Elasticsearch实战- BestFields MostFields 搜索策略
1.字段中心及词条中心查询
说区别之前,先普及下概念
- 字段中心查询式,就是以字段为中心,代表就是 BestFields和MostFields把所有的字段全都散列,然后从中去查询
举个简单的例子,地址存储的时候 你不可能直接存储 ”湖北省武汉市东湖高新区“ 这样的字符串,所以一般存储的时候 省/市/区 分别是"provice", “city”, "area"三个字段,那我搜寻 湖北省 武汉市 东湖高新的时候,是不是会把所有 包含湖北省,武汉市 都搜出来,大量重复无用数据
- 词条中心查询式,就是以词条为中心,代表就是 CrossFields,就是解决上面的问题的,以词条为中心搜索,关联多个字段
本文我们着重讲一下 字段中心的 BestFields及MostFields
2.Multi-match query 的目的多字段匹配策略
-
Best-fields策略 默认排序, 又叫最佳字段排序,可以理解为精确匹配
搜索的Documemt文档中的某一个field,尽可能多的匹配搜索条件,比如我搜索了3个字段,其中一个字段相关度分数很高,哪个分数高就用哪一个返回,作为相关度分数对结果排序
等价:BestFields 等价于dis_max查询
优点:精确匹配的数据尽可能的排列到最前端,且可以通过minimum_should_match来去除长尾数据
缺点:除了那些精准匹配的结果,其他结果没有区分度,排序结果相对不均匀
案例:百度搜索,除了前几条精确匹配,后面几页都没有区分度
-
Most-fields策略,尽可能多的字段匹配到搜索条件
综合多个field进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,结果不一定精准,某一个document的多个field 匹配到更多的关键字 就会优先返回排在了前面;而且多个字段的分数是累加计算反馈到最终分的
等价:MostFields等价于bool should查询
优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的
缺点:可能那些精准匹配的结果,无法推送到最前面
案例:wiki搜索,尽可能多的字段匹配优先返回,最精准的结果可能在后面
看起来懵逼么?下面用一个场景描述算分就明白了
2.1 准备数据
empId:员工id, salary 表示薪资, deptName:部门, address:地址
POST /testboost/_bulk
{"index":{"_id": 1}}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","address" : "湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3}}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4}}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5}}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6}}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","address" : "湖北省武汉市江汉路","content" : "i like java developer"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","address" : "湖北省武汉市江汉大学","content" : "i like spark language"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","address" : "河南省郑州市郑州大学","content" : "i like java developer"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部","address" : "河南省开封市河南大学","content" : "i am not like java "}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部","address" : "河南省郑州市金水区","content" : "i like c++"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部","address" : "河南省郑州高新开发区","content" : "i think spark is good"}
3 单个字段查询逻辑及算分
3.1 单个Address地址查询算分
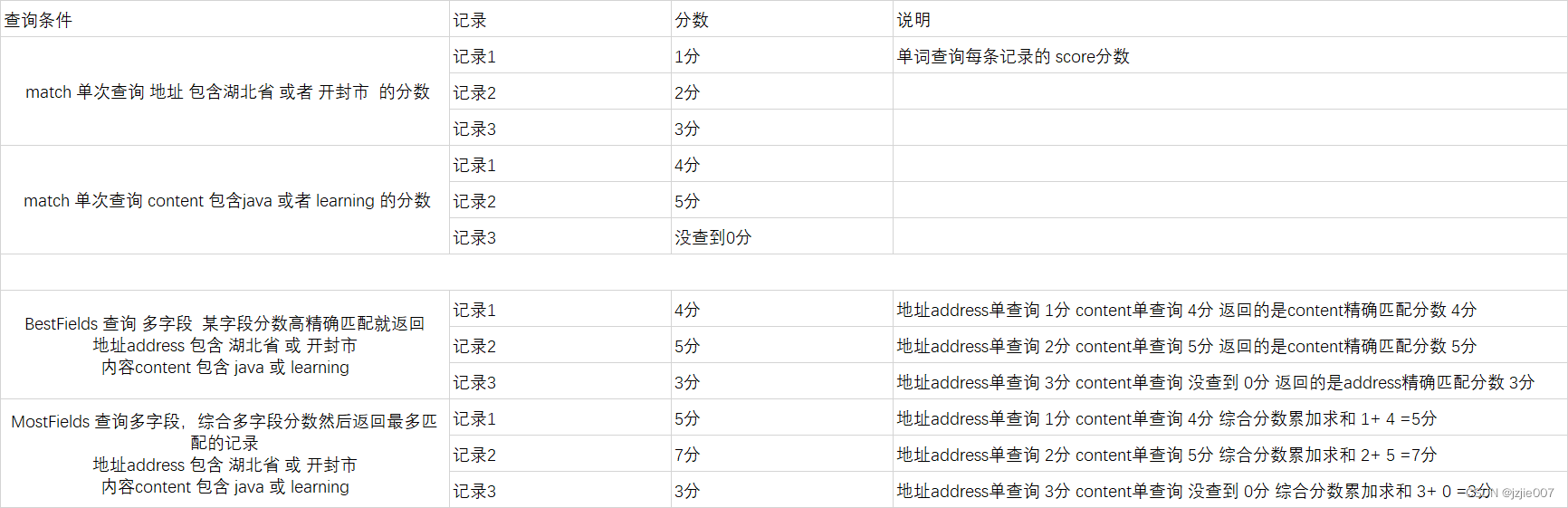
现在想找 地址:湖北省 或者开封市 的人
get /testfields/_search
{
"query":{
//搜索 address 中包含 湖北省 或 开封市 的信息
"match": {
"address": {
"query": "湖北省 开封市",
"operator": "or"
}
}
}
}
可以查看查询结果 ,address中 是湖北省 或者开封市 来判断的
为什么开封市的考前,湖北省的靠后?
开封市 只有3个文档相关,但是湖北省有10个文档相关,自然而然TFIDF计算权重的时候认为开封市 在所有的文档中 更有标识意义,所以开封市权重高,排在最前面,我用表格统计了下分数
| 员工 |
address说明 |
分数 |
| 员工11 |
address 包含 开封市 |
s core: 3.0543272 |
| 员工12 |
address 包含 开封市 |
s core: 3.0543272 |
| 员工3 |
address 包含 湖北省 |
s core: 2.1525636 |
| 员工4 |
address 包含 湖北省 |
s core: 2.1525636 |
| 员工5 |
address 包含 湖北省 |
s core: 1.3682688 |
| 员工10 |
address 包含 湖北省 |
s core: 1.3682688 |
| 员工2 |
address 包含 湖北省 |
s core:1.2228065 |
| 员工6 |
address 包含 湖北省 |
s core: 1.2228065 |
| 员工7 |
address 包含 湖北省 |
s core: 1.2228065 |
| 员工8 |
address 包含 湖北省 |
s core: 1.1727825 |
结果如图所示:
3.2 单个Content内容查询算分
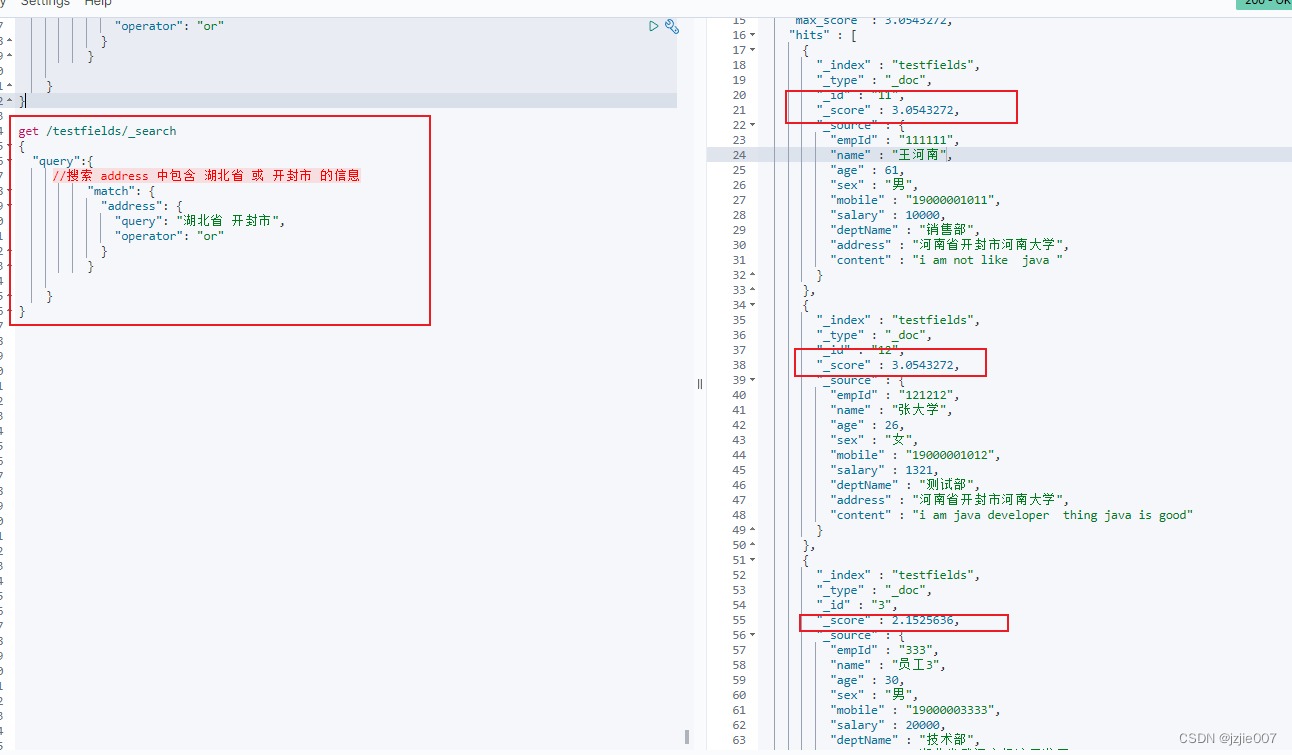
现在想找 content 中包含 elasticsearch 或 beginner的信息
get /testfields/_search
{
"query":{
//搜索 content 中包含 elasticsearch 或 beginner的信息
"match": {
"content": {
"query": "elasticsearch beginner",
"operator": "or"
}
}
}
}
可以查看查询结果 ,content 中 是包含 elasticsearch 或 beginner的信息
我用表格统计了下分数
| 员工 |
content 说明 |
分数 |
| 员工3 |
content 包含 elasticsearch 和 beginner,两个都有 而且紧邻挨着 分数最高 |
s core: 3.1380997 |
| 员工4 |
content 包含 elasticsearch 和 beginner 两个都有 但是两个单词 分开的 |
s core: 2.2975376 |
| 员工7 |
content 包含 elasticsearch |
s core: 1.3051386 |
| 员工1 |
content 包含 elasticsearch |
s core: 1.0801146 |
| 员工10 |
content 包含 elasticsearch |
s core: 1.0214127 |
结果如图所示:
4 BestFields 多字段查询
4.1 BestFields 多字段查询返回某个字段精确匹配读最高的结果及算分
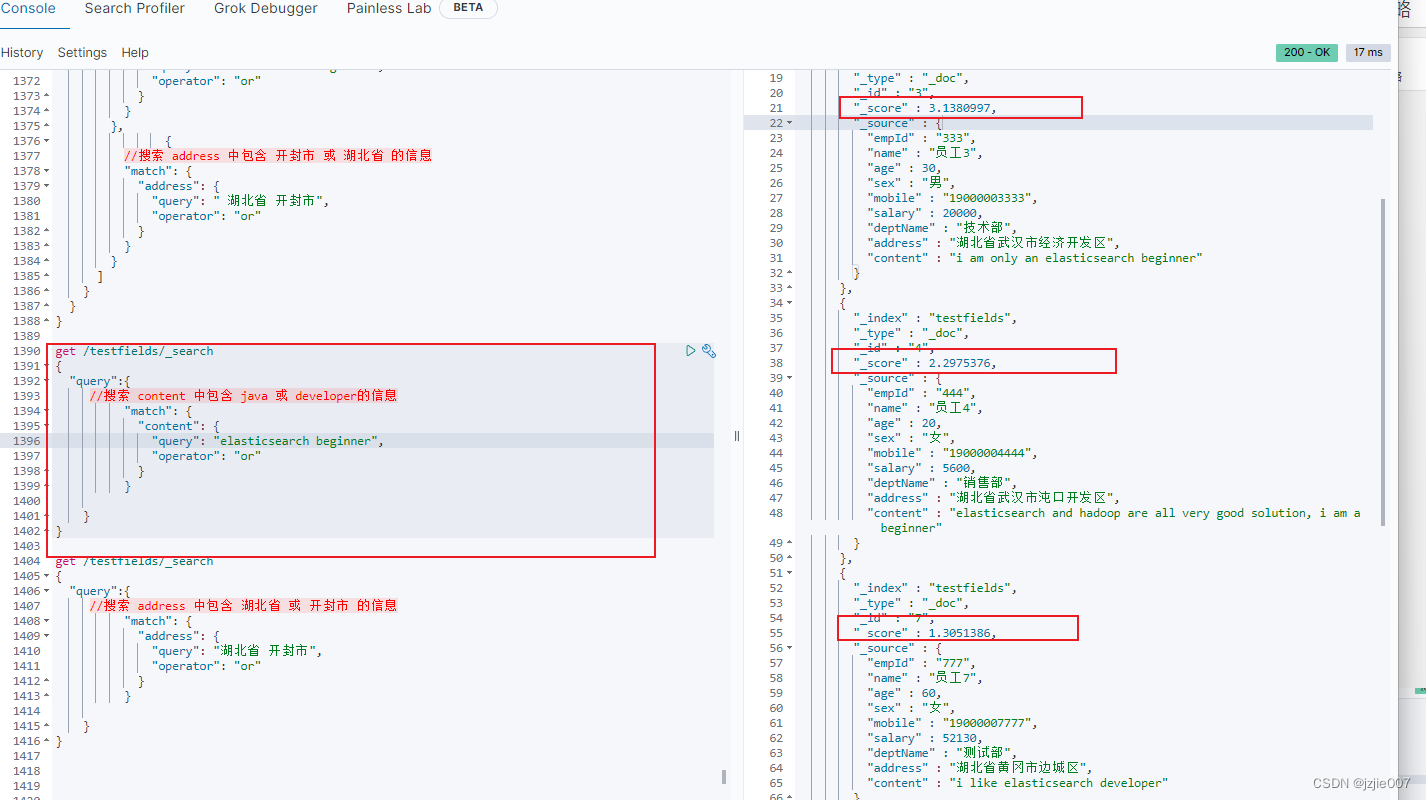
现在想根据多字段匹配,采用BestFields策略去匹配某一个字段精确度最高的
- address 地址包含 湖北省 或者 开封市 的人
- content 中包含 elasticsearch 或 beginner的人
get /testfields/_search
{
"query":{
"multi_match": {
"query": "elasticsearch beginner 湖北省 开封市",
"type": "best_fields",
"fields": [ "content", "address" ]
}
}
}
**可以查看查询结果 ,这个分数 就是单个字段 最高分匹配返回结果,BestFields,按照分数最高最匹配的返回
| 员工 |
分数 |
计算逻辑 |
| 员工3 |
3.1380997 |
3.1380997 = 员工3 第一步address 地址环节得分2.1525636 , 第二步 员工3 content环节计算 3.1380997 ~ 取最高匹配字段 content 返回 =3.1380997 |
| 员工11 |
3.0543272 |
3.0543272 = 员工11 第一步address环节计算3.0543272 ,第二步员工11 content环节 不存在 0 分 ~取最高匹配字段 content 返回 =3.0543272 |
| 员工12 |
3.0543272 |
5.29 = 员工12第一步address环节计算3.0543272 ,第二步员工12 content环节 不存在 0 分 ~取最高匹配字段 content 返回 =3.0543272 |
查看结果:

所以 BestFields 就是 多个字段中返回 匹配度最高的那条记录 返回结果, 所以就是你看到的百度 前几条最匹配,后面的区分度不高
4.2 BestFields 参数tie_breaker 设置让其他匹配结果也参与计算
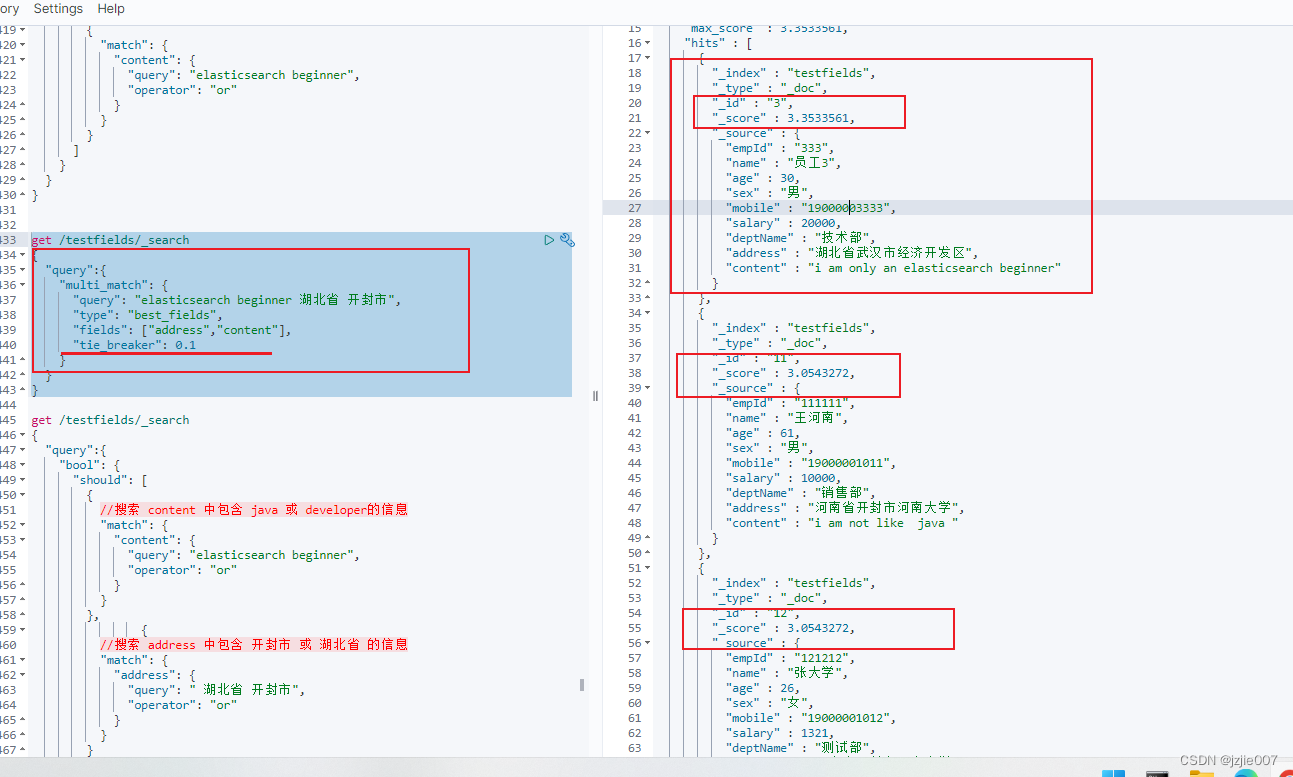
可以设置tie_breaker参数 [0~1]之间 ,然后 正常来说BestFields 是返回 最高分数,忽略 其他配条件的, 但是如果加上了 tie_breaker参数后, 就是其他条件 的得分 * tie_breaker 然后累加 ,也参与到 计算相关度总分 ,不给tie_breaker参数就是不参与即其他字段为0
#采用 bestFields 查询 携带参数 tie_breaker 0.1 就是 如果其他字段也匹配到了 ,其他字段的得分 * 0.1 + 最高的得分 累加计算最终相关度总分
get /testfields/_search
{
"query":{
"multi_match": {
"query": "elasticsearch beginner 湖北省 开封市",
"type": "best_fields",
"fields": ["address","content"],
"tie_breaker": 0.1
}
}
}
可以看到查询结果
员工 3 分数 3.3533561 = 2.1525636 * 0.1 + 3.1380997
- 原BestFields 分数 3.1380997 = 员工3 第一步address 地址环节得分2.1525636 , 第二步 员工3 content环节计算 3.1380997 ~ 取最高匹配字段 content 返回 =3.1380997
- 现在 加了tie_breaker = 0.1 分数=3.3533561 = 员工3 第一步address 地址环节得分2.1525636 , 第二步 员工3 content环节计算 3.1380997 ~ 取最高匹配字段 3.1380997 + 其他字段分2.1525636 * 0.1 (tie_breaker配置) = 3.35最终分
4.3 BestFields 参数minimum_should_match 设置控制搜索的精确度
可以设置minimum_should_match [x%] 来控制匹配多少个单词 的doc才能被匹配命中
我们现在搜索了 4个参数 湖北省 开封市 elasticsearch beginner 如果不设置 该参数, 那就是任何一个单词匹配到 都会返回
不加参数 查询
get /testfields/_search
{
"query":{
"multi_match": {
"query": "elasticsearch beginner 湖北省 开封市",
"type": "best_fields",
"fields": ["address","content"],
"tie_breaker": 0.1
}
}
}
查询结果, 只要有一个字段匹配 就会命中,比如 address 湖北省 ,content中没有任何 elasticsearch beginner的记录也命中了,这明显不是我们要的结果,太多其他无用的结果了,如何提高精度
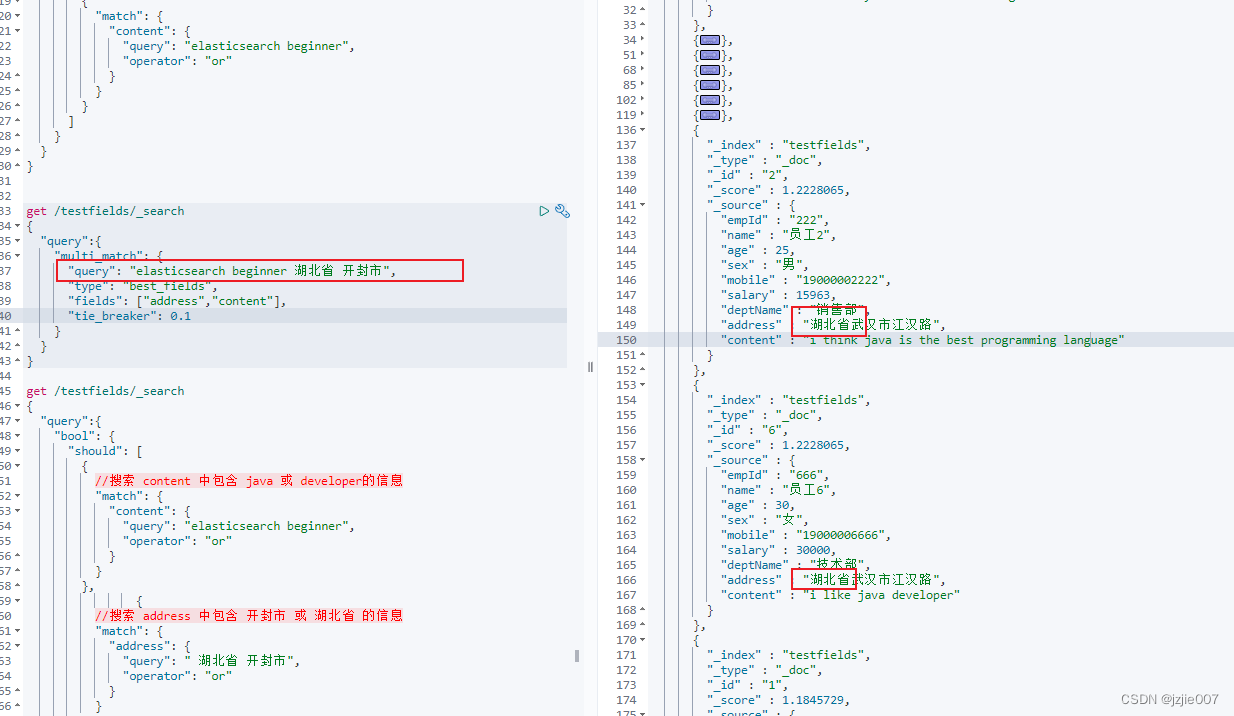
该如何控制 搜索的精度 ,比如 至少我要匹配三个 单词 ,才给我搜出来 ?如何实现 ? 用 minimum_should_match
现在又 四个搜索字段, 设置 minimum_should_match :4 什么意思 ?控制分词条件在倒排索引中最少的数量,表示最少匹配倒排索引个数
!!!!! 注意是 命中倒排索引的数量,要看你如何分词
!!!!! 注意是 命中倒排索引的数量,要看你如何分词
!!!!! 注意是 命中倒排索引的数量,要看你如何分词
我这里没做分词,所以 湖北省 开封市 被拆成了 单个字 的倒排索引 ,“湖”,“北”,“省”,“开”,“封”,“市”
所以你设置 minimum_should_match 1,2,3,4 能匹配4个字的 很多记录都命中
如果设置 5 ,那就是 除了 “湖”,“北”,“省”, “市”/ 或者 “开”,“封”,“市”,"省"四个 命中外 ,还需要再 content中 再命中 一个,才能算 5个,这样搜索精度就提高了
get /testfields/_search
{
"query":{
"multi_match": {
"query": "elasticsearch beginner 湖北省 开封市",
"type": "best_fields",
"fields": ["address","content"],
"tie_breaker": 0.1,
//1,2,3,4 以下 全部匹配
//因为 倒排索引是单个字分词的 湖 北 省 开 封 市 任何四个倒排匹配就命中
"minimum_should_match": 5
}
}
}
可以看到查询结果 ,只剩下 2条记录, 匹配后才命中,提高了查询 精确度
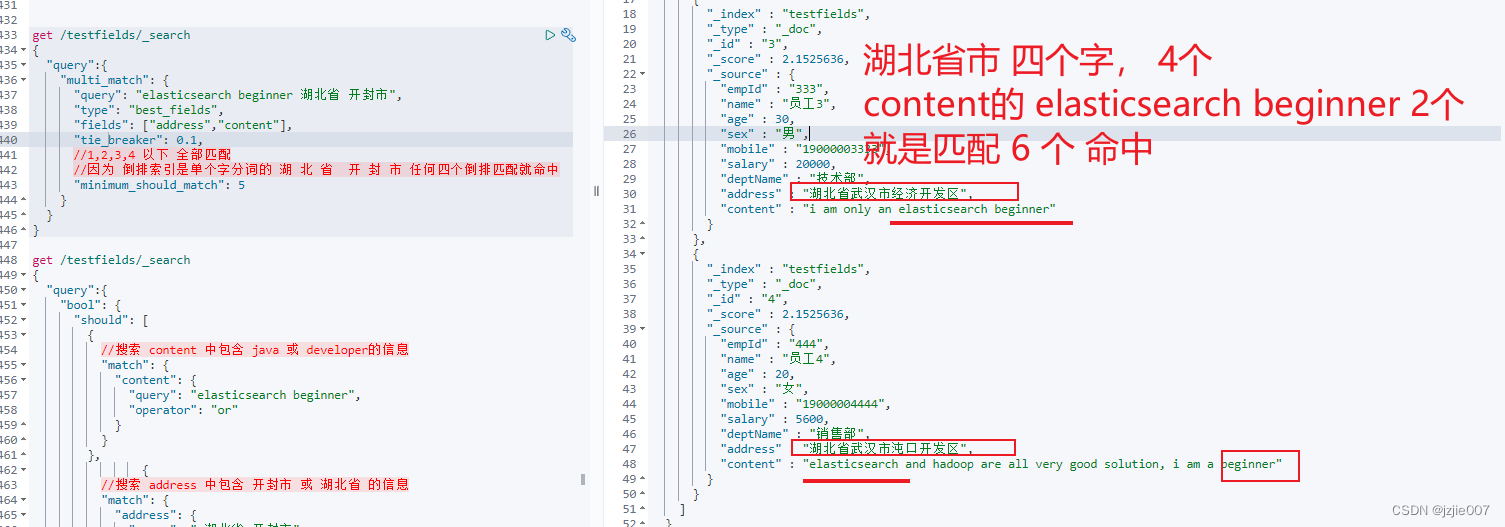
4.4 BestFields 等价于 Dis_mix查询方式
#采用dix_max查询方式,等价于 bestFields
get /testfields/_search
{
"query":{
//dis_max查询方式等价于 bestFields
"dis_max": {
"queries": [
{
"match": {
"address": {
"query": "湖北省 开封市",
"operator": "or"
}
}
},
{
"match": {
"content": {
"query": "elasticsearch beginner",
"operator": "or"
}
}
}
]
}
}
}
可以看到查询结果和刚才BestFields 查询 的一摸一样,结果排序一样,结果分数一样
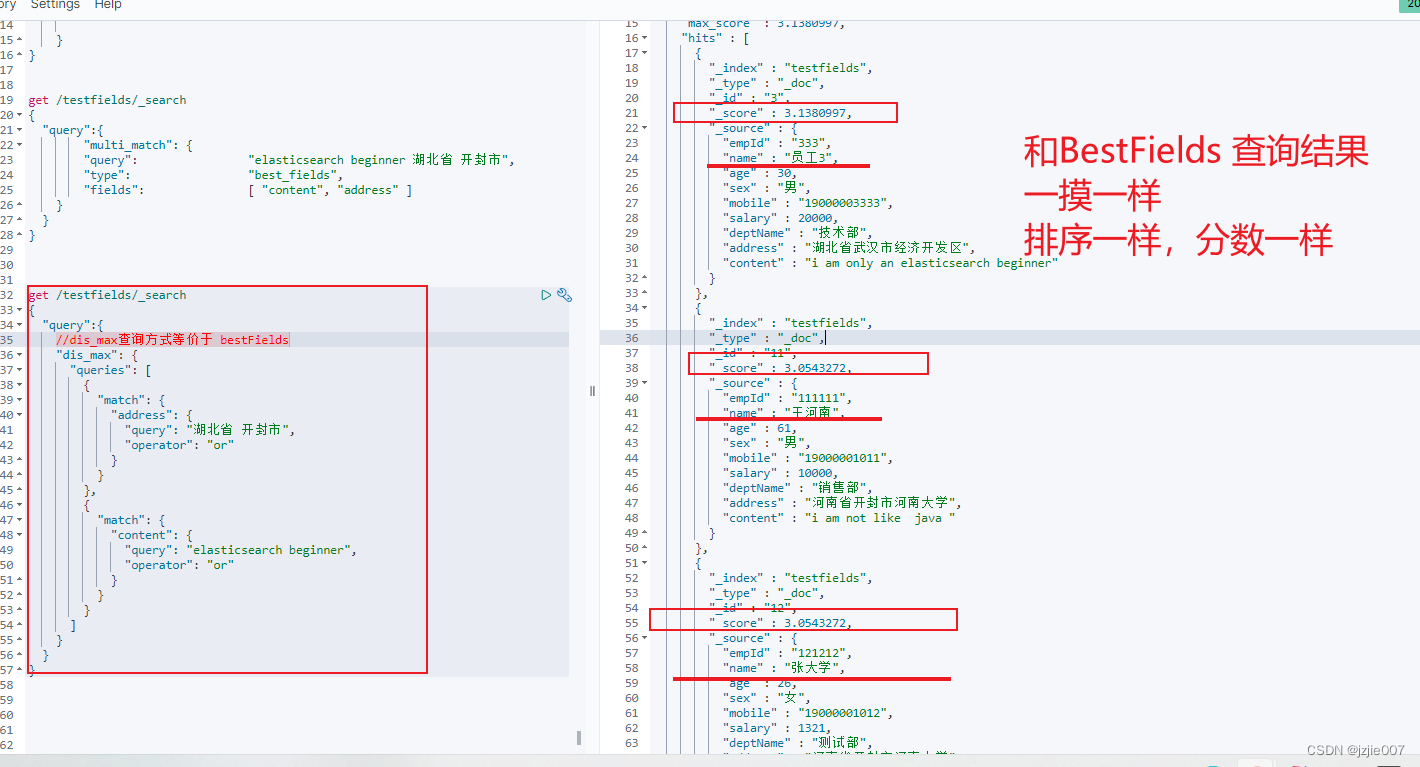
5 MostFields 多字段查询及算分
5.1 MostFields最多字段匹配返回多字段匹配累计总分
现在想根据多字段查找,采用MostFields策略去匹配最多字段符合要求的document 返回结果
- address 地址包含 湖北省 或者 开封市 的人
- content 中包含 elasticsearch 或 beginner的人
//multi_match 多字段匹配查询 most_fields策略
get /testfields/_search
{
"query":{
"multi_match": {
"query": "elasticsearch beginner 湖北省 开封市",
"type": "most_fields",
"fields": ["address","content"]
}
}
}
可以查看查询结果 ,这个分数 就是多字段匹配结果,按照分数最高 的返回, 但是分数怎么计算最高呢?累加而来
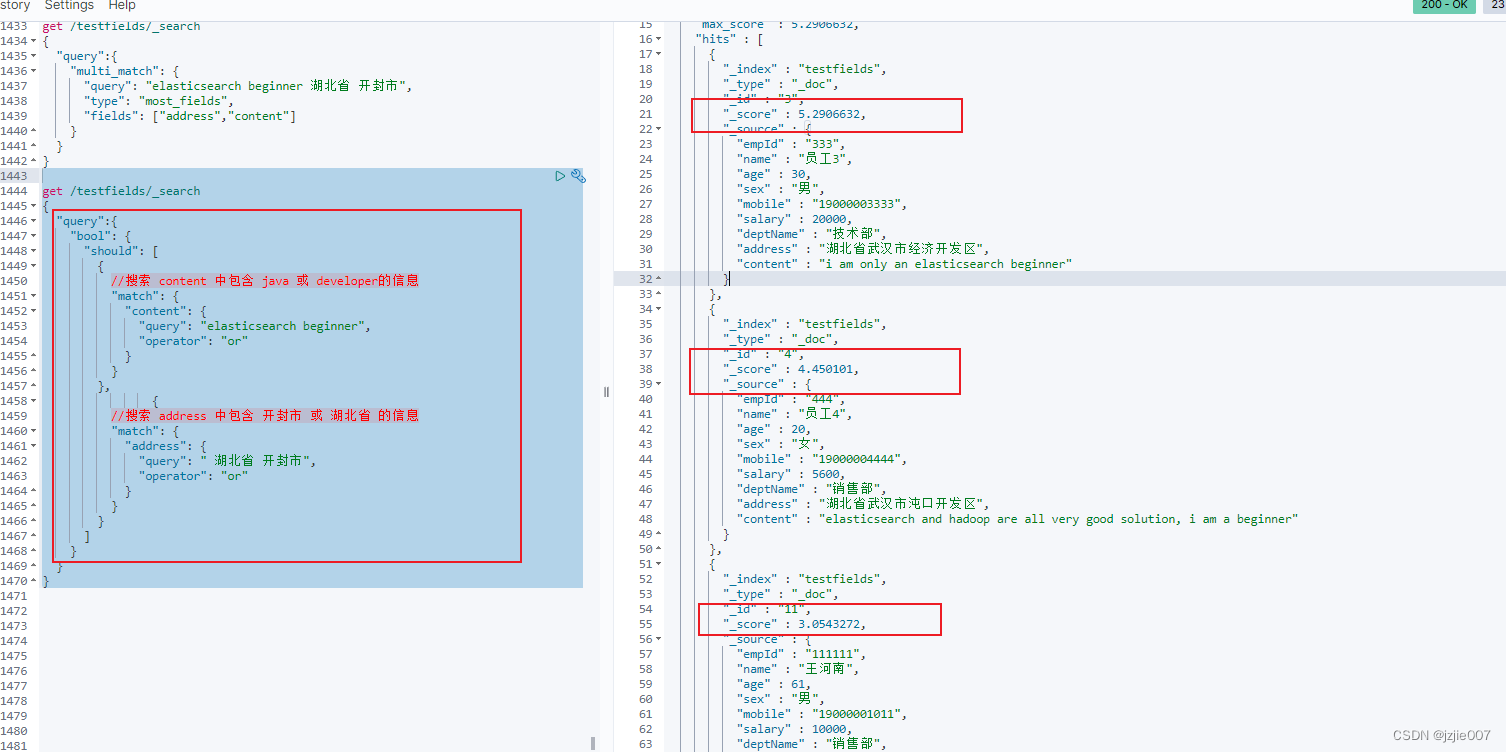
| 员工 |
分数 |
计算逻辑 |
| 员工3 |
5.2906632 |
5.29 = 员工3 第一步address环节计算2.1525636 + 第二步员工3 content环节计算 3.1380997 ~ 累加 =5.29 |
| 员工4 |
4.450101 |
4.45 = 员工4 第一步address环节计算2.1525636 + 第二步员工4 content环节计算 2.2975376 ~ 累加 =4.45 |
| 员工11 |
3.0543272 |
3.05 = 员工11 第一步address环节计算3.0543272 + 第二步员工11 content环节 不存在 0 分 ~ 累加 =3.05 |
| 员工12 |
3.0543272 |
5.29 = 员工12 第一步address环节计算3.0543272 + 第二步员工12 content环节 不存在 0 分 ~ 累加 =3.05 |
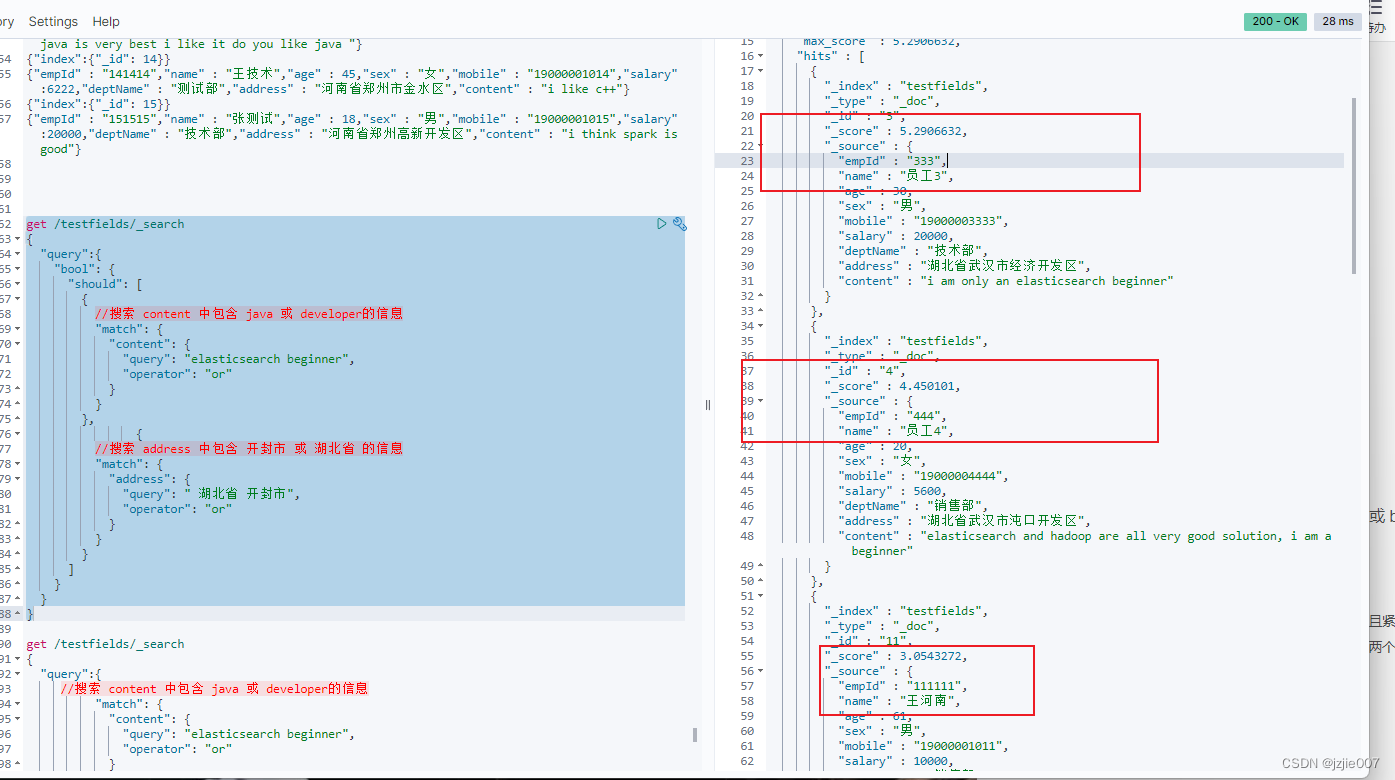
所以 最高的就是 第一步地址,第二步content内容搜索的 累加的总分 员工3的分数最高,排序最先返回
这就是 MostFields ,会综合各个字段然后参与计算, 找出多个字段匹配的 结果,也就是wiki的搜索策略,尽可能多的匹配内容,但是最匹配的可能不是最优先返回的
5.2 MostFields 等价bool should 查询方式
现在想根据多字段查找,采用bool should的方式来实现查询,看下结果如何
- address 地址包含 湖北省 或者 开封市 的人
- content 中包含 elasticsearch 或 beginner的人
get /testfields/_search
{
"query":{
"bool": {
"should": [
{
//搜索 content 中包含 java 或 developer的信息
"match": {
"content": {
"query": "elasticsearch beginner",
"operator": "or"
}
}
},
{
//搜索 address 中包含 开封市 或 湖北省 的信息
"match": {
"address": {
"query": " 湖北省 开封市",
"operator": "or"
}
}
}
]
}
}
}
可以查看查询结果 ,是和Most Fields查询结果一致的,分数都是累加做排名的
至此 我们已经能够 讲解了 BestFields 及 MostFields 字段中心的查询处理方式, 下一篇,我们讲一下 字段中心带来的问题及解决方案 词条为中心