学Python,想必大家都是从爬虫开始的吧。
python爬虫即[网络爬虫],网络爬虫是一种程序。
主要用于搜索引擎,它将一个网站的所有内容与链接进行阅读,并建立相关的全文索引到数据库中,然后跳到另一个网站。
搜索引擎(SearchEngine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、[垂直搜索引擎]、式搜索引擎、门户搜索引擎与[免费链接]列表等。
爬虫是入门Python最好的方式之一,掌握Python爬虫之后再去学习Python其他知识点,会更加地得心应手。当然,用Python爬虫对于零基础的朋友来说还是有一定难度的,那么朋友,你真的会Python爬虫吗?
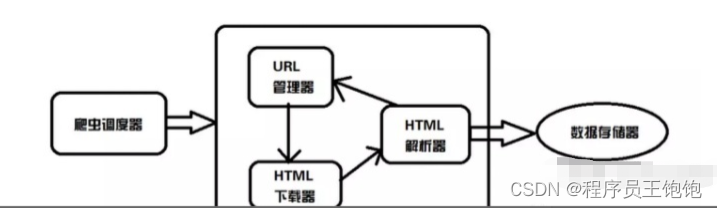
从上图可以看出,基础的爬虫架构大致分为5类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器。
对于这5类的功能,给大家简单解释一下:
- [爬虫调度器],主要是配合调用其他四个模块,所谓调度就是取调用其他的模板
- URL管理器,就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口。
- HTML[下载器],就是将要爬取的页面的HTML下载下来
- HTML解析器,就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器。
- 数据存储器,就是将HTML下载器发送过来的数据存储到本地
- python超全资料库安装包学习路线项目源码免费分享
Python爬虫是否违法?
对于Python是否违法的说法是众说纷纭,不过至今,Python网络爬虫还在法律允许范围内,当然,如果被抓取的数据被用于个人或商业用途,并造成一定的负面影响,那么是会被谴责的。所以还请大家合理使用Python爬虫。
为何选择Python来进行爬虫?
1、抓取网页本身的接口 相比与其他静态编程语言,python抓取网页文档的接口更简洁;此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,在python里都有非常优秀的第三方包帮你搞定。
2、网页抓取后的处理 抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
NO.1 快速开发,语言简洁,没那么多技巧,所以读起来很清楚容易。
NO.2 跨平台(由于python的开源,它比java更能体现"一次编写到处运行"
NO.3 解释性( 无需编译,直接运行/调试代码)
NO.4 构架选择太多(GUI构架方面 主要的就有 wxPython, tkInter, PyGtk, 。
自学Python爬虫有哪些步骤?
1、首先学会基本的Python语法知识
2、学习Python爬虫常用到的几个重要内置库, http等,用于下载网页
3、学习[正则表达式]re、BeautifulSoup(bs4)、Xpath(lxml)等网页解析工具
4、开始一些简单的网站爬取(博主从百度开始的,哈哈),了解爬取数据过程
5、了解爬虫的一些[反爬机制]),header,robot,时间间隔,代理ip,隐含字段等
6、学习一些特殊网站的爬取,解决登录、Cookie、动态网页等问题
7、了解爬虫与数据库的结合,如何将爬取数据进行储存
8、学习应用Python的多线程、多进程进行爬取,提高爬虫效率
9、学习爬虫的框架,Scrapy、PySpider等
10、学习[分布式爬虫](数据量庞大的需求)
如果说你想要学习好python编程爬虫,那么在这里我还是极力的人推荐你这样学习才是最好的,按照上面的学习教程方式和方法去学习。
读者福利:知道你对Python感兴趣,便准备了这套python学习资料
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)