1.数据集选取
1.1数据集简介
本次训练选取PASCAL-VOC2012数据集,更详细的信息请访问
官网:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
Kaggle:https://www.kaggle.com/huanghanchina/pascal-voc-2012
VOC2012用于语义分割的数据集分为20类对象+1类背景,原始的数据集包含了除分割外的分类+检测+共一万多张图片,但本次任务我们只需要语义分割的那一部分数据。
1.2 数据预处理
本次任务的标签位于VOC2012\SegmentationClass路径下,和图像识别任务不同的是,图像识别中一张图像就对应一个Label,而语义分割任务需要对一张图像实现像素级别的分类,因此分割任务是一个像素对应一个Lable,并且一张图像上还不止一个label,这样一来我们对于标签的标注方式就不能简单的像图像识别一样,可以仅通过文件的命名以体现不同图像所属的类别,而需要对图像中的每一个类别进行手动的标注,类别内的每一个像素均属于该类别。
好在VOC2012数据集为我们提供了标注好的标签,我们需要做的只是对标签进行一些细节上的处理。
1.2.1踩坑记录1
我们可以先试着读取一张标签,看看标签的存储方式:
'''for test'''
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('VOC2012/SegmentationClass/2007_000032.png')
print(np.array(img).shape)
plt.imshow(img)
plt.show()
[Out]: (281, 500)
可以看到输出尺寸是一个二维矩阵,说明标签的存储方式为”单通道“,但是通过imshow我们又可以发现,图片其实具有四个通道(右下角),好像又是RGBA的形式:
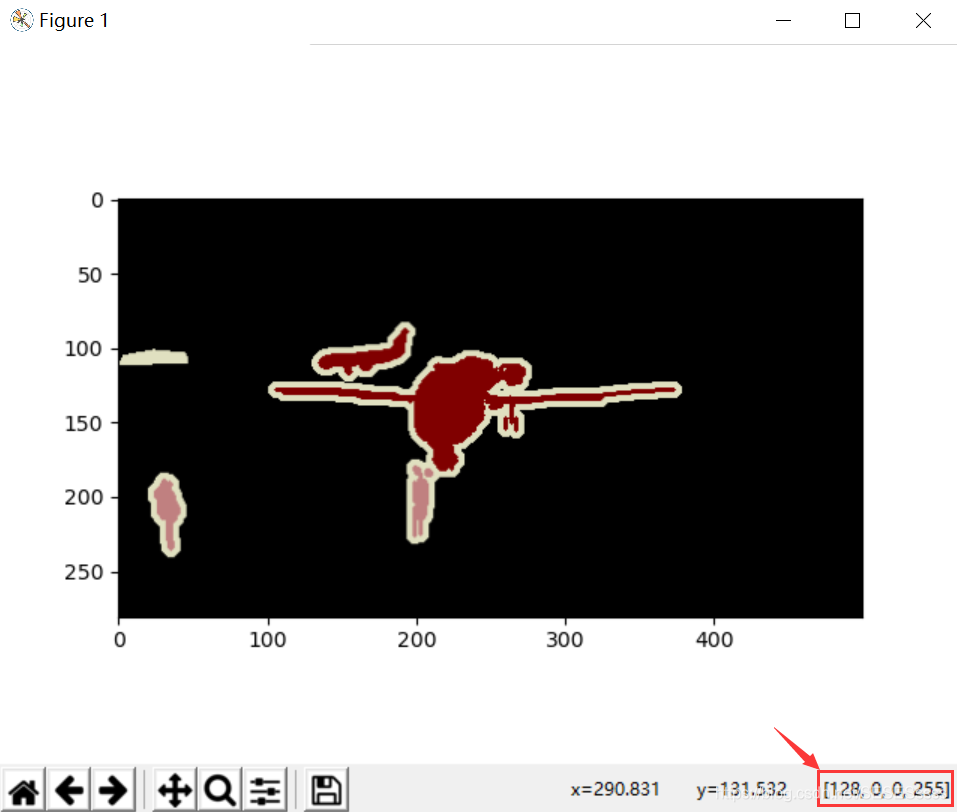
这着实让我一时半会摸不着头脑,于是我就按照RGBA->RGB的形式对图像进行处理:
#将图像转换为RGB形式(4通道->3通道)
img = Image.open('VOC2012/SegmentationClass/2007_000032.png').convert('RGB')
并自定义了将RGB图像转为灰度标签的函数(最后根本用不着):
#标注数据中每种颜色对应的类别:
colormap = [
[0,0,0],
[128,0,0],
[0,128,0],
[128,128,0],
[0,0,128],
[128,0,128],
[0,128,128],
[128,128,128],
[64,0,0],
[192,0,0],
[64,128,0],
[192,128,0],
[64,0,128],
[192,0,128],
[64,128,128],
[192,128,128],
[0,64,0],
[128,64,0],
[0,192,0],
[128,192,0],
[0,64,128],
]
#将颜色转换为类别:
def image2label(image, colormap):
image = np.array(image, dtype = 'int64') # image.shape = (320, 480, 3)
cm2lbl = np.zeros(3000)
for label, color in enumerate(colormap):
# 创建哈希表存储原图颜色序列
cm2lbl[(color[0]+color[1]*8+color[2]*2)] = label
#print(color[0]*256+color[1]*256+color[2])
#print(cm2lbl)
#print(np.sum(cm2lbl != np.zeros(3000)))
# rgb三通道合并(简单粗暴的三通道相加)
ix = (image[:,:,0]+image[:,:,1]*8+image[:,:,2]*2) # ix.shape = (320, 480)
#从哈希表中,将颜色序列转换为对应的标签
image2 = cm2lbl[ix]
return image2 # image2.shape = (320, 480)
但是最后又想了想感觉哪里不对,二维的尺寸就应该是标签的形式,于是乎就想着输出标签的一行看看:
img = Image.open('VOC2012/SegmentationClass/2007_000032.png')
print(np.array(img)[100])
发现矩阵里的元素的确是标签形式(背景0,边缘255, 其余1~20)。。。
最后通过查阅资料才发现,VOC2012语义分割的标签存储模式是P-Mode,而不是我们熟知的RGB(可以print看看):
print(img)
[Out] : <PIL.PngImagePlugin.PngImageFile image mode=P size=500x281 at 0x217DB9D7AC8>
而plt在imshow这类格式的图像又会自动处理成RGBA格式。因此imshow的时候就有三个通道。
谜题终于揭晓,关于P Mode格式不是重点,我们只需要把它看成单通道标签处理就行,因此上述的image2label函数根本用不着(先留着说不定哪天又会用到)。
1.2.2 读取图片路径
由于VOC2012数据集并不都用于语义分割,因此一万多张图片里有一些数据是我们需要舍弃的。在数据集里的\ImageSets\Segmentation里的txt文档描述了哪些数据可以用作语义分割:
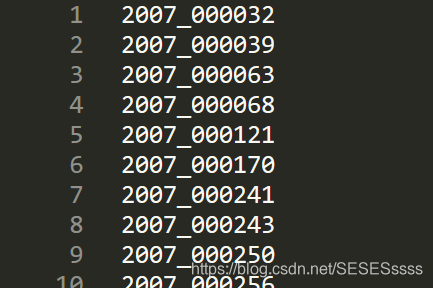
在这里我们定义一个函数用于筛选出这些数据作为我们的训练集与验证集:
# 读取图片路径 路径
def read_image_path(root):
# 读取文档
image = np.loadtxt(root, dtype = str)
n = len(image) # 数据集尺寸
data, label = [None]*n, [None]*n
for i, fname in enumerate(image):
data[i] = 'VOC2012/JPEGImages/%s.jpg' %(fname) # 数据集
label[i] = 'VOC2012/SegmentationClass/%s.png'%(fname) # 标签
return data, label
1.2.3 自定义图像增强与预处理模块
再次强调一遍,由于语义分割是像素级别的分类,因此标签和原图必须完美的匹配,这时候如果使用transforms模块自带的数据增强方法,因为是随机方法,因此处理后就会导致图像和标签在像素上不匹配的情况,因此我们自定义图像增强方法:
# 增强 # 由于是全卷积网络,图像的大小固不固定无所谓
def rand_crop(data, label, high, width): # high, width为裁剪后图像的固定宽高(320x480)
im_width, im_high = data.size
#生成随机点位置
left = np.random.randint(0, im_width - width)
top = np.random.randint(0, im_high - high)
right = left+width
bottom = top+high
#图像随机裁剪(图像和标签一一对应)
data = data.crop((left,top, right, bottom))
label = label.crop((left,top, right, bottom))
#图像随机翻转(图像和标签一一对应)
angle = np.random.randint(-15,15)
data = data.rotate(angle) # 逆时针旋转
label = label.rotate(angle) # 逆时针旋转
return data, label
# 预处理
def img_transforms(data, label, high, width):
data, label = rand_crop(data, label, high, width)
data_tfs = transforms.Compose([
transforms.ToTensor(),
#标准化,据说这6个参数是在ImageNet上百万张数据里提炼出来的,效果最好
transforms.Normalize(mean = [0.485, 0.456, 0.406],std = [0.229, 0.224, 0.225]),
])
data = data_tfs(data)
label = torch.from_numpy(np.array(label))
return data, label
1.3自定义数据集类
如何在PyTorch中自定义数据集类在我的上一篇博客已经做了详细的介绍,方法大同小异:传送地址
在这里我直接贴上代码,值得注意的是,为了防止rand_crop函数越界报错,本次我们添加了一个过滤方法用来过滤掉图像尺寸小于指定size的图像:
#自定义数据集:
class MyDataset(Data.Dataset):
def __init__(self, data_root, high, width):
self.data_root = data_root
self.high = high
self.width = width
self.imtransform = img_transforms
data_list, label_list = read_image_path(root = data_root)
self.data_list = self.filter(data_list)
self.label_list = self.filter(label_list)
def __getitem__(self, idx):
img = self.data_list[idx]
label = self.label_list[idx]
img = Image.open(img)
label = Image.open(label)#.convert('RGB')
img, label = self.imtransform(img, label, self.high, self.width)
return img, label
def __len__(self):
return len(self.data_list)
# 过滤掉图像尺寸小于high,width 的图像
def filter(self, images):
return [im for im in images if (Image.open(im).size[1] > self.high and Image.open(im).size[0] > self.width)]
1.3.1数据标签可视化
最后我们可以试着输出一个batch_size的图片看看效果如何。
BATCHSIZE = 8
voc_train = MyDataset("VOC2012/ImageSets/Segmentation/train.txt",high, width)
train_loader = Data.DataLoader(voc_train, batch_size = BATCHSIZE, shuffle = True)
for step, (b_x, b_y) in enumerate(train_loader):
if(step > 0):
break
#可视化一个batch的图像,检查数据预处理是否正确:
b_x_numpy = b_x.data.numpy()
b_x_numpy = b_x_numpy.transpose(0,2,3,1)
b_y_numpy = b_y.data.numpy()
plt.figure(figsize = (16,3))
for ii in range(BATCHSIZE):
plt.subplot(2,BATCHSIZE,ii+1)
plt.imshow(inv_normalize_image(b_x_numpy[ii]))#(320, 480, 3)
plt.axis('off')
plt.subplot(2,BATCHSIZE,ii+9)
plt.imshow(label2image(b_y_numpy[ii]))
plt.axis('off')
plt.subplots_adjust(wspace = 0.1, hspace = 0.1)
plt.show()

可视化首先要将类别转化为RGB信息:
#将标签转化为图像
def label2image(prelabel):
h,w = prelabel.shape
prelabel = prelabel.reshape(h*w, -1)
image = np.zeros((h*w