一.Yarn基本理论
1.Yarn架构
Resource Manager
- 整个集群资源的统一管理者
- 处理客户端请求
- 监控Node Manager
- 资源的分配和调度
Node Manager
- 单个节点服务器的资源管理者
- 处理来自RM和AM的命令
App Mstr
- 单个任务运行的管理者
- 为应用程序申请资源并分配任务
- 任务的监控和容错
Container
- 相当于一台独立服务器,里面有任务运行所需要的资源,比如CPU、磁盘、网络等,运行MapTask、ReduceTask等

2.Yarn工作机制
1.job.waitForCompletion()产生YarnRunner,和RM申请运行一个应用,RM同意后返回一个路径,告知应用将资源(切片、job.xml、jar包)提交到HDFS上
2.RM将用户的请求初始化为一个Task,放到任务队列里
3.其中一个NodeManager领取到Task任务,该NodeManager创建容器Container生成进程MapReduceAppMaster,Container从HDFS上拷贝资源到本地,并且分析切片信息
3.MapReduceAppMaster向RM申请运行MapTask资源(如果多个MapTask,将根据情况运行在不同NodeManager)
4.MapReduceAppMaster向接收到任务的NodeManager发送程序启动脚本,NodeManager分别启动MapTask,MapTask对数据分区排序
5.MapReduceAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask
6.ReduceTask向MapTask获取相应分区的数据
7.程序运行完毕后,MR会向RM申请注销自己
注:App Mstr、Map Task、Reduce Task都是运行在Container中
3.Yarn调度器
目前,Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler
先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务,生产环境一般不用
容量调度器(Capacity Scheduler)
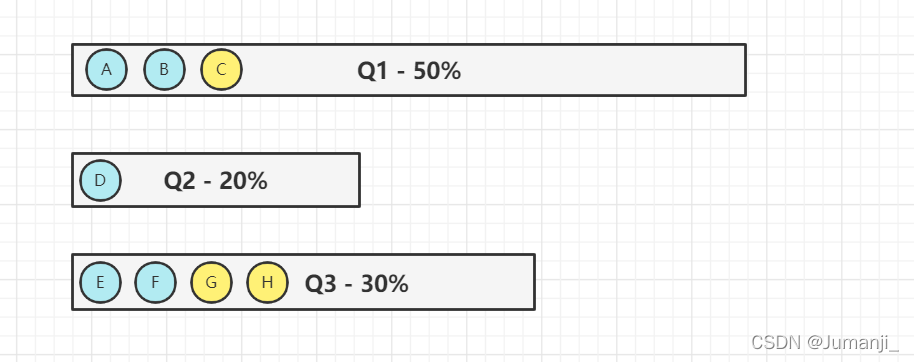
- 多队列FIFO
- 以队列为单位划分资源,每个队列设定一定比例的资源
最低保证和使用上限,比如总资源只有60%资源,那么每一个队列都应该分配到一定资源(这里的资源指的内存资源)
- 规定每个用户对每一个队列只有一定的资源使用上限,以防止资源滥用
- 当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列,但是该队列有新的作业时,资源必须归还
-
每一个队列会对前几个符合资源要求的应用分配资源,比如上述的Q1队列,作业A需要20%,作业B需要25%,那么该队列会把资源分给A和B
容量调度器资源分配算法
队列级别:首先优先选择资源占用最低的队列分配资源,如上面的Q2队列
作业级别:设置优先级,按照优先级;否则按照提交时间顺序
容器级别:设置优先级,按照优先级;否则按照数据本地性原则,任务和数据近的优先
公平调度器
- 多队列FIFO
- 以队列为单位划分资源,每个队列设定一定比例的资源最低保证和使用上限,比如只有60%资源,那么每一个队列都应该分配到资源
- 规定每个用户对每一个队列只有一定的资源使用上限,以防止资源滥用
- 当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列
每个队列公平分布资源,如队列有20%资源,4个作业,每一个任务都会分配到5%资源
公平调度器资源分配算法
队列级别:二次分配:第一次绝对公平分,第二次资源多的队列再给少的队列,实现分配
作业级别
- 不加权 第一次绝对公平,第二次将多的再平分分给少的,第三次再将多的再平分分给少的,直到没有空闲资源
- 加权
根据权重分资源 多的给少的,循环直到没有空闲资源

DRF(dominant resource fairness)
通常的资源都是单一的标准,例如只考虑内存的情况(YARN默认情况),但是多数情况是多种资源的复合,从而难以衡量两个应用应该分配的资源比例,我们就用DRF来决定如何调度,即看哪个资源需求占主导
4.Yarn常用命令
yarn application查看任务
列出所有的Application
yarn application -list
根据Application状态过滤
yarn application -list -appStates XXX(XXX - ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED)
杀死程序
yarn application -kill application-id
yarn logs查看日志
查询Application日志
yarn logs -applicationId <ApplicationId>
查询Container日志
yarn logs -applicationId <ApplicationId> -containerId <ContainerId>
yarn applicationattempt查看尝试运行的任务
列出所有Application尝试的列表
yarn applicationattempt -list <ApplicationId>
打印ApplicationAttemp状态
yarn applicationattempt -status <ApplicationAttemptId>
yarn container查看容器
列出所有Container
yarn container -list <ApplicationAttemptId>
打印Container状态
yarn container -status <ContainerId>
只有在任务跑的途中才能看到container的状态
yarn node查看节点状态
列出所有节点
yarn node -list -all
yarn rmadmin更新配置
加载队列配置
yarn rmadmin -refreshQueues
yarn queue查看队列
打印队列信息
yarn queue -status <QueueName>
5.Yarn参数配置

二 .tool接口
一个tool 接口用于支持处理普通的命令行参数
比如,我们在hadoop集群上输入命令行
yarn jar wc.jar com.gzhu.yarn.YarnDriver wordcount -Dxx /input /output
此时hadoop集群会把参数xx作为输入路径,/input作为输出路径,这样就会报错输出路径存在,为了让hadoop正确识别到输入路径和输出路径是第二个参数和第三个参数,tool接口的作用就来了

YarnDriver
package com.gzhu.yarn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.util.Arrays;
public class YarnDriver {
private static Tool tool;
public static void main(String[] args) throws Exception {
// 创建配置信息
Configuration configuration = new Configuration();
switch (args[0]){
case "wordcount":
tool = new YarnTool();
break;
default:
throw new RuntimeException("no no no");
}
int run = ToolRunner.run(configuration,tool, Arrays.copyOfRange(args,1,args.length));
System.exit(run);
}
}
YarnTool
package com.gzhu.yarn;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import java.io.IOException;
public class YarnTool implements Tool {
private Configuration conf;
@Override
public int run(String[] args) throws Exception {
// 1.获取job
Job job = Job.getInstance(conf);
// 2.设置jar路径
job.setJarByClass(YarnDriver.class);
// 3.关联mapper和reducer
job.setMapperClass(YarnTool.WorldCountMapper.class);
job.setReducerClass(YarnTool.WorldCountReduce.class);
// 4.设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5.设置最终输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean b = job.waitForCompletion(true);
return b ? 0 : 1;
}
@Override
public void setConf(Configuration configuration) {
this.conf = configuration;
}
@Override
public Configuration getConf() {
return conf;
}
// mapper
public static class WorldCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text text = new Text();
private IntWritable intWritable = new IntWritable(1);
@Override // 这里的value是每一行数据
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1.根据原始数据获取一行,转换成字符串,例如 kun kun kun
String string = value.toString();
// 2.切割每一行单词 [kun,kun,kun]
String[] words = string.split(" ");
// 3.循环写出,每一个kun都为1 K-V kun-1,Mapper阶段不汇总,所以每一个都是1
for (String word : words) {
// 将String类型转换成Text类型
text.set(word);
// write里面的参数为输出的两个参数类型 Text, IntWritable
// 这里输出三个kun-1
context.write(text,intWritable);
}
}
}
// reduce
public static class WorldCountReduce extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable intWritable = new IntWritable();
@Override
// key代表每一个key,例如Kun,values是一个集合,里面存的是key对应的V值
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
// 将每一个Key对应的value汇总
for (IntWritable value : values) {
sum += value.get();
}
intWritable.set(sum);
context.write(key,intWritable);
}
}
}