本文是LLM系列的文章,针对《A Survey on Time-Series Pre-Trained Models》的翻译。
摘要
时间序列挖掘在实际应用中显示出巨大的潜力,是一个重要的研究领域。基于大量标记数据的深度学习模型已成功用于TSM。然而,由于数据注释成本的原因,构建大规模标记良好的数据集是困难的。近年来,预训练模型由于其在计算机视觉和自然语言处理方面的卓越表现,逐渐引起了时间序列领域的关注。在这项综述中,我们对时间序列预训练模型(TS-PTM)进行了全面的回顾,旨在指导对TS-PTM的理解、应用和研究。具体来说,我们首先简要介绍TSM中使用的典型深度学习模型。然后,我们根据预训练技术对TS-PTM进行了概述。我们探索的主要类别包括有监督的、无监督的和自我监督的TS-PTM。此外,还进行了大量的实验来分析迁移学习策略、基于Transformer的模型和具有代表性的TS-PTM的优缺点。最后,我们指出了TS-PTM未来工作的一些潜在方向。源代码位于https://github.com/qianlima-lab/time-series-ptms.
1 引言
作为数据挖掘领域的一个重要研究方向,时间序列挖掘(TSM)已被广泛应用于现实世界中的应用,如金融、语音分析、动作识别和交通流预测。TSM的基本问题是如何表示时间序列数据。然后,可以基于给定的表示来执行各种挖掘任务。由于严重依赖领域或专家知识,传统的时间序列表示(例如,shapelets)非常耗时。因此,自动学习适当的时间序列表示仍然具有挑战性。
近年来,深度学习模型在各种TSM任务中取得了巨大成功。与传统的机器学习方法不同,深度学习模型不需要耗时的特征工程。相反,他们通过数据驱动的方法自动学习时间序列表示。然而,深度学习模型的成功依赖于大量标记数据的可用性。在许多真实世界的情况下,由于数据获取和注释成本的原因,很难构建一个标记良好的大型数据集。
为了减轻深度学习模型对大型数据集的依赖,通常使用基于数据增强和半监督学习的方法。数据增强可以有效地提高训练数据的大小和质量,并已被用作许多计算机视觉任务的重要组成部分。然而,与图像数据增强不同的是,时间序列数据增强还需要考虑时间序列中的时间依赖性和多尺度依赖性等属性。此外,时间序列数据增强技术的设计通常依赖于专家知识。另一方面,半监督方法使用大量未标记的数据来提高模型性能。然而,在许多情况下,即使是未标记的时间序列样本也很难收集(例如,医疗保健中的心电图时间序列数据)。
缓解训练数据不足问题的另一个有效解决方案是迁移学习,它放宽了训练和测试数据必须独立且相同分布的假设。迁移学习通常有两个阶段:预训练和微调。在预训练期间,模型在一些包含大量数据的源域上进行预训练,这些源域是独立的,但与目标域相关。在微调时,对来自目标域的通常有限的数据进行预训练模型(PTM)的微调。
最近,PTM,特别是基于Transformer的PTM,在各种计算机视觉(CV)和自然语言处理(NLP)应用中取得了显著的性能。受这些启发,最近的研究考虑了时间序列数据的时间序列预训练模型(TSPTM)的设计。首先,通过监督学习、无监督学习或自监督学习对时间序列模型进行预训练,以获得适当的表示。然后在目标域上对TS-PTM进行微调,以提高下游TSM任务(例如,时间序列分类和异常检测)的性能。
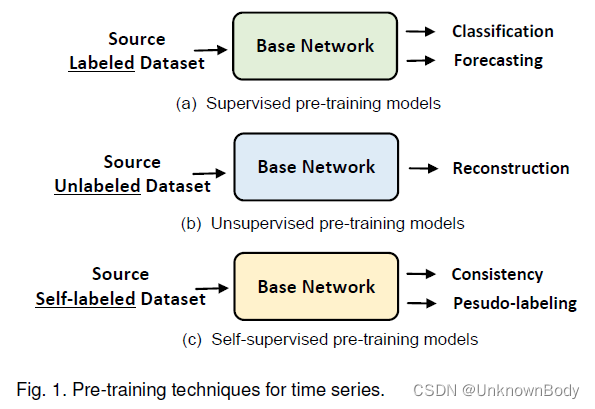
监督TS-PTM通常通过分类或预测任务进行预训练。然而,难以获得用于预训练的大量标记时间序列数据集往往限制了监督TSPTM的性能。此外,无监督的TS-PTM利用未标记的数据进行预训练,这进一步解决了标记数据不足的限制。例如,基于重建的TS-PTM使用自动编码器和重建损失来预训练时间序列模型。最近,基于对比学习的自监督PTM在CV中显示出了巨大的潜力。因此,一些学者已经开始探索基于一致性的任务设计和伪标记技术,以挖掘时间序列的固有属性。尽管如此,TS PTM的研究仍然是一个挑战。
在这项调查中,我们对TS-PTM进行了全面的回顾。具体来说,我们首先介绍了TSM中使用的各种TSM任务和深度学习模型。然后,我们基于预训练技术提出了TS PTM的分类法(图1)。其中包括有监督的预训练技术(导致基于分类和基于预测的PTM)、无监督的预训练技术(基于重建的PTMs)和自监督的预训技术(基于一致性和基于伪标记的PTMs)。请注意,一些TS-PTM可能使用多个任务(例如,[37]中的预测和重建或[38]中的一致性)进行预训练。为了简化综述,我们根据TS-PTM的核心预训练任务对其进行了分类。
在时间序列分类、预测和异常检测方面进行了广泛的实验,以研究各种迁移学习策略和具有代表性的TS-PTM的优缺点。此外,还讨论了TSPTM的未来发展方向。这项综述旨在让读者全面了解TS-PTM,从早期的迁移学习方法到最近的基于转换和一致性的TS-PTM。主要贡献可概括如下:
- 我们根据所使用的预训练技术,对现有的TS-PTM进行了分类和全面审查。
- 我们进行了大量的实验来分析TS-PTM的优缺点。对于时间序列分类,我们发现基于迁移学习的TS-PTM在UCR时间序列数据集(包含许多小数据集)上表现不佳,但在其他公开可用的大时间序列数据集中表现优异。对于时间序列预测和异常检测,我们发现设计一种合适的基于Transformer的预训练技术应该是未来TS-PTM研究的重点。
- 我们分析了现有TS-PTM的局限性,并在(i)数据集、(ii)Transformer、(iii)固有特性、(iv)对抗性攻击和(v)噪声标签下提出了潜在的未来方向。
本文的其余部分组织如下。第2节提供了TS-PTM的背景。第3节对TS-PTM进行了全面审查。第4节介绍了各种TS-PTM的实验。第5节提出了一些未来的方向。最后,我们在第6节中总结了我们的发现。
2 背景
2.1 时间序列挖掘任务
2.1.1 时间序列分类
2.1.2 时间序列预测
2.1.3 时间序列聚类
2.1.4 时间序列异常检测
2.1.5 时间序列推测
2.2 深度学习模型用于时间序列
2.2.1 循环神经网络
2.2.2 卷积神经网络
2.2.3 Transformer
2.3 为什么预训练模型
3 TS-PTMs概览
3.1 监督PTMs
3.1.1 基于分类的PTMs
3.1.2 基于预测的PTMs
3.2 非监督的PTMs
3.2.1 基于重建的PTMs
3.3 自监督的PTMs
3.3.1 基于一致性的PTMs
3.3.2 伪标记PTMs
4 实验结果和分析
4.1 PTMs在时间序列分类上的性能
4.1.1 基于监督分类和无监督重构的迁移学习PTM的比较
4.1.2 基于Transformer和一致性的PTMs比较
4.1.3 可视化
4.2 PTMs在时间序列预测上的性能
4.3 PTMs在时间序列异常检测上的性能
5 未来方向
5.1 大规模时间序列数据集
5.2 时间序列的固有性质
5.3 时间序列中的Transformer
5.4 对时间序列的对抗性攻击
5.5 时间序列噪声标签的预训练模型
6 结论
在这项综述中,我们对TS-PTM的发展进行了系统的回顾和分析。在早期关于TS PTM的研究中,相关研究主要基于CNN和RNN模型对PTM进行迁移学习。近年来,基于Transformer和基于一致性的模型在时间序列下游任务中取得了显著的性能,并被用于时间序列预训练。因此,我们针对时间序列分类、预测和异常检测这三个主要任务,对现有的TS-PTM、迁移学习策略、基于Transformer的时间序列方法以及相关的代表性方法进行了大规模的实验分析。实验结果表明,基于Transformer的PTM在时间序列预测和异常检测任务中具有巨大的潜力,而为时间序列分类任务设计合适的基于Transformer的模型仍然具有挑战性。同时,基于对比学习的预训练策略是未来TS-PTM发展的潜在焦点。