摘要:
flink1.13.0 整合 Hudi 0.11.1 ,通过FlinkSQL程序、FlinkSQL命令行对Hudi的MOR及COW进行批量写、流式写、流式读取、批量读取。通过flink sql cdc 、flink sql kafka 、flink stream kafka 探究流式数据入Hudi案例。
探究Hudi和Hive的整合,怎么通过hive查询管理Hudi表。第1种是在hive 创建Hudi 外部表,手动加分区的形式;第2种是通过FlinkSQL程序和FlinkSQL命令行在写Hudi的时候就同步Hive;第3种是使用Hudi自带的工具run_sync_tool.sh进行同步。
探究hive数仓的数据怎么入到Hudi。
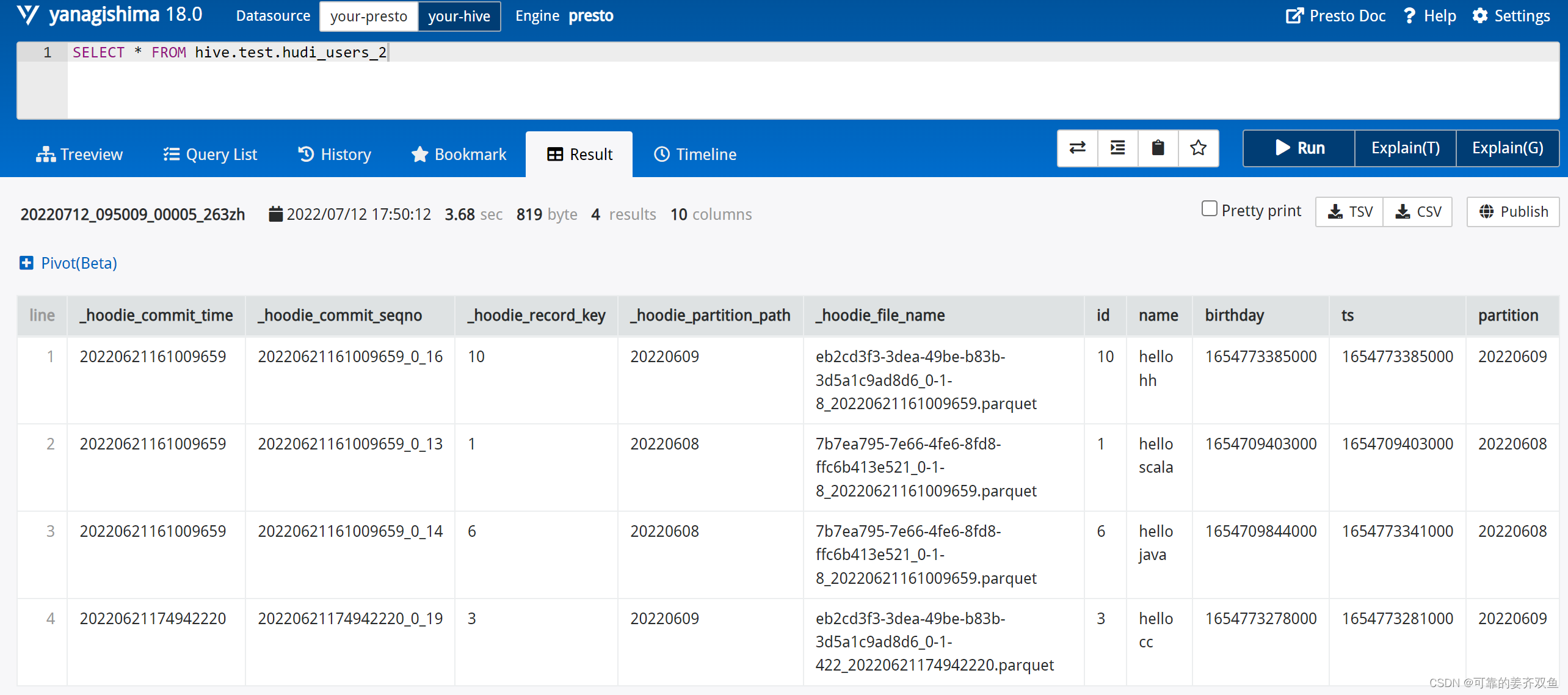
使用presto客户端查询Hudi数据,使用DBeaver 连接Presto查询Hudi数据。
使用yanagishima 界面化查询Hudi数据。
组件版本
flink 1.13.0
scala 2.11
hudi 0.11.1
hive 2.1.1
cdh 6.3.2
1.FlinkSQL程序入Hudi
1.1 flink-cdc 入 hudi
1.1.1 hive手动建表,手动同步分区
1.1.1.1 mysql cdc 入 hudi cow 表
1.1.1.1.1 在mysql 创建表,并初始化插入几条数据
use test;
-- ----------------------------
-- Table structure for users
-- ----------------------------
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`birthday` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of users
-- ----------------------------
INSERT INTO `users` VALUES ('1', 'hello scala', '2022-06-08 17:30:03', '2022-06-08 17:30:03');
INSERT INTO `users` VALUES ('2', 'bb', '2022-09-09 11:29:42', '2022-09-09 11:29:45');
INSERT INTO `users` VALUES ('3', 'hello cc', '2022-06-09 11:14:38', '2022-06-09 11:14:41');
INSERT INTO `users` VALUES ('4', 'aa', '2022-06-10 15:29:57', '2022-06-10 15:30:01');
INSERT INTO `users` VALUES ('5', '55', '2022-09-09 11:38:30', '2022-09-09 11:38:34');
INSERT INTO `users` VALUES ('6', ' hello java', '2022-06-08 17:37:24', '2022-06-09 11:15:41');
INSERT INTO `users` VALUES ('10', 'hello hh', '2022-06-09 11:16:25', '2022-06-09 11:16:25');
INSERT INTO `users` VALUES ('11', 'eee', '2022-06-21 12:02:10', '2022-06-21 12:02:10');
1.1.1.1.2 编写程序
新建maven项目flink-hudi
pom文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>work.jiang</groupId>
<artifactId>flink_hudi</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<scala.version>2.11</scala.version>
<flink.version>1.13.0</flink.version>
<hudi.version>0.11.1</hudi.version>
</properties>
<dependencies>
<!-- table start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.8.3-10.0</version>
<!-- <scope>provided</scope>-->
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
<exclusions>
<exclusion>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
</exclusion>
<exclusion>
<groupId>org.lz4</groupId>
<artifactId>lz4-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
<exclusions>
<exclusion>
<artifactId>slf4j-api</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.2.0</version>
</dependency>
<!-- hudi start -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink1.13-bundle_2.11</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-hadoop-mr-bundle</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-hive-2.2.0_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.10.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
将hive、hdfs的配置文件拷贝到项目
新建类 work.jiang.hudi.cdc.cow.FlinkcdcToHudiCOWTable
package work.jiang.hudi.cdc.cow;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* 参考连接:https://blog.csdn.net/Aaron_ch/article/details/124147649
* Hudi --COW表 mysql 每修改一条记录,hudi就新增加一个parquet文件
* 在hive查询的时候,查的是最新的那个parquet文件(是可以查到最新数据的,是写放大,会生成很多parquet文件),也是需要在hive手动增加分区
*/
public class FlinkcdcToHudiCOWTable {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "hdfs");
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
bsEnv.setParallelism(1);
// 每 1000ms 开始一次 checkpoint
bsEnv.enableCheckpointing(1000);
bsEnv.setParallelism(1);
StreamTableEnvironment env = StreamTableEnvironment.create(bsEnv, bsSettings);
// 1. 新建Flink MySQL CDC表
env.executeSql("CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '172.16.43.159',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '*',\n" +
" 'server-time-zone' = 'Asia/Shanghai',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 'users'\n" +
// " 'scan.incremental.snapshot.enabled' = 'false'\n" +
" )");
// 2. 新建Flink Hudi表
env.executeSql("CREATE TABLE hudi_users23 (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'COPY_ON_WRITE',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users23',\n" +
" 'write.insert.drop.duplicates' = 'true',\n" +
" 'write.tasks' = '1' \n" +
")");
//3.mysql-cdc 写入hudi ,会提交有一个flink任务
env.executeSql("INSERT INTO hudi_users23 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users");
env.executeSql("select * from hudi_users23").print();
}
}
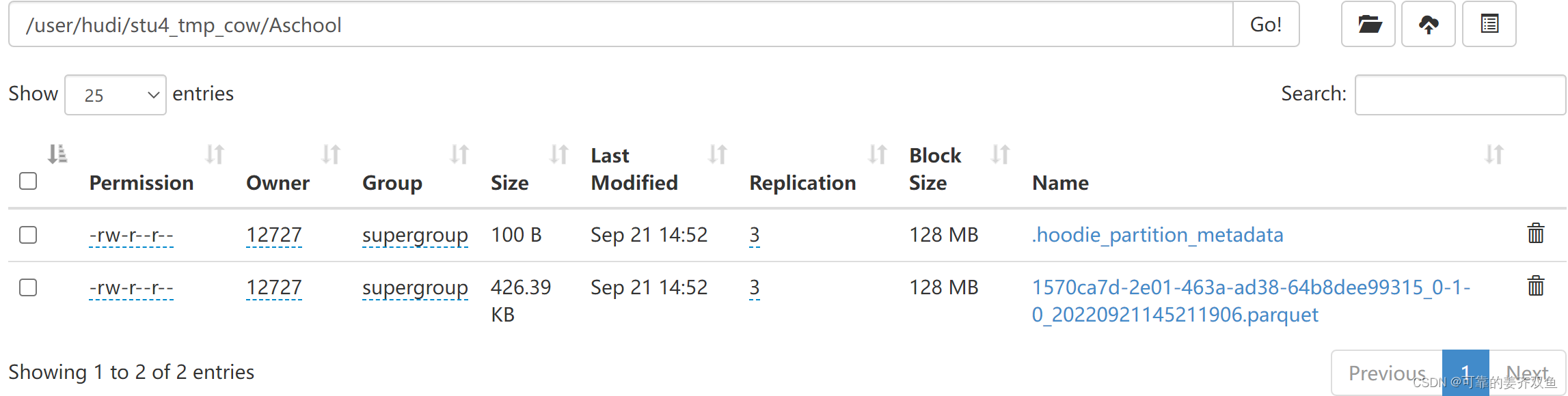
1.1.1.1.3 运行程序,查看hdfs目录
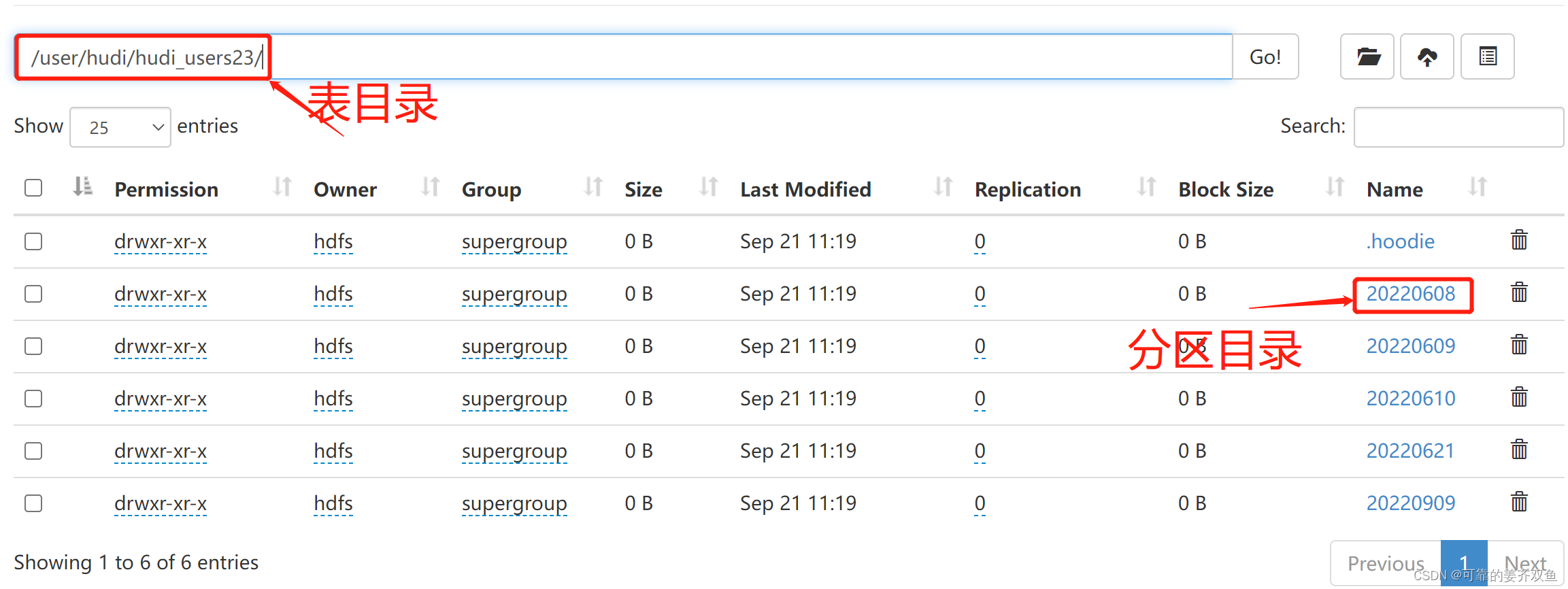
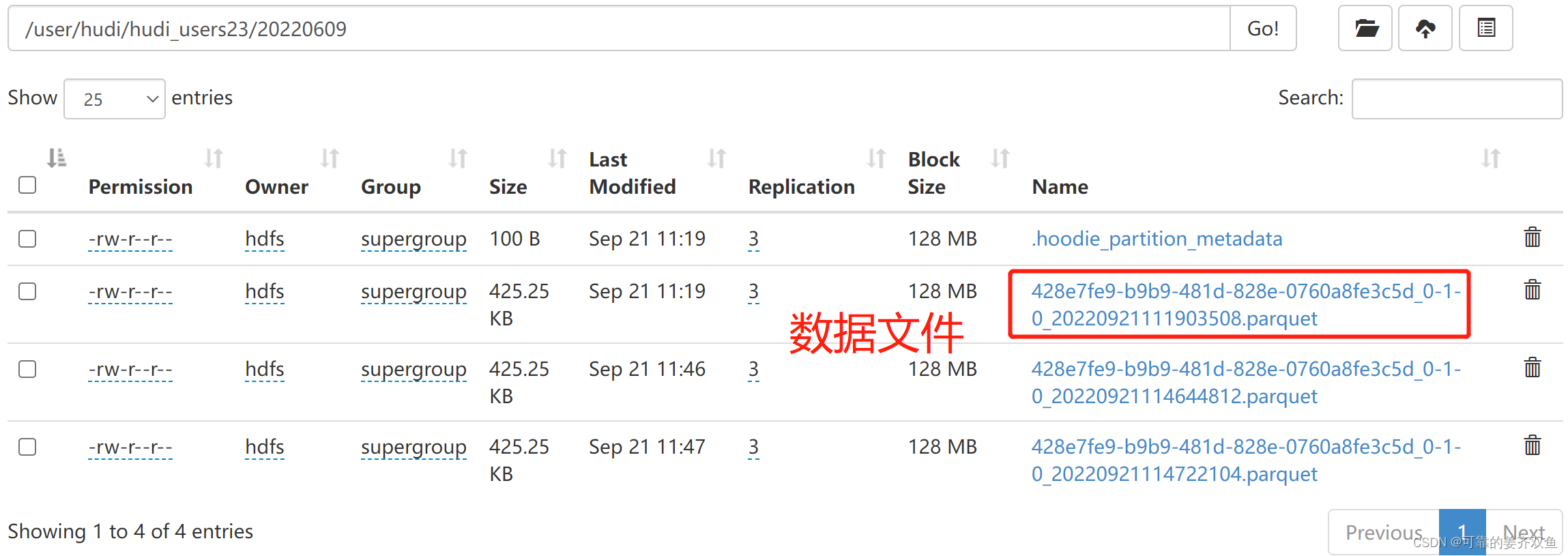
运行程序,此时在hdfs目录 /user/hudi/ 下新生成了hudi_users23表目录
1.1.1.1.4 在hive 创建hudi 外部表
hive> add jar /home/bonc/hudi-hive-sync-bundle-0.11.1.jar;
hive> add jar /home/bonc/hudi-hadoop-mr-bundle-0.11.1.jar;
hive> use hudi_db;
hive> CREATE EXTERNAL TABLE `hudi_users_23`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://cdh01:8022/user/hudi/hudi_users23';
需要手动添加分区
hive> alter table hudi_users_23 add if not exists partition(`partition`='20220608') location 'hdfs://cdh01:8022/user/hudi/hudi_users23/20220608';
hive> alter table hudi_users_23 add if not exists partition(`partition`='20220609') location 'hdfs://cdh01:8022/user/hudi/hudi_users23/20220609';
查询hudi_users_23
hive> select * from hudi_users_23;
查询结果,只能查到已经手动添加的分区
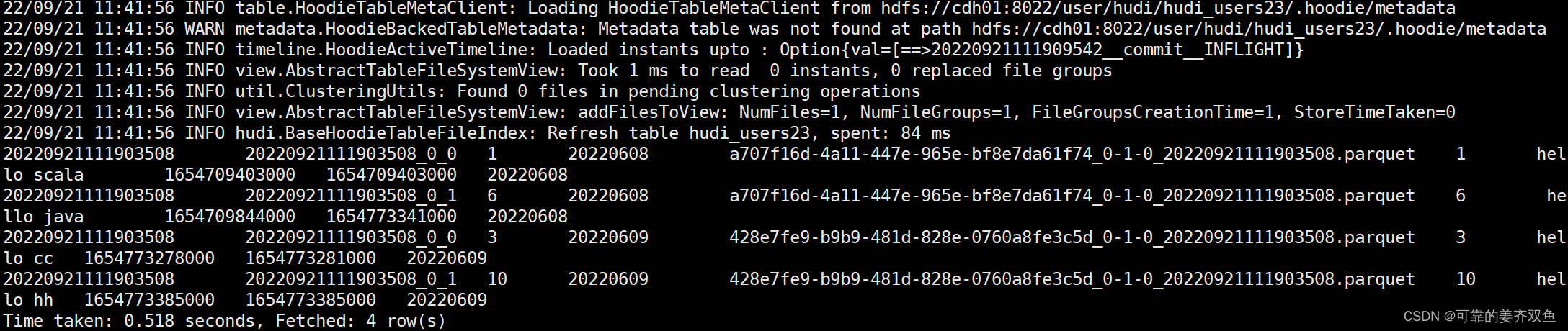
在mysql 新插入一条分区为20220608的数据,修改一条分区为20220608的数据,删除一条分区为20220608的数据,在hive里查询,看数据有没有更新
mysql> INSERT INTO `users` VALUES ('12', 'eee', '2022-06-08 12:02:10', '2022-06-08 12:02:10');
hive> select * from hudi_users_23;

mysql> update users set name = 'aa' where id = 12;
hive> select * from hudi_users_23;

mysql> delete from users where id = 12;
hive> select * from hudi_users_23;

结论:在mysql新插入、更新、删除已手动添加的分区的数据,会自动地向hive同步数据,在hive会实时更新数据
1.1.1.1 mysql cdc 入 hudi mor 表
1.1.1.1.1 在mysql 创建表,并初始化几条数据
同1.1.1.1.1
1.1.1.1.2 编写程序
创建类 work.jiang.hudi.cdc.mor.FlinkcdcToHudiMORTable
package work.jiang.hudi.cdc.mor;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* mysql cdc 入 hudi,在hive创建外部表进行查询
* 参考连接:https://blog.51cto.com/u_15458633/4829214
* 问题点:需要在hive手动创建外部表、手动创建分区
* 结论:
* hudi -- MOR表 会生成.hoodie(提交信息)、分区文件
* 分区文件里边有.hoodie_partition_metadata(元数据)、log(增量数据)、parquet(历史数据)文件
* hudi -- COW表 会生成.hoodie、分区文件
* 分区文件里边有.hoodie_partition_metadata(元数据)、parquet(历史数据)文件,每更新一次会重新生成一个parquet文件
* hive --- COW表(HoodieParquetInputFormat视图)只会读取到一开始程序运行的数据(历史数据,即parquet文件数据)
* hive --- MOR表(HoodieParquetRealtimeInputFormat视图)会读取实时更新的数据(即parquet + log 文件数据)
*/
public class FlinkcdcToHudiMORTable {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
env.setParallelism(1);
// 每 1000ms 开始一次 checkpoint,默认5次checkpoint才会生成parquet
// 重新运行程序得时候,会新生成一个parquet,这个时候是重新读取mysql表的全量数据
env.enableCheckpointing(5 * 1000);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
//1.创建 mysql cdc,流式读取
tableEnv.executeSql("CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '172.16.43.159',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '*',\n" +
" 'server-time-zone' = 'Asia/Shanghai',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 'users'\n" +
" )");
//2.创建hudi 表
tableEnv.executeSql("CREATE TABLE hudi_users3 (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users3',\n" +
" 'read.streaming.enabled' = 'true',\n" +
" 'read.streaming.check-interval' = '1', \n" +
" 'write.tasks' = '1' \n" +
")");
//3.mysql-cdc 写入hudi ,会提交有一个flink任务
tableEnv.executeSql("INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users");
tableEnv.executeSql("select * from hudi_users2").print();
}
}
1.1.1.1.3 运行程序,查看hdfs目录
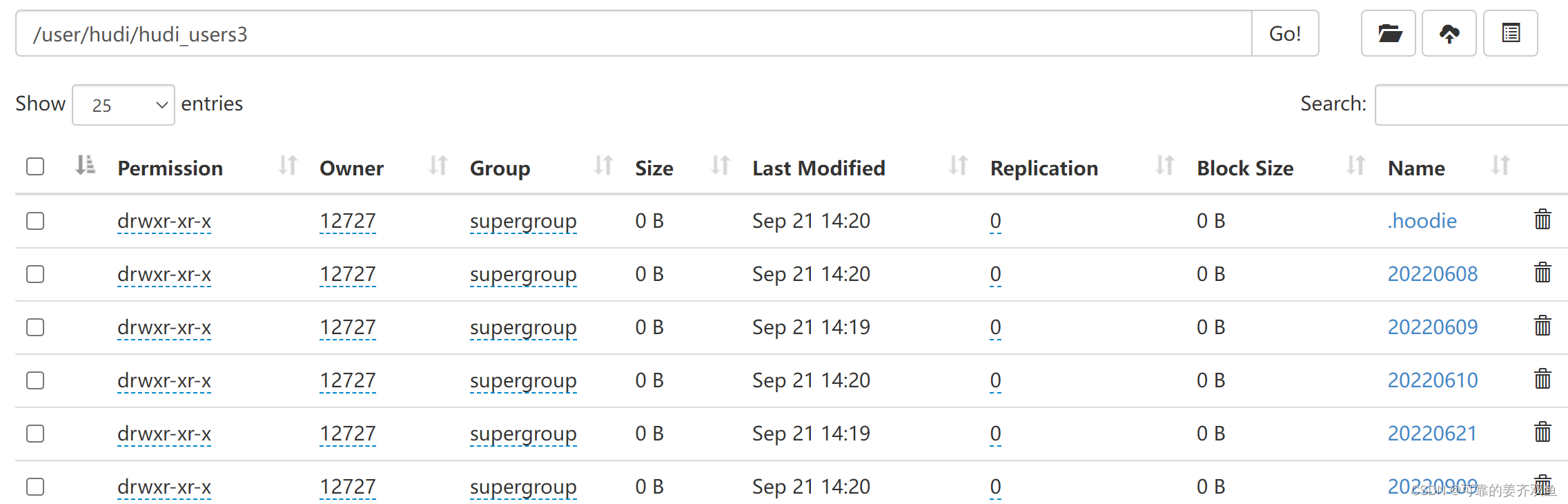
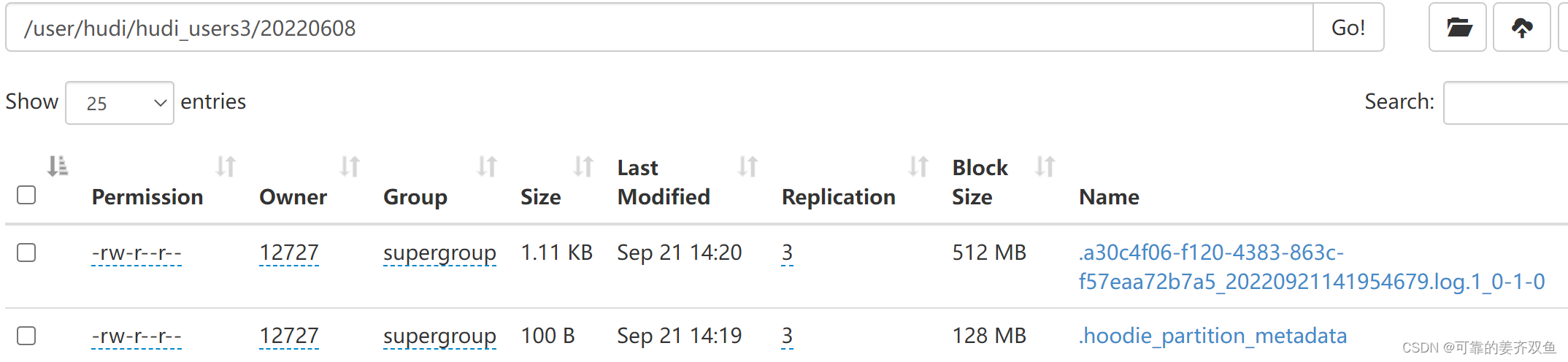
这里没有生成parquet文件,默认是5个commit才生会去压缩,可以修改下参数
tableEnv.executeSql("CREATE TABLE hudi_users3 (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users3',\n" +
" 'compaction.tasks'= '1', \n" +
" 'compaction.async.enabled'= 'true',\n" +
" 'compaction.trigger.strategy'= 'num_commits',\n" +
" 'compaction.delta_commits'= '1',\n" +
" 'changelog.enabled'= 'true',\n" +
" 'read.streaming.enabled' = 'true',\n" +
" 'read.streaming.check-interval' = '1', \n" +
" 'write.tasks' = '1' \n" +
")");
再运行程序,此时就有生成的压缩文件了
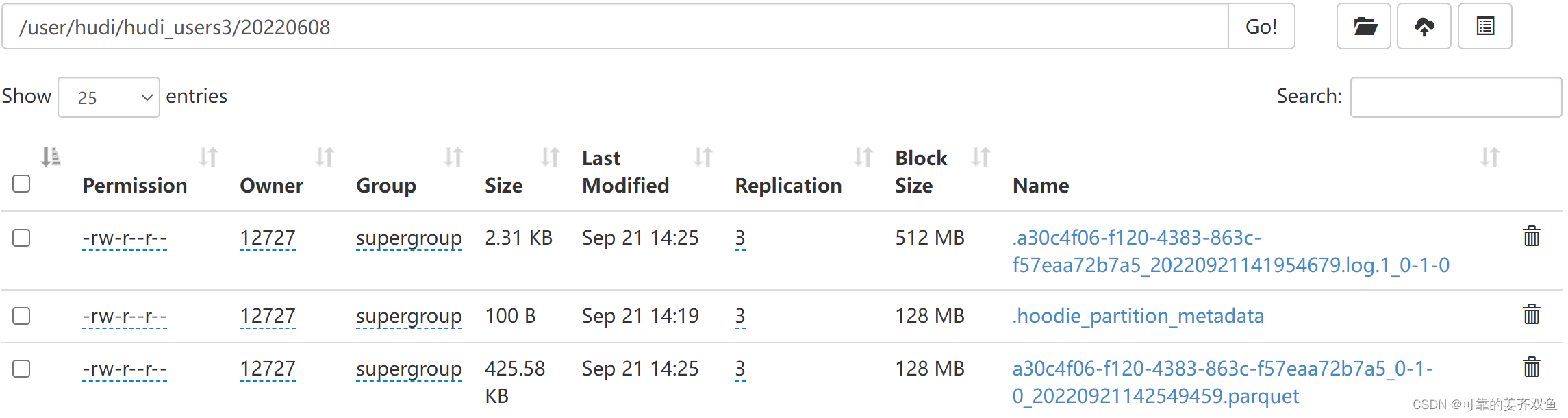
注意:没有parquet压缩文件,在hive将无法查询出数据
1.1.1.1.4 在hive 创建外部表
1.1.1.1.4.1COW表
hive> CREATE EXTERNAL TABLE `hudi_users_3`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://cdh01:8022/hudi/hudi_users3';
hive> alter table hudi_users_3 add if not exists partition(`partition`='20220608') location 'hdfs://cdh01:8022/user/hudi/hudi_users3/20220608';
hive> alter table hudi_users_3 add if not exists partition(`partition`='20220609') location 'hdfs://cdh01:8022/user/hudi/hudi_users3/20220609';
hive> select * from hudi_users_3 where `partition`=20220608;
hive> select * from hudi_users_3 where `partition`=20220609;
查询结果,只能查到已经手动添加的分区,且只能查询parquet文件,无法查询到最新写到log里边的数据

1.1.2.1.4.2 MOR表
hive> CREATE EXTERNAL TABLE `hudi_users_3_mor`(
`_hoodie_commit_time` string,
`_hoodie_commit_seqno` string,
`_hoodie_record_key` string,
`_hoodie_partition_path` string,
`_hoodie_file_name` string,
`id` bigint,
`name` string,
`birthday` bigint,
`ts` bigint)
PARTITIONED BY (
`partition` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://cdh01:8022/user/hudi/hudi_users3';
hive> alter table hudi_users_3_mor add if not exists partition(`partition`='20220608') location 'hdfs://cdh01:8022/user/hudi/hudi_users3/20220608';
hive> alter table hudi_users_3_mor add if not exists partition(`partition`='20220609') location 'hdfs://cdh01:8022/user/hudi/hudi_users3/20220609';
hive> select * from hudi_users_3_mor where `partition`=20220608;
hive> select * from hudi_users_3_mor where `partition`=20220609;
查询结果,只能查到已经手动添加的分区,可以查询历史的parquet + log文件,即可以实时查询数据

在mysql 新插入一条分区为20220608的数据,修改一条分区为20220608的数据,删除一条分区为20220608的数据,在hive里查询,看数据有没有更新
mysql> INSERT INTO `users` VALUES ('12', 'fff', '2022-06-08 12:02:10', '2022-06-08 12:02:10');
hive> select * from hudi_users_3;
hive> select * from hudi_users_3_mor;
```
```sql
mysql> update users set name = 'hhh' where id = 12;
hive> select * from hudi_users_3;
hive> select * from hudi_users_mor;
mysql> delete from users where id = 12;
hive> select * from hudi_users_3;
hive> select * from hudi_users_mor;
结论:在mysql新插入、更新、删除已手动添加的分区的数据,会自动地向hive同步数据,在hive会实时更新数据
cow表会向hive同步parquet文件的数据
mor表会向hive同步parquet + log文件的数据
因为我设置了
‘compaction.trigger.strategy’= ‘num_commits’
‘compaction.delta_commits’= ‘1’ --每几个数据一压缩
所以在cow也能看到实时变化的数据,默认是5次commit一压缩,如果不设置,cow表是看不到最新数据的变化的
1.1.2 flinksql自动建hive表,自动同步分区
1.1.2.1 mysql cdc 入 hudi cow表
1.1.2.1.1 在mysql创建表,并初始化插入几条数据
mysql> DROP TABLE IF EXISTS `stu4`;
mysql> CREATE TABLE `stu4` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`name` varchar(20) NOT NULL COMMENT '学生名字',
`school` varchar(20) NOT NULL COMMENT '学校名字',
`nickname` varchar(20) NOT NULL COMMENT '学生小名',
`age` int(11) NOT NULL COMMENT '学生年龄',
`score` decimal(4,2) NOT NULL COMMENT '成绩',
`class_num` int(11) NOT NULL COMMENT '班级人数',
`phone` bigint(20) NOT NULL COMMENT '电话号码',
`email` varchar(64) DEFAULT NULL COMMENT '家庭网络邮箱',
`ip` varchar(32) DEFAULT NULL COMMENT 'IP地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of stu4
-- ----------------------------
mysql> INSERT INTO `stu4` VALUES ('1', 'aa', 'Aschool', 'aa', '18', '70.00', '1', '12345', 'sdss@163.com', '12.12.12.12');
mysql> INSERT INTO `stu4` VALUES ('2', 'bb', 'Bschool', 'bb', '17', '70.00', '1', '123', '343', '1233');
mysql> INSERT INTO `stu4` VALUES ('4', 'cc', 'Cschool', 'cc', '19', '70.00', '1', '123', '123', '123');
1.1.2.1.2 编写程序
新建work.jiang.hudi.cdc.cow.FlinkcdcToHudiCOWTableAndSyncToHive
package work.jiang.hudi.cdc.cow;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FlinkcdcToHudiCOWTableAndSyncToHive {
public static void main(String[] args) throws Exception {
// System.setProperty("HADOOP_USER_NAME", "hdfs");
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(2 * 1000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
// 1. 新建Flink MySQL CDC表
tbEnv.executeSql("create table stu4(\n" +
" id bigint not null,\n" +
" name string,\n" +
" school string,\n" +
" nickname string,\n" +
" age int not null,\n" +
" score decimal(4,2) not null,\n" +
" class_num int not null,\n" +
" phone bigint not null,\n" +
" email string,\n" +
" ip string,\n" +
" PRIMARY KEY (id) NOT ENFORCED\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '172.16.43.159',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '*',\n" +
" 'server-time-zone' = 'Asia/Shanghai',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 'stu4'\n" +
" )");
// 2. 新建Flink Hudi表
tbEnv.executeSql("create table stu4_tmp_1(\n" +
" id bigint not null,\n" +
" name string,\n" +
" `school` string,\n" +
" nickname string,\n" +
" age int not null,\n" +
" score decimal(4,2) not null,\n" +
" class_num int not null,\n" +
" phone bigint not null,\n" +
" email string,\n" +
" ip string,\n" +
" primary key (id) not enforced\n" +
")\n" +
" partitioned by (`school`)\n" +
" with (\n" +
" 'connector' = 'hudi',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/stu4_tmp_cow',\n" +
" 'table.type' = 'COPY_ON_WRITE',\n" +
" 'write.precombine.field' = 'school',\n" +
" 'write.tasks'= '1',\n" +
" 'write.rate.limit'= '2000', \n" +
" 'compaction.tasks'= '1', \n" +
" 'compaction.async.enabled'= 'true',\n" +
" 'compaction.trigger.strategy'= 'num_commits',\n" +
" 'compaction.delta_commits'= '1',\n" +
" 'changelog.enabled'= 'true',\n" +
" 'hive_sync.enable' = 'true',\n" +
" 'hive_sync.mode' = 'hms',\n" +
" 'hive_sync.metastore.uris' = 'thrift://cdh01:9083',\n" +
" 'hive_sync.jdbc_url' = 'jdbc:hive2://cdh01:10000',\n" +
" 'hive_sync.table' = 'stu4_tmp_1',\n" +
" 'hive_sync.db' = 'hudi_db',\n" +
" 'hive_sync.username' = 'hive',\n" +
" 'hive_sync.password' = 'hive'\n" +
")");
//3.mysql-cdc 写入hudi ,会提交有一个flink任务
tbEnv.executeSql("insert into stu4_tmp_1 select * from stu4");
tbEnv.executeSql("select * from stu4_tmp_1").print();
}
}
1.1.2.1.3 运行程序查看hdfs目录

1.1.2.1.4 查询hive
hive> show tables;
hive> select * from stu4_tmp_1;
查询结果:在hive自动创建了一个表,名字和’hive_sync.table’ = ‘stu4_tmp_1’ 配置的一致,能够查询出来表的所有数据,实现了自动创建表,自动同步分区与数据

在mysql 增删改数据,查看hive数据是否更新
mysql> INSERT INTO `stu4` VALUES ('5', 'aa', 'Aschool', 'aa', '18', '70.00', '1', '12345', 'sdss@163.com', '12.12.12.12');
mysql> DELETE from `stu4` where id = '1';
mysql> update `stu4` set name = 'hhh' where id = 2;
hive> select * from stu4_tmp_1;
查询结果:hive表中的数据也实时更新了

1.1.2.2 mysql cdc 入 hudi mor表
1.1.2.2.1 在mysql创建表,并初始化插入几条数据
同1.1.1.1.1
1.1.2.2.2 编写程序
新建work.jiang.hudi.cdc.mor.FlinkcdcToHudiMORTableAndSyncToHive
package work.jiang.hudi.cdc.mor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* 已测通
* flinksql 数据写入 hudi,并自动同步创建hive分区表+自动同步数据
* 参考连接:https://blog.csdn.net/wudonglianga/article/details/122954751
* https://blog.csdn.net/wzp1986/article/details/125894473
* https://blog.csdn.net/xiaoyixiao_/article/details/125239236
* https://blog.csdn.net/yy8623977/article/details/123673316
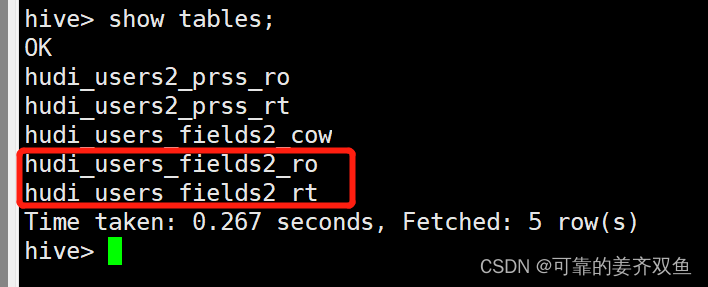
* 测试结果:会在hive里边创建两个表,hudi_users2_ro、hudi_users2_rt
* ro表示COW表,只会读取parquet格式的文件;rt表示MOR表,会读取parquet + log文件
* 如果需要查最新数据,需要查询MOR表
*/
public class FlinkcdcToHudiMORTableAndSyncToHive {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(10 * 10000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
//1.创建 mysql cdc,流式读取
tbEnv.executeSql("CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '172.16.43.159',\n" +
" 'port' = '3306',\n" +
" 'username' = 'root',\n" +
" 'password' = '*',\n" +
" 'server-time-zone' = 'Asia/Shanghai',\n" +
" 'database-name' = 'test',\n" +
" 'table-name' = 'users'\n" +
" )");
tbEnv.executeSql("CREATE TABLE hudi_users2(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8022/user/hudi/hudi_users2', \n" +
"'table.type'= 'MERGE_ON_READ',\n" +
"'hoodie.datasource.write.recordkey.field'= 'id', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'changelog.enabled'= 'true',\n" +
"'read.streaming.enabled'= 'true',\n" +
"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'hudi_users2',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
//3.mysql-cdc 写入hudi ,会提交有一个flink任务
tbEnv.executeSql("INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users");
tbEnv.executeSql("select * from hudi_users2").print();
}
}
1.1.2.2.3 运行程序查看hdfs目录
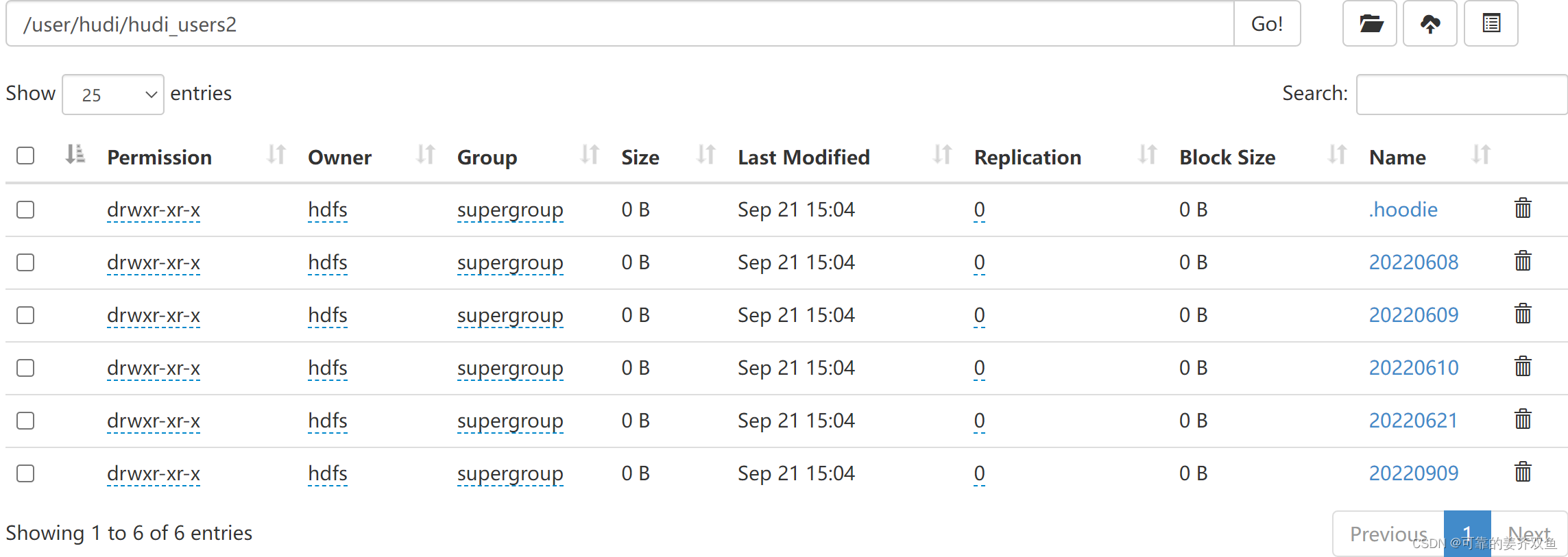
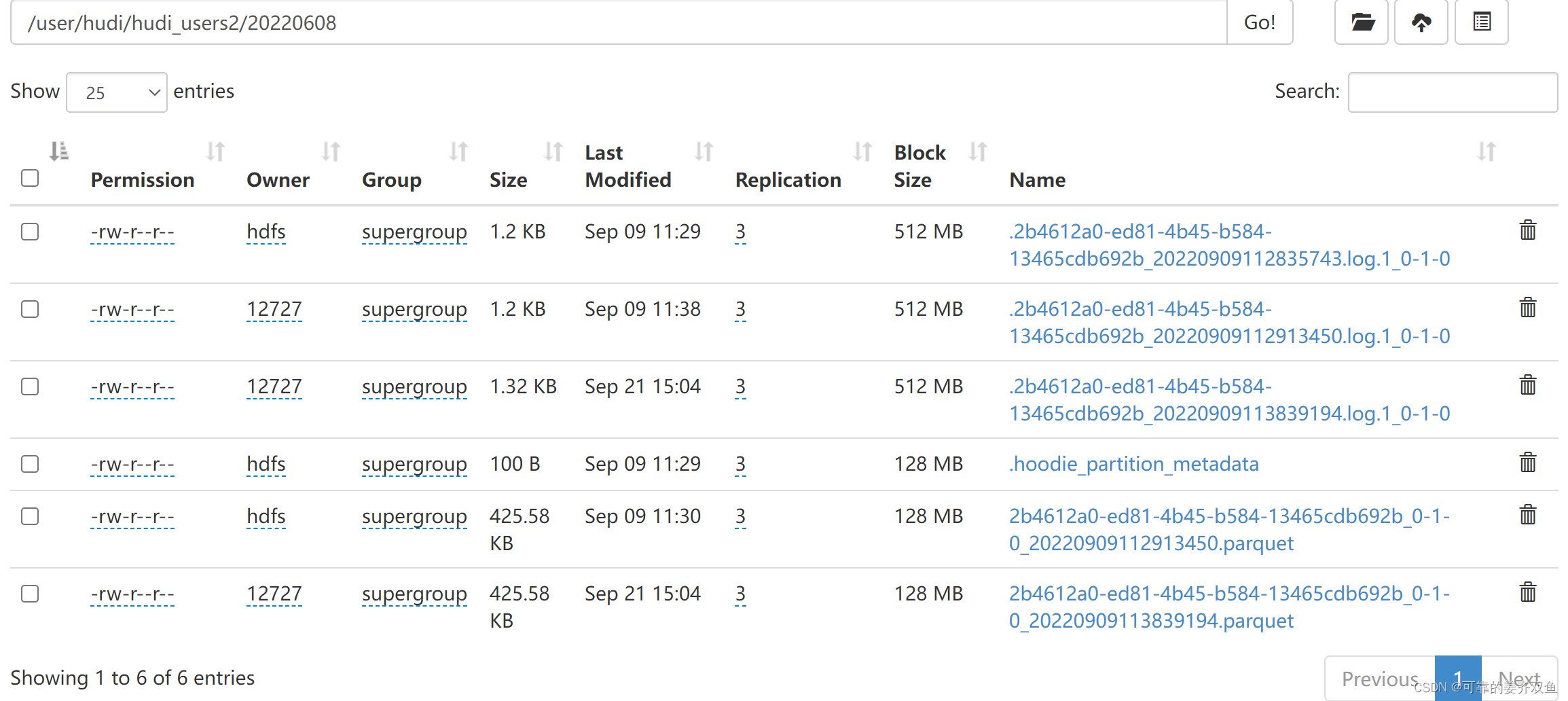
1.1.2.2.4 查询hive
自动生成了ro、rt两个表

hive> select * from hudi_users2_ro;
hive> select * from hudi_users2_rt;
查询结果,ro表可以查询parquet文件的数据,rt表可以查询parquet + log数据
查看两者的表结构,可以看到两者的INPUTFORMAT 解析类不一样
,ro是’org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat’
rt是’org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat’
hive> show create table hudi_users2_ro;
OK
CREATE EXTERNAL TABLE `hudi_users2_ro`(
`_hoodie_commit_time` string COMMENT '',
`_hoodie_commit_seqno` string COMMENT '',
`_hoodie_record_key` string COMMENT '',
`_hoodie_partition_path` string COMMENT '',
`_hoodie_file_name` string COMMENT '',
`_hoodie_operation` string COMMENT '',
`id` bigint COMMENT '',
`name` string COMMENT '',
`birthday` bigint COMMENT '',
`ts` bigint COMMENT '')
PARTITIONED BY (
`partition` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='true',
'path'='hdfs://cdh01:8022/user/hudi/hudi_users2')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://cdh01:8022/user/hudi/hudi_users2'
TBLPROPERTIES (
'last_commit_time_sync'='20220921150431744',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_operation","type":"string","nullable":true,"metadata":{}},{"name":"id","type":"long","nullable":false,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"birthday","type":"timestamp","nullable":true,"metadata":{}},{"name":"ts","type":"timestamp","nullable":true,"metadata":{}},{"name":"partition","type":"string","nullable":true,"metadata":{}}]}',
'spark.sql.sources.schema.partCol.0'='partition',
'transient_lastDdlTime'='1662694156')
Time taken: 0.4 seconds, Fetched: 32 row(s)
hive> show create table hudi_users2_rt;
OK
CREATE EXTERNAL TABLE `hudi_users2_rt`(
`_hoodie_commit_time` string COMMENT '',
`_hoodie_commit_seqno` string COMMENT '',
`_hoodie_record_key` string COMMENT '',
`_hoodie_partition_path` string COMMENT '',
`_hoodie_file_name` string COMMENT '',
`_hoodie_operation` string COMMENT '',
`id` bigint COMMENT '',
`name` string COMMENT '',
`birthday` bigint COMMENT '',
`ts` bigint COMMENT '')
PARTITIONED BY (
`partition` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'hoodie.query.as.ro.table'='false',
'path'='hdfs://cdh01:8022/user/hudi/hudi_users2')
STORED AS INPUTFORMAT
'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://cdh01:8022/user/hudi/hudi_users2'
TBLPROPERTIES (
'last_commit_time_sync'='20220921150431744',
'spark.sql.sources.provider'='hudi',
'spark.sql.sources.schema.numPartCols'='1',
'spark.sql.sources.schema.numParts'='1',
'spark.sql.sources.schema.part.0'='{"type":"struct","fields":[{"name":"_hoodie_commit_time","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_commit_seqno","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_record_key","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_partition_path","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_file_name","type":"string","nullable":true,"metadata":{}},{"name":"_hoodie_operation","type":"string","nullable":true,"metadata":{}},{"name":"id","type":"long","nullable":false,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"birthday","type":"timestamp","nullable":true,"metadata":{}},{"name":"ts","type":"timestamp","nullable":true,"metadata":{}},{"name":"partition","type":"string","nullable":true,"metadata":{}}]}',
'spark.sql.sources.schema.partCol.0'='partition',
'transient_lastDdlTime'='1662694157')
Time taken: 0.267 seconds, Fetched: 32 row(s)
在mysql进行增、删、改,数据也会自动同步到hudi,在hive里,ro表依旧是能够查询更新的parquet文件,rt表是能够查询更新的parquet + log文件
在mysql修改表结构,新增列,不会影响原来的程序
修改原有的列名,hudi原来的程序,有一列的结果会是null
删除原有的列,hudi原来的程序,有一列的结果会是null
1.2 flink-kafka 入 hudi 并自动同步hive
1.2.1 flink-kafka sql 入 hudi cow
1.2.1.1 创建kafka topic
cd /opt/cloudera/parcels/CDH/bin
kafka-topics --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 -create --replication-factor 2 --partitions 1 --topic hudi_table_user
1.2.1.2 编写程序
新建work.jiang.hudi.kafka.cow.FlinkKafkaToHudiCOWTableAndSyncToHive
package work.jiang.hudi.kafka.cow;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import work.jiang.hudi.pojo.Hudi_users2;
import work.jiang.hudi.util.KafkaUtil;
public class FlinkKafkaToHudiCOWTableAndSyncToHive {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(5 * 1000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
kafka_sql_to_hudi(tbEnv);
//kafka_stream_to_hudi(senv,tbEnv);
senv.execute();
}
/**
* 测试目的:通过 flink sql 接收kafka(kafka只能发json) 入 hudi
*
* cd /opt/cloudera/parcels/CDH/bin
* kafka-topics --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 -create --replication-factor 2 --partitions 1 --topic hudi_table_user
* kafka-console-producer --broker-list cdh01:9092,cdh02:9092,cdh03:9092 --topic hudi_table_user
* {"pid": 1, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 2, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 3, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* 测试结果:会在hdfs创建表目录,在hive生成一个表,并且自动同步分区与数据
*/
public static void kafka_sql_to_hudi(StreamTableEnvironment tableEnv) throws Exception{
tableEnv.executeSql("CREATE TABLE users_kafka_sql_tmp (\n" +
" pid STRING,\n" +
" name STRING,\n" +
" birthday STRING,\n" +
" ts STRING,\n" +
" create_day STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'hudi_table_user',\n" +
" 'properties.bootstrap.servers' = 'cdh01:9092,cdh02:9092,cdh03:9092',\n" +
" 'properties.group.id' = 'hudi_table_test',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
//tableEnv.executeSql("select * from users_kafka_sql_tmp").print();
tableEnv.executeSql("CREATE TABLE czs_hive_kafka_cow(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_kafka_cow', \n" +
"'table.type'= 'COPY_ON_WRITE',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'compaction.delta_seconds' = '120',\n" +
"'changelog.enabled'= 'true',\n" +
// "'read.streaming.enabled'= 'true',\n" +
//"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_kafka_cow',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
tableEnv.executeSql("insert into czs_hive_kafka_cow select * from users_kafka_sql_tmp");
tableEnv.executeSql("select * from czs_hive_kafka_cow").print();
}
1.2.1.3 运行程序,向kafka发送数据
> kafka-console-producer --broker-list cdh01:9092,cdh02:9092,cdh03:9092 --topic hudi_table_user
> {"pid": 1, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
> {"pid": 2, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
> {"pid": 3, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
1.2.1.4 查询hdfs
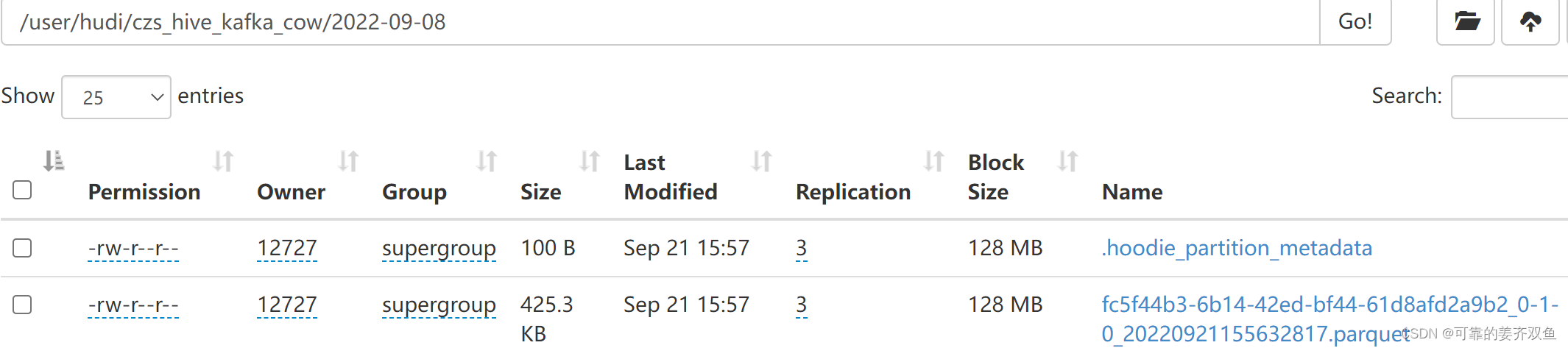
1.2.1.5 查询hive
hive有自动建表,建立一个表,kafka发送数据会实时更新到hudi
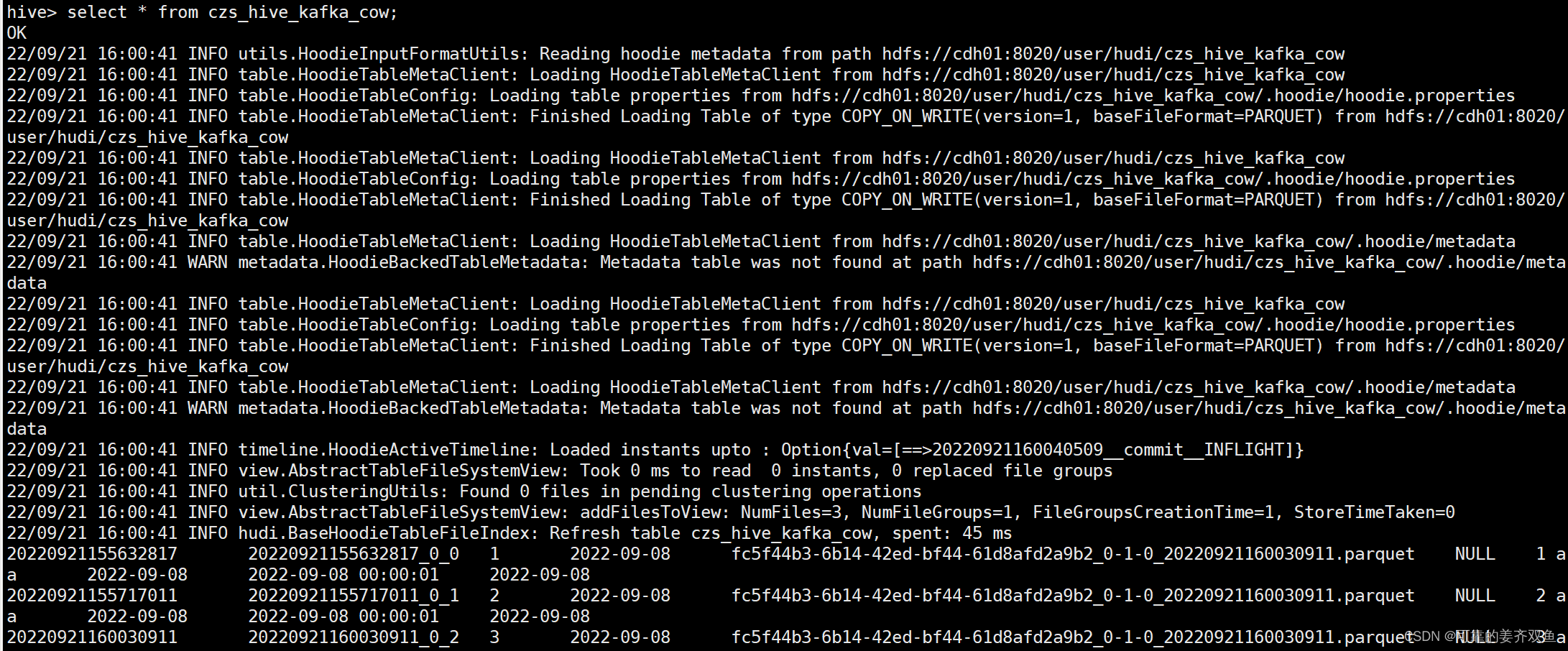
1.2.2 flink-kafka stream 入 hudi cow
1.2.2.1 创建kafka topic
同1.2.1.1
1.2.2.2 编写程序
在work.jiang.hudi.kafka.cow.FlinkKafkaToHudiCOWTableAndSyncToHive类添加方法kafka_stream_to_hudi
public class FlinkKafkaToHudiCOWTableAndSyncToHive {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(5 * 1000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
//kafka_sql_to_hudi(tbEnv);
kafka_stream_to_hudi(senv,tbEnv);
senv.execute();
}
/**
* 测试目的:通过 flink stream 接收kafka,把流转成table,把 table 入 hudi
*
* cd /opt/cloudera/parcels/CDH/bin
* kafka-topics --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 -create --replication-factor 2 --partitions 1 --topic hudi_table_user
* kafka-console-producer --broker-list cdh01:9092,cdh02:9092,cdh03:9092 --topic hudi_table_user
* {"pid": 1, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 2, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 3, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* 测试结果:会在hdfs创建表目录,在hive生成一个表,并且自动同步分区与数据
*/
public static void kafka_stream_to_hudi(StreamExecutionEnvironment senv,StreamTableEnvironment tableEnv) throws Exception{
DataStreamSource<String> hudi_table_user_kafka = senv.addSource(
new FlinkKafkaConsumer<String>(
"hudi_table_user",
new SimpleStringSchema(),
KafkaUtil.buildKafkaProps("cdh01:9092,cdh02:9092,cdh03:9092",
"hudi_table_test")));
SingleOutputStreamOperator<Hudi_users2> hudi_table_user_stream = hudi_table_user_kafka.map(new MapFunction<String, Hudi_users2>() {
@Override
public Hudi_users2 map(String value) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
String pid = jsonObject.getString("pid");
String name = jsonObject.getString("name");
String birthday = jsonObject.getString("birthday");
String ts = jsonObject.getString("ts");
String create_day = jsonObject.getString("create_day");
return new Hudi_users2(pid, name,birthday, ts, create_day);
}
});
DataStream<Hudi_users2> hudi_table_user_ = hudi_table_user_stream.rebalance();
Table user_table = tableEnv.fromDataStream(hudi_table_user_);
tableEnv.createTemporaryView("user_kafka_stream_tmp",user_table);
// 这里执行print了,就无法执行下边的语句了,需要注释掉
// tbEnv.executeSql("select * from user_kafka_stream_tmp").print();
tableEnv.executeSql("CREATE TABLE czs_hive_kafka_stream_cow(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_kafka_stream_cow', \n" +
"'table.type'= 'COPY_ON_WRITE',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'compaction.delta_seconds' = '120',\n" +
"'changelog.enabled'= 'true',\n" +
// "'read.streaming.enabled'= 'true',\n" +
//"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_kafka_stream_cow',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
tableEnv.executeSql("insert into czs_hive_kafka_stream_cow select * from user_kafka_stream_tmp");
tableEnv.executeSql("select * from czs_hive_kafka_stream_cow").print();
}
}
新建work.jiang.hudi.util.KafkaUtil
package work.jiang.hudi.util;
import java.util.Properties;
public class KafkaUtil {
/**
* 构建kafka配置
* @return
*/
public static Properties buildKafkaProps(String kafkaBroker,String kafkaGroupId ) {
Properties props =new Properties();
props.setProperty("bootstrap.servers", kafkaBroker);
props.setProperty("group.id", kafkaGroupId);
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("auto.offset.reset", "earliest");
props.setProperty("session.timeout.ms", "300000");
props.setProperty("fetch.message.max.bytes", "10000000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return props;
}
}
1.2.2.3 运行程序,向kafka发送数据
同1.2.1.3
1.2.2.4 查询hdfs
没有发数据前,表目录下只有.hoodie文件

发数据之后,才会生成分区文件
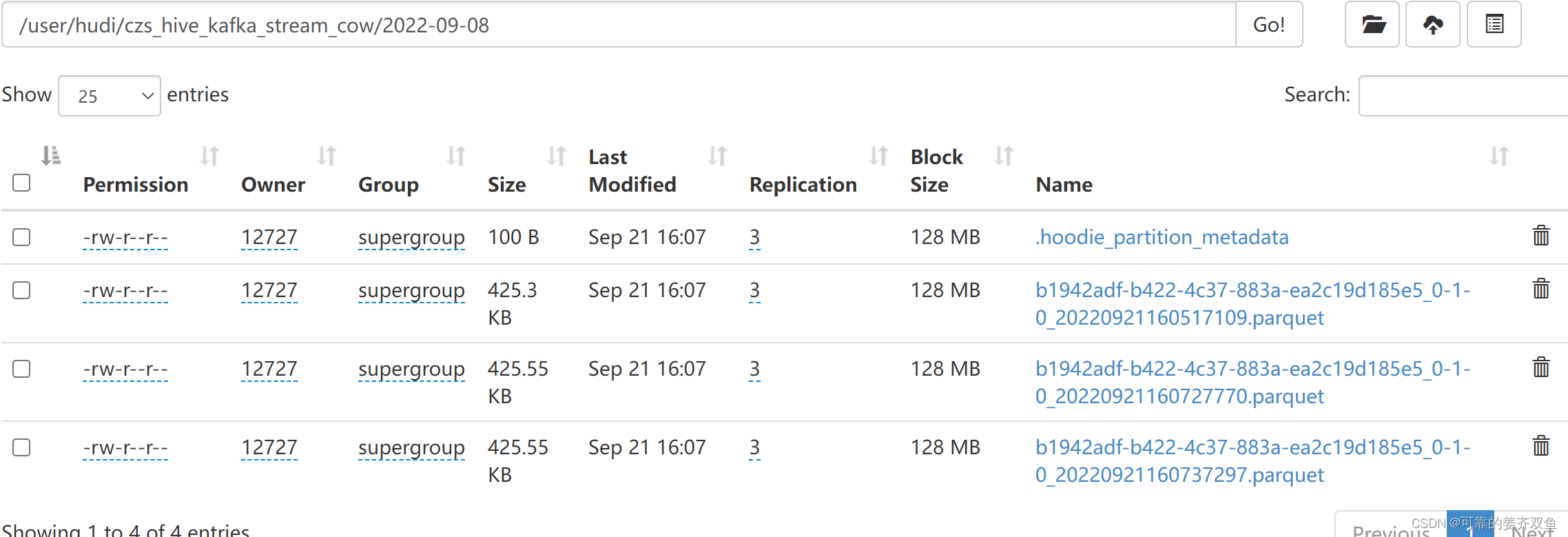
在kafka发送相同主键的数据,会更新hudi历史的主键的那行数据
1.2.2.5 查询hive
会自动创建一个表,在表里能够查到更新的数据
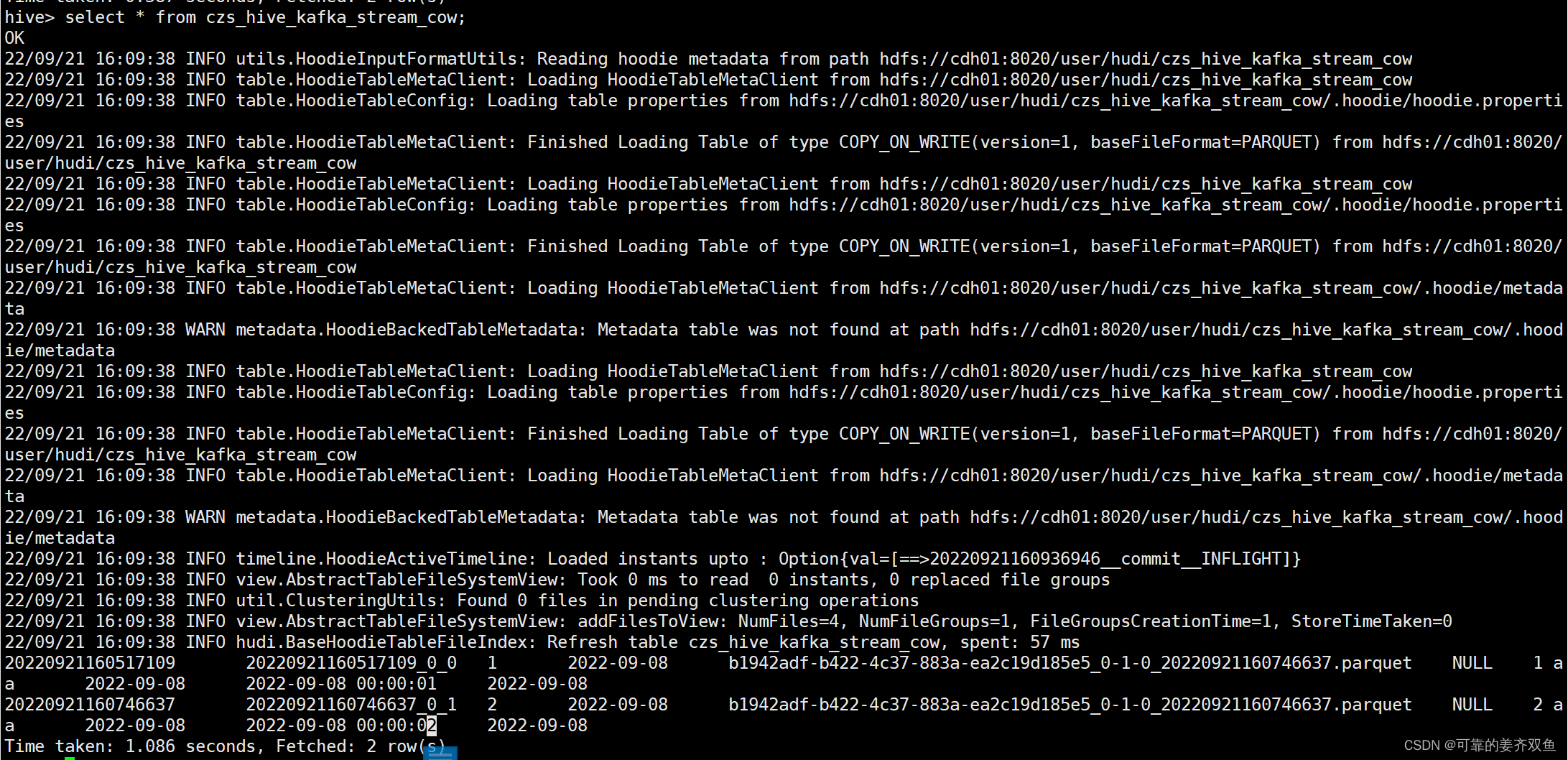
1.2.3 flink-kafka sql 入 hudi mor
1.2.3.1 创建kafka topic
同1.2.1.1
1.2.3.2 编写程序
创建work.jiang.hudi.kafka.mor.FlinkKafkaToHudiMORTableAndSyncToHive
package work.jiang.hudi.kafka.mor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import work.jiang.hudi.pojo.Hudi_users2;
import work.jiang.hudi.util.KafkaUtil;
public class FlinkKafkaToHudiMORTableAndSyncToHive {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(5 * 1000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
kafka_sql_to_hudi(tbEnv);
//kafka_stream_to_hudi(senv,tbEnv);
senv.execute();
}
/**
* 测试目的:通过 flink sql 接收kafka(kafka只能发json) 入 hudi
*
* cd /opt/cloudera/parcels/CDH/bin
* kafka-topics --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 -create --replication-factor 2 --partitions 1 --topic hudi_table_user
* kafka-console-producer --broker-list cdh01:9092,cdh02:9092,cdh03:9092 --topic hudi_table_user
* {"pid": 1, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 2, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 3, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* 测试结果:会在hdfs创建表目录,在hive生成2个表,并且自动同步分区与数据
*/
public static void kafka_sql_to_hudi(StreamTableEnvironment tableEnv) throws Exception{
tableEnv.executeSql("CREATE TABLE users_kafka_sql_tmp (\n" +
" pid STRING,\n" +
" name STRING,\n" +
" birthday STRING,\n" +
" ts STRING,\n" +
" create_day STRING\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'hudi_table_user',\n" +
" 'properties.bootstrap.servers' = 'cdh01:9092,cdh02:9092,cdh03:9092',\n" +
" 'properties.group.id' = 'hudi_table_test',\n" +
" 'scan.startup.mode' = 'latest-offset',\n" +
" 'format' = 'json',\n" +
" 'json.fail-on-missing-field' = 'false',\n" +
" 'json.ignore-parse-errors' = 'true'\n" +
")");
//tableEnv.executeSql("select * from users_kafka_sql_tmp").print();
tableEnv.executeSql("CREATE TABLE czs_hive_kafka(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_kafka', \n" +
"'table.type'= 'MERGE_ON_READ',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'compaction.delta_seconds' = '120',\n" +
"'changelog.enabled'= 'true',\n" +
"'read.streaming.enabled'= 'true',\n" +
"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_kafka',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
tableEnv.executeSql("insert into czs_hive_kafka select * from users_kafka_sql_tmp");
tableEnv.executeSql("select * from czs_hive_kafka").print();
}
}
1.2.3.3 运行程序,向kafka发送数据
同1.2.1.3
1.2.3.4 查询hdfs
没有数据之前,表目录下之后.hoodie文件

有数据之后,才会有分区文件
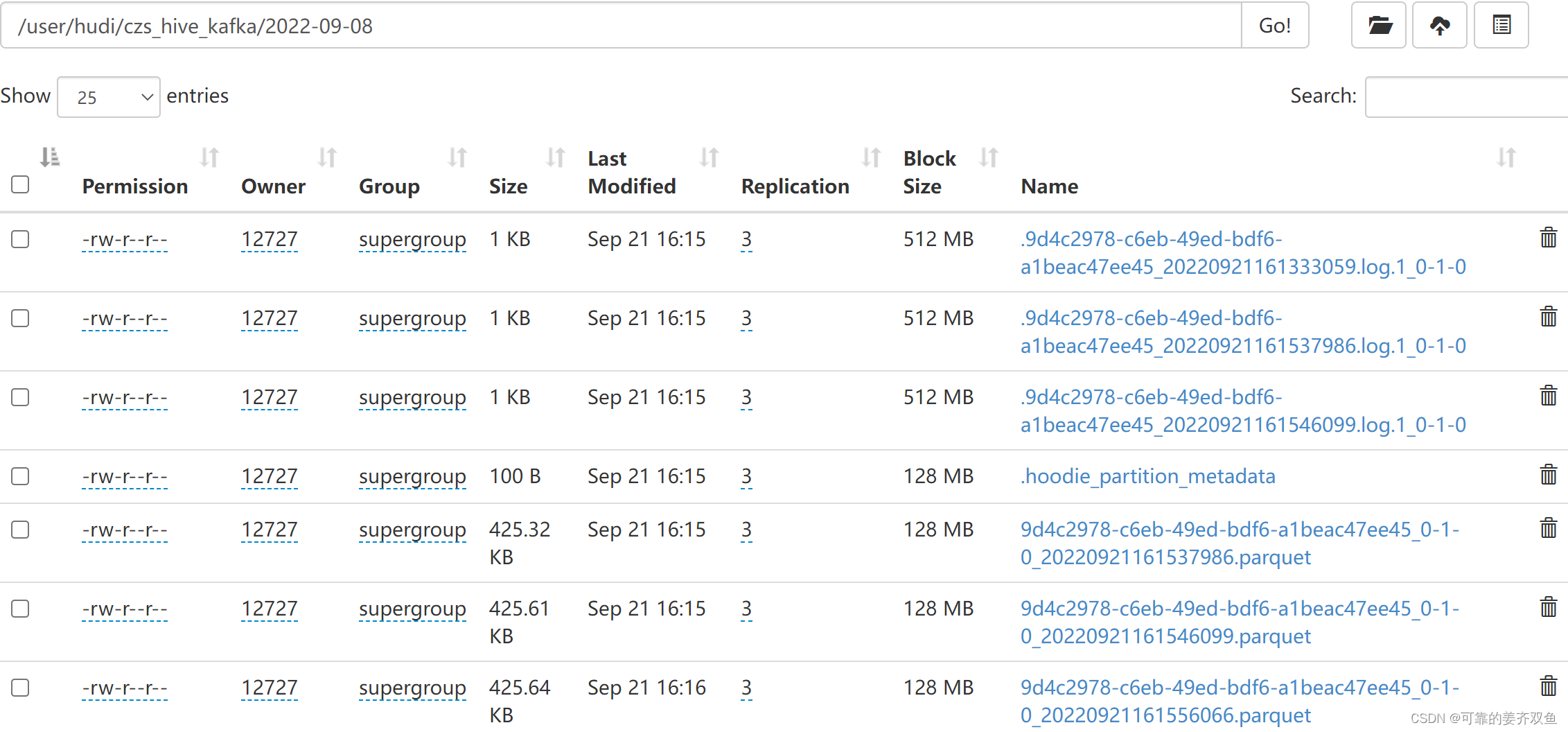
1.2.3.5 查询hive
在hive会自动生成两个表,分别是ro、rt表
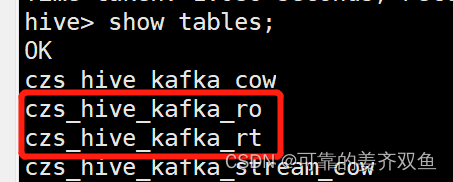
都能查询出数据

1.2.4 flink-kafka stream 入 hudi mor
1.2.4.1 创建kafka topic
同1.2.1.1
1.2.4.2 编写程序
在work.jiang.hudi.kafka.mor.FlinkKafkaToHudiMORTableAndSyncToHive 添加方法kafka_stream_to_hudi
public class FlinkKafkaToHudiMORTableAndSyncToHive {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
//StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironment();
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(5 * 1000);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
//kafka_sql_to_hudi(tbEnv);
kafka_stream_to_hudi(senv,tbEnv);
senv.execute();
}
/**
* 测试目的:通过 flink stream 接收kafka,把流转成table,把 table 入 hudi
*
* cd /opt/cloudera/parcels/CDH/bin
* kafka-topics --zookeeper cdh01:2181,cdh02:2181,cdh03:2181 -create --replication-factor 2 --partitions 1 --topic hudi_table_user
* kafka-console-producer --broker-list cdh01:9092,cdh02:9092,cdh03:9092 --topic hudi_table_user
* {"pid": 1, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 2, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* {"pid": 3, "name":"aa", "birthday": "2022-09-08", "ts": "2022-09-08 00:00:01", "create_day": "2022-09-08"}
* 测试结果:会在hdfs创建表目录,在hive生成2个表,并且自动同步分区与数据
*/
public static void kafka_stream_to_hudi(StreamExecutionEnvironment senv,StreamTableEnvironment tableEnv) throws Exception{
DataStreamSource<String> hudi_table_user_kafka = senv.addSource(
new FlinkKafkaConsumer<String>(
"hudi_table_user",
new SimpleStringSchema(),
KafkaUtil.buildKafkaProps("cdh01:9092,cdh02:9092,cdh03:9092",
"hudi_table_test")));
SingleOutputStreamOperator<Hudi_users2> hudi_table_user_stream = hudi_table_user_kafka.map(new MapFunction<String, Hudi_users2>() {
@Override
public Hudi_users2 map(String value) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
String pid = jsonObject.getString("pid");
String name = jsonObject.getString("name");
String birthday = jsonObject.getString("birthday");
String ts = jsonObject.getString("ts");
String create_day = jsonObject.getString("create_day");
return new Hudi_users2(pid, name,birthday, ts, create_day);
}
});
DataStream<Hudi_users2> hudi_table_user_ = hudi_table_user_stream.rebalance();
Table user_table = tableEnv.fromDataStream(hudi_table_user_);
tableEnv.createTemporaryView("user_kafka_stream_tmp",user_table);
// 这里执行print了,就无法执行下边的语句了,需要注释掉
// tbEnv.executeSql("select * from user_kafka_stream_tmp").print();
tableEnv.executeSql("CREATE TABLE czs_hive_kafka_stream(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_kafka_stream', \n" +
"'table.type'= 'MERGE_ON_READ',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'compaction.delta_seconds' = '120',\n" +
"'changelog.enabled'= 'true',\n" +
"'read.streaming.enabled'= 'true',\n" +
"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_kafka_stream',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
tableEnv.executeSql("insert into czs_hive_kafka_stream select * from user_kafka_stream_tmp");
tableEnv.executeSql("select * from czs_hive_kafka_stream").print();
}
}
1.2.4.3 运行程序,向kafka发送数据
同1.2.1.3
1.2.4.4 查询hdfs
没有数据之前,表目录下只有.hoodie文件

有数据之后,表目录下面才有分区文件
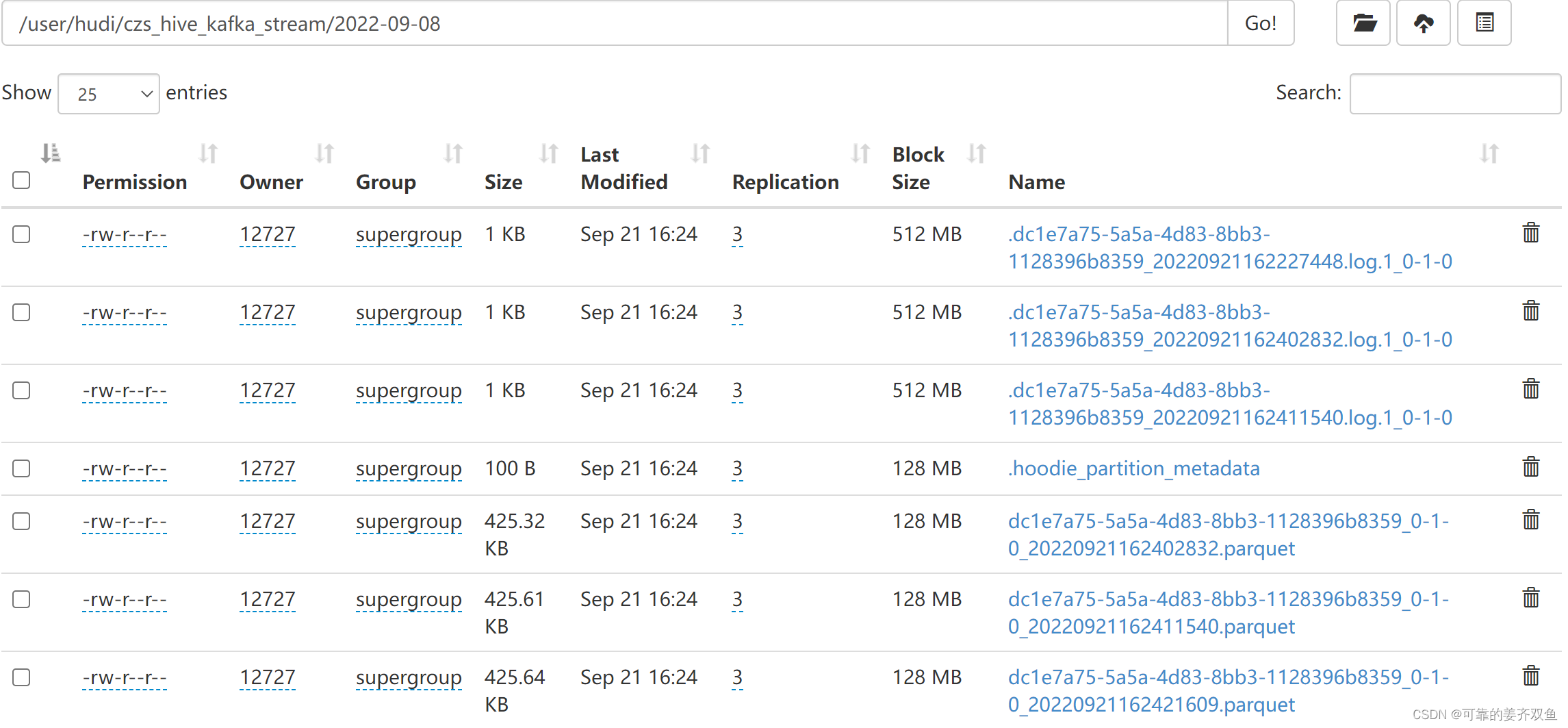
1.2.4.5 查询hive
有自动生成两个表,分别是ro、rt表
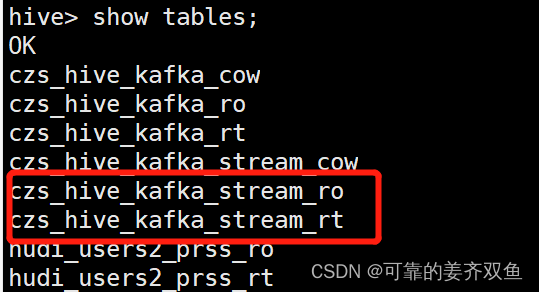
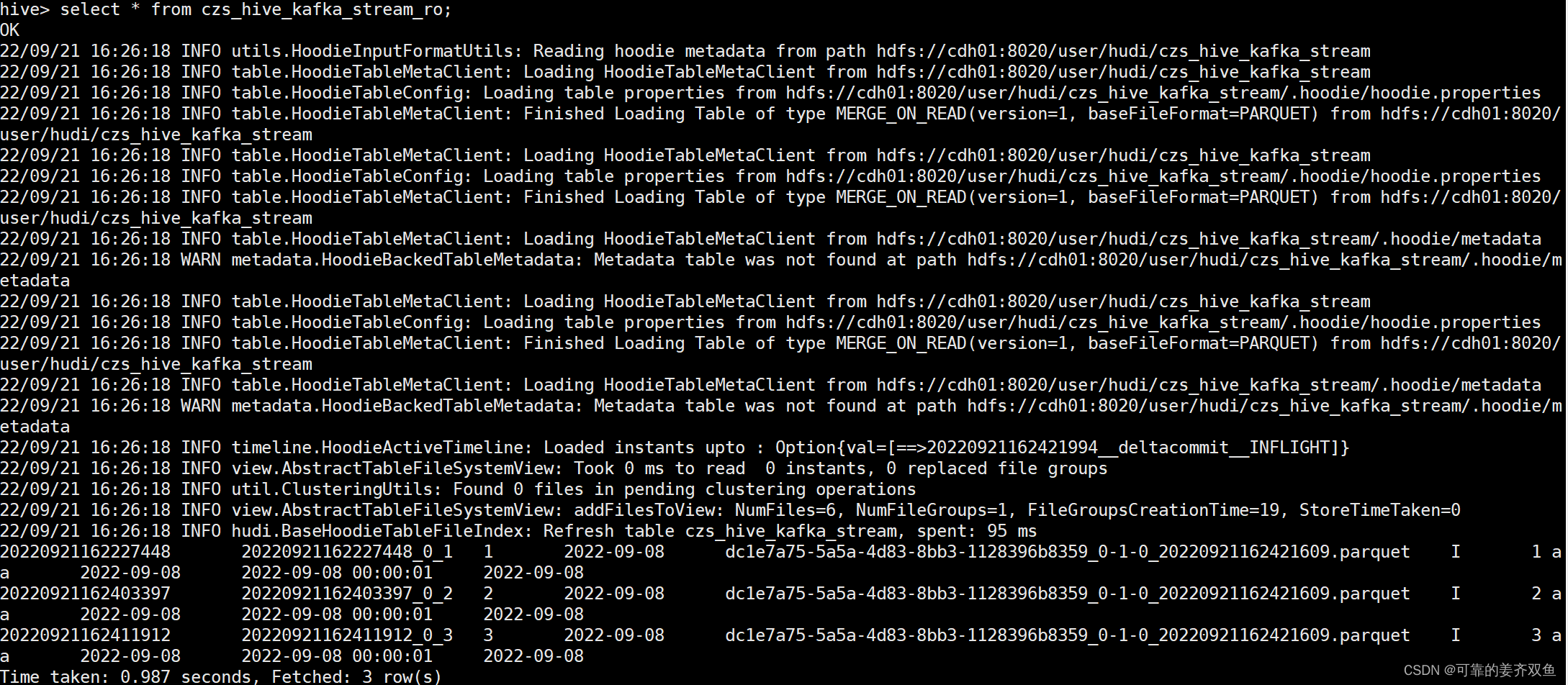
hive> select * from czs_hive_kafka_stream_ro;
hive> select * from czs_hive_kafka_stream_rt;
两个表都能查询出数据
1.3 直接insert into hudi
这种方式是批的方式,hudi 的 insert 语句只能提交一次,建表之后,如果没有insert 操作,hdfs目录下没有生成表目录
cow 表,如果insert 数据之后,会生成parquet文件,在hive可以查到
mor表,如果insert 数据之后,会生成log文件,一直没有生成parquet文件
1.3.1 cow表
新建work.jiang.hudi.fieldtosql.FieldTosql_cow
package work.jiang.hudi.fieldtosql;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FieldTosql_cow {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode()//设置流式模式
.build();
env.setParallelism(1);
env.enableCheckpointing(5 *1000);
StreamTableEnvironment tenv = StreamTableEnvironment.create(env, settings);
System.out.println("tenv====================================" + tenv);
tenv.executeSql("CREATE TABLE hudi_users_fields2_cow(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8022/user/hudi/hudi_users_fields2_cow', \n" +
"'table.type'= 'COPY_ON_WRITE',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'id', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'write.bucket_assign.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '3',\n" +
"'changelog.enabled'= 'true',\n" +
//"'read.streaming.enabled'= 'true',\n" +
// "'read.streaming.check-interval'= '10',\n" +
"'read.tasks'= '1',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'hudi_users_fields2_cow',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
String sql1 = "insert into hudi_users_fields2_cow values" +
"(0,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:00','1970-01-01')," +
"(1,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:01','1970-01-01')," +
"(2,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:02','1970-01-01')," +
"(3,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:03','1970-01-01')," +
"(4,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:04','1970-01-01')," +
"(5,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:05','1970-01-01')," +
"(6,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:06','1970-01-01')," +
"(7,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:07','1970-01-01')," +
"(8,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:08','1970-01-01')," +
"(9,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:09','1970-01-01')," +
"(1,'bb',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:10','1970-01-01')," +
"(11,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(12,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(13,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(14,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(15,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(16,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(17,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(18,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(19,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(20,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(21,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:12','1970-01-01')" ;
tenv.executeSql(sql1);
//测试结果:每重新运行一次main方法,会新生成一个parquet的文件,会在hive自动建表,自动同步数据
// 不支持重复提交
// for (int i = 100; i < 105; i++) {
// String name = "aa_" + i;
// String birthday = "2020-01-01 12:12:12";
// String ts = new Timestamp(System.currentTimeMillis()).toString().substring(0, 19);
// String partition = "2020-01-01";
// tenv.executeSql("insert into hudi_users_fields2_cow values( " + i + ", \'" + name + "\', TIMESTAMP \'" + birthday + "\', TIMESTAMP \'" + ts + "\', \'" + partition + "\')");
tenv.executeSql("select * from hudi_users_fields2_cow").print(); // 这一句会导致程序直接执行提交操作,不会再去扫描for循环
// }
}
}
运行结果,如果没有insert 语句,hdfs目录下不会生成表目录。如果有insert 语句,会生成表目录和分区文件,在hive会自动建表,且自动同步数据到hive,每运行一次main方法重新生成一个parquet文件,是典型的批量插入
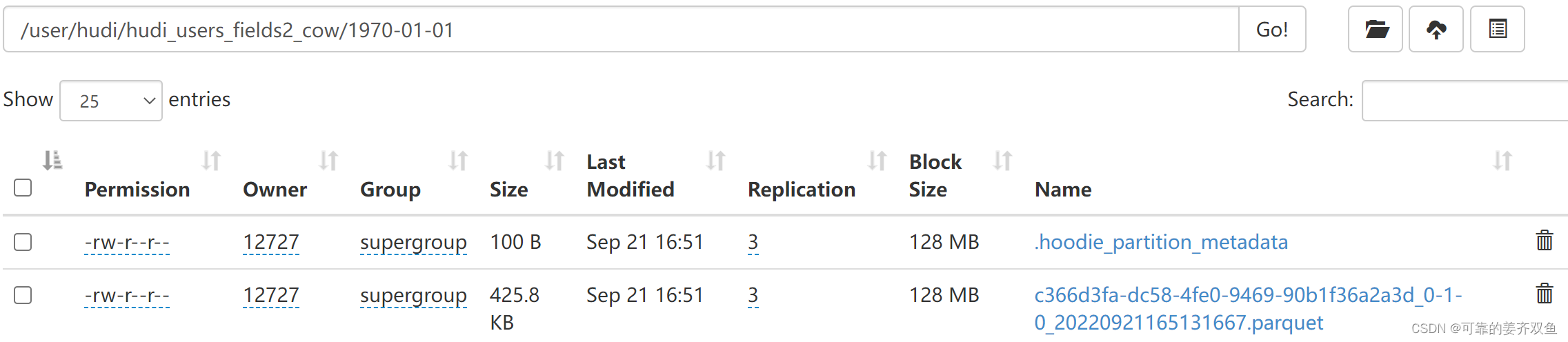
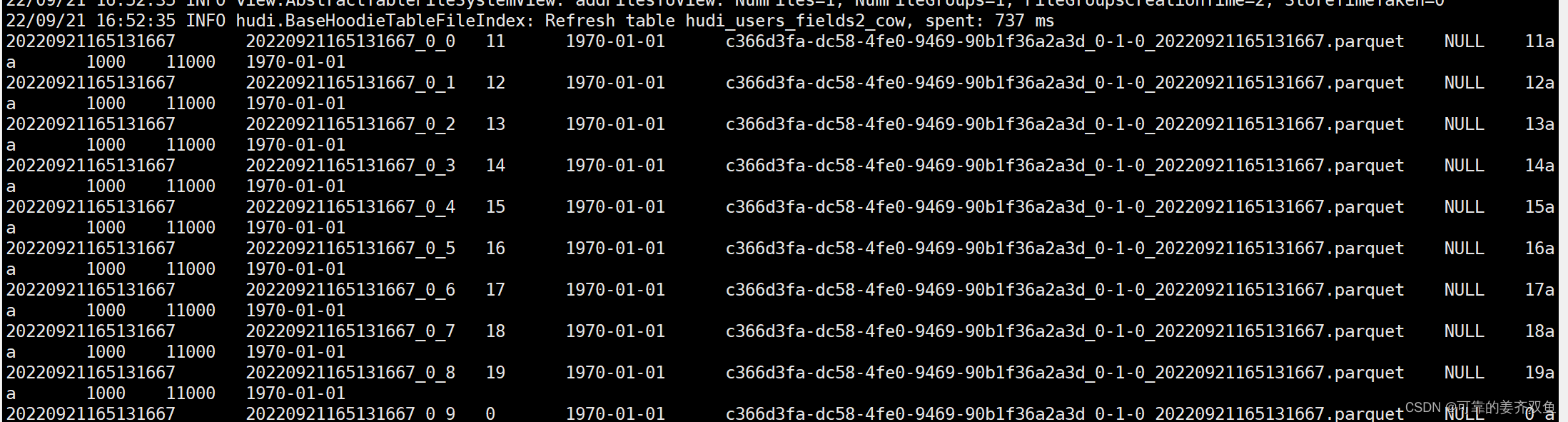
1.3.2 mor表
新建work.jiang.hudi.fieldtosql.FieldTosql_mor
package work.jiang.hudi.fieldtosql;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class FieldTosql_mor {
public static void main(String[] args) throws Exception {
//System.setProperty("HADOOP_USER_NAME", "hdfs");
//使用本地模式并开启WebUI
Configuration conf = new Configuration();
conf.setString(RestOptions.BIND_PORT, "8081-8099");
StreamExecutionEnvironment senv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
//1.获取表的执行环境
//并行度设置为1
senv.setParallelism(1);
//由于增量将数据写入到Hudi表,所以需要启动Flink Checkpoint 检查点
senv.enableCheckpointing(5 * 1000);
//senv.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//senv.setStateBackend(new FsStateBackend("hdfs://cdh01:8022/tmp/hudi_statebackend/hudi_users_fields2/cp"));
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()//blink 版本的流处理环境
.inStreamingMode()//设置流式模式
.build();
StreamTableEnvironment tbEnv = StreamTableEnvironment.create(senv, settings);
field_sql_to_hudi(tbEnv);
}
/**
* 测试目的:验证把得到的数据,通过insert into 形式插入 hudi MOR 表,会不会生成parquet文件
* <p>
* 测试结果:只有log文件,没有parquet文件,hive会创建表,但是在 hive 将无法查询出数据
* 如果没有插入语句,hdfs将不会创建表目录,hive也不会自动建表
*/
public static void field_sql_to_hudi(StreamTableEnvironment tbEnv) throws Exception {
tbEnv.executeSql("CREATE TABLE hudi_users_fields2(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8022/user/hudi/hudi_users_fields2', \n" +
"'table.type'= 'MERGE_ON_READ',\n" +
"'hoodie.datasource.write.recordkey.field'= 'id', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'write.bucket_assign.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'changelog.enabled'= 'true',\n" +
"'read.streaming.enabled'= 'true',\n" +
"'read.streaming.check-interval'= '10',\n" +
"'read.tasks'= '1',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'hudi_users_fields2',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
// long id = 3;
// String name = "cc";
// String birthday = "2020-01-01 12:12:12";
// String ts = "2022-09-13 12:12:12";
// String partition = "2020-01-01";
// String sql = "insert into hudi_users_fields2 values( "+ id + ", \'"+ name +"\', TIMESTAMP \'" + birthday +"\', TIMESTAMP \'" + ts +"\', \'" + partition +"\')," +
// "( "+ "2" + ", \'"+ name +"\', TIMESTAMP \'" + birthday +"\', TIMESTAMP \'" + "2022-09-13 12:13:13" +"\', \'" + partition +"\')";
String sql1 = "insert into hudi_users_fields2 values" +
"(0,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:00','1970-01-01')," +
"(1,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:01','1970-01-01')," +
"(2,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:02','1970-01-01')," +
"(3,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:03','1970-01-01')," +
"(4,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:04','1970-01-01')," +
"(5,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:05','1970-01-01')," +
"(6,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:06','1970-01-01')," +
"(7,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:07','1970-01-01')," +
"(8,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:08','1970-01-01')," +
"(9,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:09','1970-01-01')," +
"(1,'bb',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:10','1970-01-01')," +
"(11,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(12,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(13,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(14,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(15,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(16,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(17,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(18,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(19,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(20,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:11','1970-01-01')," +
"(21,'aa',TIMESTAMP '1970-01-01 00:00:01',TIMESTAMP '1970-01-01 00:00:12','1970-01-01')" ;
tbEnv.executeSql(sql1);
//测试结果:每重新运行一次main方法,会新生成一个log文件,没有生成parquet文件,会在hive自动建表,hive查不到数据
// 不支持重复提交
// for (int i = 1; i < 5; i++) {
// String name = "aa_" + i;
// String birthday = "2020-01-01 12:12:12";
// String ts = new Timestamp(System.currentTimeMillis()).toString().substring(0, 19);
// String partition = "2020-01-01";
// String sql = "insert into hudi_users_fields2 values( " + i + ", \'" + name + "\', TIMESTAMP \'" + birthday + "\', TIMESTAMP \'" + ts + "\', \'" + partition + "\')";
// tbEnv.executeSql(sql);
// }
// tbEnv.executeSql("select * from hudi_users_fields2").print();
}
}
测试结果,如果没有insert 语句,hdfs目录下不会生成表目录。如果有insert 语句,hdfs目录下会生成表目录和分区目录,分区目录下会生成log文件,不会生成parquet文件,在hive中有自动创建ro、rt表,但是由于分区下没有parquet文件,在hive将不会查询出数据
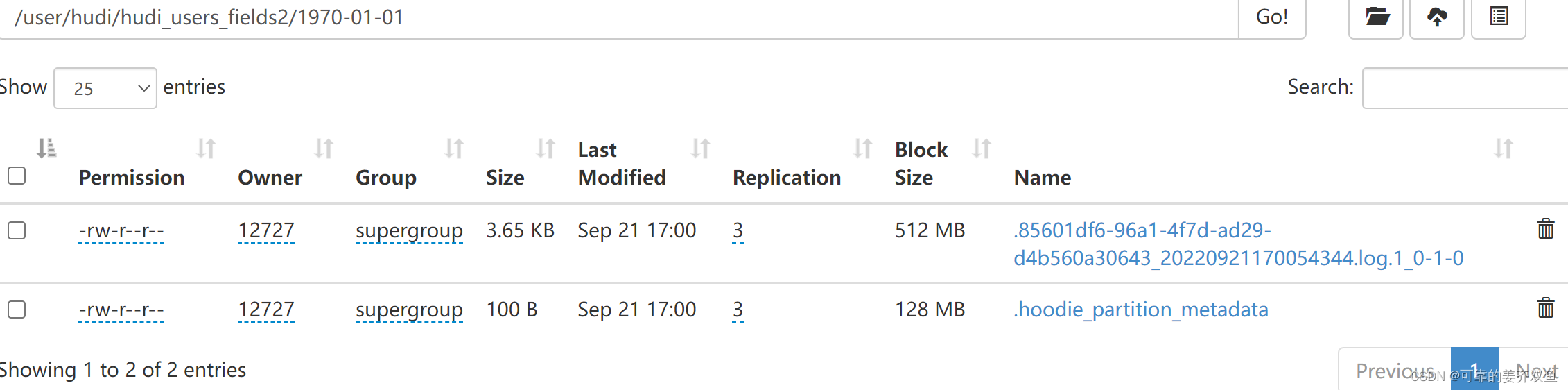
1.4 把一个pojo 转化为 table 入 hudi
这种方式是批的方式,hudi 的 insert 语句只能提交一次,建表之后,如果没有insert 操作,hdfs目录下没有生成表目录
cow 表,如果insert 数据之后,会生成parquet文件,在hive可以查到
mor表,如果insert 数据之后,会生成log文件,一直没有生成parquet文件
1.4.1 cow表
新建work.jiang.hudi.fieldtosql.PojoTosql_cow
package work.jiang.hudi.fieldtosql;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import work.jiang.hudi.pojo.Hudi_users2;
import static org.apache.flink.table.api.Expressions.$;
public class PojoTosql_cow {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
env.setParallelism(4);
env.enableCheckpointing(1000 * 1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
tableEnv.executeSql("CREATE TABLE czs_hive_pojo_cow(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_pojo_cow', \n" +
"'table.type'= 'COPY_ON_WRITE',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'changelog.enabled'= 'true',\n" +
// "'read.streaming.enabled'= 'true',\n" +
// "'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_pojo_cow',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
// hudi表插入数据
// 思路1:把一个对象转化成table,再创建临时视图,再把视图插入到hudi表,会生成parquet
pojo_insert_hudi(env,tableEnv);
// 思路2:不需要对象,把需要的字段值取到就行,通过sql语句把字段拼进去就行,这种方式比较简单,会生成parquet
//field_insert_hudi(tableEnv);
// hudi表更新数据
// 更新的语法和插入是一样的,插入一条已经存在的id的数据,即为更新
//tableEnv.executeSql("insert into czs_hive_pojo_cow values('2','dd','1970-02-02','1970-02-02 00:00:01','1970-02-02')");
// 查找并更新
//思路1:根据查询语句得出table,通过table自身api修改字段的值,把table为临时视图,将临时视图更新到hudi表,行不通,table没有相关api
//思路2:根据查询语句得到table或TableResult,循环遍历出字段,把每一行的字段取到,使用insert into 更新到hudi表,已把TableResult测通
//query_and_update_hudi(tableEnv);
//删除数据,不支持
}
public static void pojo_insert_hudi(StreamExecutionEnvironment env,StreamTableEnvironment tableEnv) throws Exception{
String timestamp = String.valueOf(System.currentTimeMillis());
//新建对象
Hudi_users2 hudi_users2_obj = new Hudi_users2("1","aa","1995-10-08",timestamp,"2022-08-29");
//转化成流
DataStream<Hudi_users2> hudi_users2_stream = env.fromElements(hudi_users2_obj);
//转化成一个table
Table hudi_users2_table = tableEnv.fromDataStream(
hudi_users2_stream,
$("pid"),
$("name"),
$("birthday"),
$("ts"),
$("create_day")
);
//创建临时视图
tableEnv.createTemporaryView("hudi_users2_tmp",hudi_users2_table);
//tableEnv.executeSql("select * from hudi_users2_tmp").print();
tableEnv.executeSql("insert into czs_hive_pojo_cow select * from hudi_users2_tmp");
tableEnv.executeSql("select * from czs_hive_pojo_cow").print();
env.execute("pojo to sql cow czs_hive_pojo_cow");
}
public static void field_insert_hudi(StreamTableEnvironment tableEnv){
String pid = "12";
String name = "bb";
String birthday = "2022-09-20";
String ts = "2022-09-20 12:12:12";
String create_day = "2022-09-20";
tableEnv.executeSql("insert into czs_hive_pojo_cow values(\'" +
pid +"\',\'"+name +"\',\'"+birthday +"\',\'"+ ts + "\',\'"+ create_day +"\')");
tableEnv.executeSql("select * from czs_hive_pojo_cow").print();
}
public static void query_and_update_hudi(StreamTableEnvironment tableEnv){
//需要更新的字段
String ts = "2022-09-20 11:11:11";
//查询出的历史记录
TableResult result = tableEnv.executeSql("select pid,name,birthday,ts,create_day from czs_hive_pojo_cow where pid = '1' ");
CloseableIterator<Row> row = result.collect();
//取历史数据,如果有多条数据,需要取时间最新的那条数据,且不是脏数据
System.out.println("aaaaaaaaaaaaaaaaaaaaaaaaaaaa");
if(row.hasNext()){
System.out.println("bbbbbbbbbbbbbbbbbbbbbbbbbbbbb");
Row row_tmp = row.next();
String pid = row_tmp.getField("pid").toString();
String name = row_tmp.getField("name").toString();
String birthday = row_tmp.getField("birthday").toString();
String create_day = row_tmp.getField("create_day").toString();
System.out.println(row_tmp.toString());
tableEnv.executeSql("insert into czs_hive_pojo_cow values(\'" +
pid +"\',\'"+name +"\',\'"+birthday +"\',\'"+ ts + "\',\'"+ create_day +"\')");
}
tableEnv.executeSql("select * from czs_hive_pojo_cow").print();
}
}
新建work.jiang.hudi.pojo.Hudi_users2
package work.jiang.hudi.pojo;
public class Hudi_users2 {
String pid;
String name;
String birthday;
String ts;
String create_day;
public Hudi_users2() {
super();
}
public Hudi_users2(String pid, String name, String birthday, String ts, String create_day){
this.pid = pid;
this.name = name;
this.birthday = birthday;
this.ts = ts;
this.create_day = create_day;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getBirthday() {
return birthday;
}
public void setBirthday(String birthday) {
this.birthday = birthday;
}
public String getTs() {
return ts;
}
public void setTs(String ts) {
this.ts = ts;
}
public String getCreate_day() {
return create_day;
}
public void setCreate_day(String create_day) {
this.create_day = create_day;
}
@Override
public String toString() {
return "hudi_users2{" +
"pid='" + pid + '\'' +
", name='" + name + '\'' +
", birthday='" + birthday + '\'' +
", ts='" + ts + '\'' +
", create_day=" + create_day +
'}';
}
}
测试结果同1.3.1
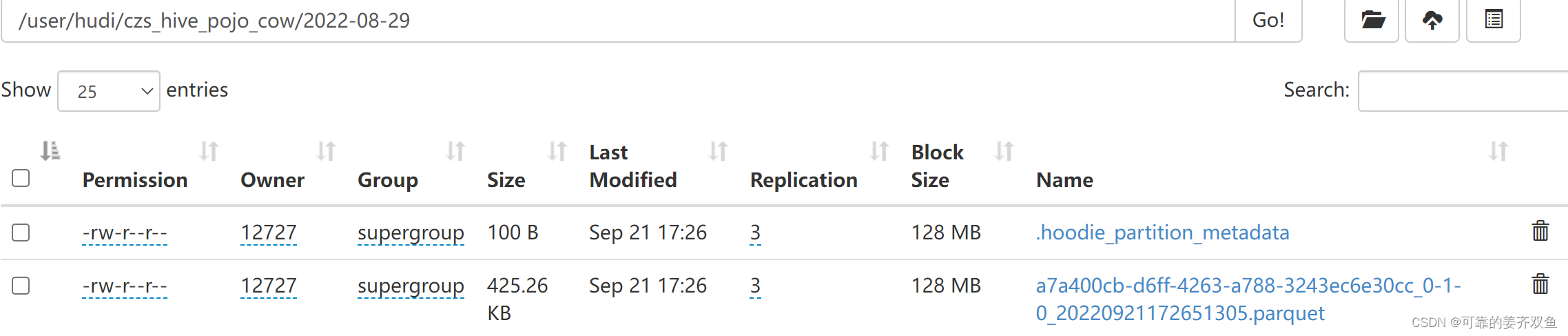
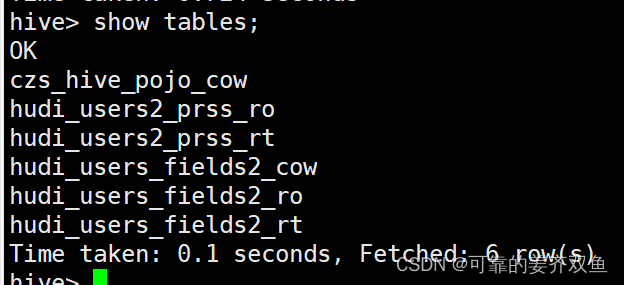
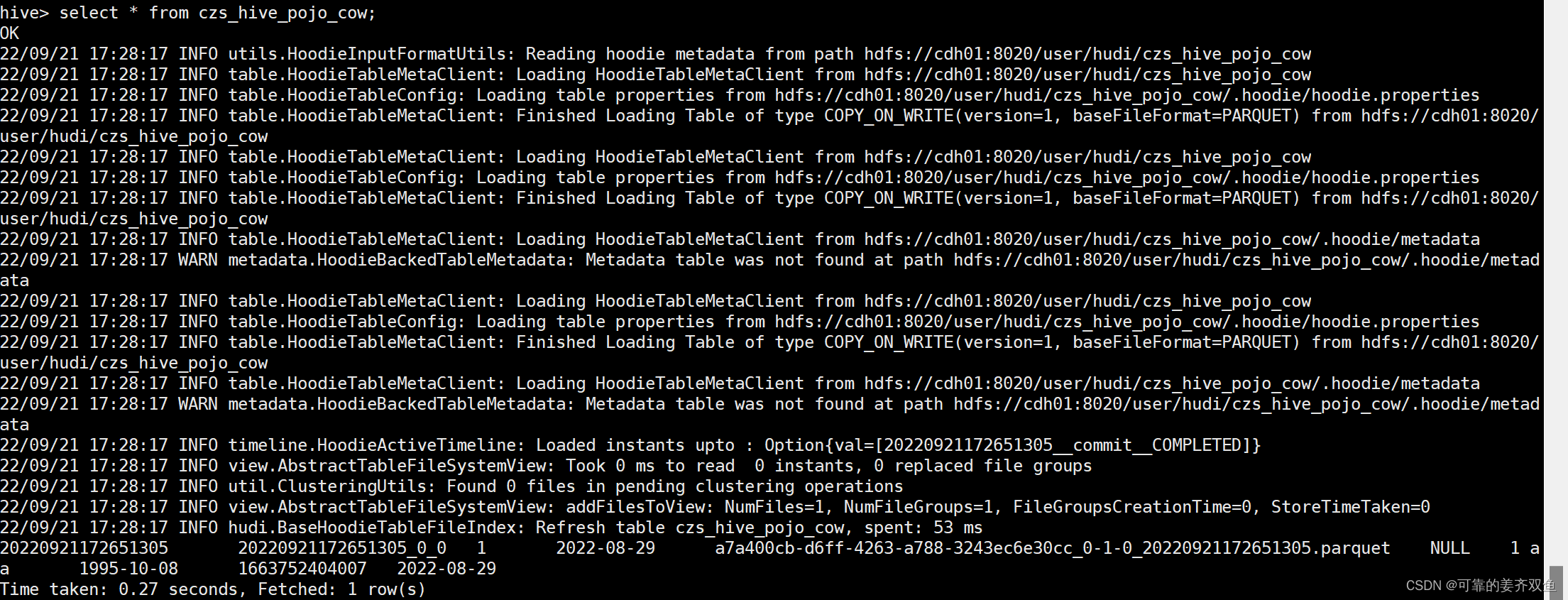
1.4.2 mor表
新建work.jiang.hudi.fieldtosql.PojoTosql_mor
package work.jiang.hudi.fieldtosql;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.flink.util.CloseableIterator;
import work.jiang.hudi.pojo.Hudi_users2;
import static org.apache.flink.table.api.Expressions.$;
///https://blog.csdn.net/wzp1986/article/details/125894473
public class PojoTosql_mor {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
env.setParallelism(4);
env.enableCheckpointing(1000 * 1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
tableEnv.executeSql("CREATE TABLE czs_hive_pojo_mor(\n" +
"pid string primary key not enforced,\n" +
"name string,\n" +
"birthday string,\n" +
"ts string,\n" +
"create_day string \n" +
")\n" +
"PARTITIONED BY (create_day)\n" +
"with(\n" +
"'connector'='hudi',\n" +
"'path'= 'hdfs://cdh01:8020/user/hudi/czs_hive_pojo_mor', \n" +
"'table.type'= 'MERGE_ON_READ',\n" +
"'write.operation' = 'upsert',\n" +
"'hoodie.datasource.write.recordkey.field'= 'pid', \n" +
"'write.precombine.field'= 'ts',\n" +
"'write.tasks'= '1',\n" +
"'write.rate.limit'= '2000', \n" +
"'compaction.tasks'= '1', \n" +
"'compaction.async.enabled'= 'true',\n" +
"'compaction.trigger.strategy'= 'num_commits',\n" +
"'compaction.delta_commits'= '1',\n" +
"'changelog.enabled'= 'true',\n" +
"'read.streaming.enabled'= 'true',\n" +
"'read.streaming.check-interval'= '3',\n" +
"'hive_sync.enable'= 'true',\n" +
"'hive_sync.mode'= 'hms',\n" +
"'hive_sync.metastore.uris'= 'thrift://cdh01:9083',\n" +
"'hive_sync.jdbc_url'= 'jdbc:hive2://cdh01:10000',\n" +
"'hive_sync.table'= 'czs_hive_pojo_mor',\n" +
"'hive_sync.db'= 'hudi_db',\n" +
"'hive_sync.username'= 'hive',\n" +
"'hive_sync.password'= 'hive',\n" +
"'hive_sync.support_timestamp'= 'true'\n" +
")");
// hudi表插入数据
// 思路1:把一个对象转化成table,再创建临时视图,再把视图插入到hudi表,会生成日志文件,不会生成parquet
pojo_insert_hudi(env,tableEnv);
// 思路2:不需要对象,把需要的字段值取到就行,通过sql语句把字段拼进去就行,这种方式比较简单,,会生成日志文件,不会生成parquet
//field_insert_hudi(tableEnv);
// hudi表更新数据
// 更新的语法和插入是一样的,插入一条已经存在的id的数据,即为更新
//tableEnv.executeSql("insert into czs_hive_pojo_mor values('2','dd','1970-02-02','1970-02-02 00:00:01','1970-02-02')");
// 查找并更新
//思路1:根据查询语句得出table,通过table自身api修改字段的值,把table为临时视图,将临时视图更新到hudi表,行不通,table没有相关api
//思路2:根据查询语句得到table或TableResult,循环遍历出字段,把每一行的字段取到,使用insert into 更新到hudi表,已把TableResult测通
//query_and_update_hudi(tableEnv);
//删除数据,不支持
}
public static void pojo_insert_hudi(StreamExecutionEnvironment env,StreamTableEnvironment tableEnv) throws Exception{
String timestamp = String.valueOf(System.currentTimeMillis());
//新建对象
Hudi_users2 hudi_users2_obj = new Hudi_users2("1","aa","1995-10-08",timestamp,"2022-08-29");
//转化成流
DataStream<Hudi_users2> hudi_users2_stream = env.fromElements(hudi_users2_obj);
//转化成一个table
Table hudi_users2_table = tableEnv.fromDataStream(
hudi_users2_stream,
$("pid"),
$("name"),
$("birthday"),
$("ts"),
$("create_day")
);
//创建临时视图
tableEnv.createTemporaryView("hudi_users2_tmp",hudi_users2_table);
//tableEnv.executeSql("select * from hudi_users2_tmp").print();
tableEnv.executeSql("insert into czs_hive_pojo_mor select * from hudi_users2_tmp");
tableEnv.executeSql("select * from czs_hive_pojo_mor").print();
env.execute("pojo to sql mor czs_hive_pojo_mor");
}
public static void field_insert_hudi(StreamTableEnvironment tableEnv){
String pid = "12";
String name = "bb";
String birthday = "2022-09-20";
String ts = "2022-09-20 12:12:12";
String create_day = "2022-09-20";
tableEnv.executeSql("insert into czs_hive_pojo_mor values(\'" +
pid +"\',\'"+name +"\',\'"+birthday +"\',\'"+ ts + "\',\'"+ create_day +"\')");
tableEnv.executeSql("select * from czs_hive_pojo_mor").print();
}
public static void query_and_update_hudi(StreamTableEnvironment tableEnv){
//需要更新的字段
String ts = "2022-09-20 11:11:11";
//查询出的历史记录
TableResult result = tableEnv.executeSql("select pid,name,birthday,ts,create_day from czs_hive_pojo_mor where pid = '1' ");
CloseableIterator<Row> row = result.collect();
//取历史数据,如果有多条数据,需要取时间最新的那条数据,且不是脏数据
System.out.println("aaaaaaaaaaaaaaaaaaaaaaaaaaaa");
if(row.hasNext()){
System.out.println("bbbbbbbbbbbbbbbbbbbbbbbbbbbbb");
Row row_tmp = row.next();
String pid = row_tmp.getField("pid").toString();
String name = row_tmp.getField("name").toString();
String birthday = row_tmp.getField("birthday").toString();
String create_day = row_tmp.getField("create_day").toString();
System.out.println(row_tmp.toString());
tableEnv.executeSql("insert into czs_hive_pojo_mor values(\'" +
pid +"\',\'"+name +"\',\'"+birthday +"\',\'"+ ts + "\',\'"+ create_day +"\')");
}
tableEnv.executeSql("select * from czs_hive_pojo_mor").print();
}
}
测试结果同1.3.2,如果没有insert,hdfs不会生成表目录。如果有insert,hdfs会生成表目录和分区文件,分区下边只有log日志,没有生成parquet文件,在hive里边有创建两个表,但是由于没有parquet文件,在hive将查询不到数据
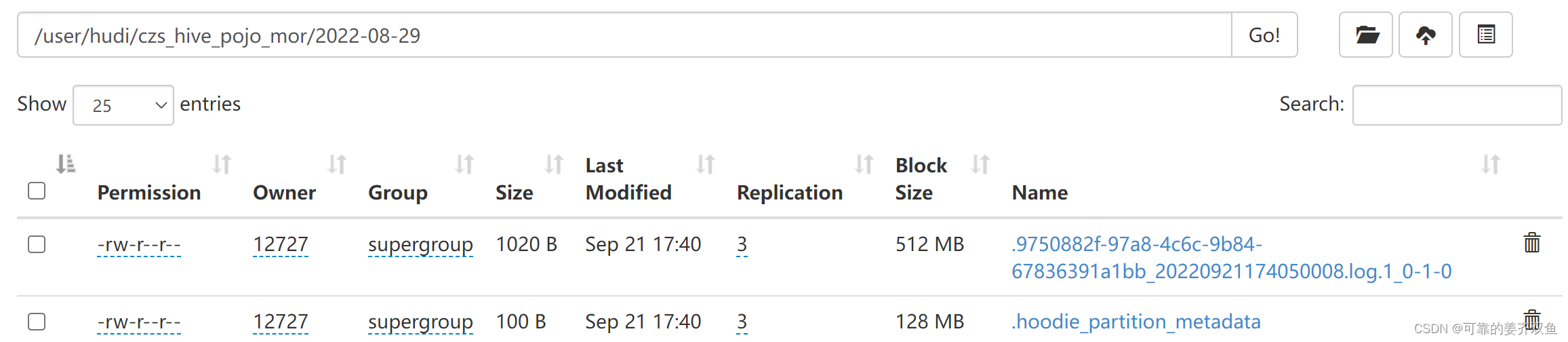
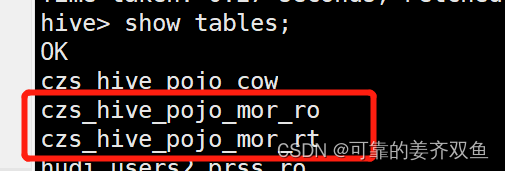
1.5 hudi 的更新和删除
在flink cdc 、flink kafka 或 其他cdc format 入hudi中,hudi可以获取到上游数据的变化,去更新删除数据。
在flink sql 不支持将 "‘write.operation’ = ‘delete’ 的方式删除数据,也不支持delete from语句
在flink sql 不支持update 语句,它的更新的实现方式是inset into 一条已存在的主键数据(‘hoodie.datasource.write.recordkey.field’= ‘id’,这句是指定表的主键是哪个字段),默认是uuid。会通过(‘write.precombine.field’= ‘ts’,这是指定如果存在两条相同主键的数据,根据哪个字段去保留最新的数据),默认是ts,会保留ts大的那条数据
1.6 hudi 的查询
1.6.1 cow表
package work.jiang.hudi.read;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* cow 读取方式:快照查询+增量查询
* 1.Incremental Query
* 默认是Batch query,查询最新的Snapshot
* Batch query: 同时设置read.start-commit和read.end-commit,start commit和end commit都包含,或者设置read.start-commit
* ————————————————
* 版权声明:本文为CSDN博主「Bulut0907」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
* 原文链接:https://blog.csdn.net/yy8623977/article/details/123810836
*/
public class FlinkReadHudiCOWTable {
public static void main(String[] args) throws Exception {
// System.setProperty("HADOOP_USER_NAME", "hdfs");
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
bsEnv.setParallelism(1);
bsEnv.enableCheckpointing(5 * 1000);
StreamTableEnvironment env = StreamTableEnvironment.create(bsEnv, bsSettings);
env.executeSql("CREATE TABLE hudi_users_fields2_cow(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'COPY_ON_WRITE',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users_fields2_cow',\n" +
" 'read.tasks' = '1' \n" +
")");
env.executeSql("select * from hudi_users_fields2_cow").print();
}
}
运行结果,运行一次程序自动停止
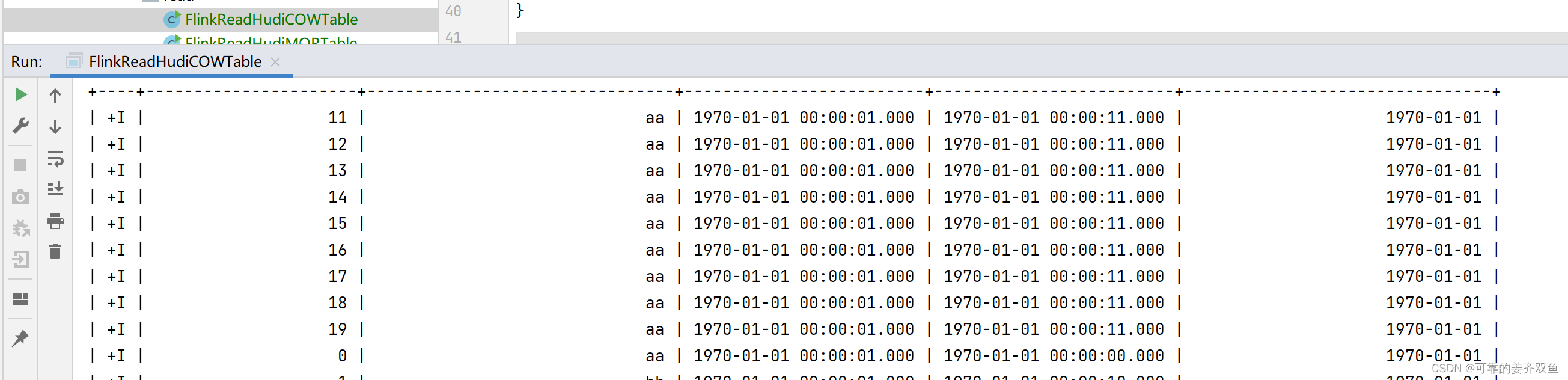
1.6.2 mor表
package work.jiang.hudi.read;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
/**
* mor 读取方式:快照查询+增量查询+读优化查询
* 1.Streaming Query
* 默认是Batch query,查询最新的Snapshot
* Streaming Query需要设置read.streaming.enabled = true。再设置read.start-commit,如果想消费所有数据,设置值为earliest
*
* 2.Incremental Query
* 有3种使用场景
* Streaming query: 设置read.start-commit
* Batch query: 同时设置read.start-commit和read.end-commit,start commit和end commit都包含
* TimeTravel: 设置read.end-commit为大于当前的一个instant time,read.start-commit默认为latest
* ————————————————
* 版权声明:本文为CSDN博主「Bulut0907」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
* 原文链接:https://blog.csdn.net/yy8623977/article/details/123810836
*/
public class FlinkReadHudiMORTable {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "hdfs");
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
//1.Streaming Query
tableEnv.executeSql("CREATE TABLE hudi_users_fields2 (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users_fields2',\n" +
" 'read.streaming.enabled' = 'true',\n" +
//" 'read.streaming.start-commit' = '20210316134557',\n" +
" 'read.streaming.check-interval' = '1', \n" +
" 'read.tasks' = '1' \n" +
")");
tableEnv.executeSql("select * from hudi_users_fields2").print();
/*tableEnv.executeSql("CREATE TABLE hudi_users2_prss (\n" +
" Pid VARCHAR(100) PRIMARY KEY NOT ENFORCED,\n" +
" InVehicleManager VARCHAR(100),\n" +
" BigTypes VARCHAR(100),\n" +
" InVehicleCode VARCHAR(100),\n" +
" CreateTime VARCHAR(100),\n" +
" `CreateDay` VARCHAR(100)\n" +
") PARTITIONED BY (`CreateDay`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' = 'hdfs://cdh01:8022/user/hudi/hudi_users2_prss',\n" +
" 'read.streaming.enabled' = 'true',\n" +
" 'read.streaming.check-interval' = '1', \n" +
" 'read.tasks' = '1' \n" +
")");*/
// tableEnv.executeSql("select * from hudi_users2_prss").print();
env.execute("read_hudi");
}
}
运行结果,程序会一直运行,在’read.streaming.check-interval’ = ‘1’ 设置的频率进行刷新

2. presto 集成 hudi
2.1 presto 部署
参见
https://blog.csdn.net/jiangjiangaa666/article/details/125723084
2.2 创建hive连接器,启动presto
presto 集成hudi 是基于hive catalog, 同样是访问hive 外表进行查询,如果要集成,需要把hudi 包copy 到presto hive-hadoop2插件下面。
presto集成hudi方法: 将hudi jar复制到 presto hive-hadoop2下
cp */hudi-hadoop-mr-bundle-0.11.1.jar $PRESTO_HOME/plugin/hive-hadoop2/
vi catalog/hive.properties
connector.name = hive-hadoop2
hive.metastore.uri = thrift://cdh01:9083
hive.parquet.use-column-names=true
其中,hive.parquet.use-column-names=true设置来解决presto读取parquet类型问题,必填项
2.3 部署 yanagishima
参见https://blog.csdn.net/jiangjiangaa666/article/details/125723084
2.4 使用 yanagishima 查询 hudi