目录
1.事务
1.1 概念:
1.2 回退事务
1.3提交事务
1.4事务细节注意点
1.5事务的隔离级别
1.5.1 介绍
1.5.2 解决这些安全性问题
1.5.3演示脏读
1.5.4避免脏读,演示不可重复发生
1.5.5 演示不可重复读
1.5.6演示串行化
1.6事务的ACID特性
1.6.1 原子性
1.6.2一致性
1.6.3 隔离性
1.6.4 持久性
2. mysql 表类型和存储引擎
2.1基本介绍
2.2主要的存储引擎/表类型特点
2.3细节说明
2.3.1三种存储引擎表使用案例
2.4如何选择表的存储引擎
2.5 修改存储引擎
3.视图(view)
3.1视图的作用
3.2视图和基表的关系
3.3视图的基本使用
3.4视图的注意点
3.5视图的优点
3.6视图的练习
4.MySQL用户管理
4.1概念:
4.2创建用户
4.3删除用户
4.4用户修改密码
4.5mysql 中的权限
4.6给用户授权
4.7回收用户授权
4.8权限生效指令
1.事务
1.1 概念:
事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功,要么全部失败,例如:转账就要用事务来处理,用以保证数据的一致性。

回滚:手动开始一个保存点,并且设置一个事务
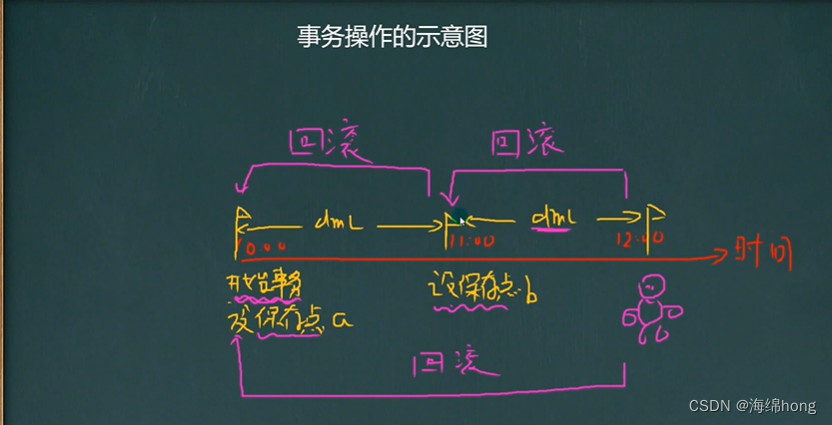
-- 事务的一个重要的概念和具体操作
-- 看一个图[看示意图]
-- 演示
-- 1. 创建一张测试表
CREATE TABLE t27 (
id INT,
`name` VARCHAR(32));
-- 2. 开始事务
START TRANSACTION
-- 3. 设置保存点
SAVEPOINT a
-- 执行 dml 操作
INSERT INTO t27 VALUES(100, 'tom');
SELECT * FROM t27;
SAVEPOINT b
-- 执行 dml 操作
INSERT INTO t27 VALUES(200, 'jack');
-- 回退到 b
ROLLBACK TO b
-- 继续回退 a
ROLLBACK TO a
-- 如果这样, 表示直接回退到事务开始的状态.
ROLLBACK COMMIT
1.2 回退事务
保存点:保存点时事务中的点,用于取消部分事务
当结束事务时,会自动删除该事务所定义的所有保存点,当执行回退事务时,通过指定的保存点可以回退到指定的点。
1.3提交事务
使用commit语句可以提交事务,当执行了commit语句后,会确认事务的变化,结束事务,删除保存点,释放锁,数据生效,当使用commit语句结束事务之后,其他会话[其他连接],将可以查看事务变化之后的新数据[所以数据将正式生效]
1.4事务细节注意点
1.如果不开始事务,默认情况下,dml时自动提交的,不能回滚。
2.如果开始一个事务,你没有创建保存点,你可以执行rollback,默认就是回滚到你事务开始的状态
3.你可以在这个事务中(还没有提交时),创建多个保存点。比如:savepoint aaa;执行dml,savepoint bbb
4.你可以在事务没有提交前,选择回退到哪个保存点
5.mysql的事务机制需要innobd的存储引擎才可以使用,myisam不好使
6.开始一个事务start transaction ,set autocommit=off;
1.5事务的隔离级别
1.5.1 介绍
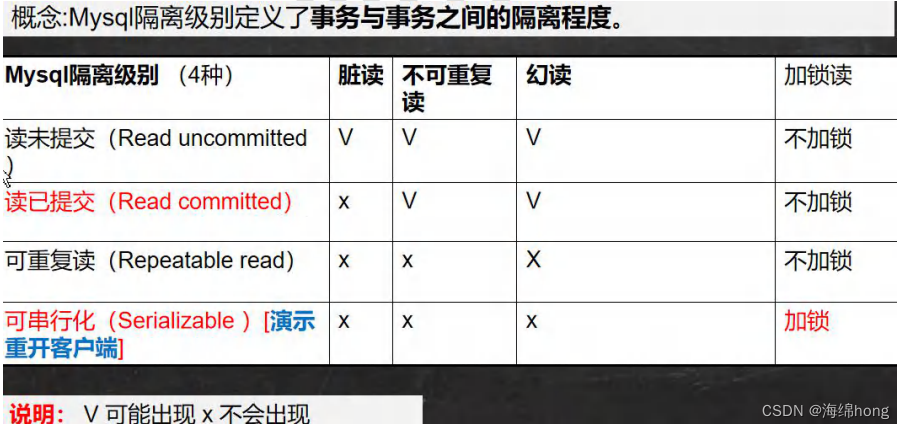
隔离性:一个事务的执行,不应该受到其他事务的干扰。
1.多个事务开启各自事务操作数据库中数据时,数据库系统要负责隔离操作,以保证各个连接在获取数据时的准确性;
2.如果不考虑隔离性(一个事务执行受到其他的事务的干扰),引发一些安全问题,主要体现在读取数据上:
-
脏读:一个事务读到了另一个事务未提交的数据,导致查询结果不一致
-
不可重复读:一个事务读到了另一个事务已经提交的update的数据,导致多次查询结果不一致。
-
虚读/幻读:一个事务读到了另一个事务已经提交的insert的数据,导致多次查询结果不一致。
1.5.2 解决这些安全性问题
1.5.3演示脏读
开启两个窗口A,B
设置A窗口的隔离级别为read uncommitted;
SET SESSION TRANSACTION ISOLATION LEVEL read uncommitted;
 在A,B两个窗口中开启事务
在A,B两个窗口中开启事务
start transaction;
在B窗口中完成转账的功能:
update account set money = money - 1000 where name= '小张';
update account set money = money + 1000 where name= '小凤';
*** 事务未提交!!!

在A窗口中进行查询
select * from account;
 ***发现A窗口中已经查询到转账成功了!!!已经发生了脏读:一个事务中已经读到了另一个事务未提交的数据。
***发现A窗口中已经查询到转账成功了!!!已经发生了脏读:一个事务中已经读到了另一个事务未提交的数据。
1.5.4避免脏读,演示不可重复发生
开启两个窗口A,B
设置A窗口的隔离级别为read committed;
SET SESSION TRANSACTION ISOLATION LEVEL read committed;
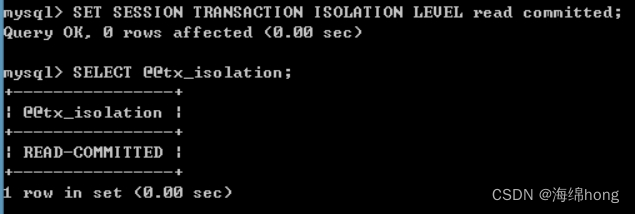 分别在两个窗口中开启事务:
分别在两个窗口中开启事务:
start transaction;
在B窗口中完成转账
update account set money = money - 1000 where name= '小张';
update account set money = money + 1000 where name= '小凤';
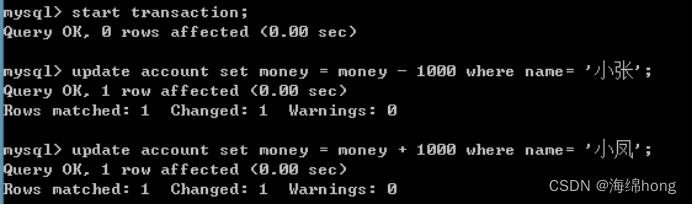
*** 没有提交事务!!!
在A窗口中进行查询:
select * from account;

*** 发现这个时候没有转账成功!!!(没有查询到另一个事务未提交的数据:说明已经避免了脏读)。
在B窗口中提交事务
commit;
在A窗口查询
select * from account;
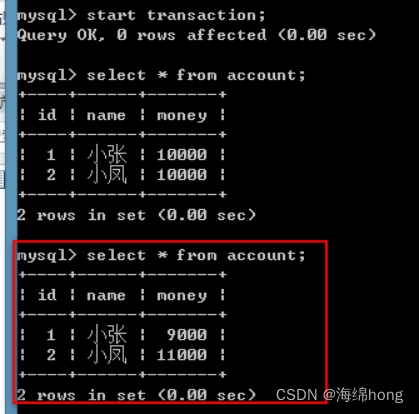 *** 发现这次的结果已经发生了变化!!!(已经发生不可重复读:一个事务已经读到了另一个事务提交的update的数据,导致多次查询结果不一致。)
*** 发现这次的结果已经发生了变化!!!(已经发生不可重复读:一个事务已经读到了另一个事务提交的update的数据,导致多次查询结果不一致。)
1.5.5 演示不可重复读
分别开启两个窗口A,B
设置A窗口的隔离级别:repeatable read;
SET SESSION TRANSACTION ISOLATION LEVEL repeatable read;
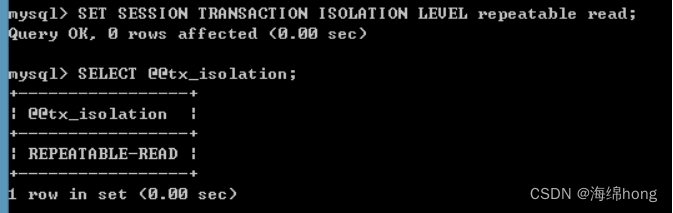 在A,B两个窗口中开启事务:
在A,B两个窗口中开启事务:
start transaction;
在B窗口完成转账
update account set money = money - 1000 where name= '小张';
update account set money = money + 1000 where name= '小凤';
 *** 未提交事务!!!
*** 未提交事务!!!
在A窗口中进行查询
select * from account;
*** 发现没有转账成功:说明避免脏读!!!
在B窗口中提交事务
commit;
在A窗口中再次查询:
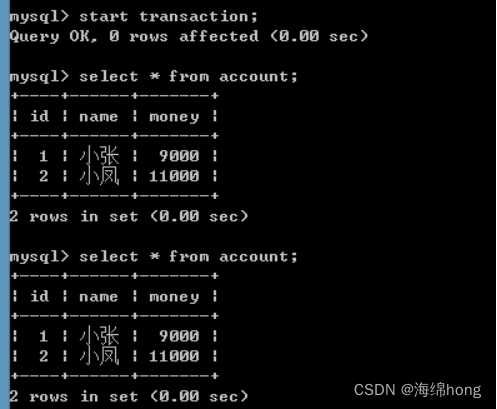 *** 发现在一个事务中的多次查询结果是一致!!!(已经避免不可重复读)。
*** 发现在一个事务中的多次查询结果是一致!!!(已经避免不可重复读)。
1.5.6演示串行化
·开启两个窗口A,B
设置A窗口的隔离级别:serializable
SET SESSION TRANSACTION ISOLATION LEVEL serializable;
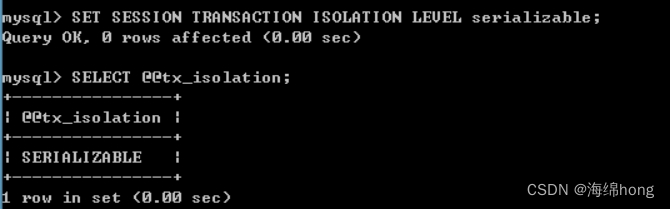 分别在两个窗口中开启事务:
分别在两个窗口中开启事务:
start transaction;

在B窗口中插入一条记录
insert into account values (null,'小李',10000);

在A窗口中进行查询
select * from account;
***发现A窗口已经卡住了(说明事务不允许出现并发,A窗口需要等待B窗口事务执行完成以后,才会执行A窗口的事务。)当B窗口的事务结束(提交或者回滚),那么A窗口马上就会出现结果。
1.6事务的ACID特性
1.6.1 原子性
原子性:事务的不可分割,组成事务的各个逻辑单元不可分割。
1.6.2一致性
一致性:事务执行的前后,数据完整性保持一致。
1.6.3 隔离性
隔离性:事务执行不应该受到其他事务的干扰。
1.6.4 持久性
持久性:事务一旦结束,数据就持久化到数据库中。
2. mysql 表类型和存储引擎
2.1基本介绍
1.mysql的表类型由存储引擎(Storage Engines)决定,主要包括MyISAM,innoDB,Memory等。
2.mysql数据表主要支持六种类型,分别是CVS,Memory,ARCHIVE,MRG MYISAM,MYISAM,innoDB.
3.这六种又分为两类,一类是“事务安全型”比如:innoDB;其余都属于第二类,称为“非事务安全型”
2.2主要的存储引擎/表类型特点

2.3细节说明
我这里重点给大家介绍三种: MyISAM、InnoDB、MEMORY

2.3.1三种存储引擎表使用案例
-- 表类型和存储引擎
-- 查看所有的存储引擎
SHOW ENGINES
-- innodb 存储引擎,是前面使用过.
-- 1. 支持事务 2. 支持外键 3. 支持行级锁
-- myisam 存储引擎
CREATE TABLE t28 (
id INT,
`name` VARCHAR(32)) ENGINE MYISAM
-- 1. 添加速度快 2. 不支持外键和事务 3. 支持表级锁
START TRANSACTION;
SAVEPOINT t1
INSERT INTO t28 VALUES(1, 'jack');
SELECT * FROM t28;
ROLLBACK TO t1
-- memory 存储引擎
-- 1. 数据存储在内存中[关闭了 Mysql 服务,数据丢失, 但是表结构还在]
-- 2. 执行速度很快(没有 IO 读写) 3. 默认支持索引(hash 表)
CREATE TABLE t29 (
id INT,
`name` VARCHAR(32)) ENGINE MEMORY
DESC t29
INSERT INTO t29
VALUES(1,'tom'), (2,'jack'), (3, 'hsp');
SELECT * FROM t29
-- 指令修改存储引擎
ALTER TABLE `t29` ENGINE = INNODB
2.4如何选择表的存储引擎

2.5 修改存储引擎
alter table '表名' engine=存储引擎;
3.视图(view)
3.1视图的作用
三范式让表查询变得复杂,对于常用的数据查询,反复写复杂的查询语句十分不方便,因此可以创建一个虚拟的表(不存数据),这个虚拟表的数据来源于数据库中存在的其他表,虚拟表的数据来源就在定义时给定
3.2视图和基表的关系
3.3视图的基本使用

3.4视图的注意点
-
创建视图后,到数据库去看,对应视图只有一个视图结构文件(形式:视图名.frm)
-
视图的数据发生变化会影响的基表,基表的数据变化也会影响到视图
-
视图中可以在使用视图数据仍然来自于基表
3.5视图的优点
-
安全:一些数据有着重要的信息,有些字段是保密的,不能然客户看到。这是就可以创建一个视图,在这张表里面只保留一部分字段。这样用户就可以查询自己需要的字段,不能查看保密的字段。
-
性能:关系数据库的数据常常会分表存储,使用外键建立这些表之间的关系。这是数据库查询,通常会用到连接(join)。这样做不但麻烦,效率相对也比较低,如果建立有一个视图将相关的表和字段组合在一起,就可以避免使用join查询数据
灵活:如果系统中有一个旧的表,这张表由于设计的问题,即将被废弃。然而很多应用都基于这张表,不易修改。这是就可以建立一个视图,视图中的数据直接映射到新建的表。这样,就可以少做很多改动,也达到升级数据表的目的。
3.6视图的练习
-- 视图的课堂练习
-- 针对 emp ,dept , 和 salgrade 张三表.创建一个视图 emp_view03,
-- 可以显示雇员编号,雇员名,雇员部门名称和 薪水级别[即使用三张表,构建一个视图]
/* 分析: 使用三表联合查询,得到结果
将得到的结果,构建成视图 */
CREATE VIEW emp_view03
AS
SELECT empno, ename, dname, grade
FROM emp, dept, salgrade
WHERE emp.deptno = dept.deptno AND
(sal BETWEEN losal AND hisal)
DESC emp_view03
SELECT * FROM emp_view03
4.MySQL用户管理
4.1概念:
MySQL中的用户,都存储在系统数据库mysql的usre表中 host:允许登录的“位置”,localhost表示该用户只允许在本机登录,也可以指定ip地址,比如:192.168.0.1
host:允许登录的“位置”,localhost表示该用户只允许在本机登录,也可以指定ip地址,比如:192.168.0.1
user:用户名
authentication_string:密码,是通过mysql的password()函数加密之后的密码
4.2创建用户
create user '用户名'@'允许登录的位置' identified by '密码'
-- 说明:创建用户,提示指定密码
4.3删除用户
drop user '用户名' @ '允许登录位置';
4.4用户修改密码
修改自己的密码:
set password = password('密码');
修改他人的密码:
set password for '用户名' @ '登录位置' =password('密码')
4.5mysql 中的权限
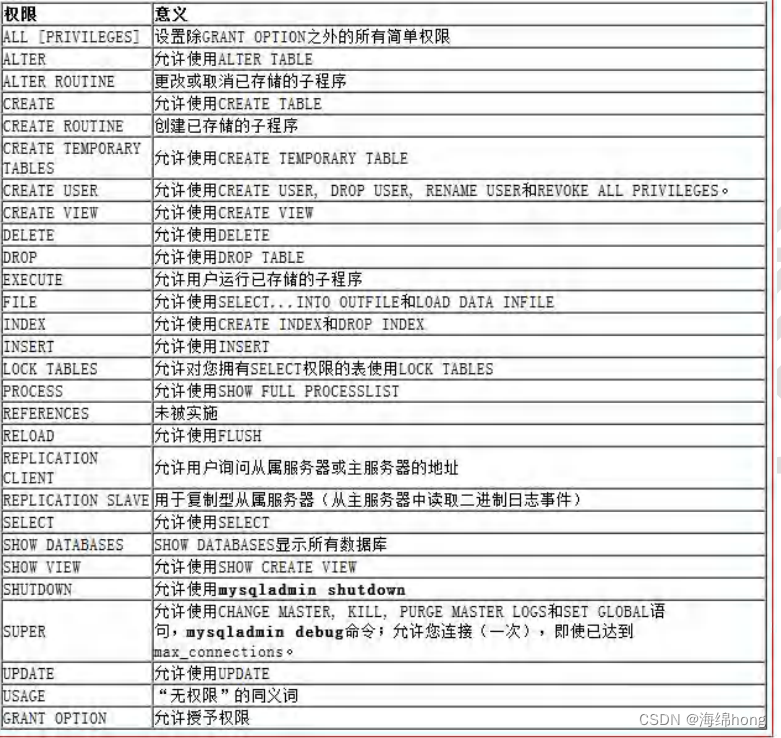
4.6给用户授权

4.7回收用户授权
基本语法:
revoke 权限列表 on 库.对象名 from '用户名'@'登录位置';
4.8权限生效指令
如果权限没有生效可以执行下列命令
flush privileges;