点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者丨米阿罗@知乎(已授权)
来源丨https://zhuanlan.zhihu.com/p/486360176
编辑丨极市平台
首发于踢翻炼丹炉:https://www.zhihu.com/column/c_1320691511223136256
二次转载须经作者授权
导读
本文细致的对PyTorch 显存管理机制进行了剖析,包括:寻找合适的block的步骤、实现自动碎片整理详解等,希望本文能帮助大家更透彻的理解显存优化。
本文使用的 PyTorch 源码为 master 分支,commit id 为 a5b848aec10b15b1f903804308eed4140c5263cb(https://github.com/pytorch/pytorch/tree/a5b848aec10b15b1f903804308eed4140c5263cb)。
背景介绍
剖析 PyTorch 显存管理机制主要是为了减少显存碎片化带来的影响。一个简单示例为:
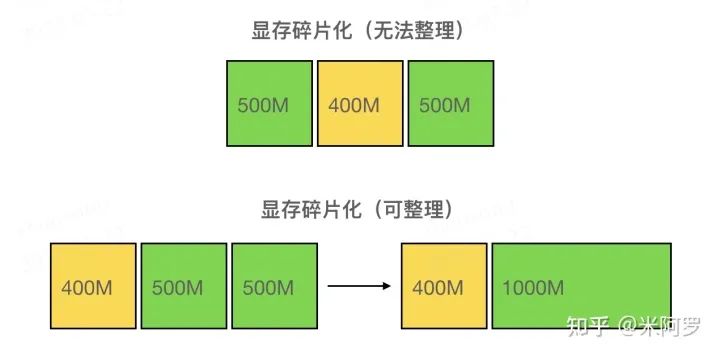
如上图所示,假设当前想分配 800MB 显存,虽然空闲的总显存有 1000MB,但是上方图的空闲显存由地址不连续的两个 500MB 的块组成,不够分配这 800MB 显存;而下方的图中,如果两个 500MB 的空闲块地址连续,就可以通过显存碎片的整理组成一个 1000MB 的整块,足够分配 800MB。上方图的这种情况就被称为显存碎片化。
解决方法: 当有多个 Tensor 可以被释放时,可以优先释放那些在内存空间上前后有空闲内存的 Tensor。这样便于 PyTorch 整理这些空闲块组成的碎片,让三个块组成一整个更大的块。
核心问题/前提: 能否以非常小的代价( O(1) 或 O(logn) 复杂度)拿到当前想要释放的块,以及它前后的空闲空间大小?有了这个,我们可以对 Tensor 排序,优先选择:“前后空闲块+自己大小” 最大的 Tensor 来释放。
这一前提可以转化为:找到下面两个函数(pseudo code):
block = get_block(tensor) # 找到存储该 Tensor 的 Block
size = get_adjacent_free_size(block) # 返回该 Block 前后的空余空间,便于排序
研究 PyTorch 显存管理机制后可能能回答的问题:
为什么报错信息里提示显存够,但还是遇到了 OOM?
显存的多级分配机制是怎样的?为什么要这样设计?
源码解读
主要看 c10/cuda/CUDACachingAllocator.cpp 里面的 DeviceCachingAllocator 类(L403)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L403
主要的数据结构
Block:
分配 / 管理内存块的基本单位,(stream_id, size, ptr) 三元组可以特异性定位一个 Block,即 Block 维护一个 ptr 指向大小为 size 的内存块,隶属于 stream_id 的 CUDA Stream。
所有地址连续的 Block(不论是否为空闲,只要是由 Allocator::malloc 得来的)都被组织在一个双向链表里,便于在释放某一个 Block 时快速检查前后是否存在相邻碎片,若存在可以直接将这三个 Block 合成为一个。
struct Block {
int device; // gpu
// Block 和被分配时调用者的 stream 是绑定的,即使释放了也无法给其他 stream 使用
cudaStream_t stream; // allocation stream
stream_set stream_uses; // streams on which the block was used
size_t size; // block size in bytes
BlockPool* pool; // owning memory pool
void* ptr; // memory address
bool allocated; // in-use flag
Block* prev; // prev block if split from a larger allocation
Block* next; // next block if split from a larger allocation
int event_count; // number of outstanding CUDA events
};
BlockPool:
struct BlockPool {
BlockPool(
Comparison comparator,
bool small,
PrivatePool* private_pool = nullptr)
: blocks(comparator), is_small(small), owner_PrivatePool(private_pool) {}
std::set<Block*, Comparison> blocks;
const bool is_small;
PrivatePool* owner_PrivatePool; // 供 CUDA Graphs 使用,此处不详讲
};
直观理解 Block、BlockPool 见下图:
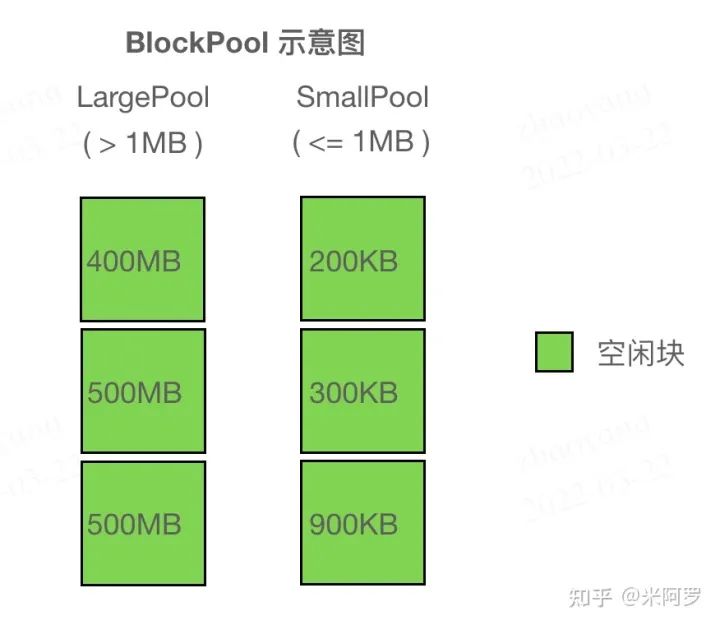
BlockPool 示意图,左边两个 500MB 的块 size 相同,因此上面的比下面的地址更小
总结: Block 在 Allocator 内有两种组织方式,一种是显式地组织在 BlockPool(红黑树)中,按照大小排列;另一种是具有连续地址的 Block 隐式地组织在一个双向链表里(通过结构体内的 prev, next 指针),可以以 O(1) 时间查找前后 Block 是否空闲,便于在释放当前 Block 时合并碎片。
malloc 函数解析:返回一个可用的 Block(L466)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L466
一个区分:(出于简洁考虑,下面全文都对这两个表述进行区分,不多赘述)
一个 hard-coded: 根据 size 决定实际上的 alloc_size(get_allocation_size 函数,L1078):https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1078
寻找是否有合适的 block 会有五个步骤,如果这五个步骤都没找到合适的 Block,就会报经典的 [CUDA out of memory. Tried to allocate ...] 错误(具体见下“分配失败的情况”)。
步骤一:get_free_block 函数(L1088)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1088
TLDR:尝试在 Allocator 自己维护的池子中找一个大小适中的空闲 Block 返回。
* TLDR = Too Long; Didn't Read
用当前的 (size, stream_id) 这二元组制作 Block Key 在对应的 BlockPool 中查找;
环境变量 PYTORCH_CUDA_ALLOC_CONF 中指定了一个阈值 max_split_size_mb,有两种情况不会在此步骤分配:
需要的 size 小于阈值但查找到的 Block 的比阈值大(避免浪费block);
两方都大于阈值但 block size 比需要的 size 大得超过了 buffer(此处是 20MB,这样最大的碎片不超过 buffer 大小)。
这里的这个阈值 max_split_size_mb 涉及一个有趣的特性,后面会讲到。
若成功分配一个 Block,则将这个 Block 从 BlockPool 中删除。后续用完释放(free)时会再 insert 进去,见free_block : L976:https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L976)
步骤二:trigger_free_memory_callbacks 函数(L1106)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1106
TLDR:手动进行一波垃圾回收,回收掉没人用的 Block,再执行步骤一。
若第一步的 get_free_block 失败,则在第二步中先调用 trigger_free_memory_callbacks,再调用一次第一步的 get_free_block;
trigger_free_memory_callbacks 本质上通过注册调用了 CudaIPCCollect 函数,进而调用 CudaIPCSentDataLimbo::collect 函数(torch/csrc/CudaIPCTypes.cpp : L64);https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/torch/csrc/CudaIPCTypes.cpp#L64
CudaIPCSentDataLimbo 类管理所有 reference 不为 0 的 Block,所以实际上 collect 函数的调用算是一种懒更新,直到无 Block 可分配的时候才调用来清理那些 reference 已经为 0 的 Block(值得一提的是,该类的析构函数会首先调用 collect 函数,见 torch/csrc/CudaIPCTypes.cpp : L58)https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/torch/csrc/CudaIPCTypes.cpp#L58;
相关源码可以看 torch/csrc/CudaIPCTypes.h & .cpp。
步骤三:alloc_block 函数(L1115)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1115
TLDR:Allocator 在已有的 Block 中找不出可分配的了,就调用 cudaMalloc 创建新的 Block。
步骤一、二中重用 block 失败,于是用 cudaMalloc 分配内存,大小为 alloc_size;
注意有一个参数 set_fraction 会限制可分配的显存为当前剩余的显存 * fraction(若需要分配的超过这一限制则失败),但还没搞清楚哪里会指定这个(TODO);
新分配的内存指针会被用于创建一个新 Block,新 Block 的 device 与 cuda_stream_id 与 caller 保持一致。
上面几个步骤都是试图找到一些空闲显存,下面是两个步骤是尝试进行碎片整理,凑出一个大块显存
步骤四:release_available_cached_blocks 函数(L1175)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1175
TLDR:先在自己的池子里释放一些比较大的 Block,再用 cudaMalloc 分配看看
如果上面的 alloc_block 失败了,就会尝试先调用这一函数,找到比 size 小的 Block 中最大的,由大至小依次释放 Block,直到释放的 Block 大小总和 >= size(需要注意,这一步骤只会释放那些大小大于阈值 max_split_size_mb 的 Block,可以理解为先释放一些比较大的);
释放 block 的函数见 release_block(L1241),主要就是 cudaFree 掉指针,再处理一些 CUDA graphs 的依赖,更新其他数据结构等等,最后把这个 Block 从 BlockPool 中移除;
当前整个 BlockPool(作为提醒,Allocator 有两个 BlockPool,这里指的是最初根据 size 指定的大 pool 或小 pool)中,可以释放的 Block 需要满足两个条件:cuda_stream_id 相同的,且大小要大于阈值 max_split_size_mb。如果将这样的 Block 全部释放的空间仍比 size 小,那么这一步就会失败。
释放掉了一批 Block 之后,再次执行步骤三中的 alloc_block 函数,创建新 Block。
步骤五:release_cached_blocks 函数(L1214)
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1214
malloc 分配失败的情况
https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L519-L560
会报经典的 CUDA out of memory. Tried to allocate ... 错误,例如:
CUDA out of memory. Tried to allocate 1.24 GiB (GPU 0; 15.78 GiB total capacity; 10.34 GiB already allocated; 435.50 MiB free; 14.21 GiB reserved in total by PyTorch)
Tried to allocate:指本次 malloc 时预计分配的 alloc_size;
total capacity:由 cudaMemGetInfo 返回的 device 显存总量;
already allocated:由统计数据记录,当前为止请求分配的 size 的总和;
free:由 cudaMemGetInfo 返回的 device 显存剩余量;
reserved:BlockPool 中所有 Block 的大小,与已经分配的 Block 大小的总和。
即 [reserved] = [already allocated] + [sum size of 2 BlockPools]
注意,reserved + free 并不等同于 total capacity,因为 reserved 只记录了通过 PyTorch 分配的显存,如果用户手动调用 cudaMalloc 或通过其他手段分配到了显存,是没法在这个报错信息中追踪到的(又因为一般 PyTorch 分配的显存占大部分,分配失败的报错信息一般也是由 PyTorch 反馈的)。
在这个例子里,device 只剩 435.5MB,不够 1.24GB,而 PyTorch 自己保留了 14.21GB(储存在 Block 里),其中分配了 10.3GB,剩 3.9GB。那为何不能从这 3.9GB 剩余当中分配 1.2GB 呢?原因肯定是碎片化了,而且是做了整理也不行的情况。
实现自动碎片整理的关键特性:split
前面提到,通过环境变量会指定一个阈值 max_split_size_mb,实际上从变量名可以看出,指定的是最大的可以被 “split” 的 Block 的大小。
在本节最开头解释过,步骤三 alloc_block 函数通过 cuda 新申请的 Block(这是 Allocator 唯一一个创建新 Block 的途径)大小是计算出的 alloc_size 而不是用户通过 malloc 请求的大小 size。因此,如果 malloc 在上述五个步骤中成功返回了一个 Block,Allocator 会通过函数 should_split (L1068) 检查:
被 split 的操作很简单,当前的 Block 会被拆分成两个 Block,第一个大小正好为请求分配的 size,第二个则大小为 remaining,被挂到当前 Block 的 next 指针上(这一过程见源码 L570~L584:https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L570-L584)。这样一来,这两个 Block 的地址自然而然成为连续的了。随着程序运行,较大的 Block(只要仍小于阈值 max_split_size_mb)会不断被分成小的 Block。值得注意的是,由于新 Block 的产生途径只有一条,即通过步骤三中的 alloc_block 函数经由 cudaMalloc 申请,无法保证新 Block 与其他 Block 地址连续,因此所有被维护在双向链表内的有连续地址空间的 Block 都是由一个最初申请来的 Block 拆分而来的。
一段连续空间内部(由双向链表组织的 Block 们)如下图所示:
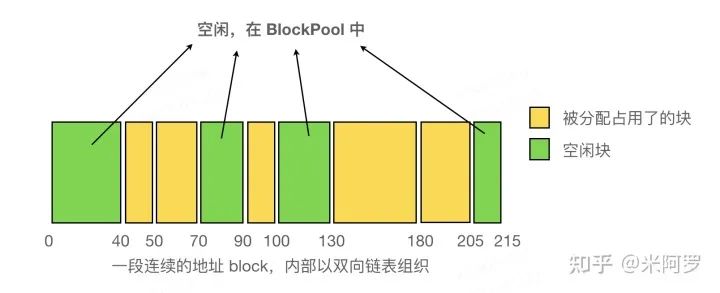 连续空间内部的双向链表(链表箭头已省略)
连续空间内部的双向链表(链表箭头已省略)
当 Block 被释放时,会检查其 prev、next 指针是否为空,及若非空是否正在被使用。若没有在被使用,则会使用 try_merge_blocks (L1000) 合并相邻的 Block。由于每次释放 Block 都会检查,因此不会出现两个相邻的空闲块,于是只须检查相邻的块是否空闲即可。这一检查过程见 free_block 函数(L952)。又因为只有在释放某个 Block 时才有可能使多个空闲块地址连续,所以只需要在释放 Block 时整理碎片即可。
try_merge_blocks (L1000):https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L1000
free_block 函数:https://github.com/pytorch/pytorch/blob/a5b848aec10b15b1f903804308eed4140c5263cb/c10/cuda/CUDACachingAllocator.cpp#L952
关于阈值 max_split_size_mb ,直觉来说应该是大于某个阈值的 Block 比较大,适合拆分成稍小的几个 Block,但这里却设置为小于这一阈值的 Block 才进行拆分。个人理解是,PyTorch 认为,从统计上来说大部分内存申请都是小于某个阈值的,这些大小的 Block 按照常规处理,进行拆分与碎片管理;但对大于阈值的 Block 而言,PyTorch 认为这些大的 Block 申请时开销大(时间,失败风险),可以留待分配给下次较大的请求,于是不适合拆分。默认情况下阈值变量 max_split_size_mb 为 INT_MAX,即全部 Block 都可以拆分。
总结
剖析 PyTorch 显存管理机制可以帮助我们更好地寻找显存优化的思路。目前我们正在联合 Dynamic Tensor Rematerialization (DTR)(https://arxiv.org/abs/2006.09616) 的作者@圆角骑士魔理沙 推进 PyTorch 上 DTR 技术的工业界落地,其中一项就是解决上述文章中提到的训练过程内存碎片化问题。近期会有一篇文章介绍 DTR 落地遇到的问题 & 解决方案 & benchmark,敬请期待。


点个在看 paper不断!