
/*
常见的排序算法有:直接插入 希尔 冒泡 快速 选择 堆排序 归并 基数
*/
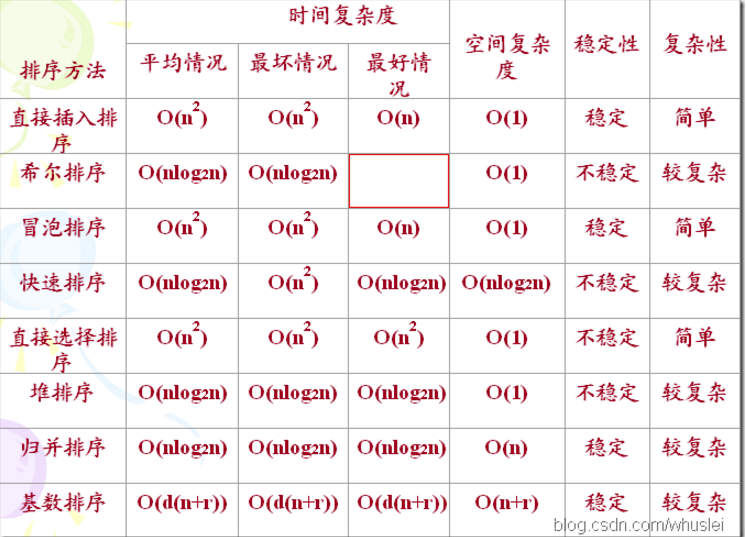
//下面一一分析,并实现:
/*
1.冒泡排序
冒泡排序是最简单的排序算法,冒泡排序的基本思想是从后往前(或从前往后)两两比较相邻元素的值,若为逆序,则交换它们,直到序列比较完毕。我
们称它为一趟冒泡。每一趟冒泡都会将一个元素放置到最终的位置上。
*/
//从前往后遍历,保证排好序的放到右侧
void BubbleSort_from_0(vector<int>& nums){
int n = nums.size();
//一共进行n-1趟
for (int i = 0; i < n - 1; i++){
//注意j的起点和终点
for (int j = 1; j < n - i; j++){
if (nums[j] < nums[j - 1]){
swap(nums[j], nums[j - 1]);
}
}
}
}
//从后往前遍历,保证排好序的放到左侧
void BubbleSort_from_n(vector<int>& nums){
int n = nums.size();
//一共进行n-1趟
for (int i = 0; i < n - 1; i++){
//注意j的起点和终点
for (int j = n-1; j >i; j--){
if (nums[j] < nums[j-1]){
swap(nums[j], nums[j - 1]);
}
}
}
}
/*
2.快速排序
快速排序是对冒泡排序的一种改进。其基本思想是基于分治法:在待排序表L[n]中任取一个元素
pivot作为基准,通过一趟排序将序列划分为两部分L[1…K-1] 和L[K+1…n],使得L[1…
K-1]中的所有元素都小于pivot,而L[k+1…n]中的所有元素都大于或等于pivot。则pivot放
在了其最终的位置L(k)上。然后,分别递归对两个子序列重复上述过程,直至每部分内只有一个元
素或空为止,即所有元素放在了其最终的位置上。

需要注意的是:关于遍历可以从两头开始,也可以只从一侧开始,下边都会给出实现
*/
int Partion_from_LR(vector<int>&nums, int left, int right){
//取左元素作为哨兵
int key = nums[left];
while (left < right){
//一开始认为左侧位置是空的,所以从右侧找一个数来填充它
while (left < right && nums[right] >= key)--right;
nums[left] = nums[right];
//轮到从左侧找一个合适的数来填充右侧right的空缺
while (left < right&& nums[left] < key)++left;
nums[right] = nums[left];
}
//最后把中间的空缺位置放上key
nums[left] = key;
//返回最终位置
return left;
}
int Partion_from_L(vector<int>&nums, int left, int right){
//从一侧开始的一般取另一侧的端点为key.因此取右侧端点为key
int key = nums[right];
//设置两个指针 i ,left
int i = left - 1;
while (left <=right){
//保证i~left(不包含i)之间的数都比key大,0~i(含i)的数比key小
if (nums[left] <= key){
++i;
swap(nums[left], nums[i]);
}
++left;
}
return i;
}
void QuickSort(vector<int> &nums, int left, int right){
//递归法
if (left < right){
//int pos = Partion_from_L(nums, left, right);
int pos = Partion_from_LR(nums, left, right);
QuickSort(nums, left, pos - 1);
QuickSort(nums, pos + 1, right);
}
}
/*
3.简单选择排序
对要排序的序列,选出关键字最小的数据,将它和第一个位置的数据交换,接着,选出关键字次小的
数据,将它与第二个位置上的数据交换。以此类推,直到完成整个过程
所以如果有n个数据,那么则需要遍历n-1遍。
实现代码如下:
*/
//选择排序
void SelectSort(vector<int> &nums){
int n = nums.size();
//只需n-1个位置需要考察,因为最后一个自然而然就放上了
for (int i = 0; i < n - 1; i++){
//每一趟我都是要去找最小的那个的序号
int minx = nums[i];
int cur = i;
for (int j = i+1; j < n; j++){
if (minx > nums[j]){
cur = j;
}
}
//交换
swap(nums[cur], nums[i]);
}
}
/*
4.直接插入排序
为了实现N个数的排序,将后面N-1个数依次插入到前面已经排好的子序列中,假定刚开始第一个
数是一个已拍好序的子序列,那么经过N-1趟就能得到一个有序的序列。
代码实现如下:
*/
//插入排序
void InsertSort(vector<int>& nums){
//少于两个元素的数组不用排序
if (nums.size() < 2)return;
//排序从第二个元素进行考察
int n = nums.size();
for (int i = 1; i < n; i++){
int key = nums[i];
int j;
for ( j = i - 1; j >= 0&& key<nums[j]; j--){
nums[j + 1] = nums[j];
}
nums[j + 1] = key;
}
}
/*
5.希尔排序(ShellSort )是插入排序的一种,是对直接插入排序算法的 改进该方法又称为缩小增量
排序。比较相距一定间隔的元素,即形如L[i,i+d,i+2d,…,i+kd]的序列然后缩小间距,再对各分组序列进行排序。直到之比较相邻元素的最后一趟排序为止,即最后的间距为1。
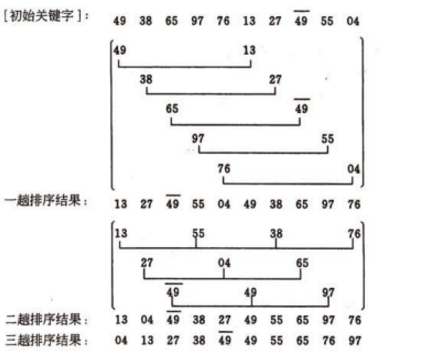
代码如下:
*/
//希尔排序
void ShellSort(vector<int> & nums){
int n = nums.size();
int i, j, tmp;
int d = n / 2;
while (d >= 1){
//对每组进行直接插入排序
for (int i = d; i < n; ++i){
tmp = nums[i];
for (j = i - d; j >= 0 && tmp < nums[j]; j -= d){
nums[j + d] = nums[j];
}
nums[j + d] = tmp;
}
d /= 2;
}
}
/*
6.合并排序
合并排序采用分治算法,思路是将两个或以上的有序表合并为一个有序表,把
待排序的序列分割成若干个子序列,每个子序列有序,然后再把子序列合并为
一个有序序列。若将两个有序表合并成一个有序表,则成为2路合并排序。
2-路归并即使将2个有序表组合成一个新的有序表。假定待排序表有n个元素,
则可以看成是n个有序的字表,每个子表长度为1,然后两两归并…不停重复,
直到合并成一个长度为n的有序列表为止。Merge()函数是将前后相邻的两个有
序表归并为一个有序表,设A[low…mid]和A[mid+1…high]存放在同一顺序表
的相邻位置上,先将他们复制到辅助数组B中,每次从对应B中的两个段取出一
个元素进行比较,将较小者放入A中。
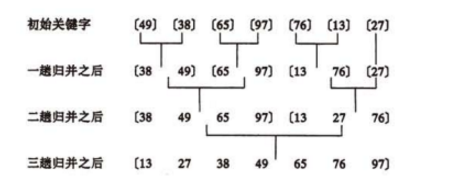
代码如下:
*/
//归并排序
//将两个有序的序列nums[low...mid] nums[mid...hight]合并
void mMerge(vector<int>&nums, int left, int mid, int right){
int k = right - left + 1;
vector<int> tmpArray(k);
int p = right, q = mid;
while (p > mid&& q >= left){
if (nums[p] > nums[q]){
tmpArray[--k] = nums[p--];
}
else{
tmpArray[--k] = nums[q--];
}
}
while (p > mid){
tmpArray[--k] = nums[p--];
}
while (q >= left){
tmpArray[--k] = nums[q--];
}
k = right - left + 1;
for (int i = 0; i < k; i++){
nums[left + i] = tmpArray[i];
}
}
//折半法,即分治思想
void mymergeSort(vector<int>& nums, int left, int right){
if (left < right){
int mid = left + (right - left) / 2;
mymergeSort(nums, left, mid);
mymergeSort(nums, mid + 1, right);
mMerge(nums, left, mid, right);
}
}
void MergeSort(vector<int>& nums){
int n = nums.size();
mymergeSort(nums, 0, n - 1);
}
/*
7.堆排序
堆排序是一种属性选择排序方法,在排序过程中,将L[n]看成是一颗完全二叉树的顺序存储结构,利用完全
二叉中双亲节点和孩子节点之间的内在关系,在当前无序区中选择关键字最大(或最小)的元素。堆排序
的思路是:首先将序列L[n]的n个元素建成初始堆,由于堆本身的特点(以大根堆为例),堆顶元素就是最大
值。输出堆顶元素后,通常将堆底元素送入堆顶,此时根节点已不满足大根堆的性质,堆被破坏,将堆顶元
素向下调整使其继续保持大根堆的性质,再输出堆顶元素。如此重复,直到堆中仅剩下一个元素为止。
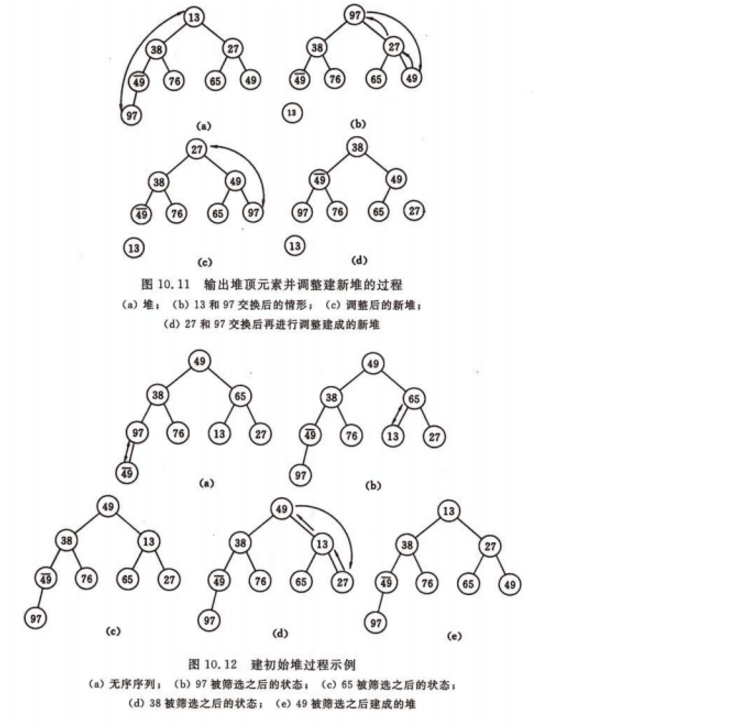
//代码如下:
*/
//堆排序
//使用数组二叉树,数组实现的堆中,第N个节点的左孩子的索引值是
void HeapAdjust(vector<int>&nums, int root, int size){
//左孩子
int leftChild = 2 * root + 1;
//若有左孩子
if (leftChild <= size - 1){
//右孩子
int rightChild = leftChild + 1;
//若有右孩子
if (rightChild <= size - 1){
if (nums[leftChild] < nums[rightChild]){
leftChild = rightChild;
}
}
if (nums[root] < nums[leftChild]){
swap(nums[root], nums[leftChild]);
HeapAdjust(nums, leftChild, size);
}
}
}
void HeapSort(vector<int>& nums){
int size = nums.size();
for (int i = size / 2 - 1; i >= 0; --i){
HeapAdjust(nums, i, size);
}
for (int i = size - 1; i>0; --i){
swap(nums[0], nums[i]);
HeapAdjust(nums, 0, i);
}
}
/*
8.基数排序
它是一种非比较排序。它是根据位的高低进行排序,也就是先按照个位排序然后按照十位
排序……依次类推。示例如下:
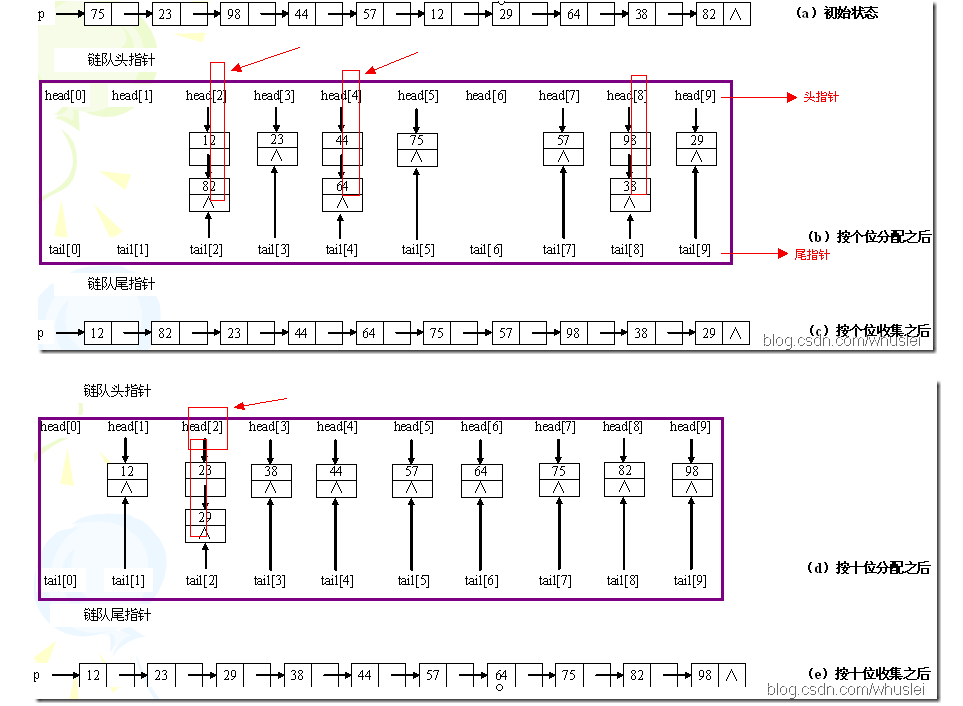
代码如下:
*/
/*基数排序*/
void RadixSort(vector<int> &array)
{
int size = array.size();
int bucket[10][10] = { 0 };//定义基数桶
int order[10] = { 0 };//保存每个基数桶之中的元素个数
int key_size = KeySize(array);//计算关键字位数的最大值
for (int n = 1; key_size>0; n *= 10, key_size--)
{
/*将待排序的元素按照关键值的大小依次放入基数桶之中*/
for (int i = 0; i<size; i++)
{
int lsd = (array[i] / n) % 10;
bucket[lsd][order[lsd]] = array[i];
order[lsd]++;
}
/*将基数桶中的元素重新串接起来*/
int k = 0,i;
for (i = 0; i<10; i++)
{
if (order[i] != 0)
{
for (int j = 0; j<order[i]; j++)
{
array[k] = bucket[i][j];
k++;
}
order[i] = 0;
}
}
}
}
int main(){
vector<int> nums{25,54,34,922,134,778};
RadixSort(nums);
for (auto a : nums){
cout << a << " ";
}
cout << endl;
return 0;
}