半监督学习介绍
我们在丰收的季节来到瓜田,满地都是西瓜,瓜农抱来四个西瓜说这都是好瓜,然后指着地里面六个瓜说这些不好,还需要再生长几天,基于这些信息,我们能否构建一个模型,用于判别地里面哪些是该采摘的瓜?显然,可将瓜农告诉我们的好瓜,与不好的瓜分别作为正例和反例来训练一个分类器,然而只用这十个瓜做训练样本,有点太少了吧,能不能把地里的瓜也用上呢?
形式化地看,我们有训练样本集合
D
l
=
{
x
1
,
x
2
,
.
.
.
,
x
l
}
D_l=\{x_1,x_2,...,x_l\}
Dl={x1,x2,...,xl},这个样本集是带标记的(告诉了我们哪些是好瓜,哪些是坏瓜),称为有标记样本;此外还有无标记样本,
D
u
=
{
x
l
+
1
,
x
x
+
2
,
.
.
.
,
x
l
+
u
}
D_u=\{x_{l+1},x_{x+2},...,x_{l+u}\}
Du={xl+1,xx+2,...,xl+u},我们知道这类无标记的样本数量是远远大于有标记样本的数量的,也就是
u
>
>
l
u>>l
u>>l。
如果我们只利用
l
l
l个数据来做训练,那剩下的庞大的
u
u
u个样本就浪费了。我们怎么样才能把剩下的庞大的
u
u
u个样本利用起来呢?下面是两种思想。
- 把剩下的
u
u
u个样本打上标记,这样做的缺点就是耗费人力,相当于让瓜农把剩下的瓜全部检查一遍。
- 先把
l
l
l个数据训练起来,训练好了,我们把一个瓜判断优劣后,问问瓜农这瓜是不是符合我们的判断,然后把该样本加入到
l
+
1
l+1
l+1个数据中再训练。这样瓜农只需要检验少量的瓜,从而大幅度降低成本。这种方法叫做主动学习。
别慌,还有一种思路。上面两种思路都是需要通过“专家参与”,人为的判断样本好坏,那么有没有一种不用人为判断好坏的方法出现呢?
半监督学习:让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能
半监督学习,要利用未标记的
u
u
u个样本,同样参与到训练之中。所以,半监督学习有这么一个假设:相似的样本有相似的输出。
半监督学习又分为纯半监督学习和直推学习。前者假定训练数据中的未标记样本并非待预测的数据, 而后者则假定学习过程中所考虑的未标记样本恰是待预测数据。
下面只介绍两种半监督,其他算法原理以后有机会再学习。
半监督SVM
半监督支持向量机(S3VM)是支持向量机在半监督学习上的推广。它的思想很简单,如下图所示:

在不考虑未标记样本时,支持向量机试图找到最大间隔划分超平面, 而在考虑未标记样本后, S3VM 试图找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面。
回忆一下SVM的公式:https://blog.csdn.net/No_Game_No_Life_/article/details/89877123#_108
我们在SVM中得出过下面的公式:
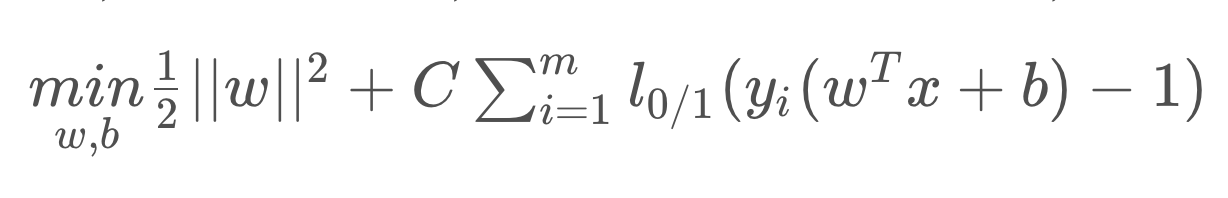
并且,我们曾经提到过,
l
0
/
1
l_{0/1}
l0/1函数不连续,我们有其变形。不过在本节,我们将其表示为:
m
i
n
w
,
b
,
ξ
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
m
ξ
\underset{w,b,\xi}{min}\frac{1}{2}||w||^2+C\sum_{i=1}^{m}\xi
w,b,ξmin21∣∣w∣∣2+C∑i=1mξ
其中,
ξ
\xi
ξ与
l
0
/
1
l_{0/1}
l0/1函数的作用相同。
同样的,在S3VM中,我们结合样本集
D
l
=
{
x
1
,
x
2
,
.
.
.
,
x
l
}
D_l=\{x_1,x_2,...,x_l\}
Dl={x1,x2,...,xl}和样本集
D
u
=
{
x
l
+
1
,
x
x
+
2
,
.
.
.
,
x
l
+
u
}
D_u=\{x_{l+1},x_{x+2},...,x_{l+u}\}
Du={xl+1,xx+2,...,xl+u},可知:
m
i
n
w
,
b
,
ξ
1
2
∣
∣
w
∣
∣
2
+
C
l
∑
i
=
1
l
ξ
l
+
C
u
∑
i
=
l
+
1
l
+
u
ξ
u
\underset{w,b,\xi}{min}\frac{1}{2}||w||^2+C_l\sum_{i=1}^{l}\xi_l+C_u\sum_{i=l+1}^{l+u}\xi_u
w,b,ξmin21∣∣w∣∣2+Cl∑i=1lξl+Cu∑i=l+1l+uξu
其中,
C
u
C_u
Cu的值比
C
l
C_l
Cl小,这样才能使得有标记的样本的作用更大。
输入很明显,直接来说过程。这里我们介绍TSVM的过程。
过程:
- 通过有标记样本
D
l
D_l
Dl计算出一个SVM模型。
- 通过SVM模型给
D
u
D_u
Du打标记(伪标记)。
- 通过有标记的两个样本
D
l
D_l
Dl和
D
u
D_u
Du,训练出新的TSVM,找到新的
(
w
,
b
)
(w,b)
(w,b)(新的超平面)。
- 通过训练出的TSVM,在
D
u
D_u
Du中找出两个标记指派为异类且很可能发生错误的未标记样本?交换它们的标记。
- 重复步骤3,4。并逐步增大
C
u
C_u
Cu以提高未标记样本的影响,直到
C
u
=
C
l
C_u=C_l
Cu=Cl为止。
S3VM介绍完毕,可以看到,一开始,我们就利用了未标记的样本,并且不断修正对未标记样本的伪标记。
其实这个过程很像EM算法的思想,关于EM算法,可以看下面的链接 https://zhuanlan.zhihu.com/p/36331115
基于分歧的方法
基于分歧的方法大多数使用“学习器”,并利用“学习器”之间的“分歧”来对未标记数据进行利用。
我们这里介绍其中一种算法:协同训练。在介绍协同训练之前,首先要了解什么是多视图数据。
一个数据对象往往同时拥有多个"属性集" (attributeset) ,每个属性集就构成了一个"视图"(view)。举个例子,对一部电影来说,它拥有多个属性集:图像画面信息所对应的属性集、声音信息所对应的属性集(还有字幕,网上讨论等等属性集)。.于是,一个电影片段可表示为样本
(
<
x
1
,
x
2
>
,
y
)
(<x_1,x_2>,y)
(<x1,x2>,y),
x
1
x_1
x1表示图像画面信息对应的属性集,
x
2
x_2
x2表示声音信息所对应的属性集,
y
y
y则是标记,比如电影属于“爱情片”“动作片”等等(我怀疑你在开车,可是我没有证据)。
假设不同视图具有"相容性",举个例子,用
y
1
y^1
y1表示从图像画面信息判别的标记空间,用
y
2
y^2
y2表示从声音信息判别的标记空间。以电影为例,某个片段上有两人对视(
y
1
=
爱
情
片
y^1=爱情片
y1=爱情片),仅凭图像画面信息难以分辨其类型,但此时若从声音信息昕到"我爱你"(
y
2
=
爱
情
片
y^2=爱情片
y2=爱情片)则可判断出该片段很可能属于"爱情片"(
y
=
爱
情
片
y=爱情片
y=爱情片)。当两者一起考虑时就有很大的把握判别正确,在"相容性"基础上,不同视图信息的"互补性"会给学习器的构建带来很多便利。
协同训练正是很好地利用了多视图的"相容互补性"。假设数据拥有两个充分(sufficient )且条件独立视图,“充分"是指每个视图都包含足以产生最优学习器的信息”,条件独立"则是指在给运类别标记条件下两个视图独立。
在此情形下,可用一个简单的办法来利用未标记数据:
首先在每个视图上基于有标记样本分别训练出一个分类器,然后让每个分类器分别去挑选自己"最有把握的"未标记样本赋予伪标记,并将伪标记样本提供给另一个分类器作为新增的有标记样本用于训练更新。
这个"互相学习、共同进步"的过程不断迭代进行,直到两个分类器都不再发生变化,或达到预先设定的迭代轮数为止。
为了使用此类方法,市能生成具有显著分歧、性能尚可的多个学习器,但当有标记样本很少,尤其是数据不具有多视图时,要做到这一点并不容易,需有巧妙的设计。