1 新建一个C++ 项目

2 右键添加一个cuda C/C++ file

3 添加下面 lib 库
右键项目->属性->链接器->输入->附加依赖项目:
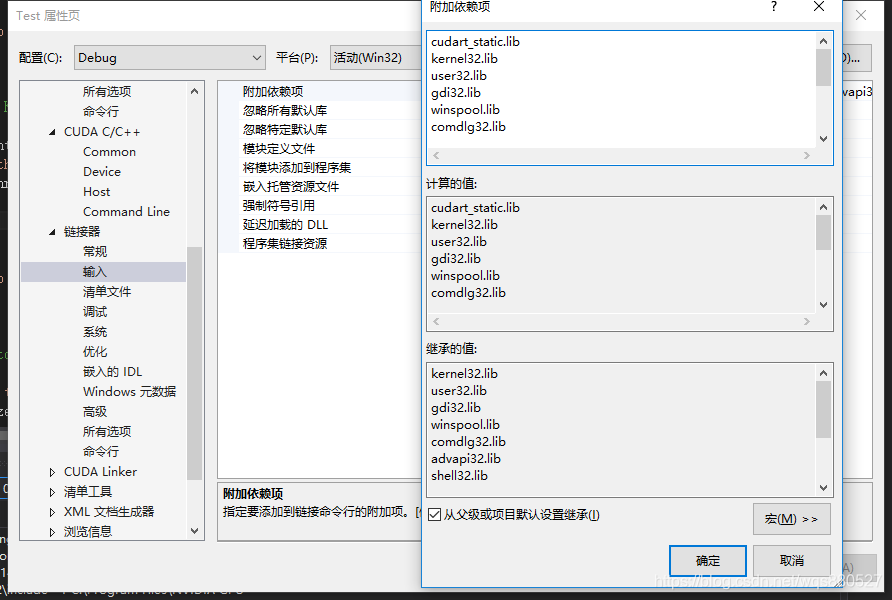
cudart_static.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
comdlg32.lib
advapi32.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
odbc32.lib
odbccp32.lib
4 关键一步 添加自定义生成
右键项目->属性->生成依赖项->自定义生成:

5. cuda.cu文件内容
#include <stdio.h>
#include <random>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
__global__ void
vectorAdd(const float *A, const float *B, float *C, int numElements)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements)
{
C[i] = A[i] + B[i];
}
}
int mainCuda(void)
{
// Error code to check return values for CUDA calls
cudaError_t err = cudaSuccess;
// Print the vector length to be used, and compute its size
int numElements = 50000;
size_t size = numElements * sizeof(float);
printf("[Vector addition of %d elements]\n", numElements);
// Allocate the host input vector A
float *h_A = (float *)malloc(size);
// Allocate the host input vector B
float *h_B = (float *)malloc(size);
// Allocate the host output vector C
float *h_C = (float *)malloc(size);
// Initialize the host input vectors
for (int i = 0; i < numElements; ++i)
{
h_A[i] = rand() / (float)RAND_MAX;
h_B[i] = rand() / (float)RAND_MAX;
}
// Allocate the device input vector A
float *d_A = NULL;
err = cudaMalloc((void **)&d_A, size);
// Allocate the device input vector B
float *d_B = NULL;
err = cudaMalloc((void **)&d_B, size);
// Allocate the device output vector C
float *d_C = NULL;
err = cudaMalloc((void **)&d_C, size);
// Copy the host input vectors A and B in host memory to the device input vectors in
// device memory
printf("Copy input data from the host memory to the CUDA device\n");
err = cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
err = cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Launch the Vector Add CUDA Kernel
int threadsPerBlock = 256;
int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;
printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid, threadsPerBlock);
vectorAdd <<<blocksPerGrid, threadsPerBlock >>>(d_A, d_B, d_C, numElements);
err = cudaGetLastError();
// Copy the device result vector in device memory to the host result vector
// in host memory.
printf("Copy output data from the CUDA device to the host memory\n");
err = cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Verify that the result vector is correct
for (int i = 0; i < numElements; ++i)
{
if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5)
{
fprintf(stderr, "Result verification failed at element %d!\n", i);
exit(EXIT_FAILURE);
}
}
printf("Test PASSED\n");
// Free device global memory
err = cudaFree(d_A);
err = cudaFree(d_B);
err = cudaFree(d_C);
// Free host memory
free(h_A);
free(h_B);
free(h_C);
printf("Done\n");
return 0;
}
6. Main.cpp 文件内容
#include <stdio.h>
#include <stdlib.h>
extern int mainCuda(void);
void main()
{
mainCuda();
system("pause");
}
