最近使用yolov8进行字符检测任务,因为场景数据是摆正后的证件数据,所以没有使用DB进行模型训练,直接选用了yolov8n进行文本检测,但是长条字符区域检测效果一直不太好,检出不全,通过检测和分割等算法的调试,发现算法本身不太适合作文本检测,然后调试的时候去掉了DFL loss,整个检出效果就可以使用了,目前还没有对DFL loss进行算法分析。修改不使用DFL loss 的代码在:ultralytics-main/ultralytics/nn/modules.py中line 396修改为1:

仅此记录一下。( torch.nn.Identity( ) 作用是输入是什么,输出就是什么)
DFL loss的全称Distribution Focal Loss;首次提出是:https://arxiv.org/pdf/2006.04388.pdf
将框的位置建模成一个 general distribution,让网络快速的聚焦于和目标位置距离近的位置的分布
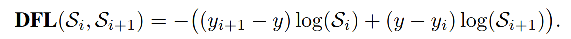
对yolov8 DFL loss的详细解说可参考:
YOLOv8-损失函数 - 知乎