IO流
File
1.File类概述和构造方法
File:它是文件和目录路径名的抽象表示
文件和目录是可以通过File封装成对象的
对于File而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名 而已,它可以是存在的,也可以是不存在的,将来是要通过具体的操作把这个路径的内容转化为具体存在的
File类中的构造方法

2.File类的创建功能
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ETG2InXv-1667567975440)(C:\Users\23600\AppData\Roaming\Typora\typora-user-images\image-20211123111332282.png)]](https://img-blog.csdnimg.cn/f1951056d3d642d4b3a794db84abb26c.png)
createNewFile():用来创建文件的方法
mkdir():用来创建目录的方法
mkdirs():用来创建多级目录的方法
创建文件的时候不能同名,与文件夹名也不能相同
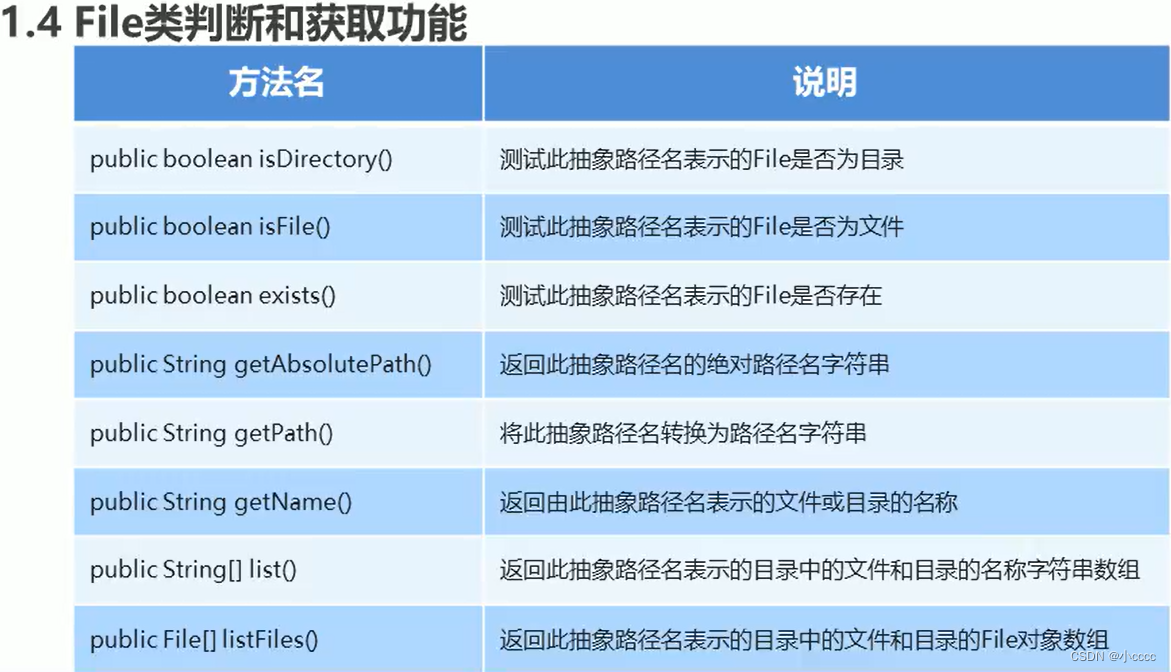
3.File类判断和获取功能
4.File类删除功能
public boolean delete():删除由此抽象路径名表示的文件或目录
注意:非空目录是无法直接使用delete()直接删除的,需要删除目录下的所有内容才能对该目录进行删除
5.绝对路径和相对路径的区别
绝对路径:完整的路径名,不需要任何其他信息就可以定位它所表示的文件。例如:"D:\\test\\JavaSE\\java.txt
相对路径:必须使用取自其他路径名的信息进行解释。例如:“JavaSE\\java.txt”
6.递归
递归概述:以编程的角度看,递归指的是方法定义中调用方法本身的现象
递归解决问题的思路:
把一个复杂的问题层层转化为一个与原问题相似却规模较小的问题来求解
递归策略只需少量的程序就可以描述过程所需要的多次重复的计算
递归解决问题要找到两个内容:
递归出口:否则会出现内存溢出
递归规则:与原问题相似的规模较小的问题
字节流
1.IO流概述和分类
IO流概述:
IO:输入/输出(Input/Output)
流:是一种抽象概念,是对数据传输的总称。也就是说数据在设备之间的传输成为流,流的本质是数据传输
IO流就是用来处理设备间数据传输问题的
常见的应用:文件复制;文件上传;文件下载
IO流分类:
按照数据的流向:
输入流:读数据
输出流:写数据
按照数据类型来分:
字节流
字节输入流;字节输出流
字符流
字符输入流;字符输出流
2.字节流写数据
字节流抽象基类
InputStream:这个抽象类是表示字节输入流的所有类的超类
OutputStream:这个抽象类是表示字节输出流的所有类的超类
其子类名称都是以七父类名作为子类名的后缀
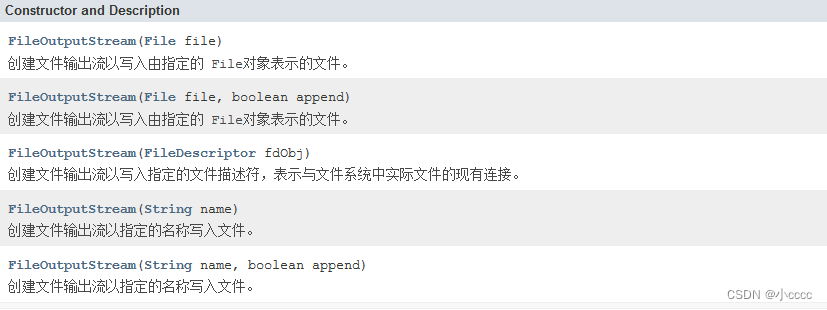
FileOutputStream:文件输出流用于将数据写入File
FileOutputStream(String name):创建文件输出流以指定的名称写入文件
FileOutputStream的构造方法:
FileOutputStream的常用方法:

使用字节输出流写数据的步骤:
1.创建字节流输出对象(A:创建了指定路径的文件;B:创建了字节输出流对象;C:让字节输出流对象指向创建好的文件)
2.调用数据输出流对象的写数据方法
3.释放资源(关闭此文件输出流并释放与此流相关联的任何系统资源)
3.字节流写数据的三种方式

获取数据的重要方法:byte[ ] getBytes():返回字符串对应的字节数组
4.字节流写数据的两个小问题
1.字节流写数据如何实现换行:
Windows换行符是:\r\n
Linux是:\n
Mac是:\r
2.字节流写数据如何实现追加写入:
FileOutputStream(String name, boolean append)方法和FileOutputStream(File file, boolean append)方法能提供追加写入
若第二个参数boolean类型的为true,则进行追加写入操作;若为false,则删除当前的所有内容并重新写入
5.字节流写数据加异常处理
finally:在异常处理时提供finally块来执行所有清除操作,比如IO流种的释放资源
finally特点:被finally控制的语句一定会被执行,除非JVM退出
6.字节流读数据<1>
FileInputStream:从文件系统中的文件获取输入字节
FileInputStream(String name):通过打开与实际文件的连接来创建一个FileInputStream,该文件由文件系统中的路径名name命名
连续使用read方法可以连续对下一个字符进行读取操作
该方法是一次读一个字节
//创建一个读取文件的对象
FileInputStream fIpS = new FileInputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_2\\fIpS_1.txt");
//调用该对象的读取方法
//字节流读数据的标准代码
int read;
while((read = fIpS.read()) != -1) {
System.out.print((char) read);
}
//关闭此文件输入流并释放与流相关联的任何系统资源
fIpS.close();
7.字节流读数据<2>
使用字符数组的read方法返回的是所读取的字符长度,若read方法没有接收到Byte数组内的元素,返回-1
FileInputStream fIpS = new FileInputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_2\\TEST.txt");
//定义字节数组时,数组长度基本定义为1024及其整数倍
byte []bytes = new byte[1024];
int len;
//使用字符数组的read方法返回的是所读取的字符长度
//使用字符数组的read的典型方法
while ((len = fIpS.read(bytes)) != -1) {
System.out.print(new String(bytes, 0, len));
}
8.字节缓冲流
Class BufferedOutputStream:该类实现缓冲输出流。通过设置这样的输出流,应用程序可以向底层输出流写入字节,而不必为写入的每个字节导致底层系统的调用。
构造方法:BufferedOutputStream(OutputStream out)
Class BufferedInputStream:当创建BufferedInputStream时,将创建一个内部缓冲区数组。 当从流中读取或跳过字节时,内部缓冲区将根据需要从所包含的输入流中重新填充,一次有多个字节。 mark操作会记住输入流中的一点,并且reset操作会导致从最近的mark操作之后读取的所有字节在从包含的输入流中取出新的字节之前重新读取。
构造方法:BufferedInputStream(InputStream in)
字节缓冲流仅仅提供缓冲区,而真正的读写数据还得依靠基本的字节流对象进行操作
//复制视频
public class BufferedStream__1 {
public static void main(String[] args) throws IOException {
FileInputStream In = new FileInputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_2\\vdo.mp4");
FileOutputStream Out = new FileOutputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_2\\vdo_1.mp4");
BufferedInputStream in = new BufferedInputStream(In);
BufferedOutputStream out = new BufferedOutputStream(Out);
byte[] bytes = new byte[1024];
int len;
while((len = in.read(bytes)) != -1)
{
out.write(bytes, 0, len);
}
}
}
字符流
一个汉字的存储:
如果是GBK编码,占用2个字节
如果是UTF-8编码,占用3个字节
1.为什么会出现字符流
字符流 = 字节流 + 编码表
汉字在存储的时候,无论选择哪种编码存储,第一个字节都是负数
2.编码表
基础知识
计算机中存储的信息都是用二进制数表示的;我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果
按照某种规则,将字符存储到计算机中,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析出来,称为解码。且按照A编码储存,必须按照A编码解析,这样才能显示正确的文本符号,否则就会出现乱码现象
字符编码:就是一套自然语言的字符与二进制数之间的对应规则
字符集
是一个系统支持的所有字符的集合,包括各个国家的文字、标点符号、图形符号、数字等
计算机要准确的存储和识别各种字符集符号,就需要进行编码,一套字符集必然至少有一套字符编码
常见字符集有:ASCII字符集、GBXXX字符集、Unicode字符集等
3.字符串的编码解码问题
编码:
byte[ ] getBytes( ):使用平台的默认字符集将该String编码为一系列字节,将结果存储到新的字节数组中
byte[ ] getBytes(String charsetName):使用指定的字符集将该String编码为一系列字节,将结果存储到新的字节数组中
解码:
String(byte[ ] bytes):通过使用平台的默认字符集解码指定的字节数组来构造新的String
String(byte[ ] bytes, String charsetName):通过指定的字符集解码指定的字节数组来构造新的String
4.字符流的编码解码问题
字符流抽象基类:
Reader:字符输入流的抽象类
Writer:字符输出流的抽象类
字符流中和编码解码问题相关的两个类:
InputStreamReader:InputStreamReader是从字节流到字符流的桥:它读取字节,并使用指定的charset将其解码为字符 。它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集。
InputStreamReader的构造方法:
-
-
InputStreamReader(InputStream in) 创建一个使用默认字符集的InputStreamReader。 |
|---|
InputStreamReader(InputStream in, Charset cs) 创建一个使用给定字符集的InputStreamReader。 |
OutputStreamWriter:OutputStreamWriter是字符的桥梁流以字节流:向其写入的字符编码成使用指定的字节charset。它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集。
OutputStreamWriter的构造方法:
-
-
OutputStreamWriter(OutputStream out) 创建一个使用默认字符编码的OutputStreamWriter。 |
|---|
OutputStreamWriter(OutputStream out, Charset cs) 创建一个使用给定字符集的OutputStreamWriter。 |
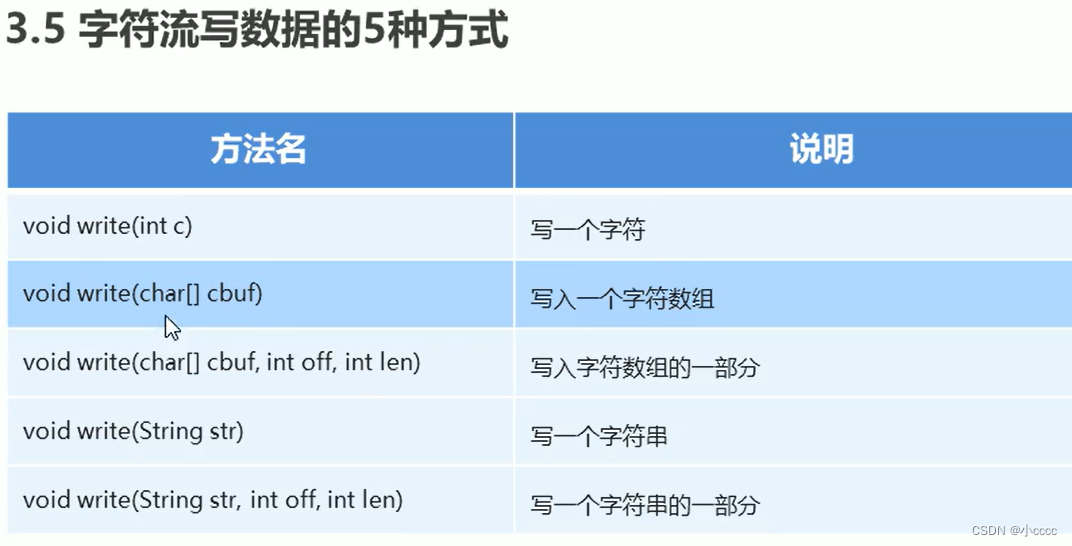
5.字符流写数据的5种方式
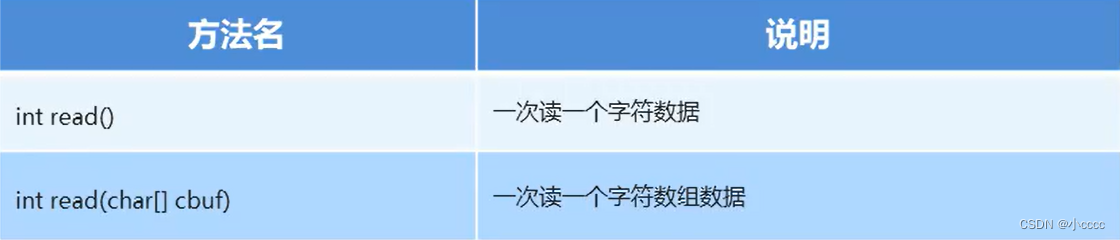
6.字符流读数据的2种方式
7.InputStreamReader与OutputStreamWriter的子类
InputStreamReader拥有一个子类:FileReader中的构造方法,FileReader(String fileName)可以减少文字的输入量
OutputStreamWriter拥有一个子类:FileWriter中的构造方法,FileWriter(String fileName)可以减少文字的输入量
注意:若要实现编码转换问题,还是得需要InputStreamReader与OutputStreamWriter
8.字符缓冲流
BufferedReader:从字符输入流读取文本,缓冲字符,以提供字符,数组和行的高效读取。
相关构造方法:
-
-
BufferedReader(Reader in) 创建使用默认大小的输入缓冲区的缓冲字符输入流。 |
|---|
BufferedReader(Reader in, int sz) 创建使用指定大小的输入缓冲区的缓冲字符输入流。 |
BufferedWriter:将文本写入字符输出流,缓冲字符,以提供单个字符,数组和字符串的高效写入。
相关构造方法:
-
-
BufferedWriter(Writer out) 创建使用默认大小的输出缓冲区的缓冲字符输出流。 |
|---|
BufferedWriter(Writer out, int sz) 创建一个新的缓冲字符输出流,使用给定大小的输出缓冲区。 |
9.字符缓冲流的特有功能
BufferedWriter:
void newLine( ):写一行行分隔符,行分隔符字符由系统属性定义;例:如果该电脑系统为Windows则添加一个"\r\n"字符串,Linux则添加"\n"字符串,Mac OS则添加"\r"字符串
BufferedReader:
public String readLine( ):读一行文字。结果包含行的内容的字符串,不包括任何行终止符。如果流的结尾已经到达,则为null
10.IO流小结
**1.字节流:**字节流可以复制任意文件数据,有4种方式一般采用字节缓冲流一次读写一个字节数组的方式:FileInputStream,BufferedInputStream;FileOutputStream,BufferedOutputStream
**2.字符流:**字符流只能复制文本数据,有五种方式,一般采用字符缓冲流的特有功能BufferedReader中的String readLine()方法,与BufferedWriter中的void newLine()方法
特殊操作流
1.标准输入输出流
System类中有两个静态的成员变量:
public static final InputStream in:标准输入流。通常该流对应于键盘输入或由主机环境或用户指定的另一个输入源
public static final PrintStream out:标准输出流。通常该流对应于演示输出或由主机环境或用户指定的另一个输出目标
自己实现键盘录入数据:
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Java提供的一个类实现了该方法:
Scanner sc = new Scanner(System.in);
输出语句的本质是一个标准的输出流
PrintStream ps = System.out;
PrintStream类有的方法,System.out都可以使用
2.打印流
打印流分类:
字节打印流:PrintStream
字符打印流:PrintWriter
打印流的特点:
只负责输出数据,不负责读取数据
有自己的特有方法print( ),println( )
字节打印流:
PrintStream(String fileName):使用指定的文件名创建新的打印流
使用继承父类的方法写数据,查看的时候会转码;使用自己的特有方法写数据,查看的数据原样输出
字符打印流:
字符打印流的构造方法:
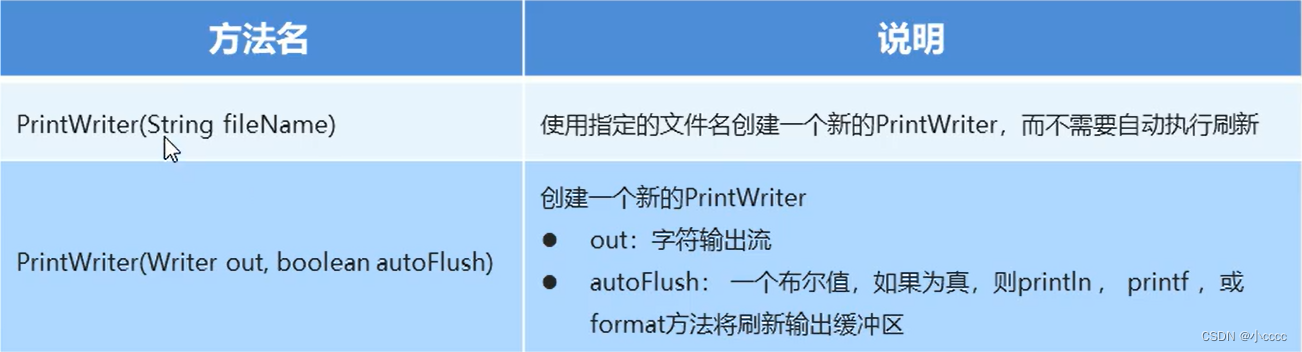
3.对象序列化流
对象序列化:就是将对象保存到磁盘中,或者在网络中传输对象
这种机制就是一个字节序列表示一个对象,该字节序列包含:对象的类型、对象的数据和对象中储存的属性等信息
字节序列写到文件之后,相当于文件中持久保存了一个对象的信息;反之,该字节序列还可以从文件中读取出来,重构对象,对它进行反序列化
要实现序列化和反序列化就要使用对象序列化流和对象反序列化流:
对象序列化流:ObjectOutputStream
对象反序列化流:ObjectInputStream
对象序列化流:
- ObjectOutputStream将Java对象的原始数据类型和图形写入OutputStream。 可以使用ObjectInputStream读取(重构)对象。 可以通过使用流的文件来实现对象的持久存储。 如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象。
构造方法:
ObjectOutputStream(OutputStream out):创建一个写入指定的OutputStream的ObjectOutputStream
序列化对象的方法:
void writeObject(Object obj):将指定的对象写入ObjectOutputStream
注意:
一个对象要想被序列化,该对象所属的类必须实现Serializable接口
Serializable是一个标记接口,实现该接口,不需要重写任何方法
4.对象反序列化流
对象反序列化流:ObjectInputStream
ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象
构造方法:
ObjectInputStream(InputStream in):创建从指定的InputStream读取的ObjectInputStream
反序列化对象的方法:
Object readObject( ):从ObjectInputStream读取一个对象
5.关于序列化反序列化的两个问题
用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据会不会出问题,若出了问题,该如何解决
会出问题,会抛出InvalidClassException异常,该异常是在
- 当序列化运行时检测到类中的以下问题之一时抛出。
- 类的串行版本与从流中读取的类描述符的类型不匹配
- 该类包含未知的数据类型
- 该类没有可访问的无参数构造函数
为什么会导致类的串行版本与从流中读取的类描述符的类型不匹配
因为序列化运行时将每个可序列化的类与称为serialVersionUID的版本号相关联,该序列号在反序列化期间用于验证序列化对象的发送者和接收者是否已加载与该序列化兼容的对象的类。 如果接收方加载了一个具有不同于相应发件人类的serialVersionUID的对象的类,则反序列化将导致InvalidClassException 。
解决方案:
-
序列化运行时将每个可序列化的类与称为serialVersionUID的版本号相关联,该序列号在反序列化期间用于验证序列化对象的发送者和接收者是否已加载与该序列化兼容的对象的类。 如果接收方加载了一个具有不同于相应发件人类的serialVersionUID的对象的类,则反序列化将导致InvalidClassException 。 一个可序列化的类可以通过声明一个名为"serialVersionUID"的字段来显式地声明它自己的serialVersionUID,该字段必须是静态的,而且类型为long
-
就是给对象所属的类添加一个serialVersionUID:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果一个对象中的某个成员变量的值不想被序列化,该如何实现
使用transient关键字修饰成员变量,被transient关键字修饰的成员变量不参与序列化过程
6.序列化反序列化的相关操作
public class ObjectOutputStudentStream_1 {
//注意被序列化的类需要实现一个Serializable的标记接口
public static void main(String[] args) throws IOException {
//对象序列化流的构造方法:ObjectOutputStream(OutputStream out)
ObjectOutputStream obps = new ObjectOutputStream(new FileOutputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_5\\St_oc.txt"));
//创建Student类的对象
Student s1 = new Student("Li", 18);
//将Student对象写入ObjectOutputStream:void writeObject(Object obj)
obps.writeObject(s1);
obps.close();
}
}
public class ObjectInputStudentStream_1 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
//反序列化流的构造方法:ObjectInputStream(InputStream in)
ObjectInputStream obis = new ObjectInputStream(new FileInputStream("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_5\\St_oc.txt"));
//反序列化对象的方法:Object readObject()
//进行向下转型
Student s1 = (Student) obis.readObject();
//调用反序列化后的Student对象
System.out.println(s1.getName()+", "+s1.getAge());
obis.close();
}
}
7.Properties
Properties概述:
是一个Map体系的集合类,但不是泛型类
Properties可以保存到流中或从流中加载
Properties的特有方法:
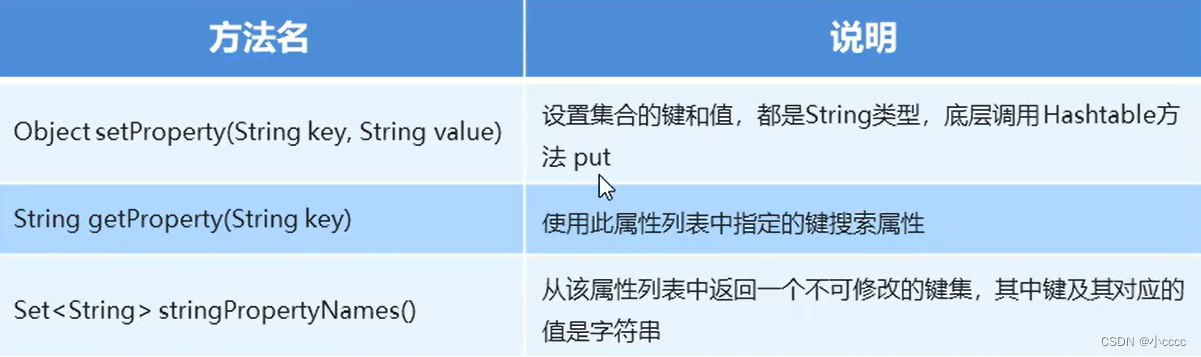
Properties和IO流结合的方法:

8.Properties的具体操作
public class Properties_1 {
public static void main(String[] args) throws IOException{
//定义一个将键值对写入Properties列表并写入文件中的方法
myStore();
//定义一个将键值对文件读取的列表
myLoad();
}
private static void myStore() throws IOException
{
//定义一个Properties列表并添加键值对
Properties prop = new Properties();
prop.setProperty("Li", "18");
prop.setProperty("Mo", "18");
prop.setProperty("Ja", "19");
//定义一个字符输出流
FileWriter writer = new FileWriter("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_5\\prop_1.txt");
//将键值对写入Properties列表
prop.store(writer, null);
writer.close();
}
private static void myLoad() throws IOException
{
//定义一个Properties列表
Properties prop = new Properties();
//定义一个字符输入流
FileReader reader = new FileReader("D:\\IdeaProjects\\untitled1\\untit__IO\\src\\Day_5\\prop_1.txt");
//Properties列表从字符输入流读取键值对
prop.load(reader);
reader.close();
//输出Properties列表的内容
System.out.println(prop);
}
}