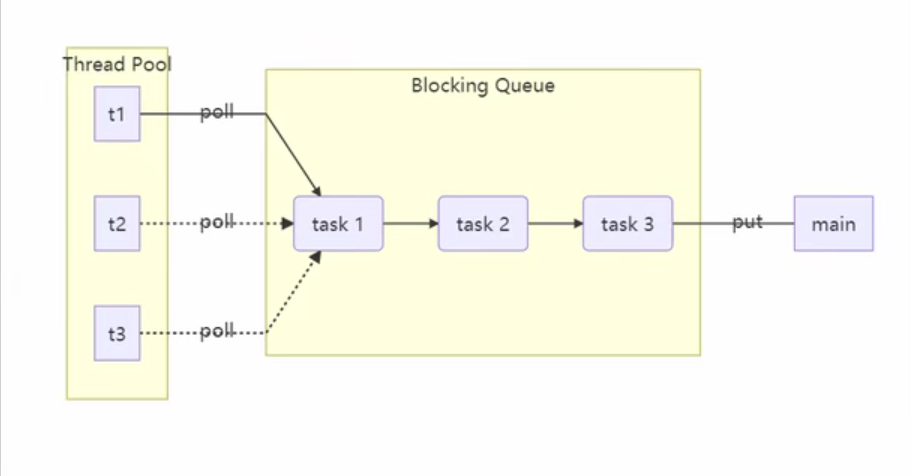
优化队列
设置等待时间,通过TimeUnit把秒转换成纳秒,最后awaitNacos返回的是还需要等待的时间,如果小于0那么就要结束等待。
public T poll(long timeout, TimeUnit unit){
lock.lock();
try{
long nacos = unit.toNanos(timeout);
while(queue.isEmpty()){
try {
//等待超时,后自动解锁。
if(nacos<=0){
return null;
}
nacos= emptyCondition.awaitNanos(nacos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
//唤醒满队列
fullCondition.signal();
return t;
}finally {
lock.unlock();
}
}
线程池
包括核心线程数,任务阻塞队列,任务超时时间等。
class ThreadPool{
private BlockedQueue<Runnable> queue;
private HashSet<Worker> workers=new HashSet<>();
private int coreSize;
private long timeout;
private TimeUnit timeUnit;
/**
* 初始化
* @param coreSize
* @param timeout
* @param timeUnit
* @param queueCapcity
*/
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapcity) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
queue=new BlockedQueue<Runnable>(queueCapcity);
}
class Worker{
}
}
执行和线程处理设计
- 执行之前需要查看线程是否够用,如果不够那么就放入消息队列
- 如果够那么就创建线程然后执行,并且把线程放入线程池
- 线程执行之后,还需要持续判断是否有任务存在,如果有继续执行,如果没有那么就把自己退出线程池,结束循环
public void execute(Runnable task){
synchronized (this){
//保证只有一个线程能够被创建
if(workers.size()<coreSize){
Worker worker = new Worker(task);
workers.add(worker);
}else{
//如果没有线程处理那么就放入到阻塞队列
queue.put(task);
}
}
}
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
while(task!=null||(task=queue.take())!=null){
try {
task.run();
} catch (Exception e) {
e.printStackTrace();
}finally {
task=null;
}
}
//执行完任务之后立刻移除当前线程。
synchronized (workers){
workers.remove(this);
}
}
}
线程池执行的整个思路
创建线程池之后,然后for循环让它执行任务,如果核心空闲的线程有那么就创建并且执行任务,如果没有多余的线程那么进入消息队列等待。线程空闲之后访问消息队列是不是还有任务,如果有那么就执行,没有就退出,并且退出线程池。
- 使用take的问题就是,多个线程在无限时间等待任务,但是任务已经没有了,而且没有东西可以唤醒线程导致线程一直阻塞无法运行。解决办法就是使用ReentrantLock的超时等待功能
- 线程执行任务,不断访问消息队列,如果任务结束那么就结束循环,并且退出线程池。但是通常是没有办法退出循环,原因是线程取任务的时候被消息队列阻塞了,因为消息队列没有任务让线程等等,那么所有的线程都会被阻塞
- 关于put为什么需要加锁,如果不加锁,那么就会有多个线程进入去add这个任务,可能会导致同时判断队列没满,然后加入对象让队列内存溢出
@Slf4j(topic = "c.test")
public class MyTestThreadPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2, 1000, TimeUnit.MILLISECONDS, 10);
for(int i=0;i<5;i++){
int j=i;
threadPool.execute(()->{
log.debug("执行任务{}",j);
});
}
}
}
@Slf4j(topic = "c.pool")
class ThreadPool{
private BlockedQueue<Runnable> queue;
private HashSet<Worker> workers=new HashSet<>();
private int coreSize;
private long timeout;
private TimeUnit timeUnit;
public ThreadPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapcity) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
queue=new BlockedQueue<Runnable>(queueCapcity);
}
public void execute(Runnable task){
synchronized (this){
//保证只有一个线程能够被创建
if(workers.size()<coreSize){
Worker worker = new Worker(task);
log.debug("线程和任务创建{},{}",worker,task);
workers.add(worker);
worker.start();
}else{
log.debug("加入到任务队列{}",task);
//如果没有线程处理那么就放入到阻塞队列
queue.put(task);
}
}
}
// @Slf4j(topic = "worker")
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
while(task!=null||(task=queue.poll(timeout,timeUnit))!=null){
try {
log.debug("任务被执行{}",task);
task.run();
} catch (Exception e) {
e.printStackTrace();
}finally {
task=null;
}
}
//执行完任务之后立刻移除当前线程。
synchronized (workers){
log.debug("线程完成任务退出池{}",this);
workers.remove(this);
}
}
}
}
class BlockedQueue<T>{
//阻塞队列
private Deque<T> queue=new ArrayDeque<>();
//锁
private ReentrantLock lock=new ReentrantLock();
//空队列条件
private Condition emptyCondition=lock.newCondition();
//满队列条件
private Condition fullCondition=lock.newCondition();
private int capcity;
public BlockedQueue(int capcity) {
this.capcity = capcity;
}
public T poll(long timeout, TimeUnit unit){
lock.lock();
try{
long nacos = unit.toNanos(timeout);
while(queue.isEmpty()){
try {
//等待超时,后自动解锁。
if(nacos<=0){
return null;
}
nacos= emptyCondition.awaitNanos(nacos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
//唤醒满队列
fullCondition.signal();
return t;
}finally {
lock.unlock();
}
}
public T take(){
lock.lock();
try{
while(queue.isEmpty()){
try {
emptyCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.removeFirst();
//唤醒满队列
fullCondition.signal();
return t;
}finally {
lock.unlock();
}
}
public void put(T t){
lock.lock();
try{
while(queue.size()==capcity){
try {
fullCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
queue.addLast(t);
emptyCondition.signal();
}finally {
lock.unlock();
}
}
public int getCapcity(){
lock.lock();
try{
return this.capcity;
}finally {
lock.unlock();
}
}
}
阻塞添加
- 阻塞添加的问题就是线程数量不够,而且线程任务处理时间很长,任务量很大,导致需要主线程需要等待任务队列出空位,put任务进去。
解决方案
可以通过对等待加入任务队列的条件变量限制超时时间,如果一定时间没有空位,那么主线程主动放弃把新任务加入到任务队列的操作
public boolean offer(T t,long timeout,TimeUnit unit){
lock.lock();
try{
long nacos=unit.toNanos(timeout);
while(queue.size()==capcity){
try {
log.debug("任务队列满了...");
if(nacos<=0){
return false;
}
nacos = fullCondition.awaitNanos(nacos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//任务加入到队列
log.debug("加入到任务队列{}",t);
queue.addLast(t);
emptyCondition.signal();
return true;
}finally {
lock.unlock();
}
}
拒绝策略
阻塞添加的处理办法有很多
- 死等
- 超时等待
- 立刻放弃
- 调用者自己处理
- 调用者抛出异常
这里使用到了策略模式,实际上就是一个接口,然后如何实现并不知道,可以通过自己的实现来完成不同的拒绝策略。
- 拒绝策略接口是线程池自己的一个成员变量,在队列执行了tryput的时候也就是添加任务到阻塞队列的时候需要把拒绝策略接口带上,原因是如果加入失败(队列是满的时候)那么就要通过拒绝策略来决定队列和任务之间的处理逻辑,也就是主线程应该如何对队列和任务进行拒绝。
- 比如死等,那么就在传入拒绝策略参数的ThreadPool的时候就lambda来调用队列的死等put方法,如果没有任务满了,那么就一直等坑位
- 还可以调用offer超时等待策略。
本质就是通过接口,和lambda函数来完成拒绝策略的多样性编写。并且在需要执行拒绝策略的类中加入成员变量,通过局部变量来传输执行。实际上就是一个执行接口,只要出现该拒绝的时候就可以调用策略执行。
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockedQueue<T> queue,T task);
}
public void execute(Runnable task){
synchronized (this){
//保证只有一个线程能够被创建
if(workers.size()<coreSize){
Worker worker = new Worker(task);
log.debug("线程和任务创建{},{}",worker,task);
workers.add(worker);
worker.start();
}else{
//如果没有线程处理那么就放入到阻塞队列
queue.tryput(rejectPolicy,task);
}
}
}
public void tryput(RejectPolicy<T> rejectPolicy, T task) {
//判断是否满,本队列在调用自己的加入方法,然后其他考自定义
lock.lock();
try{
if(queue.size()==capcity){
rejectPolicy.reject(this,task);
}else{
log.debug("加入到任务队列{}",task);
queue.addLast(task);
emptyCondition.signal();
}
}finally {
lock.unlock();
}
}
各种策略
ThreadPool threadPool = new ThreadPool(2, 1000, TimeUnit.MILLISECONDS, 0
,(queue,task)->{
//死等
// queue.put(task);
//超时等待
// queue.offer(task,500,TimeUnit.MILLISECONDS);
//放弃执行
// log.debug("放弃任务{}",task);
//抛出异常
// throw new RuntimeException("任务执行失败");
//调用者自己执行,不能使用线程池了
task.run();
});
2.ThreadExecutor
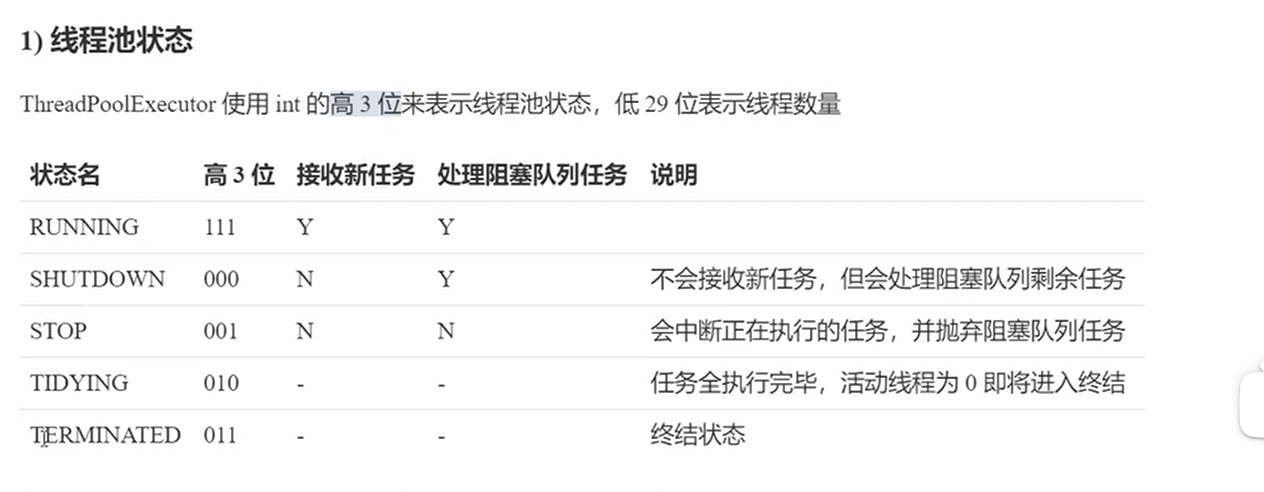
线程池状态
- RUNNINR 111 :接收新任务处理阻塞任务
- SHUTDOWN 000:不接收新任务,处理阻塞任务(温和)
- STOP 001:不接收,且抛弃阻塞任务
- TIDYING:任务执行完,活动线程为0
- TERMINATED:终结状态
线程池参数
- corePoolSize:最大核心线程数
- maximumPoolSize:最大线程数
- keepAliveTime:救急线程可以存活时间
- TimeUnit:存活时间单位
- BlockingQueue:阻塞队列
- ThreadFactory:线程工厂,创建和管理线程
- RejectedExecutionHandler:拒绝策略
工作顺序首先是创建核心线程工作,核心线程满了那么就把任务放进去阻塞队列,阻塞队列也满了那么就放到救急线程处理,最后才是拒绝策略的使用。
核心线程和救急线程最大的不同就是救急线程是有限制时间的。

拒绝策略
- AbortPolicy:抛出异常
- CallerRunPolicy:调用者调用方法
- DiscardOldestPolicy:抛弃最早进入的任务
- DiscardPolicy:放弃这次任务
- Netty:创建新线程
- Dubbo:日志+异常记录问题
- ActiveMq:超时
- Pinpoint:各种拒绝策略

newFixedThreadPool
创建固定大小的线程池,这里的核心线程数和最大线程数一致,而且是LinkedBlockQueue。使用的线程工厂是Executors.defaultThreadFactory(),默认的。实际上就为线程创建好名字。而且创建的线程是非守护线程不会随着main线程结束而结束
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
@Slf4j(topic = "c.test")
public class TestThreadPoolExecutors {
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(2, new ThreadFactory() {
private AtomicInteger i=new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"线程"+i.getAndIncrement());
}
});
pool.execute(()->{
log.debug("1");
});
}
}
newCacheThreadPool
缓存线程池特点
- 只有救急线程
- 同步队列,一手交钱一手交货,也就是一定要有线程处理任务的时候才会接受任务
- 任务量大,执行时间短
- 生产者生产多任务,但是同步队列一定要等任务处理完才会接受下一个任务。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
@Slf4j(topic = "c.TestSynchronousQueue")
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t1").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t2").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t3").start();
}
}
newSingleThreadPool
特点
- 单线程,而且可以处理只有一个线程的时候无法处理的异常,并且在线程出现问题的时候及时创建新线程保证线程池中始终有一个线程运行
- 被包装了FinalizableDelegatedExecutorService,间接调用Executor的方法,这也是和Fixed只有一个线程时候的区别,Fixed可以重新设置线程大小,但是单线程池不可以
- 队列无界
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
submit
有返回值的执行。通过Future进行接收类似,与通信的一个中间信箱。
@Slf4j(topic = "c.test")
public class TestSubmit {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(1);
Future<String> future = service.submit(new Callable<String>() {
@Override
public String call() throws Exception {
log.debug("好人");
return "ok";
}
});
log.debug("结果{}",future.get());
}
}
invokeAll
执行一系列的任务。返回一系列的结果
@Slf4j(topic = "c.test")
public class TestSubmit {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(1);
List<Future<Object>> futures = service.invokeAll(Arrays.asList(
() -> {
Sleeper.sleep(1);
log.debug("测试1");
return "1";
},
() -> {
Sleeper.sleep(0.5);
log.debug("测试2");
return "2";
},
() -> {
Sleeper.sleep(2);
log.debug("测试3");
return "3";
}
)
);
futures.forEach(f->{
try {
log.debug("结果{}",f.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}
}
invokeAny
最快执行完的任务返回结果并且截断其它任务的执行。
@Slf4j(topic = "c.test")
public class TestSubmit {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(1);
String s = service.invokeAny(Arrays.asList(
() -> {
Sleeper.sleep(1);
log.debug("{}", 1);
return "1";
},
() -> {
Sleeper.sleep(0.5);
log.debug("{}", 3);
return "1";
},
() -> {
Sleeper.sleep(2);
log.debug("{}", 2);
return "1";
}
));
log.debug("{}",s);
}
}
关闭线程
shutdown
- 关闭空闲线程,但是不会阻塞运行线程
- 不接收新任务
- 处理完队列任务
shutdownNow
其它方法
- isShutdown()
- isTerminating()
- awaitTermination(long timeout, TimeUnit unit),在terminated之前做一些最后的处理的时间
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//修改线程池状态
advanceRunState(SHUTDOWN);
//关闭所有空闲线程
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//修改状态为stop
advanceRunState(STOP);
//关闭所有线程
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
shutdown之后主线程是不会等待线程池全部执行完的。但是可以通过调用方法awaitTerminated来要求主线程到底需要等待多久。但是shutdownNow需要主线程等待线程池中断之后的返回任务才能够继续执行。
@Slf4j(topic = "c.TestShutDown")
public class TestShutDown {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> result1 = pool.submit(() -> {
log.debug("task 1 running...");
Thread.sleep(1000);
log.debug("task 1 finish...");
return 1;
});
Future<Integer> result2 = pool.submit(() -> {
log.debug("task 2 running...");
Thread.sleep(1000);
log.debug("task 2 finish...");
return 2;
});
Future<Integer> result3 = pool.submit(() -> {
log.debug("task 3 running...");
Thread.sleep(1000);
log.debug("task 3 finish...");
return 3;
});
log.debug("shutdown");
pool.shutdown();
pool.awaitTermination(3, TimeUnit.SECONDS);
log.debug("other");
// List<Runnable> runnables = pool.shutdownNow();
// log.debug("other.... {}" , runnables);
}
}
设计模式之工作线程
定义
其实就是给线程进行分工。有限的线程处理多个异步任务,而且分工处理,增强效率。
上菜案例
出现的问题就是只有两个线程,而且同时点菜成功之后,需要等待其它线程做完菜才能结束运行。但是这里很明显已经没有线程去做菜了,导致了死锁的问题(不是synchronize的死锁),其实就是因为没有线程执行下一步导致大家都卡住在那里
ExecutorService pool = Executors.newFixedThreadPool(2);
pool.execute(()->{
log.debug("点菜");
Future<String> future = pool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜{}",future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
解决方案
可以把线程池的功能区分,一个线程做服务员,一个线程做厨师,那么就不会导致两个都去点菜导致没人做菜的问题.
static final List<String> MENU = Arrays.asList("地三鲜", "宫保鸡丁", "辣子鸡丁", "烤鸡翅");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(1);
ExecutorService cookPool = Executors.newFixedThreadPool(1);
waiterPool.execute(()->{
log.debug("点菜");
Future<String> future = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜{}",future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
waiterPool.execute(()->{
log.debug("点菜");
Future<String> future = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜{}",future.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
});
}
线程池需要的线程数量
cpu密集型
也就是cpu计算时间占据大部分,那么就不需要那么多线程,只需要cpu数量+1的线程,多一个去处理页缺失问题也就是虚拟内存导致。cpu计算时间多,如果线程数还多的话问题就是上下文切换导致的时间浪费,性能消耗。所以只需要刚好这么多就可以了
IO密集型
cpu百分之50去计算,百分之50去等待,那么就需要多个线程去处理等待的问题,如果需要io等待,只需要分配一个线程去处理阻塞不占用cpu的计算时间,提高cpu的计算利用率。

Timer的缺陷
问题就是只有一个线程在处理,限时任务如果出现异常或者是延迟就会影响后面的线程处理
@Slf4j(topic = "c.32")
public class MyTest32 {
public static void main(String[] args) {
Timer timer=new Timer();
TimerTask task1=new TimerTask() {
@Override
public void run() {
log.debug("执行1");
Sleeper.sleep(2);
}
};
TimerTask task2=new TimerTask() {
@Override
public void run() {
log.debug("执行2");
}
};
timer.schedule(task1,1000);
timer.schedule(task2,1000);
}
}
newScheduledThreadPool
ScheduledThreadPool解决了Timer如果任务出现异常和延迟的问题。可以略过当前任务异常执行下一个任务,并且可以通过多个线程解决延迟问题。
@Slf4j(topic = "c.33")
public class MyTest33 {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1);
scheduledThreadPool.schedule(()->{
log.debug("1");
int i=1/0;
Sleeper.sleep(1);
},1, TimeUnit.SECONDS);
scheduledThreadPool.schedule(()->{
log.debug("2");
},1,TimeUnit.SECONDS);
}
}
scheduleWithFixedDelay和scheduleAtFixedRate方法
- withFix是等待上次执行完之后才开始计算延迟时间
- atFix是在执行任务的时候就已经开始计时了
@Slf4j(topic = "c.33")
public class MyTest33 {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1);
// scheduledThreadPool.scheduleAtFixedRate(()->{
// log.debug("运行");
// Sleeper.sleep(2);
// },1,1,TimeUnit.SECONDS);
scheduledThreadPool.scheduleWithFixedDelay(()->{
log.debug("运行");
Sleeper.sleep(2);
},1,1,TimeUnit.SECONDS);
}
}
异常处理
可以直接通过future来返回异常,因为线程池处理的任务异常全部封装到了future
Future<String> future = scheduledThreadPool.submit(() -> {
log.debug("测试");
// int i = 1 / 0;
return "1";
});
log.debug("{}",future.get());
定时任务
主要就是对间隔时间的一个计算,使用LocalDateTime进行处理。with设置时间,compareto来对比两个时间的大小,最后使用plus等方法来增加时间。Duration来计算时间差,然后就可以带入到上面的定时任务。
LocalDateTime now=LocalDateTime.now();
LocalDateTime time = now.withHour(18).withSecond(0).withMinute(0).withNano(0).with(DayOfWeek.THURSDAY);
log.debug("{}",now);
log.debug("{}",time);
if(now.compareTo(time)>0){
time=time.plusWeeks(1);
}
log.debug("{}",time);
long l = Duration.between(now, time).toMillis();
System.out.println(l);
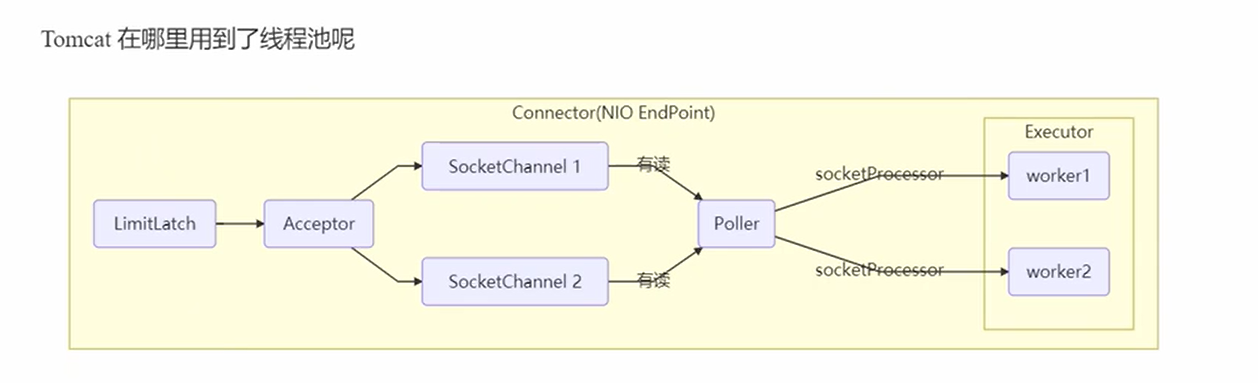
3.Tomcat的线程池(StandardThreadExecutor)
每个线程的作用
- LimitLatch:能够限制连接
- Acceptor:接收socket连接
- Poller:查询SocketChannel是否有IO事件
- worker负责处Poller监听到封装好的socketProcessor
分工处理,并发度更强。
最大和Executor创建的线程池的区别是execute是重写的,这里再救急线程用完之后不会立即调用拒绝策略,而是再次尝试把任务放入队,如果失败那么才调用拒绝策略
public void execute(Runnable command) {
if (this.executor != null) {
try {
//执行任务
this.executor.execute(command);
} catch (RejectedExecutionException var3) {
//发现线程和队列都没有空闲,先尝试把任务再次加入到队列中
if (!((TaskQueue)this.executor.getQueue()).force(command)) {
throw new RejectedExecutionException(sm.getString("standardThreadExecutor.queueFull"));
}
}
} else {
throw new IllegalStateException(sm.getString("standardThreadExecutor.notStarted"));
}
}
调用超时拒绝策略。
public boolean force(Runnable o, long timeout, TimeUnit unit) throws InterruptedException {
if (this.parent != null && !this.parent.isShutdown()) {
//调用超时任务加入
return super.offer(o, timeout, unit);
} else {
throw new RejectedExecutionException(sm.getString("taskQueue.notRunning"));
}
}
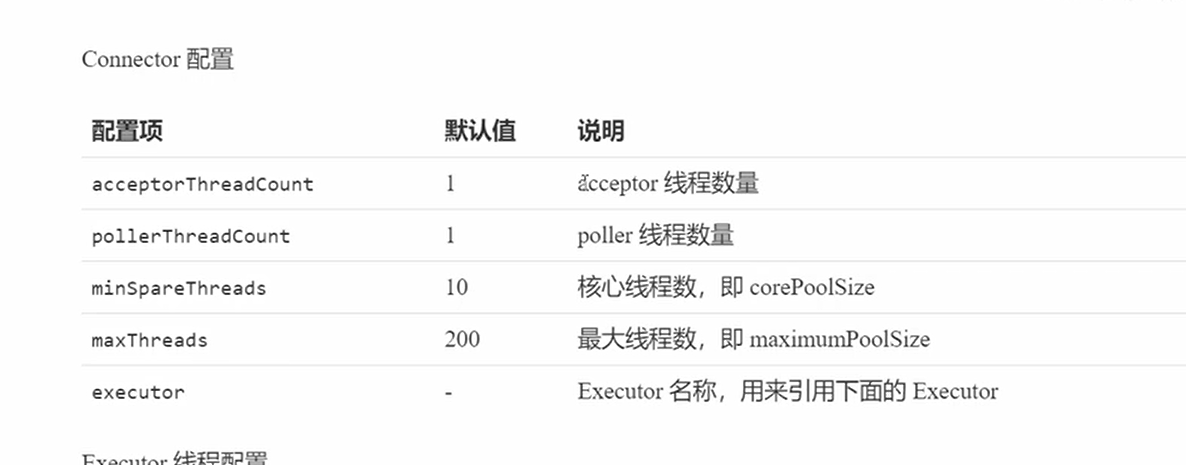
Connetor配置
- acceptorThreadCount:accept线程数量,默认一个
- pollerThreadCount:监视多个,多路复用
- minSpareThreads:核心线程数
- maxThreads:最大线程数
- executor:自定义线程池,如果创建那么上面的参数无效,参考自定义线程池
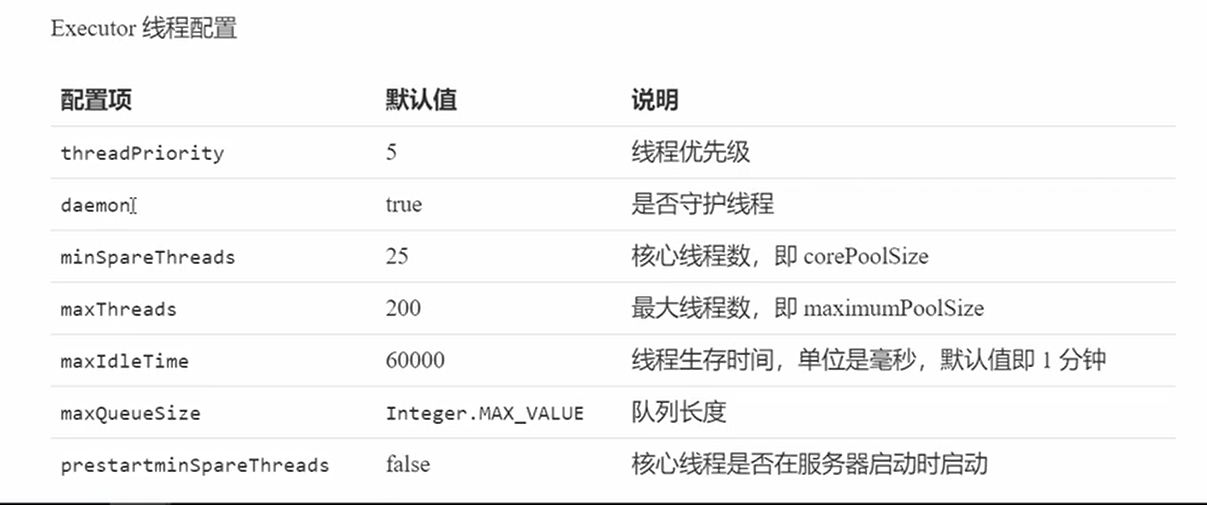
Executor配置
- threadPriority:优先级
- daemon:默认守护线程,tomcat挂那么线程池也要停止
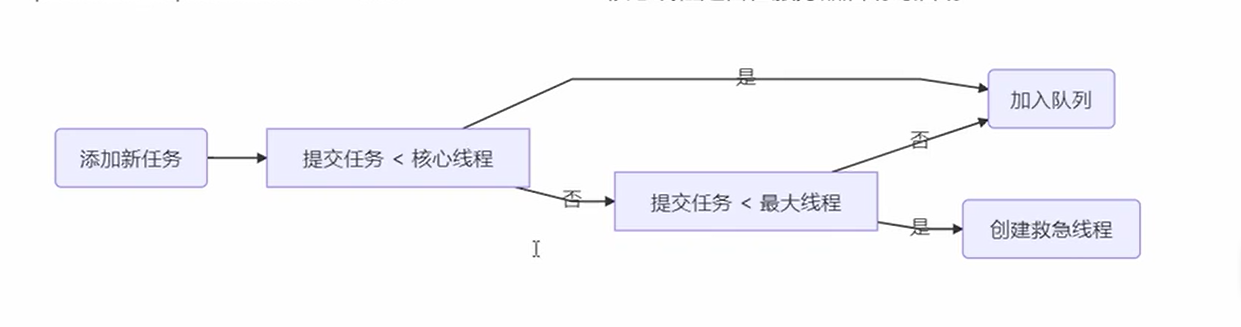
tomcat线程池工作机制
- 添加任务
- 判断任务是否小于核心线程
- 如果是那么加入到队列,如果不是那么就判断提交任务是不是小于最大线程,如果是那么就可以创建救急线程处理任务,如果不是那么就加入到队列。这就是为什么这里的队列是无限的原因,实际上使用救急线程需要队列是有限才能执行,但是这里只要提交任务大于核心线程并且小于最大线程就能够创建和处理。
4.fork/join
定义
其实就是分治,把大任务拆分成小任务交给线程执行。
案例(ForkJoinPool)
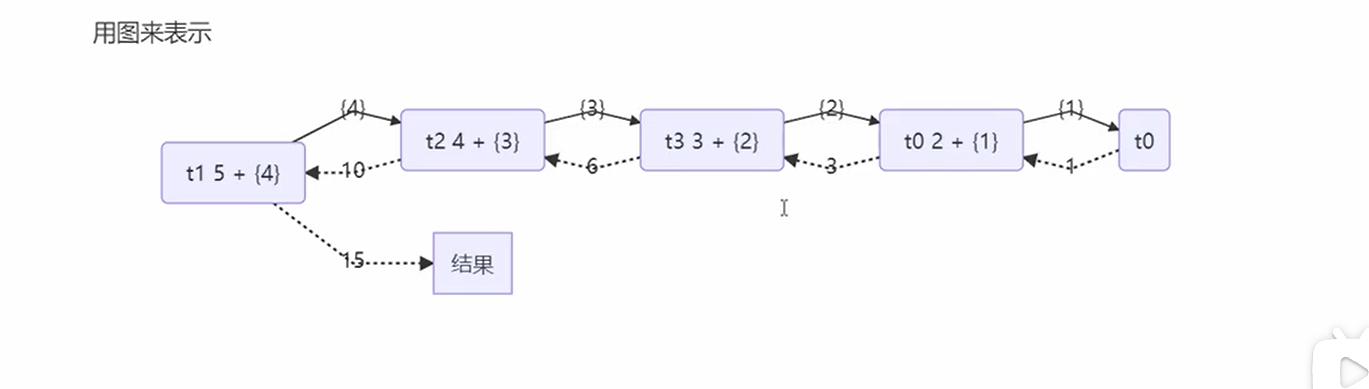
思路
其实就是通过把1+2+3+4+5进行了任务拆分,变成5+(4),4+(3)。。。这样的任务,接着交给不同的线程来进行处理,而且每个线程处理的结果依赖于上一次的小任务处理的结果。
@Slf4j(topic = "c.TestForkJoin2")
public class TestForkJoin2 {
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new MyTask(5)));
// new MyTask(5) 5+ new MyTask(4) 4 + new MyTask(3) 3 + new MyTask(2) 2 + new MyTask(1)
}
}
// 1~n 之间整数的和
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
private int n;
public MyTask(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
protected Integer compute() {
// 如果 n 已经为 1,可以求得结果了
if (n == 1) {
log.debug("join() {}", n);
return n;
}
// 将任务进行拆分(fork)
AddTask1 t1 = new AddTask1(n - 1);
t1.fork();
log.debug("fork() {} + {}", n, t1);
// 合并(join)结果
int result = n + t1.join();
log.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
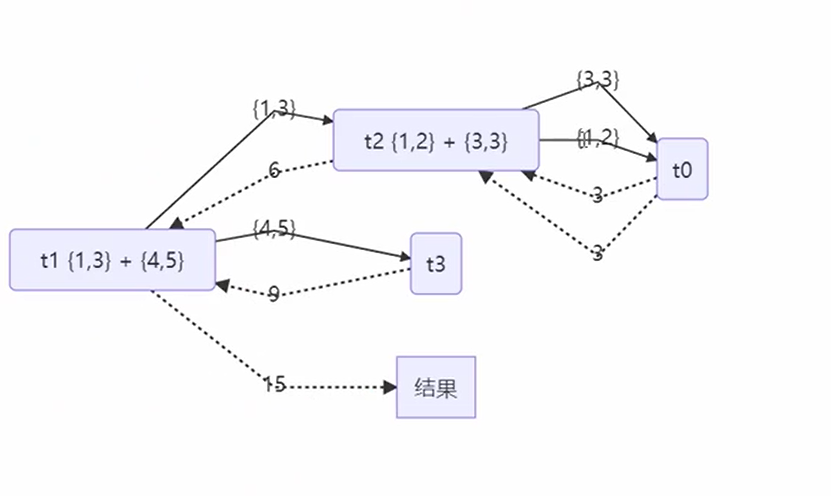
任务拆分优化
优化思路就是二分拆解,把任务拆成两个范围,相当于就是减小了树的深度,返回的速度也就更快了。
相当于这次是拆分成两个节点去处理,而不是一个一个处理,两个处理可以分配多个线程,那么就不需要等待那么多次前面线程处理完之后返回的结果
第八章思维导图
9.JUC
AQS原理
AbstractQueueSynchronizer抽象队列同步器
特点
- state代表资源的状态
- FIFO队列实现
- 多个条件变量,采用的是park和unpark的机制

自定义锁
自定义的锁的方法基本上都是通过AQS来进行实现的
- tryAcquire给state进行修改状态,这次使用的是独享锁,给AQS对象锁设置owner
- 然后就是tryRelease,主要就是设置state为0,解锁,释放owner
- isHeldExcusively:判断是不是有对象在占用锁
- newCondition实际上还是AQS里面的ConditionObject对象,也就是条件变量的创建
最后就是实现锁的方法,基本上都是间接调用同步器的方法来执行
@Slf4j(topic = "c.test111")
public class MyLockTest {
public static void main(String[] args) {
MyLock lock = new MyLock();
new Thread(()->{
System.out.println("线程1执行");
lock.lock();
try{
log.debug("上锁1");
Sleeper.sleep(2);
}finally {
log.debug("解锁1");
lock.unlock();
}
},"t1").start();
new Thread(()->{
lock.lock();
try{
log.debug("上锁2");
Sleeper.sleep(1);
}finally {
log.debug("解锁2");
lock.unlock();
}
},"t2").start();
}
}
class MyLock implements Lock {
class MySync extends AbstractQueuedSynchronizer{
@Override
protected boolean tryAcquire(int arg) {
//尝试加锁
if(compareAndSetState(0,1)){
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
@Override
protected boolean tryRelease(int arg) {
//尝试释放锁
setExclusiveOwnerThread(null);
setState(0);
return true;
}
@Override
protected boolean isHeldExclusively() {
//锁是不是被线程持有
return getState()==1;
}
public Condition newCondition(){
return new ConditionObject();
}
}
private MySync sync=new MySync();
@Override//加锁
public void lock() {
sync.acquire(1);
}
@Override//加锁,可以被中断
public void lockInterruptibly() throws InterruptedException {
sync.acquireInterruptibly(1);
}
@Override//尝试加锁,不成功就放弃
public boolean tryLock() {
return sync.tryAcquire(1);
}
//尝试加锁,超时就进入队列
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
long waitTime = unit.toNanos(time);
return sync.tryAcquireNanos(1,waitTime);
}
@Override
public void unlock() {
sync.release(1);
}
@Override
public Condition newCondition() {
// sync.newCondition();
return sync.newCondition();
}
}
- 调用acquire的时候,AQS首先调用的是tryAcquire也就是我们重写的方法,如果加锁失败,那么就会尝试把线程加入到阻塞队列
public final void acquire(int arg) {
if (!tryAcquire(arg) &&//尝试加锁
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//加锁失败线程进入阻塞队列
selfInterrupt();
}
- release尝试先解锁tryRelease还是自己写的,然后及就是增加了一个唤醒队列中线程的处理。
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
ctrl+alt+左键可以查看接口方法
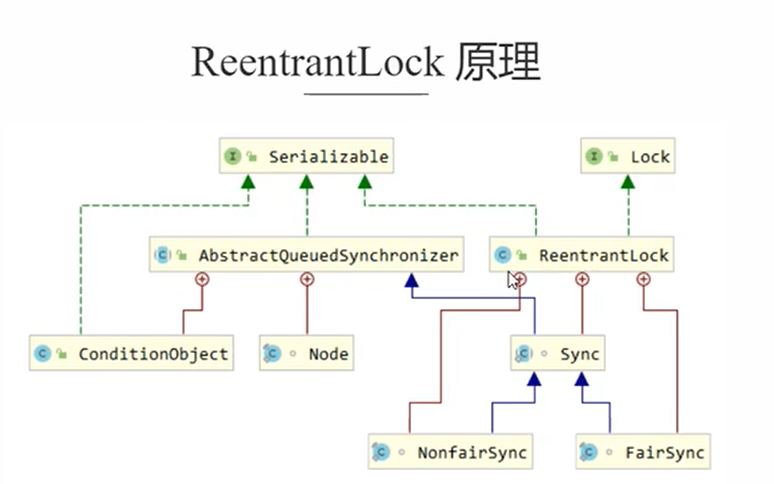
ReentrantLock原理
首先就是ReentrantLock中的Sync同步器继承了AQS而且有两个子类。
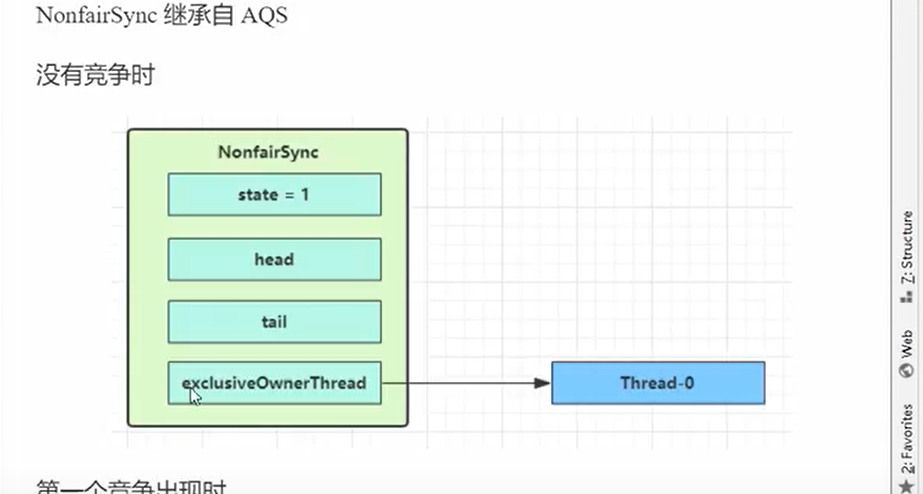
- 非公平锁使用的就是我们定义的那种方法来加锁,state->1然后就是给同步器设置ExclusiveOwnerThread。设置为当前的线程
public void lock() {//ReentrantLock的方法
sync.lock();
}
final void lock() {//NonfairSync
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
lock的整个流程梳理
- 首先就是lock也就是调用Sync的子类NonfairSync的lock,第一次尝试修改state和把线程放进owner
- 假设如果不能放入和修改,那么就会调用AQS的acquire方法
- acquire方法主要就是再次进行tryAcquire也就是重新去上锁,如果还是失败那么就调用addWaiter也就是把当前线程加入到阻塞队列
- 加入到阻塞队列之后再次调用acquireQueue
- 取出节点的前驱节点,如果发现是头结点,那么再次尝试上锁,看看能不能获取锁
- 如果不能那么就调用shouldParkAfterFailedAcquire也就是给前驱节点的状态赋值为-1,意思就是前驱节点有义务唤醒后驱节点,返回false
- 再次进入循环再一次acquireQueue尝试tryAcquire获取锁,再次失败,这个时候shouldParkAfterFailedAcquire发现前驱节点的状态是-1,那么就调用parkAndCheckinterupt来把线程阻塞
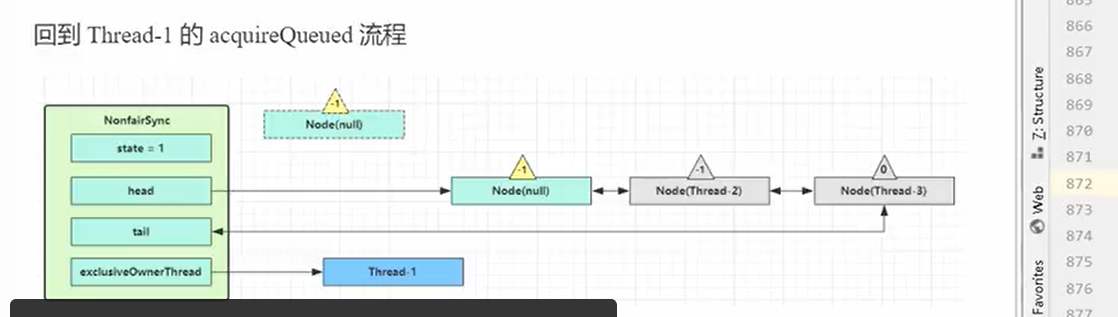
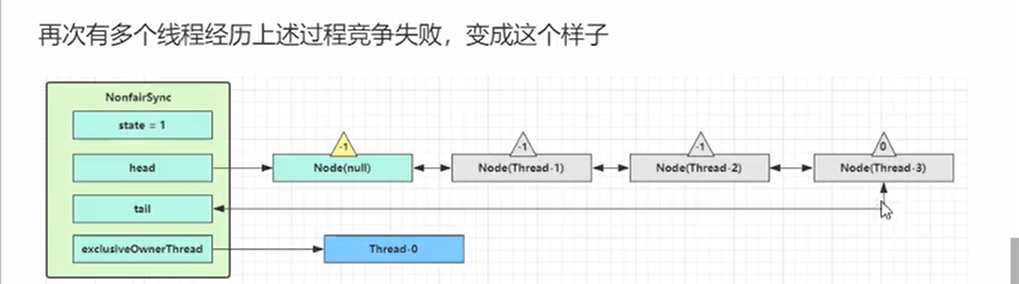
- Sync的lock->AQS.acquire->tryAcquire->addWaiter 和 acquireQueue(相当于就是加入队列之后再次尝试获取锁,并且告知前面的节点有必要唤醒自己)->shouldParkAfterFailedAcquire(告知前驱节点)->acquireQueue->tryAcquire再次尝试->parkAndCheckinterupt
总共尝试了4次获取锁。(作用?)
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
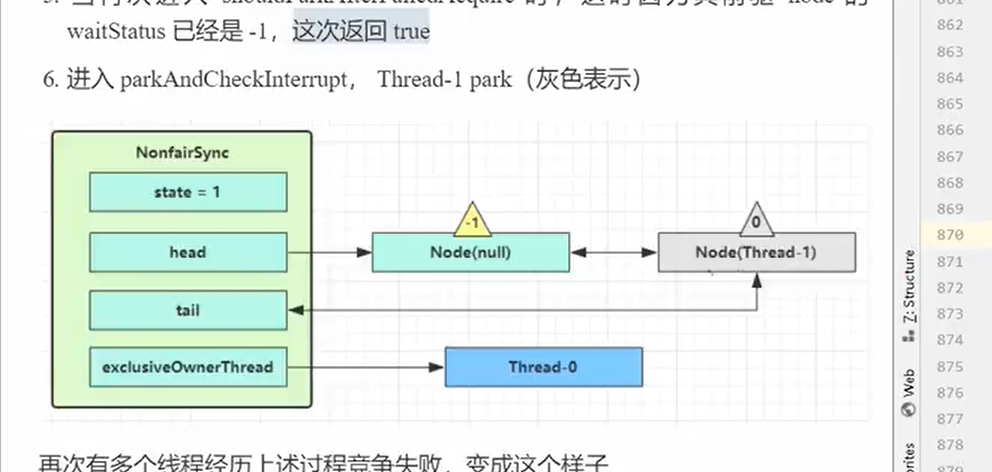
unlock流程详解
- unlock调用sync的release
- release尝试解锁tryRelease(AQS子类Sync的解锁),尝试设置owner为空,和设置状态是0也就是空闲状态(锁空间)
- 然后发现release下面还有取AQS队列中的头结点,如果发现头结点不是空,而且状态是-1那么就要去唤醒下一个节点,其实就是直接取出来,然后调用LockSupport的unpark进行解锁
- 解锁之后线程回到parkAndCheckInterrupt这个位置继续往下面执行,然后尝试加锁
- 如果加锁tryAcquire成功那么就会去掉原来的头部,并且设置当前线程的节点是头结点,并且把线程送到owner(这步是在tryAcquire中处理的)。然后解锁结束
流程总结ReentrantLock.unlock->AQS.release->Sync.tryRelease->state修改,owner设置为null->唤醒下一个队列节点->parkAndCheckInterrupt中重新往下面执行
如果这个时候有线程在外面进来,由于是非公平锁,所以还是会与唤醒的线程竞争。竞争失败再次进入队列
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())//解锁后的位置
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;//获取下一个节点
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);//解锁
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);//设置owner为空
}
setState(c);//修改状态
return free;
}
可重入的原理
- 实际上就是在进入获取锁的时候先获取状态的值,如果发现是0(那么就是线程没有获取锁),如果发现不是0而且当前线程和owner相同,也就是线程获取了锁,那么就给当前状态+1。相当于就是再次获取锁
- 如果是在解锁的时候tryRelease,它会先让状态减1,如果状态是0那么说明不是可重入可以释放锁,如果state不是0那么就是可重入返回的是false。那么就是不会让当前线程释放锁。
本质就是state代表状态也代表锁重入次数,通过state来决定是不是可重入锁,并且对比owner来是不是当前线程来决定是否可以可重入还是说直接加锁。
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {//如果锁没有锁定资源,那么就把锁交给当前线程
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {//如果当前的资源是当前线程那么就可以修改状态,也就是锁被同1线程获取多少次
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
//state-1相当于就是锁释放一次,如果发现不是0那么就是可重入锁。
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
不可打断的原理
- 其实就是在parkAndCheckInterrupt的时候,打断线程,并且清除了打断标记
- 再次进入循环,如果没有锁那么还是会阻塞
- 如果有锁那么就会返回到获取锁之后线程再次调用一次中断。相当于就是再次提醒线程是否要被打断
- 但是实质上是队列中的线程需要有锁才能运行不可以被打断弄出来
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);
return Thread.interrupted();
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())//中断并且设置interrupted为true
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();//调用中断
}
static void selfInterrupt() {//再次调用线程中断
Thread.currentThread().interrupt();
}
可打断的原理
- 这里Sync调用的不再是acquire而是acquireInterruptibly
- acquireInterruptibly的处理方式就是调用doAcquireInterruptibly(int arg)
- 这个方法一旦被打断立刻抛出异常
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
//被打断后抛出异常
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
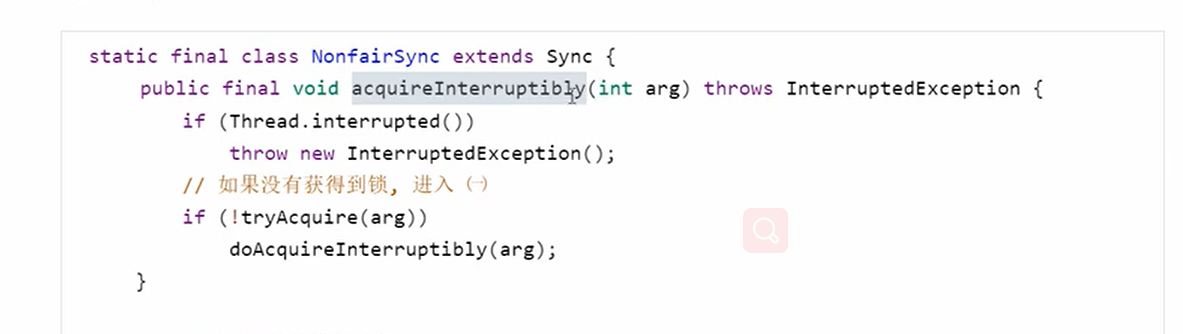
难点:可打断和不可打断的区别实质上就是被打断之后的处理方式。不可打断是通过变量interrupted来标记被打断,然后获取锁之后才能够打断线程。可打断直接抛出异常
非公平和公平锁
公平
公平这个地方会先判断是否有前驱节点,如果有那么就没办法直接去抢占,如果没有那么就可以直接抢。主要就是判断前驱节点是否有下一个节点,和下一个节点是不是就是当前的线程,如果不是那么就没办法锁定,只能够进入acquireQueue方法判断是不是需要阻塞。
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());//判断前驱节点的下一个是不是为空
}
非公平
直接就是判断owner是不是空,如果不是那么就直接切入,而不是先去判断AQS是不是有节点在阻塞,导致的非公平问题。
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {//直接判断而不会去查询AQS是不是有节点在阻塞
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
条件变量
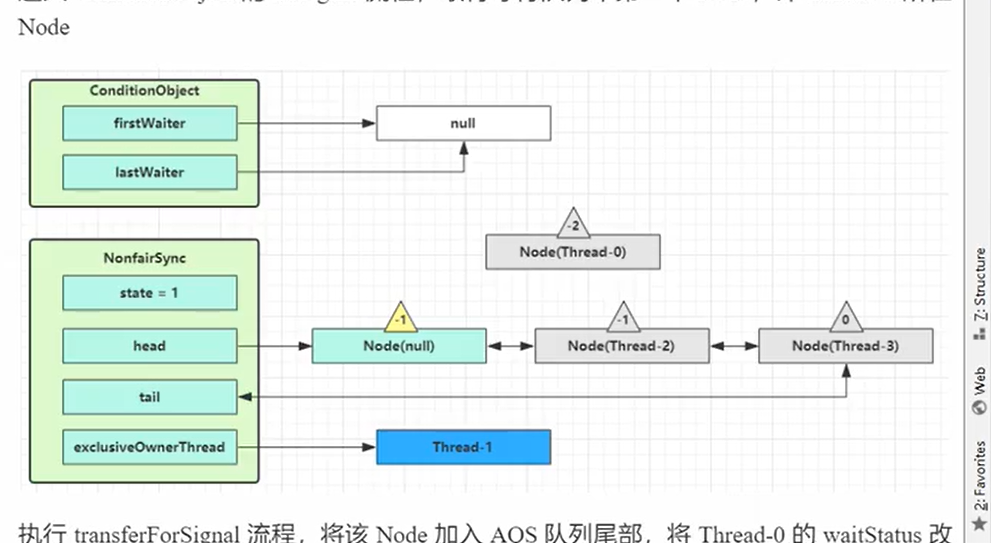
await原理
- 首先就是把线程放入到对应的await的condition队列(相当于就是休息室)
- 就是清空锁,防止可重入和获取了别的锁。然后唤醒Sync的队列的线程
- 然后就是进入condition阻塞
总结:进入condition队列,清空锁并且唤醒线程,最后就是使用park进行阻塞。
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();//进入condition
int savedState = fullyRelease(node);//清空锁
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);//进入阻塞
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
final int fullyRelease(Node node) {
boolean failed = true;
try {
int savedState = getState();
if (release(savedState)) {//清空锁实际上就是清空state
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);//唤醒同步器队列的线程。
return true;
}
return false;
}
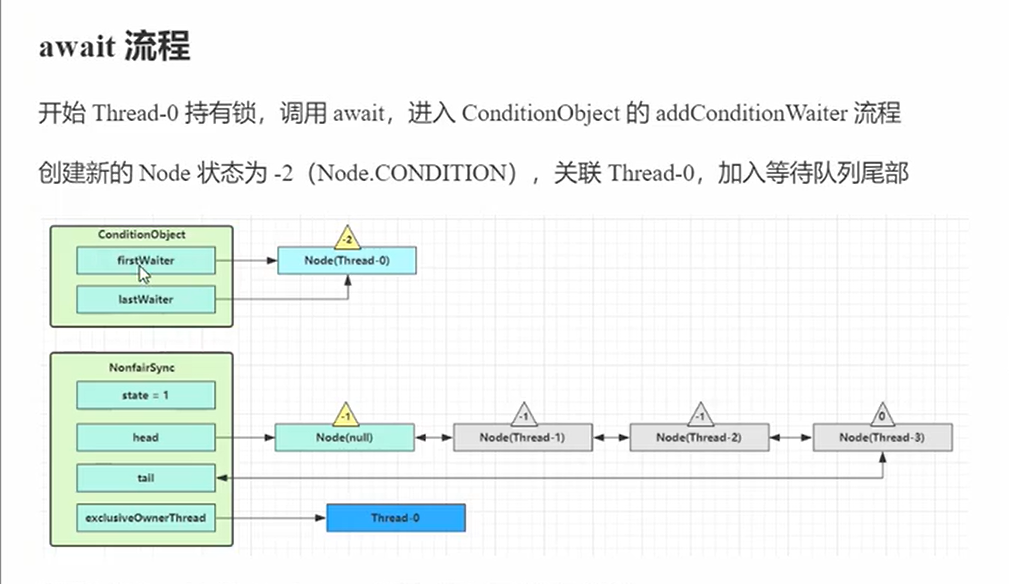
signal的原理
- 首先检查线程是不是获取了锁,然后就是获取队列的头结点
- 接着就是调用doSignal唤醒first加入到Sync的队列(加入到Sync才能够进入到owner竞争锁执行),类似wait之后进入休息室,唤醒后还是要进入队列竞争
- 接着就是获取下一个节点(也就是真正的条件队列节点),获取如果是null,那么最后的节点设置为空
- 如果不为空,节点被取出来并且next节点设置为空(已经保存到firstWaiter中)
- if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
- 首先需要知道这是一个单向链表,而且有指向的队首和指向队尾的节点,可以看下面的addConditionWaiter方法,很明显每次都是直接通过队尾下一个节点指向新节点,然后队尾=新节点。这样子的移动。那么这里的first.nextWaiter就是断开first而已,并没有把firstWaiter设置为null。只是指针没有指向下一个节点。每次相当于就是把firstWaiter队首往后面移动,然后把first节点弄到Sync队列上面去等待。
- 接着就是到把first节点转移通过方法transferForSignal,并且把节点的状态设置为0
- Node p = enq(node);最后就是把节点拼接上Sync队列,并且返回前驱节点
- 修改前驱节点状态-1。结束了signal唤醒
总结:signal完成了条件队列清除(单项链表清除),然后就是把对应的节点全部送去Sync队列。如果失败可能就是队列满了或者是超时了。最后就是取出前驱节点修改状态。
public final void signal() {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
private Node addConditionWaiter() {
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
final boolean transferForSignal(Node node) {
/*
* If cannot change waitStatus, the node has been cancelled.
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
/*
* Splice onto queue and try to set waitStatus of predecessor to
* indicate that thread is (probably) waiting. If cancelled or
* attempt to set waitStatus fails, wake up to resync (in which
* case the waitStatus can be transiently and harmlessly wrong).
*/
Node p = enq(node);
int ws = p.waitStatus;
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
读写锁
好处
读的过程中大部分时间都是可以共享的因为不会修改资源,但是写的时候需要上锁。为了更高的并发和读多写少的问题,可以使用读写锁
- 读读可以并发获取锁
- 读写需要读完才能写,反过来也是一样
- 写写需要等前一个写完
public class MyReadAndWrite {
public static void main(String[] args) {
DataContainer dataContainer = new DataContainer("123");
new Thread(()->{
dataContainer.read();
},"t1").start();
Sleeper.sleep(0.1);
new Thread(()->{
dataContainer.write();
},"t2").start();
}
}
@Slf4j(topic = "c.data")
class DataContainer{
public DataContainer(String s) {
this.s = s;
}
private String s;
private ReentrantReadWriteLock rw=new ReentrantReadWriteLock();
private ReentrantReadWriteLock.ReadLock r=rw.readLock();
private ReentrantReadWriteLock.WriteLock w=rw.writeLock();
public void read(){
log.debug("上读锁");
r.lock();
try{
log.debug("读取{}",s);
Sleeper.sleep(1);
}finally {
log.debug("释放读锁");
r.unlock();
}
}
public void write(){
log.debug("上写锁");
w.lock();
try{
log.debug("读取{}",s);
}finally {
log.debug("释放写锁");
w.unlock();
}
}
}
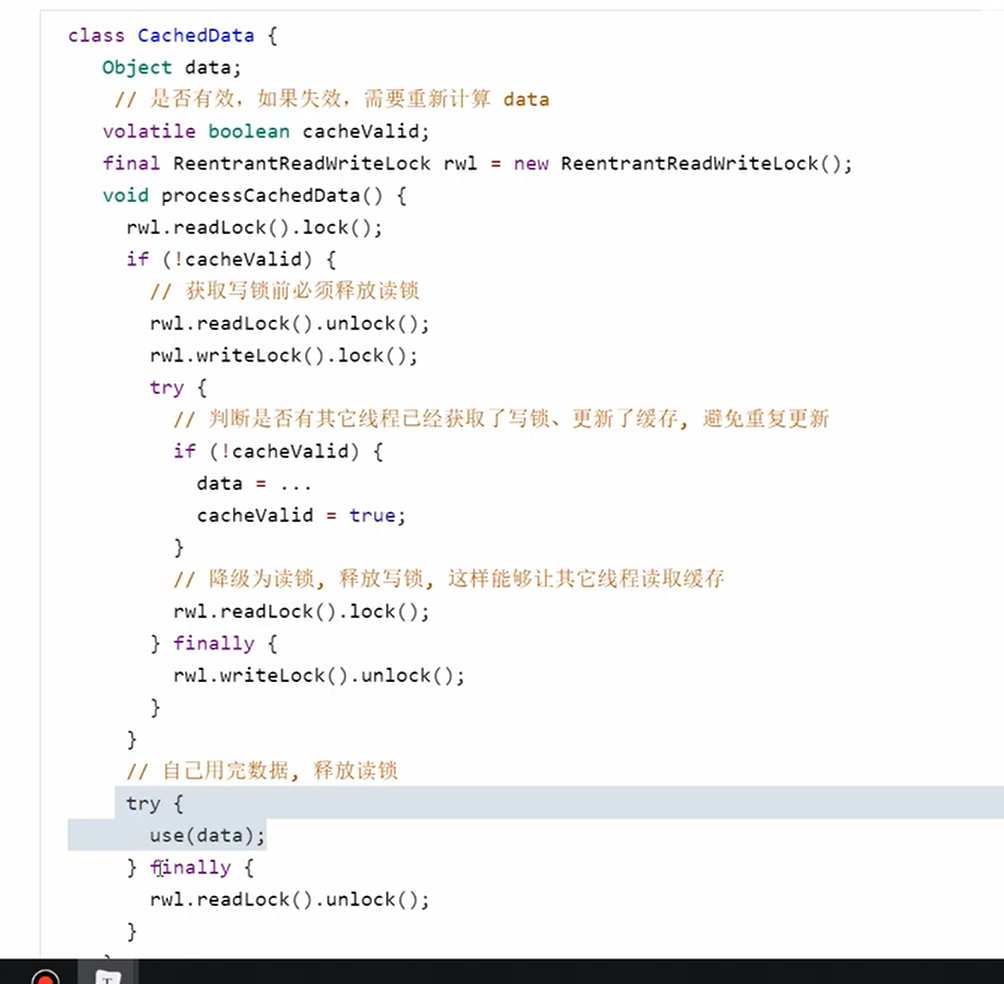
案例
- 缓存如果不存在,那么先释放读锁然后获取写锁
- 然后修改之后先再获取读锁(降级)然后就是释放写锁
- 但是获取读锁之后不能够重入升级获取写锁
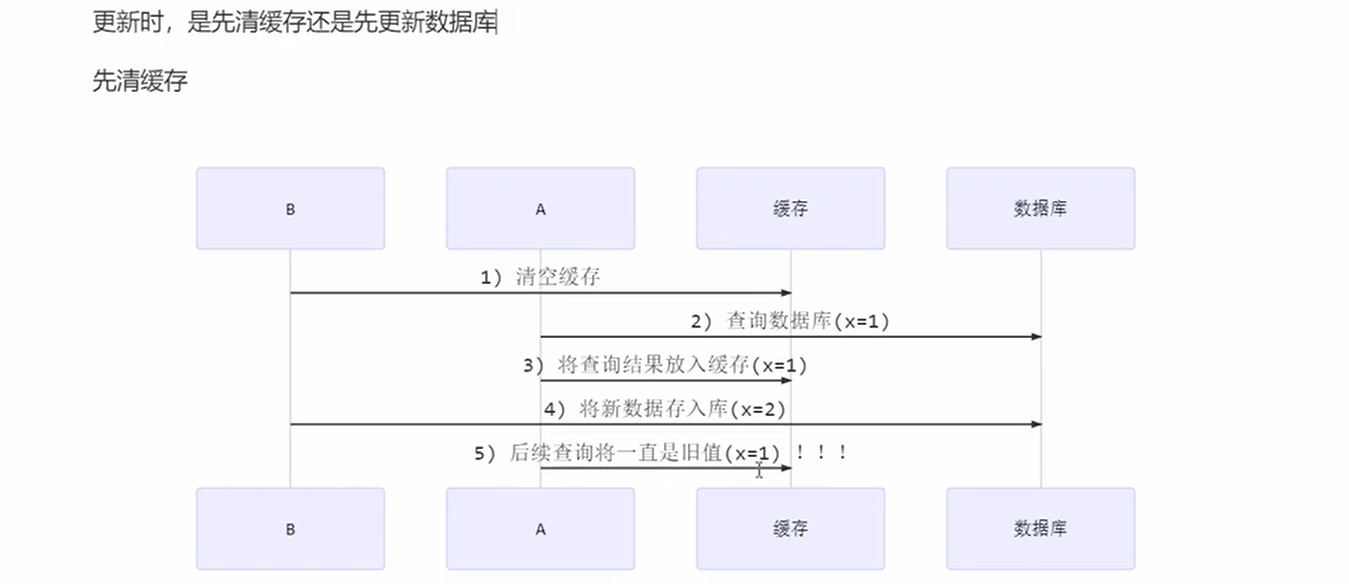
先清除缓存还是更新数据库
先清除缓存
问题就是线程B清空之后还没更新数据库切换到线程A发现缓存空了查询数据库,然后又把旧数据弄上去。B这个时候才修改数据库,如果没有线程修改数据库,那么缓存就会一直不会发生改变,也就是读取错误数据的时间很长
先更新数据库
B去更新数据库,但是还没有缓存的时候,切换到A读取缓存中错误数据,再切换到B来存入新数据到缓存。但是A再次读取就是正确的数据,而不像先清除缓存导致,A获取旧数据库的错误数据,并且如果没有线程修改那么缓存就不会发生变化。
问题
缓存错误期间怎么进行处理?
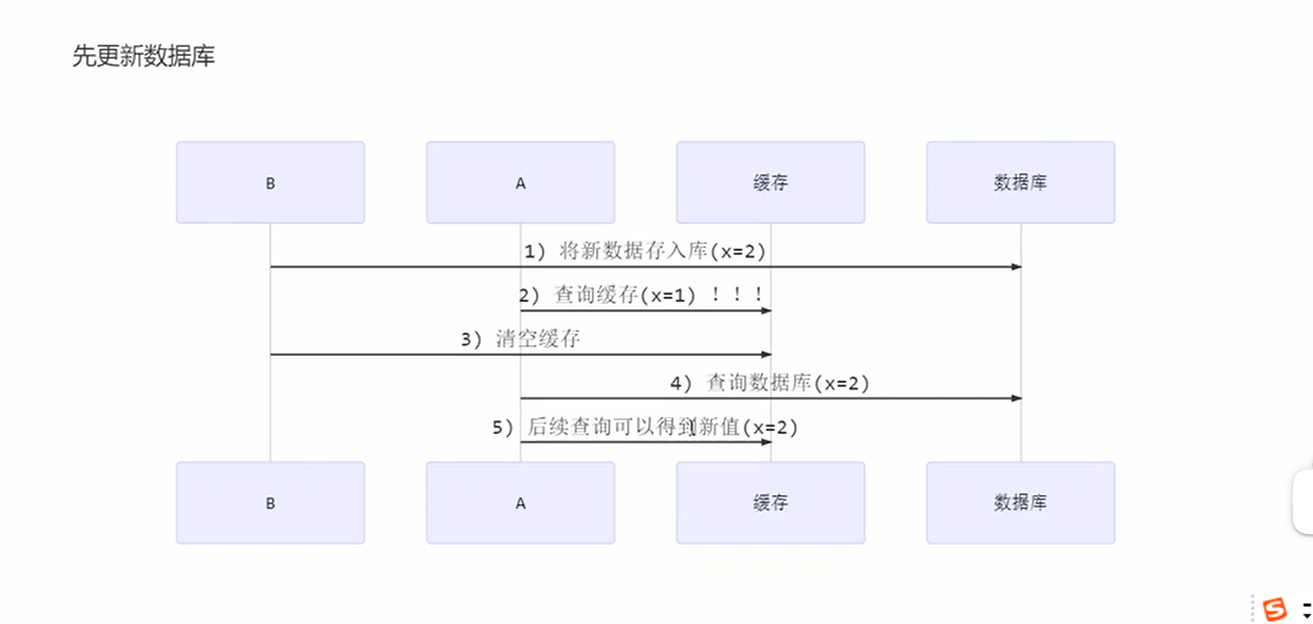
先更新数据库再缓存的错误数据解决方案
使用的是读写锁,当读取query的时候就是读锁,但是可能会多线程判断value不存在缓存之后被切换,那么这个时候除了再给map设置查询缓存的时候加上写锁(避免多个进来写),同时需要进行双重检查value是不是空,因为前一个线程可能已经完成缓存的替换。如果是更新那么直接加上写锁就可以了。
@Override
public <T> T queryOne(Class<T> beanClass, String sql, Object... args) {
// 先从缓存中找,找到直接返回
SqlPair key = new SqlPair(sql, args);;
// rw.readLock().lock();
rw.readLock().lock();
try {
T value = (T) map.get(key);
if(value != null) {
return value;
}
} finally {
rw.readLock().unlock();
// rw.readLock().unlock();
}
// rw.writeLock().lock();
rw.writeLock().lock();
try {
// 多个线程
T value = (T) map.get(key);
// if(value == null) {
// 缓存中没有,查询数据库
if(value==null){
value = dao.queryOne(beanClass, sql, args);
map.put(key, value);
}
// }
return value;
} finally {
rw.writeLock().unlock();
// rw.writeLock().unlock();
}
}
@Override
public int update(String sql, Object... args) {
// rw.writeLock().lock();
rw.writeLock().lock();
try {
// 先更新库
int update = dao.update(sql, args);
// 清空缓存
map.clear();
return update;
} finally {
rw.writeLock().unlock();
// rw.writeLock().unlock();
}
}
可继续优化的地方
读写锁原理
写锁原理
lock
- 写锁也是使用的acquire,而且使用的是state的前16位,后16位是读锁的。规则和state一样的。
- 但是这里使用的Sync就不相同了,使用的是ReentrantReadWriteLock的Sync
- 然后自然的就调用tryAcquire,获取写锁当前的状态,是不是已经被别人获取。如果c不为0说明别人获取了写锁或者是读锁,然后进入判断,w是写锁的意思,w==0说明写锁没被获取,而是被别人获取了读锁,那么就只能获取写锁失败。后面再判断owner是不是当前线程,且w!=0如果是当前线程那么就可以重入。setState(c + acquires);如果超过了可重入范围那么就抛出异常
- 如果不是那么就判断writeShouldBolck是公平还是非公平锁,接着就是上锁
public void lock() {
sync.acquire(1);
}
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread())//如果别人获取读锁或者是owner不是自己,说明了别人获取了写锁或者是读锁,我无法获取锁。假设都不成立说明写锁被获取,并且owner是自己,那么就可以执行写锁可重入。
return false;/
if (w + exclusiveCount(acquires) > MAX_COUNT)//大于可重入的最大值
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);//重入
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))//判断是不是公平锁,判断之后就上锁
return false;
setExclusiveOwnerThread(current);
return true;
}
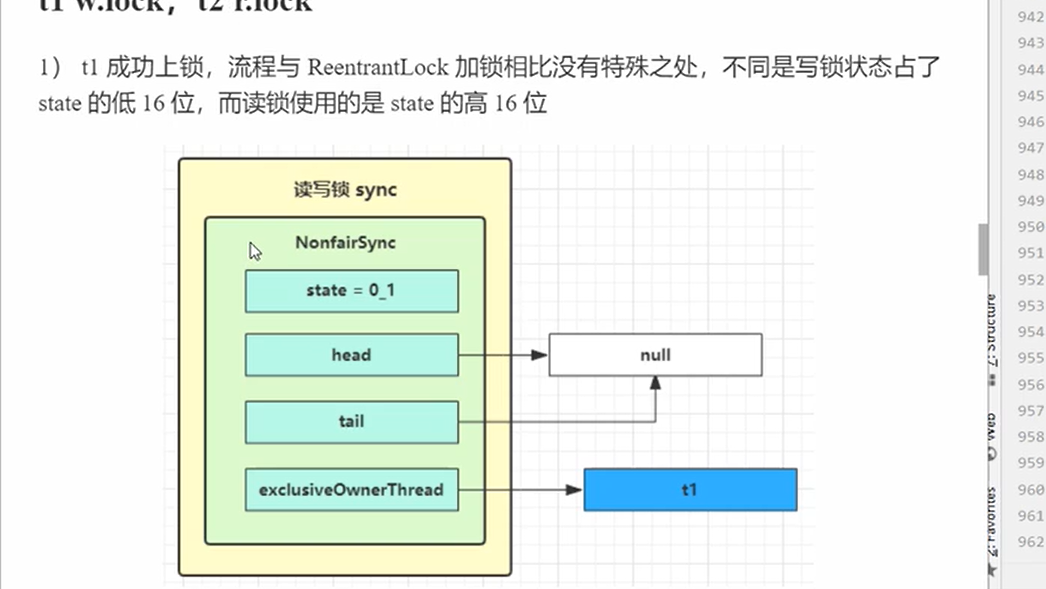
unlock
- 调用的是release,然后就是尝试解锁,其实就是获取状态数,然后-1。防止是可重入,所以用free判断是不是需不需要释放
- 然后就是unparkSuccessor解锁队列后面的线程
- (假设线程2获取读锁)去到doAcquireShare的parkAndCheckInterrupt,继续执行相当于就是和之前一样再次尝试获取锁->tryAcquireShare,那么这个时候获取的读锁状态,如果读锁没有被获取,那么就compareAndSetState(c, c + SHARED_UNIT))修改读锁状态最后就是返回1,并且把线程放到owner去
- 然后就是把当前的节点设置为头结点。
- unlock之后会通过unparkProcessor来唤醒别的线程,这里就很神奇了,读锁的原理,其实就是,解锁只有,阻塞队列的要获取读锁的线程从阻塞中醒来然后,获取锁state+1,接着就是去setHeadAndPropagate(node, r);这里实际上就是把刚才的节点当成头结点并且检查后面是不是读锁节点,如果是那么继续唤醒doReleaseShared();
- doReleaseShared会先把头结点线程状态改成0(开始唤醒下一个节点),防止再次让首节点(不修改就是-1状态)唤醒下一个节点。接着就是把读锁线程唤醒,state+1;
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head; // Record old head for check below
setHead(node);
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())//如果下一个节点还是读锁
//再次唤醒
doReleaseShared();
}
}
private void doReleaseShared() {
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
读锁原理
lock
- 调用的是tryAcquireShare返回值是整数。如果是0就是成功而且没有后继,如果是-1那么就是失败,如果是n那么就是n个后继节点而且加锁成功
- tryAcquireShared先获取锁的状态,如果是如果别人获取了锁c自然就不是0,然后如果也不是自己的线程那么就没办法获取锁,返回-1
- 然后doAcquireShared,还是先把线程加入到队列,如果发现前驱节点是头结点说明自己是老二再次尝试获取锁,如果失败那么就修改前驱节点状态-1,接着就是再次尝试获取锁,失败之后parkAndCheckInterrupt和前面的锁都基本是同一个套路。
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)//如果别人获取了锁c自然就不是0,然后如果也不是自己的线程那么就没办法获取锁,返回-1
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}
private void doAcquireShared(int arg) {
final Node node = addWaiter(Node.SHARED);//加入节点到队列
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {//如果是老二
int r = tryAcquireShared(arg);//再次尝试获取锁
if (r >= 0) {
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&//标记前驱节点状态-1
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
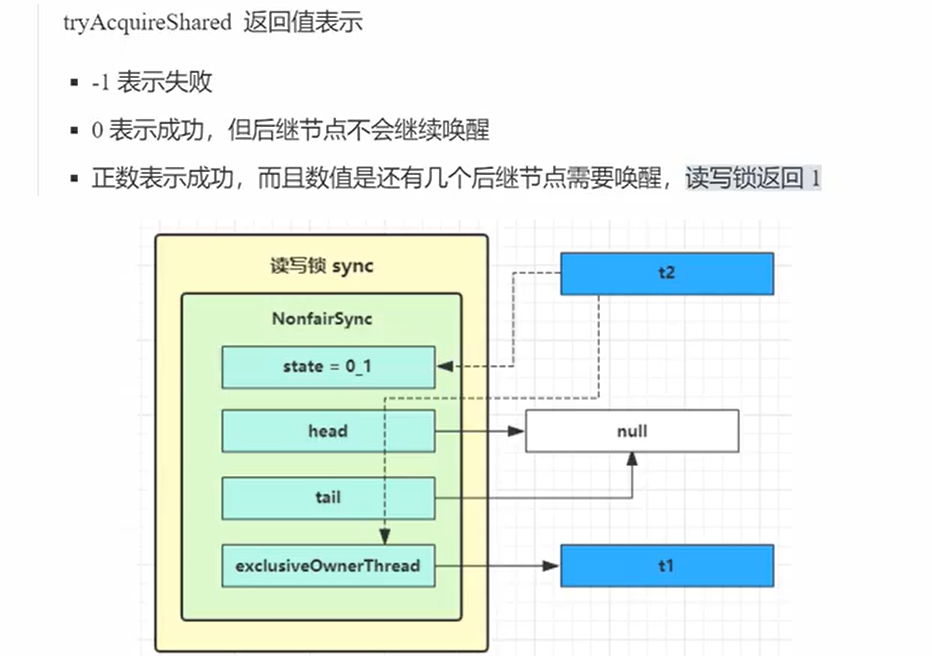
unlock(情景是两个读锁线程解锁)
- 调用了sync.releaseShared(1);
- 然后先去尝试解锁tryReleaseShare,获取锁状态,看看是不是多个读锁,如果是那么就慢慢state-1,暂时不去唤醒其它线程。
- 如果发现读锁线程全部释放了,那么就调用doReleaseAcquire,解放写锁线程获取锁。
- 写锁线程消除阻塞之后tryAcquire,获取之后,把当前节点变成头结点。并且把线程放入owner
public void unlock() {
sync.releaseShared(1);
}
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
//解锁的关键代码
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}
总结:
lock区别:基本流程是一样的,但是读锁的tryAcuireShare返回的是int整型。都是对比状态,然后进行加锁或者是阻塞。但是在doAcquireQueue的时候就不一样,对于写锁来说,直接删除节点即可,但是读锁阻塞结束之后还会去doReleaseShare能够唤醒其它读锁,一系列完成操作
unlock区别:读锁的unlock会等所有线程都退出,那么才会唤醒下一个线程,对于写锁来说除非同一线程可重入,其他都是直接去唤醒队列中的线程。
关键的两个tryAcquire加锁和doAcquireQueue加入阻塞队列
tryRelease尝试解锁,doRelease唤醒下一个线程(这里的-1状态就起作用了)
模板(可能不是很精准)
lock
if(tryAcquire){//尝试获取
doAcquireQueue()//如果无法获取锁进入阻塞队列
}
doAcquireQueue(){
-
取 node
-
node如果是老二,再次tryAcquire
-
标记前驱节点
-
再次tryAcquire
-
阻塞
阻塞结束之后
- 再次tryAcquire
- 如果是写锁删头,如果是读锁再次唤醒读锁线程
- 结束
}
StampedLock
定义
其实就是每次都加锁的时候都会生成戳,并且解锁对比戳而不是CAS来修改状态进而让读速度达到极致
乐观读
定义其实就是生成戳(不加锁),然后就是判断戳是否被改变,不被改变就继续,改变就升级为读锁
案例上面,只有写锁和读锁一起被使用的时候会导致stamp的改变。两个读锁并不会
StampedLock的问题
@Slf4j(topic = "c.TestStampedLock")
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
sleep(0.5);
new Thread(() -> {
dataContainer.write(1);
}, "t2").start();
}
}
@Slf4j(topic = "c.DataContainerStamped")
class DataContainerStamped {
private int data;
private final StampedLock lock = new StampedLock();
public DataContainerStamped(int data) {
this.data = data;
}
public int read(int readTime) {
long stamp = lock.tryOptimisticRead();
log.debug("optimistic read locking...{}", stamp);
sleep(readTime);
if (lock.validate(stamp)) {
log.debug("read finish...{}, data:{}", stamp, data);
return data;
}
// 锁升级 - 读锁
log.debug("updating to read lock... {}", stamp);
try {
stamp = lock.readLock();
log.debug("read lock {}", stamp);
sleep(readTime);
log.debug("read finish...{}, data:{}", stamp, data);
return data;
} finally {
log.debug("read unlock {}", stamp);
lock.unlockRead(stamp);
}
}
public void write(int newData) {
long stamp = lock.writeLock();
log.debug("write lock {}", stamp);
try {
sleep(2);
this.data = newData;
} finally {
log.debug("write unlock {}", stamp);
lock.unlockWrite(stamp);
}
}
}
基本流程是一样的,但是读锁的tryAcuireShare返回的是int整型。都是对比状态,然后进行加锁或者是阻塞。但是在doAcquireQueue的时候就不一样,对于写锁来说,直接删除节点即可,但是读锁阻塞结束之后还会去doReleaseShare能够唤醒其它读锁,一系列完成操作
unlock区别:读锁的unlock会等所有线程都退出,那么才会唤醒下一个线程,对于写锁来说除非同一线程可重入,其他都是直接去唤醒队列中的线程。
关键的两个tryAcquire加锁和doAcquireQueue加入阻塞队列
tryRelease尝试解锁,doRelease唤醒下一个线程(这里的-1状态就起作用了)
模板(可能不是很精准)
lock
if(tryAcquire){//尝试获取
doAcquireQueue()//如果无法获取锁进入阻塞队列
}
doAcquireQueue(){
-
取 node
-
node如果是老二,再次tryAcquire
-
标记前驱节点
-
再次tryAcquire
-
阻塞
阻塞结束之后
- 再次tryAcquire
- 如果是写锁删头,如果是读锁再次唤醒读锁线程
- 结束
}
StampedLock
定义
其实就是每次都加锁的时候都会生成戳,并且解锁对比戳而不是CAS来修改状态进而让读速度达到极致
乐观读
定义其实就是生成戳(不加锁),然后就是判断戳是否被改变,不被改变就继续,改变就升级为读锁
案例上面,只有写锁和读锁一起被使用的时候会导致stamp的改变。两个读锁并不会
StampedLock的问题
@Slf4j(topic = "c.TestStampedLock")
public class TestStampedLock {
public static void main(String[] args) {
DataContainerStamped dataContainer = new DataContainerStamped(1);
new Thread(() -> {
dataContainer.read(1);
}, "t1").start();
sleep(0.5);
new Thread(() -> {
dataContainer.write(1);
}, "t2").start();
}
}
@Slf4j(topic = "c.DataContainerStamped")
class DataContainerStamped {
private int data;
private final StampedLock lock = new StampedLock();
public DataContainerStamped(int data) {
this.data = data;
}
public int read(int readTime) {
long stamp = lock.tryOptimisticRead();
log.debug("optimistic read locking...{}", stamp);
sleep(readTime);
if (lock.validate(stamp)) {
log.debug("read finish...{}, data:{}", stamp, data);
return data;
}
// 锁升级 - 读锁
log.debug("updating to read lock... {}", stamp);
try {
stamp = lock.readLock();
log.debug("read lock {}", stamp);
sleep(readTime);
log.debug("read finish...{}, data:{}", stamp, data);
return data;
} finally {
log.debug("read unlock {}", stamp);
lock.unlockRead(stamp);
}
}
public void write(int newData) {
long stamp = lock.writeLock();
log.debug("write lock {}", stamp);
try {
sleep(2);
this.data = newData;
} finally {
log.debug("write unlock {}", stamp);
lock.unlockWrite(stamp);
}
}
}
[外链图片转存中…(img-6OKhK5Ce-1634435379876)]