现在新技术迭代非常快,我们一方面要学习掌握更多的新技术,同时我们需要不断的巩固已学的知识,一点点的知识积累终会变成质的飞跃。现在我就想来总结一下java一些常用的面试题。
原文:https://blog.csdn.net/sufu1065/article/details/88051083
参考文章
文章1
一.容器
18.java 容器都有哪些?
答:数组 ,String util包下的集合类。
数组长度限制为 Integer.Integer.MAX_VALUE;String的长度限制: 底层是char 数组 长度 Integer.MAX_VALUE 线程安全的
util包下的所有集合类: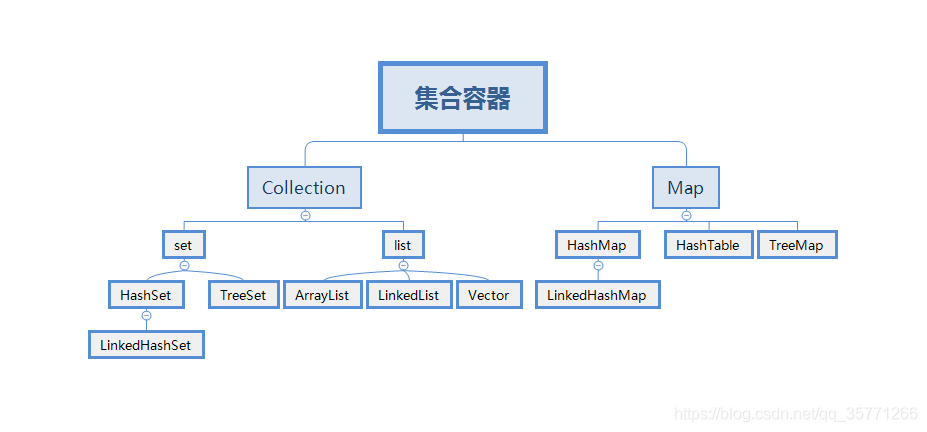
详细地址解释: https://blog.csdn.net/qq_37358860/article/details/100515612
19.Collection 和 Collections 有什么区别?
答:Collection是集合类的上级接口,collection下有List Set,它提供了对集合对象进行基本操作的通用接口方法。
Collections是集合类的帮助类,可对集合类进行排序等操作。
20.List、Set、Map 之间的区别是什么?
答: List. 中的元素可重复,有序。 List 分为ArrayList 和LinkedList Vector。 ArrayList 底层是数组,LinkedList底层是链表 , ArrayList 增删慢,查询快,LinkedList 增删快,查询慢,ArrayList 更加适用于随机访问数据的情况,LinkedList更 加适用于在集合里多次增删的情况,ArrayList 和LinkedList线程不安全,而Vector线程安全。
Set 中的元素,不可重复,Set 分为HashSet 和TreeSet,LinkedHashSet。HashSet底层是哈希表,主要依赖hashcode() 和 equals()俩个方法 ,TreeSet底层是二叉树,元素有顺序。
Map 主要是根据键值对进行存储数据, 根据键查询对应的值,Map 分为HashMap HashTable LinkedHashMap TreeMap HashMap只允许一个key为null ,多条记录为null, HashMap中的元素不可重复,且没有顺序,线程不同步。 LinkedHashMap中的元素有顺序 保留了元素的插入顺序,HashTable线程同步,无序,不允许输入的键值为null。
TreeMap 底层是二叉树,实现sortMap 接口,元素有序。
详细地址解释: https://blog.csdn.net/tangthh123/article/details/104112865
https://blog.csdn.net/qq_35606010/article/details/99243705
21.HashMap 和 HashTable 有什么区别?
答: 1.HashMap 是线程不安全的,HashTable 是线程安全的 。
2.HashMap继承AbstractMap类。HashTable继承自Dictionary类,但二者都实现了Map接口 。
3.HashTable不允许null值(key和value都不可以),HashMap允许使用null值(key和value)都可以。这样的键只有一个, 可以有一个或多个键所对应的值为null。
4.HashMap使用Iterator进行遍历,HashTable使用Enumeration遍历。
等等。
详细地址解释:https://www.cnblogs.com/williamjie/p/9099141.html
https://blog.csdn.net/qq_34602647/article/details/81671067
22.如何决定使用 HashMap 还是 TreeMap?
答:1. HashMap 中的元素没有顺序,而TreeMap中的元素有顺序,HashMap和TreeMap都不是线程安全的。
2. HashMap继承AbstractMap类;覆盖了hashcode() 和equals() 方法,以确保两个相等的映射返回相同的哈希值,而 TreeMap继承SortedMap类;他保持键的有序顺序;
3.HashMap:基于hash表实现的;使用HashMap要求添加的键类明确定义了hashcode() 和equals() (可以重写该方法); 为了优化HashMap的空间使用,可以调优初始容量和负载因子, TreeMap:基于红黑树实现的;TreeMap就没有调优选 项,因为红黑树总是处于平衡的状态。
4.HashMap的遍历是随机的,而TreeMap的遍历是有顺序的。
5.HashMap只允许键值均为null,而TreeMap 不允许键值为null。
23.说一下 HashMap 的实现原理?
答:HashMap基于hashing原理,我们通过put()和get()方法存储和获取对象。当我们将键值对传给put()方法时;它调用键对象 的hashCode()方法来计算hashCode,然后找到bucket位置来存值对象。当获取对象时,通过键值对的equals()方法来找 到正确的键值对。然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞时,对象会存储在链表的下一个节 点。hashMap在每个链表的阶段存储键值对对象。当两个不同的键对象hashCode相同时会发生什么?他们会存储在同一 个bucket位置的链表中。建对象的equals()方法用来找到键值对。
工作原理: Map的put(key,value) 来存储元素,通过get(key) 来得到value值,通过hash算法来计算hashcode值,用 hashcode 标识Entry在bucket中的位置,存储结构计算哈希表等。
详细地址解释:https://blog.csdn.net/vking_wang/article/details/14166593
24.说一下 HashSet 的实现原理?
答:HashSet是基于HashMap实现的,HashSet 底层使用HashMap来保存所有元素,因此HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层HashMap的相关方法来完成,HashSet不允许有重复的值,并且元素是无序 的。
详细地址解释:https://blog.csdn.net/itmyhome1990/article/details/76212556
25.ArrayList 和 LinkedList 的区别是什么?
答: ArrayList底层是数组,LinkedList底层是链表。ArrayList和LinkedList都是线程不安全的,ArrayList更加查询快,增删慢,而 LinkedList 增删快,查询慢。
详细地址解释: https://blog.csdn.net/TTTZZZTTTZZZ/article/details/84916281
https://blog.csdn.net/qq_33300026/article/details/79232006
26.如何实现数组和 List 之间的转换?
答:
List转数组:toArray(arraylist.size()方法
数组转List:Arrays的asList(a)方法
详细地址解释:https://blog.csdn.net/qq_31840023/article/details/87111279
27.ArrayList 和 Vector 的区别是什么?
答:1.Vector中的方法大多加了sychronized关键字,因而是线程安全的,而ArrayList 是线程不安全的。
2. Vector是线程不安全的,因而影响效率,ArrayList 的效率高于Vector。
3.ArrayList以1.5倍的方式在扩容。Vector 当扩容容量增量大于0时、新数组长度为原数组长度+扩容容量增量、否则新数组 长 度为原数组长度的2倍。
4.当Vector或ArrayList中的元素超过它的初始大小时,Vector会将它的容量翻倍,而ArrayList只增加50%的大小,
这样,ArrayList 就有利于节约内存空间。
共同点:ArrayList和Vector都是继承了相同的父类(AbstractList )和实现了相同的接口(List),底层都是数组 (Object[])实现的,初始默认长度都为10。
详细地址解释: https://blog.csdn.net/weixin_43287508/article/details/88065284
28.Array 和 ArrayList 有何区别?
答:Array(数组)里面存储的可以有基本类型和对象类型,而ArrayList里面存储对象类型。
Array 数组的空间大小是固定的,所以需要事前确定合适的空间大小,而ArrayList 的空间是动态增长的,而且,每次添加新的 元 素的时候都会检查内部数组的空间是否足够
详细地址解释 : https://blog.csdn.net/g1998i/article/details/79663976
29.在 Queue 中 poll()和 remove()有什么区别?
答:队列是一个典型的先进先出的容器,队列有俩种实现方式,一个是LinkedList,一个是PriorityQueue。
poll()和remove() 都是返回第一个元素,并在队列中删除返回的对象。,但是在poll()在队列为空时返回null,而remove() 会 抛出NoSuchElementException异常。
详细地址解释:https://www.jianshu.com/p/7c2878c78207
30.哪些集合类是线程安全的?
答: vector ,HashTable statck:堆栈类,先进后出 enumeration:枚举,相当于迭代器
详细地址解释:https://blog.csdn.net/u013239236/article/details/51005976
31.迭代器 Iterator 是什么?
答:链接:https://www.nowcoder.com/questionTerminal/8863f297b1fc4bbca6de95528b6051e1来源:牛客网
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它 可以从两个方向遍历List,也可以从List中插入和删除元素。
32.Iterator 怎么使用?有什么特点?
引自:https://blog.csdn.net/meism5/article/details/89917376
33.Iterator 和 ListIterator 有什么区别?
引自:https://blog.csdn.net/xiangyuenacha/article/details/84253630
34.怎么确保一个集合不能被修改?
刚看到这个题目的我的第一想法就是用final关键字修饰,因为final修饰引用类型的时候,引用地址不变,但是里面的内容其实是可以改变的。此时我们可以使用Collections包下的unmodifiableMap方法,通过这个方法返回的map,是不可以修改的。
示例代码:https://blog.csdn.net/syilt/article/details/90548237