ARIMA时间序列分析
作用:ARIMA时间序列分析通常用于对单列具有时间序列的数据进行预测,例如销售量预测,股票收盘价预测等等
○ 输入:单列数据序列的数据,例如每个月销售额,每天股票的价格,通常数据量为15-50
条;
○ 输出:对未来5-15
天进行预测

ARIMA模型的全称叫做自回归移动平均模型,也记作ARIMA(p,d,q),是统计模型中最常见的一种用来进行时间序列预测的模型。ARIMA模型建模的基本条件是要求待预测的数列满足平稳的条件,即个体值要围绕序列均值上下波动,不能有明显的上升或下降趋势,如果出现上升或下降趋势(不稳定数据),是无法捕捉到规律的,需要对原始序列进行差分平稳化处理。比如股票数据用ARIMA无法预测的原因就是股票数据是非稳定的,常常受政策和新闻的影响而波动,可以使用ADF检验用于稳定性检验,使用差分分析对数据进行稳定性处理。

从步骤上讲,ARIMA时间序列分析共分为五个步骤:
○ Step1:ARIMA模型要求序列满足平稳性,查看ADF检验结果,根据分析t值,分析其是否可以显著地拒绝序列不平稳的假设(p<0.05或0.01)
○ Step2:查看差分前后数据对比图,判断是否平稳(上下幅度不大),同时对时间序列进行偏自相关分析、自相关分析,根据截尾情况估算其p、q值
○ Step3:ARIMA模型要求时间序列数据具备纯随机性,即模型残差为白噪声,查看模型检验表,根据Q统计量的p值对模型白噪声进行检验,也可以结合信息准则AIC和BIC值进行分析(越低越好),也可通过ACF/PACF图进行分析
○ Step4:根据模型参数表,得出模型公式
○ Step5:结合时间序列分析图进行分析,得到向后预测的阶数结果
ARIMA模型案例
1.
数据
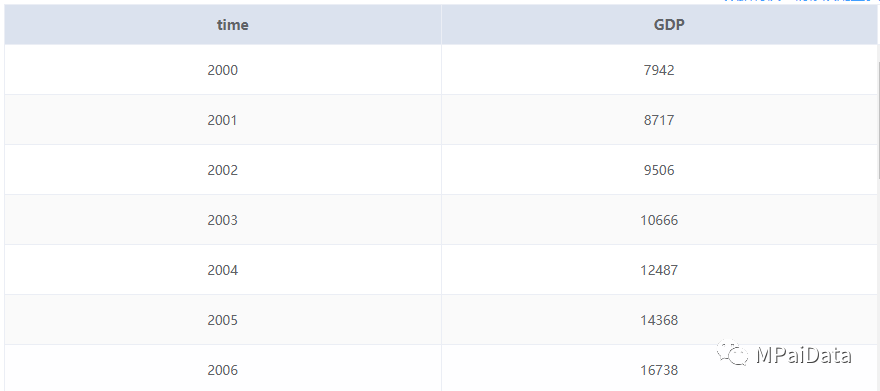
当前已有我国的人均生产总值GDP(2000~2019年)的数据,希望通过这些历史数据预测后面15年的人均GDP情况。部分数据如下(来自我国国家统计局)[2]:
小提示:
○
选择对预测问题有意义的时间单位很重要,比如我国历年人均GDP
、我国历年财政收入等,一般以年作为单位。对于其他的数据集,根据需要可以按月或周为单位。
○
为了保证结果的正确性,时间一般不能有间隔,如2017
,2018
,2020
2.
理论
ARIMA模型主要用法是根据已有的历史数据对未来数据进行预测,其基本思想是将预测对象随时间推移而形成的数据序列视为一个随机序列,用一定的数学模型来近似地描述这个序列。这个模型一旦被识破后就可以从时间序列的过去值来预测未来值。
ARIMA
模型可分为三个部分,AR
自回归模型,I
即差分
,MA
滑动平均模型。
○ AR
模
型:是描述当前值与历史值之间的关系的模型,是一种用变量自身的历史事件数据对自身进行预测的方法
○ MA
模型:自回归模型中误差项的累加,它能够有效地消除预测中的随机波动
○
差分I
:时间序列变量的本期值与其滞后值相减的运算称为差分。滞后值:有些变量的反应会出现延迟现象,比如国家调整货币政策,可能今年出台,要到明年甚至后年才能见效
MPai
能够智能寻优找到最佳的AR
模型,I
和MA
模型,并且给出最终的模型预测结果。
除了MPai
的智能推荐,用户也可以自定义AR
模型、I
和MA
模型,即分别设置回归系数p
,
差分阶数d
(时间序列平稳时所做的差分次数)和移动平均项数q
,然后进行模型的构建。具体如何设置,可以根据MPai
智能提供的p
值或者q
值考虑,以及使用ADF
检验可以得出适合的差分阶数d
值。
3. 操作
本次分析希望得到MPai自动推荐的ARIMA模型,因此4个参数(自回归阶数p,差分阶数d值和移动平均阶数q,向后预测阶数)均采取MPai默认的方式。操作如下图:
4. MPai输出结果
MPai的输出结果共有3个6个图,分别如下:
○ ADF检验表,该表用于检验时间序列是否平稳
○ 最终差分序列图,得到序列平稳后的结果图
○ 最终差分数据的自相关图(ACF)、偏自相关图(PACF),根据截尾情况估算其p、q值
○ ARIMA模型检验表,该表可以反映模型的残差是否存在自相关
○ 模型残差的自相关图(ACF)、偏自相关图(PACF),检验残差是否为白噪声
○ 模型参数表,展示本次模型的参数结果
○ 模型的预测结果(共往后15期的模型预测值)
同时,MPai还输出模型的真实、拟合、预测的折线图,便于用户直观的分析模型的拟合情况和预测情况。
5.
具体分析
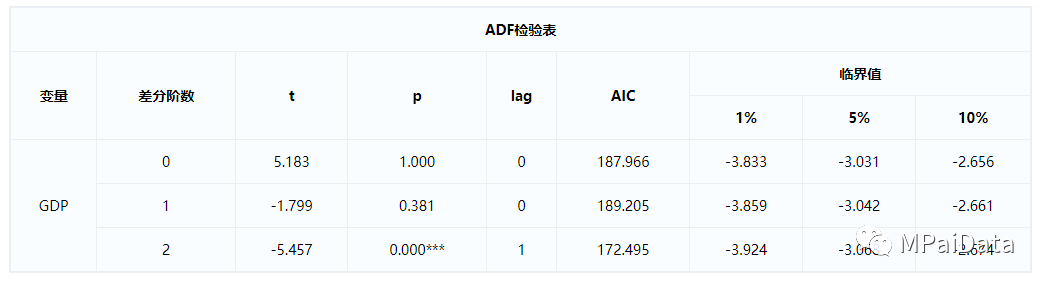
上表展示了模型ADF
检验的结果,包括差分阶数、t
值,显著性P
值,AIC
值等,用于检验时间序列是否平稳。由上表可见,该时间序列数据ADF
检验的t
统计量为5.183
,p
值为1.000
,1%
、5%
、10%
临界值分别为-3.833
、-3.031
、-2.656
。p =1
>0.05
,不能拒绝原假设,序列不平稳。对序列进行一阶差分再进行ADF
检验。
一阶差分后数据ADF
检验结果显示p=0.381
>0.05
,不能拒绝原假设,序列不平稳,对序列进行二阶差分再进行ADF
检验。二阶差分后数据ADF
检验结果显示p =0.000
<0.01
,有高于99%
的把握拒绝原假设,此时序列平稳。
因此在后续进行分析时,应该基于2
阶差分数据进行分析才可以。此外,MPai
还输出了模型最终差分序列图、最终差分数据的自相关图(ACF
)、偏自相关图(PACF
),便于用户直观的分析模型。

上表格展示本次模型检验结果,包括样本数,自由度(Df Residuals)、Q统计量、信息准则和模型的拟合优度。本次模型的构建时,MPai自动构建输出模型为:ARIMA(0,1,1)
ARIMA模型构建后残差一般不存在自相关性,即模型残差为白噪声,查看模型检验表,根据Q统计量的p值,对模型白噪声进行检验,其原假设为:残差是白噪声(p值大于0.1为白噪声);常见情况下直接对Q6进行分析即可,Q6用于检测残差前6阶自相关系数是否满足白噪声。从Q统计量结果看,Q6的p值为0.130大于0.1,则在0.1的显著性水平下,接受原假设,模型的残差是白噪声,模型基本满足要求。拟合优度代表时间序列的拟合程度,
R²的值越接近1效果越好。MPai还提供模型的残差自相关图(ACF)和偏自相关图(PACF),方便用户更直观地分析残差是否存在自相关性。
除此之外,若用户是自己进行模型构建,并希望能够得到对比结果,可以结合信息准则AIC和BIC值进行对比,两值越小越好。此处显示的AIC值已经是各种潜在可能模型的最小值了。
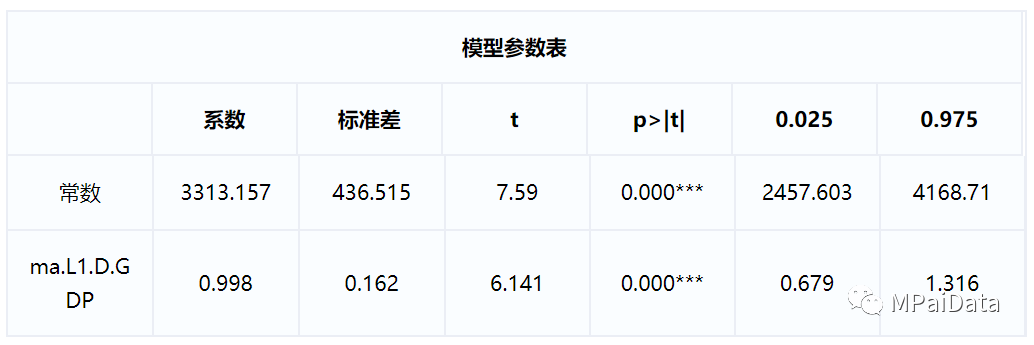
上述表格展示了本次模型参数结果,包括模型的系数、标准差、T
检验结果和置信区间,用于分析模型公式。
本次构建模型时,MPai
自动构建输出模型的公式:
y(t)= 3313.157+0.998*
ε
(
t-1
)
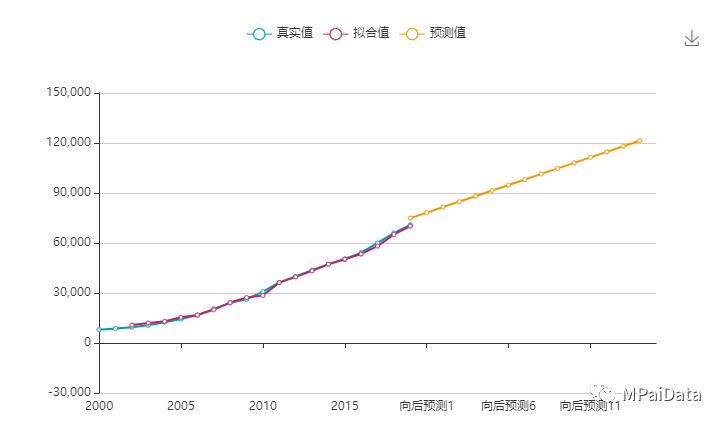
MPai
时间序列图采用不同的颜色,展示了真实值和拟合值的情况,并展示了最近15
期的预测情况。从图可得知,真实数据和拟合数据基本上吻合,说明模型的拟合较好,并且整体呈现出增长的趋势。
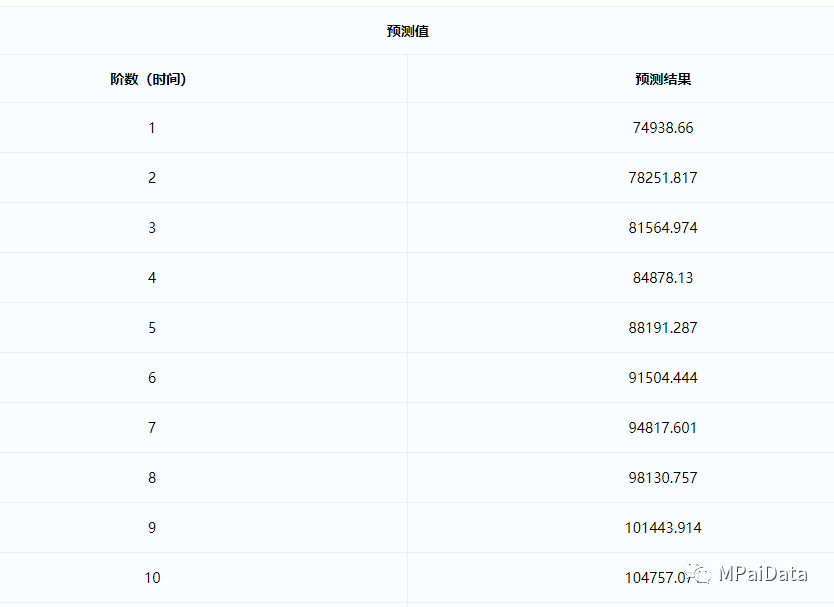
时间序列分析表是本次分析的重点,ARIMA
模型的目的就在于预测未来的数据情况。该表格对接下来的15
期的数据进行了预测,上图展示了部分图表的数据。阶数1
(时间)代表2020
年,向后2
期是指2021
年。根据分析的经验来看,ARIMA
模型预测一般1
期和2
期的结果较为可靠。
使用ARIMA
模型对(2000-2019
)的数据进行预测,最终预测出我国2020
年人均GDP
为74938.66
元。
6.
划重点
ARIMA模型分析中涉及的理论和注意事项,如下:
○
选择对预测问题有意义的时间单位很重要,一般选取能够体现数据的变化规律的。
○ MPai
能够智能寻优找到最佳的AR
模型,I
和MA
模型,并且给出最终的模型预测结果。
○
用户若要自定义回归系数p
,差分阶数d
和移动平均项
数q
,也可参考Mpai
提供的值,自行设置。
○ 若用户没有设定向后预测阶数,MPai默认提供未来15期的预测数据,但针对ARIMA模型来讲,一般情况下向后1期或者向后2期的预测较为准确,往后的预测数据预测准确率较低,通常只作为参考
7.
参考文献
[1] 广州万灵数据科技有限公司.自动数据处理与多协议接入的数据分析平台.https://www.mpaidata.com. 2020-04-22-。
[2] 中华人民共和国统计局.中国统计年鉴[M].北京:中国统计出版社,2018.