目录
前言:
1.打开文件 (open)
关闭文件(close)
2.文件的读取(文件变量名 f)
(1)整体读取(read)
(2)读取一行(readline)
(3)读取多行(readlines)
3.文件的写入(文件变量名f)(write)
4.判断文件的可读性、可写性、是否关闭完全(文件变量名f)
(1)判断文件的可读性(readable)
(2)判断文件的可写性(writeable)
(3) 判断文件是否关闭完全(closed)
5.文件的定位(文件变量名为f)
(1)自定义读写位置(seek)
(2)获取当前位置(tell)
6.with open 打开文件方法
前言:
前面我们学过C语言操作文件,文件有很多种,.txt、.mp3、.doc、.jpg等等……,一般我们是从文本文件txt开始去学习了,这里我们就以文本文件为学习对象,详细讲解Python中文件操作方式。
这个是c语言文本文件操作方法C语言 文本文件读取、写入与定位(详细介绍)_c语言文件的读取和写入_Python欧尼酱的博客-CSDN博客
1.打开文件 (open)
格式:
f = open(文件路径,操作符,encoding=编码)
说明:
文件路径:包括相对路径和绝对路径,如果不写的话,系统会默认当前文件夹的目录
操作符:包括 r(读取read),w(写入write)、a(追加append)、wb(以二进制流写入)、rb(以二进制流读取)……
encoding:这个是设置字符编码,一般用utf8,这个是世界万能编码(几乎集合了世界所以文字字符)。另外介绍 GBK(中文编码)、ASCII(阿斯克码)

f=open(r"./user.txt",'w',encoding='utf8')
f.close() #关闭文件
#说明:
#如果这个文本文件是不存在的,系统会创建一个新的文本文件,如果存在的话,w操作符写入的数据会把原来的内#容覆盖
#r 是表示原始字符串
#./ 是表示当前目录,../ 是表示上一级目录
关闭文件(close)
f.close()
说明:当我们操作完了文件之后一定要记得关闭文件,免得出现内存泄露
2.文件的读取(文件变量名 f)
r
(1)整体读取(read)
格式:
f.read(num)
说明:这个函数是以整个文本为读取对象的,num是表示读取数量,如果num不写的话,那么就读取全部文本,如果num写了,就读取num个字符,最后是返回一个字符串的,当num大于文本里面字符的个数也不会报错
这个是当前文本文件的内容:
f=open(r"./user.txt",'r',encoding='utf8')
s=f.read()
print(s) #读取完成了之后,文件读取指针就在末尾,下面索性就关闭再重新打开
#输出结果:HelloWord,my friend
f.close() #关闭文件
f1=open(r"./user.txt",'r',encoding='utf8') #当要再次读取就的再次打开,出现获取变量
s1=f1.read(2) #表示读取两个字符
print(s1)
#输出结果:He
f1.close()
(2)读取一行(readline)
f.readline(num)
说明:这个函数是只读取一行,num的用法跟上面是一样的
文本内容:
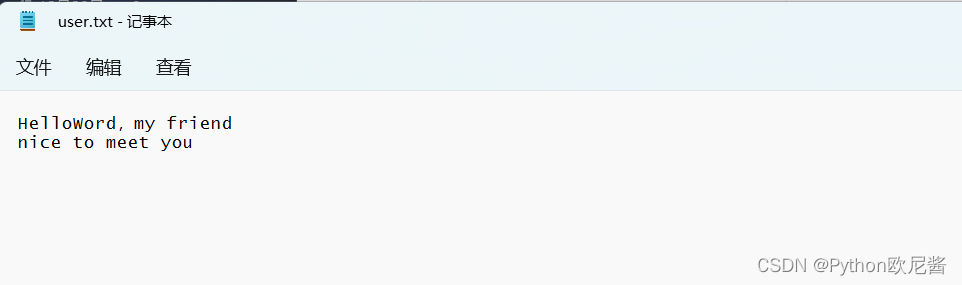
f=open(r"./user.txt",'r',encoding='utf8')
read=f.readline() #读取第一行全部
print(read)
#输出结果:HelloWord,my friend
read1=f.readline() #此时文件读取指针到了第二行,所以就从第二行开始
print(read1)
#输出结果:nice to meet you
(3)读取多行(readlines)
f.readlines(num)
说明:这个是吧文本内容全部按行读取,每行为一个字符串,结果返回这些字符串组成的列表,num用法同上。
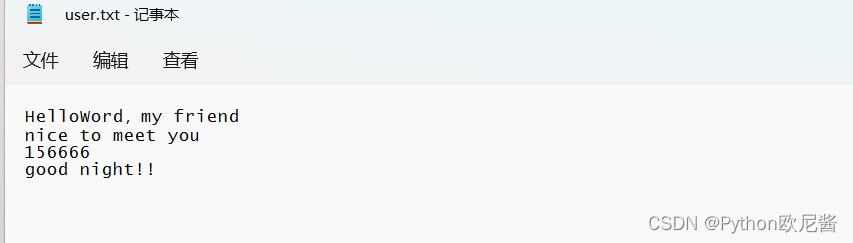
f=open(r"./user.txt",'r',encoding='utf8')
r=f.readlines(2) #读取全部数据,然后返回一个列表,其中的换行符\n也会读取进去
print(r) #输出这个列表
for i in r: #用循环依次输出
print(i,end='')
f.close()
#输出结果:
# ['HelloWord,my friend\n', 'nice to meet you\n', '156666\n', 'good night!!']
# HelloWord,my friend
# nice to meet you
# 156666
# good night!!
3.文件的写入(文件变量名f)(write)
w
f.write(内容)
注意:写入了之后就必须关闭文件!!!
f=open(r"./user.txt",'w',encoding='utf8')
f.write('''my love\n
kun\n
wawd
''')
f.close()
查看写入的文件:

4.判断文件的可读性、可写性、是否关闭完全(文件变量名f)
(1)判断文件的可读性(readable)
f.readable()
说明:这个函数的返回值是一个布尔变量,如果文件具备可读性就返回True,反之返回False
f=open(r"./user.txt",'w',encoding='utf8')
print(f.readable())
f.close()
#输出结果:False
f=open(r"./user.txt",'r',encoding='utf8')
print(f.readable())
f.close()
#输出结果:True
(2)判断文件的可写性(writeable)
f.readable()
说明:这个函数的返回值是一个布尔变量,如果文件具备可写性就返回True,反之返回False
f=open(r"./user.txt",'w',encoding='utf8')
print(f.writable())
f.close()
#输出结果:True
f=open(r"./user.txt",'r',encoding='utf8')
print(f.writable())
f.close()
#输出结果:False
(3) 判断文件是否关闭完全(closed)
f.closed
说明:这个函数的返回值是一个布尔变量,如果文件完全关闭就返回True,反之返回False
f=open(r"./user.txt",'w',encoding='utf8')
w=f.write('hello')
f.close()
print(f.closed)
#输出结果:True
5.文件的定位(文件变量名为f)
(1)自定义读写位置(seek)
f.seek(size,position)
说明:参数size是表示文件指针移动的字节数(正数表示右移,负数表示左移),position 是表示开始定位的初始位置,0表示从头开始,1表示从此时的位置开始,2表示从末尾开始,如果没有去设置的话,系统会默认从此时的位置开始。
补充说明:在utf8编码中,中文的字节数是3,而在GBK编码中,中文是占2个字节。英文不管在什么编码下都是占1个字节(所以要注意看编码格式,如果用utf8编码读取中文只读取/偏移3个字节就会报错的!)
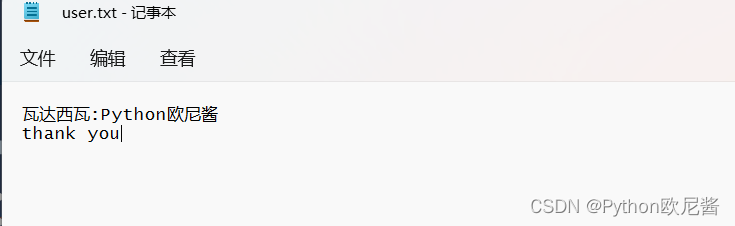
示例1:
f=open(r"./user.txt",'r',encoding='utf8')
f.seek(3,0)
print(f.read())
#输出结果:达西瓦:Python欧尼酱
# thank you
示例2:
f=open(r"./user.txt",'r',encoding='utf8')
f.seek(-9,2)
print(f.read())
#结果报错:io.UnsupportedOperation: can't do nonzero end-relative seeks
原因分析:在Python3中,seek文件指针初始位置是只能从开头开始,而不可以从末尾开始,而Python2是允许的。
解决方法:以二进制流去读取每一个字节码,所以把操作符由 r 改为 rb ,同时encoding去掉,改为 f=open(r"./user.txt",'rb')
效果:
f=open(r"./user.txt",'rb')
f.seek(-9,2)
print(f.read())
#输出结果:b'thank you'
(2)获取当前位置(tell)
f.tell()
说明:这个函数的返回值是当前文件指针的位置,返回的是从头开始到此时文件指针的位置所经历过的总字节数(偏移字节数)
文本内容:

f=open(r"./user.txt",'r+',encoding='utf8')
a=f.read()
print(a)
print(f.tell()) #测量文件指针偏移了多少个字节
#输出结果:39
6.with open 打开文件方法
格式:
with open(文件名/文件路径,操作文件,字符编码[encoding='utf-8']) as 别名:
内容
……
说明:这种写法是不需要关闭文件的,系统会默认关闭文件,写法是采样缩进原则
示例:
with open(r"./user.txt",'w',encoding='utf8') as f:
f.write('流浪地球2')
print(f.closed) #判断文件是否关闭
#输出结果:True
OK,这一期就到这里了,thanks~~~
分享一张壁纸
