【Python】多分类算法—Random Forest
本文将主要就Random Forest(随机森林)的多分类应用进行描述,当然也可运用于二分类中。本文运用scikit-learn框架。
一、导入基础库
导入数据处理和绘图的相关库,为使层次更加分明,将在后面再导入scikit-learn框架。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
二、数据读取及处理
1.数据读取
从csv文件中读取设备数据,代码如下:
# 读取数据
dataset = pd.read_csv('test_data.csv')
print(dataset)
数据形式大概如下,x为设备数据,class为数据特征,这里分为三类:
(真实数据不便展示,截图只是做展示,这里可下载iris鸢尾花数据集https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data)

2.数据处理
接下来进行数据预处理,将x作为自变量X,class作为自变量y。
# 数据预处理 选择自变量x 因变量y
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
三、基于scikit-learn的随机森林
1.训练集和测试集
利用scikit-learn中的train_test_split模块将数据拆分为训练集和测试集。
# 将数据集拆分为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)
2.标准化
为消除数据差值太大带来的影响,利用StandardScaler进行标准化,突出数据集的特征。
# 数据标准化 特征标度
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
3.训练
在scikit-learn中,采用随机森林模块RandomForestClassifier,对训练数据进行训练。
n_estimators表示随机森林中树的数量, criterion='entropy’表示选用entropy信息熵来寻找节点和分枝, random_state表示随机模式参数。
from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier(n_estimators=50, criterion='entropy', random_state=42)
classifier.fit(X_train, y_train)
print("X_train:", X_train)
print("y_train:", y_train)
3.预测
在模型训练好后,利用测试数据集进行预测。对测试集的分类实质上是通过测试集数据去预测因变量y,即表格中的class。
y_pred = classifier.predict(X_test)
print("X_test:", X_test)
print("y_pred:", y_pred)
4.输出结果
最后采用scikit-learn中自带的分类器将预测结果输出,包括confusion matrix、Classification Report、Accuracy。
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
result = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(result)
result1 = classification_report(y_test, y_pred)
print("Classification Report:", )
print(result1)
result2 = accuracy_score(y_test, y_pred)
print("Accuracy:", result2)
从confusion matrix的结果可以看出,分类0被抽取的随机数量为62,预测准确数量为62;分类1被抽取的数量为240,预测准确数量为232;分类2被抽取的数量为33,预测准确数量为33。

precision表示准确率,recall表示召回率,f1-score表示precision和recall的调和平均值。

Accuracy为随机森林分类的准确性,结果表明准确率为97.6%。
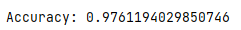
总结。
本文主要介绍了随机森林进行多分类的大致步骤,准确率还算不错,关于RandomForestClassifier中的具体参数设置可以参考官网教程sklearn.ensemble.RandomForestClassifier。