背景
以图搜图,是日常生活中我们经常会用到,例如在选购一款商品时,想要对比价格,往往会在各个购物app上通过搜图的形式来看同一款产品的价格;当你碰到某种不认识的植物时,也可以通过以图搜图的方式来获取该种植物的名称。而这些功能大都是通过计算图像的相似度来实现的。通过计算待搜索图片与图片数据库中图片之间的相似度,并对相似度进行排序为用户推荐相似图像的搜索结果。同时,通过检测图片是否相似也可用于判断商标是否侵权,图像作品是否抄袭等。本文将介绍几种比较常用的相似图像检测方法,其中包括了基于哈希算法,基于直方图,基于特征匹配,基于BOW+Kmeans以及基于卷积网络的图像相似度计算方法。
技术实现

相似图像的检测过程简单说来就是对图片数据库的每张图片进行编码或抽取特征(一般形式为特征向量),形成数字数据库。对于待检测图片,进行与图片数据库中同样方式的编码或特征提取,然后计算该编码或该特征向量和数据库中图像的编码或向量的距离,作为图像之间的相似度,并对相似度进行排序,将相似度靠前或符合需求的图像显示出来。
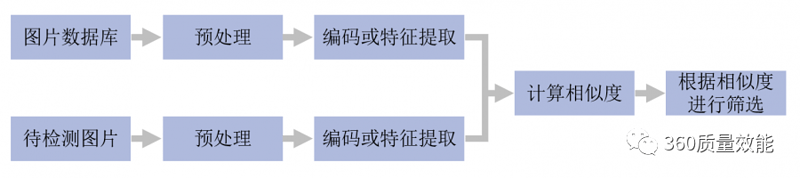
900×201 77.3 KB
哈希算法
哈希算法可对每张图像生成一个“指纹”(fingerprint)字符串,然后比较不同图像的指纹。结果越接近,就说明图像越相似。
常用的哈希算法有三种:
def aHash(img):
img = cv2.resize(img, (8, 8))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
np_mean = np.mean(gray)
ahash_01 = (gray > np_mean) + 0
ahash_list = ahash_01.reshape(1, -1)[0].tolist()
ahash_str = ''.join([str(x) for x in ahash_list])
return ahash_str
def pHash(img):
img = cv2.resize(img, (32, 32))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dct = cv2.dct(np.float32(gray))
dct_roi = dct[0:8, 0:8]
avreage = np.mean(dct_roi)
phash_01 = (dct_roi > avreage) + 0
phash_list = phash_01.reshape(1, -1)[0].tolist()
pha
{kind=link}