-
初始化,在十秒内页面加载完毕,调用selenium。
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 10)
-
定义一个登陆函数,我采用的是扫码登陆,需要你手动用手机扫码登陆,最开始用的账号密码登陆可把我给折磨的,账号密码登陆我的淘宝号会出现滑动登陆和跳转到验证页面发送验证码验证,整了半天滑动一出现我就重新运行,验证码我用Xpath找到元素位置点击发送验证码,手动后台输入,但我发现不行,后来次用扫码登陆,心累。有一点要注意,不要为了方便扫码最大化窗口,有时候会被反爬。设置合适的窗口大小,方便扫码。自己根据要扫码的时间设置时间。
def login_Infos(self):
self.browser.get(self.url)
# 改变窗口宽度,不要最大化,会被反爬虫检测到
self.browser.set_window_size(1300, 800)
# 点击二维码扫描
self.browser.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
# 等待扫描二维码,时间短了就改一改
time.sleep(12)
-
新建一个保存数据的csv函数,需要导入csv库
def file_Csv(self):
csv_file = open(r'手机.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(csv_file)
self.writer = writer
writer.writerow(['商品名称', '销售地', '店铺名称', '销售价格', '销售量', '商品链接'])
-
设置保存数据的函数,登录上后,一般会跳转到个人中心,然后跳到主页,用Xpath定位,如果跳到个人主页,就模拟点击跳到淘宝主页,如果已经在主页了就定位到搜索框,后台输入要搜索的商品名称,爬取页数,然后模拟点击搜索,注意淘宝只能到100页,所以页数最大值只能是100。
page = self.browser.page_source 保存页面,用BeautifulSoup解析,中间有个坑特坑

红色标记处解析不出来,检查了半天写的一点毛病都没有,就是获取不到,然后逐步检查,才发现红色标记处获取不到为NoneType,后来改用规则,获取其div下的div标签就能获取得到,很奇怪,心累。
然后就是数据处理了。
模拟下一页的时候还有一个坑,每次下一页的标签会变,但它始终是最后一个li标签位置,所以定位li标签要定位到最后一个li标签的位置,而不是直接浏览器复制Xpath路径。
def get_Data(self):
global data
# page = self.browser.page_source
#
# dk = page.encode(encoding='UTF-8').decode('unicode_escape')
# tt = dk.decode(encoding='UTF-8')
# print(dk)
if self.browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a'):
taobao_index = self.browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a')
taobao_index.click()
time.sleep(2)
search_input = self.browser.find_element_by_xpath('//*[@id="q"]')
goods_name = input("请输入要搜索的商品名称:")
search_input.send_keys(goods_name)
time.sleep(2)
search_submit = self.browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
search_submit.click()
count = int(input("请输入要爬的页数(最大为100):"))
# 淘宝最大页数为100页
for k in range(count):
page = self.browser.page_source
# print(page.encode('utf-8', 'ignore'))
print("页面正在解析<<<<<<<<<<<<<<<<<<<<<<<<<<<")
# with open(r'demo.html', 'w', newline='', encoding='utf-8-sig') as f:
# f.write(page.encode("gbk", 'ignore').decode("gbk", "ignore"))
soup = BeautifulSoup(page, "html.parser")
data_site = soup.find('div', class_='grid g-clearfix').find_all_next('div', class_='items')
for data_good in data_site:
dk0 = data_good.find_all('div', class_='row row-1 g-clearfix')
dk1 = data_good.find_all('div', class_='row row-2 title')
dk2 = data_good.find_all('div', class_='row row-3 g-clearfix')
for i in range(len(dk0)):
price_site = dk0[i].find('div', class_='price g_price g_price-highlight')
price_good = price_site.find('strong').text.strip()
counts_buy = dk0[i].find('div', class_='deal-cnt').text
counts_buy = counts_buy.replace('人付款', '')
# print(counts_buy)
if '+' in counts_buy:
counts_buy = counts_buy.replace('+', '')
if '万' in counts_buy:
counts_buy = float(counts_buy.replace('万', '')) * 10000
# print(counts_buy)
name_site = dk1[i].find('a')
url_good = name_site['href']
name_good = name_site.text.strip()
shop_name = dk2[i].find('div', class_='shop').text.strip()
shop_site = dk2[i].find('div', class_='location').text
# print(name_good, shop_site, shop_name, price_good, counts_buy, url_good)
data.append([str(name_good), str(shop_site), str(shop_name), str(price_good), str(counts_buy),
str(url_good)])
# print(i)
for j in range(len(data)):
self.writer.writerow(data[j])
print("第" + str(k+1) + "页解析、存储完毕<<<<<<<<<<<<<<<<<<<<<")
if k != 99:
data = []
page_next = self.browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/ul/li[last()]/a')
page_next.click()
t = randint(3, 5)
time.sleep(t)
-
过程截图
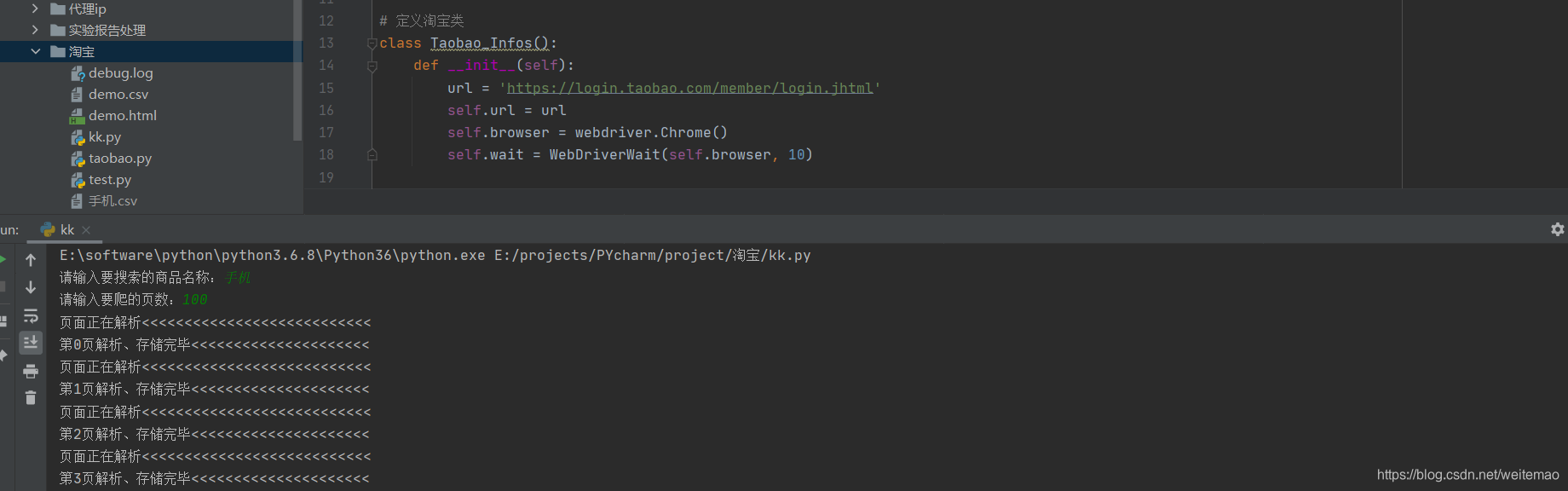

-
最后附上源码,有说的不明或错误的地方,有看到的小伙伴请指正。
import time
from selenium import webdriver # 调用webdriver模块
from selenium.webdriver.support.ui import WebDriverWait
from bs4 import BeautifulSoup
import csv
from random import *
# 定义淘宝类
class Taobao_Infos():
def __init__(self):
url = 'https://login.taobao.com/member/login.jhtml'
self.url = url
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 10)
def login_Infos(self):
self.browser.get(self.url)
# 改变窗口宽度,不要最大化,会被反爬虫检测到
self.browser.set_window_size(1300, 800)
# 点击二维码扫描
self.browser.find_element_by_xpath('//*[@id="login"]/div[1]/i').click()
# 等待扫描二维码,时间短了就改一改
time.sleep(12)
def file_Csv(self):
csv_file = open(r'手机.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(csv_file)
self.writer = writer
writer.writerow(['商品名称', '销售地', '店铺名称', '销售价格', '销售量', '商品链接'])
def get_Data(self):
global data
# page = self.browser.page_source
#
# dk = page.encode(encoding='UTF-8').decode('unicode_escape')
# tt = dk.decode(encoding='UTF-8')
# print(dk)
if self.browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a'):
taobao_index = self.browser.find_element_by_xpath('//*[@id="J_SiteNavHome"]/div/a')
taobao_index.click()
time.sleep(2)
search_input = self.browser.find_element_by_xpath('//*[@id="q"]')
goods_name = input("请输入要搜索的商品名称:")
search_input.send_keys(goods_name)
time.sleep(2)
search_submit = self.browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button')
search_submit.click()
count = int(input("请输入要爬的页数(最大为100):"))
# 淘宝最大页数为100页
for k in range(count):
page = self.browser.page_source
# print(page.encode('utf-8', 'ignore'))
print("页面正在解析<<<<<<<<<<<<<<<<<<<<<<<<<<<")
# with open(r'demo.html', 'w', newline='', encoding='utf-8-sig') as f:
# f.write(page.encode("gbk", 'ignore').decode("gbk", "ignore"))
soup = BeautifulSoup(page, "html.parser")
data_site = soup.find('div', class_='grid g-clearfix').find_all_next('div', class_='items')
for data_good in data_site:
dk0 = data_good.find_all('div', class_='row row-1 g-clearfix')
dk1 = data_good.find_all('div', class_='row row-2 title')
dk2 = data_good.find_all('div', class_='row row-3 g-clearfix')
for i in range(len(dk0)):
price_site = dk0[i].find('div', class_='price g_price g_price-highlight')
price_good = price_site.find('strong').text.strip()
counts_buy = dk0[i].find('div', class_='deal-cnt').text
counts_buy = counts_buy.replace('人付款', '')
# print(counts_buy)
if '+' in counts_buy:
counts_buy = counts_buy.replace('+', '')
if '万' in counts_buy:
counts_buy = float(counts_buy.replace('万', '')) * 10000
# print(counts_buy)
name_site = dk1[i].find('a')
url_good = name_site['href']
name_good = name_site.text.strip()
shop_name = dk2[i].find('div', class_='shop').text.strip()
shop_site = dk2[i].find('div', class_='location').text
# print(name_good, shop_site, shop_name, price_good, counts_buy, url_good)
data.append([str(name_good), str(shop_site), str(shop_name), str(price_good), str(counts_buy),
str(url_good)])
# print(i)
for j in range(len(data)):
self.writer.writerow(data[j])
print("第" + str(k+1) + "页解析、存储完毕<<<<<<<<<<<<<<<<<<<<<")
if k != 99:
data = []
page_next = self.browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/ul/li[last()]/a')
page_next.click()
t = randint(3, 5)
time.sleep(t)
if __name__ == "__main__":
data = []
app = Taobao_Infos()
app.login_Infos()
app.file_Csv()
app.get_Data()
-
还得数据处理,头秃。