我们在工作中用到网络上发布的各种信息,如果用搜索引擎查找并整理,需要花费大量时间,现在python能够帮助我们,使用爬虫技术,提高数据查找和整理的效率。
我们来找一个爬虫的案例——抓取求职招聘类网站中的数据。使用环境:win10+python3+Juypter Notebook
第一步:分析网页
第一步:分析网页
要爬取一个网页,首先分析网页结构。
现在很多网站都用Ajax(异步加载)的技术,打开网页,先给你看上面一部分东西,然后剩下的东西再慢慢加载。所以你可以看到很多网页,都是慢慢的刷出来的,或者有些网站随着你的移动,很多信息才慢慢加载出来。这样的网页有个好处,就是网页加载速度特别快。
但这个技术是不利于爬虫的爬取的,我们可以借助chrome浏览器的小工具进行分析,进入网络分析界面,界面如下:
这时候是一片空白,我们刷新一下,就可以看到一系列的网络请求了。
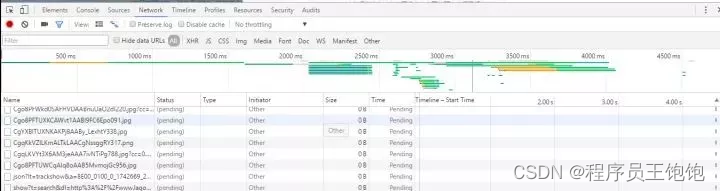
然后我们就开始找可疑的网页资源。首先,图片,css什么之类的可以跳过,一般来说,关注点放在xhr这种类型请求上,如下:
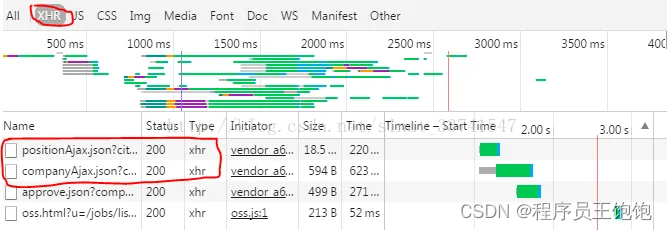
这类数据一般都会用json格式,我们也可以尝试在过滤器中输入json,来筛选寻找。
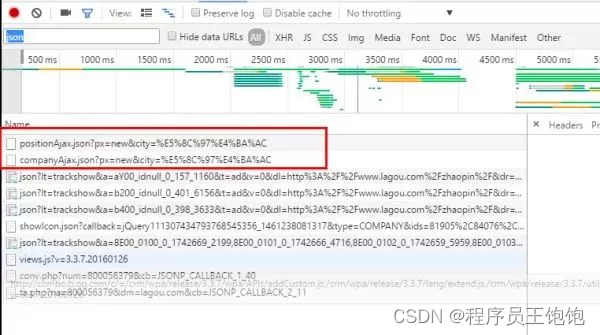
上图发现了两个xhr请求,从字面意思看很有可能是我们需要的信息,右键点击,在另一个界面打开。
我们可以在右边的框中,切换到“Preview”,然后点content——positionResult查看,能看到是关于职位的信息,以键值对的格式呈现,这就是json格式,特别适合网页数据交换。
第二步,网址构造
在“Headers”中,看到网页地址,通过观察网页地址可以发现推测出:http://www.lagou.com/jobs/positionAjax.json?这一段是固定的,剩下的我们发现有个city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false&isSchoolJob=0
再查看请求发送参数列表,到这里我们可以肯定city参数便是城市,pn参数便是页数,kd参数便是职位关键字。
再来看看关于职位,一共有30页,每页有15个数据,所以我们只需要构造循环,遍历每一页的数据。
第三步,编写爬虫脚本写代码
需要说明的是因为这个网页的格式是用的json,那么我们可以用json格式很好的读出内容。这里我们切换成到preview下,然后点content——positionResult——result,可以发现出先一个列表,再点开就可以看到每个职位的内容。为什么要从这里看?有个好处就是知道这个json文件的层级结构,方便等下编码。
具体代码展示:
import requests,json
from openpyxl import Workbook
#http请求头信息
headers={
'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'25',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie':'user_trace_token=20170214020222-9151732d-f216-11e6-acb5-525400f775ce; LGUID=20170214020222-91517b06-f216-11e6-acb5-525400f775ce; JSESSIONID=ABAAABAAAGFABEF53B117A40684BFB6190FCDFF136B2AE8; _putrc=ECA3D429446342E9; login=true; unick=yz; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_navigation; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1494688520,1494690499,1496044502,1496048593; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1496061497; _gid=GA1.2.2090691601.1496061497; _gat=1; _ga=GA1.2.1759377285.1487008943; LGSID=20170529203716-8c254049-446b-11e7-947e-5254005c3644; LGRID=20170529203828-b6fc4c8e-446b-11e7-ba7f-525400f775ce; SEARCH_ID=13c3482b5ddc4bb7bfda721bbe6d71c7; index_location_city=%E6%9D%AD%E5%B7%9E',
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_Python?',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'
}
def get_json(url, page, lang_name):
data = {'first': "true", 'pn': page, 'kd': lang_name,'city':"北京"}
#POST请求
json = requests.post(url,data,headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i['companyId'])
info.append(i['companyFullName'])
info.append(i['companyShortName'])
info.append(i['companySize'])
info.append(str(i['companyLabelList']))
info.append(i['industryField'])
info.append(i['financeStage'])
info.append(i['positionId'])
info.append(i['positionName'])
info.append(i['positionAdvantage'])
# info.append(i['positionLables'])
info.append(i['city'])
info.append(i['district'])
# info.append(i['businessZones'])
info.append(i['salary'])
info.append(i['education'])
info.append(i['workYear'])
info_list.append(info)
return info_list
def main():
lang_name = input('职位名:')
page = 1
url = 'http://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
info_result=[]
title = ['公司ID','公司全名','公司简称','公司规模','公司标签','行业领域','融资情况',"职位编号", "职位名称","职位优势","城市","区域","薪资水平",'教育程度', "工作经验"]
info_result.append(title)
#遍历网址
while page < 31:
info = get_json(url, page, lang_name)
info_result = info_result + info
page += 1
#写入excel文件
wb = Workbook()
ws1 = wb.active
ws1.title = lang_name
for row in info_result:
ws1.append(row)
wb.save('职位信息3.xlsx')
main()
打开excel文件,查看数据是否存取成功:
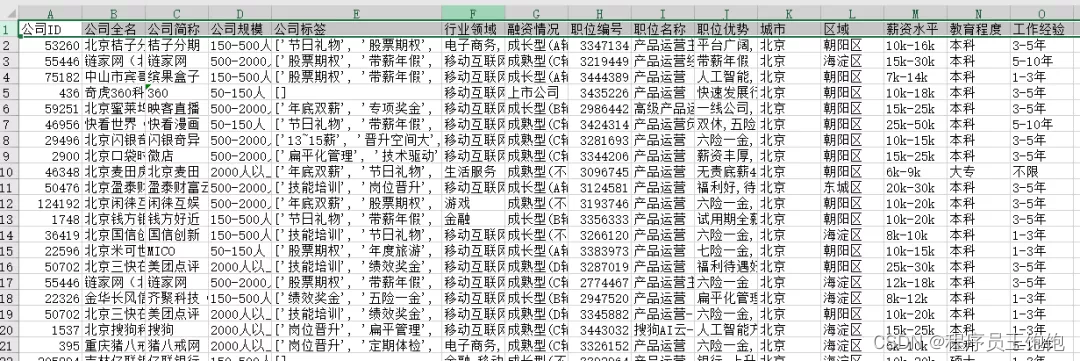
我们看到关于招聘类网站中抓取的数据,被成功的保存在excel表格中。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要这份完整的资料可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
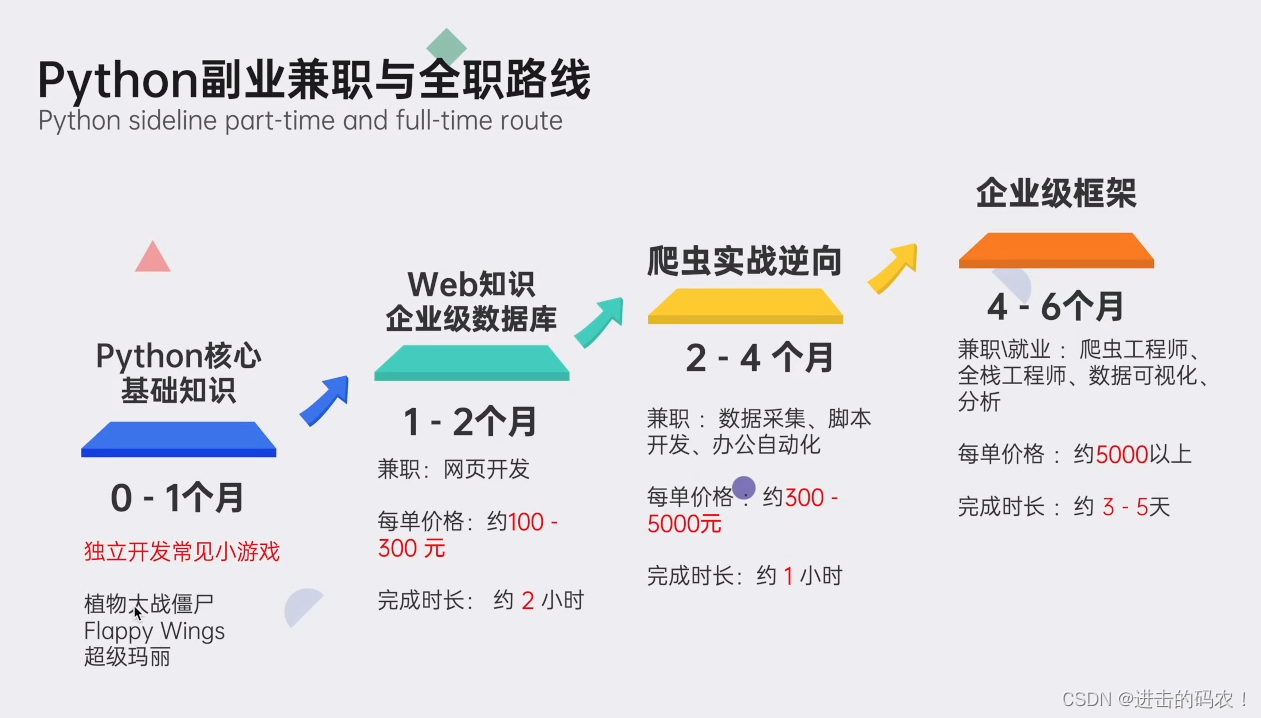
五、python副业兼职与全职路线

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)