数据库中多表联查可以通过连接运算实现,即将多张表通过主外键关系关联在一起进行查询,分为非等值查询和等值查询两大类。
非等值查询语法:
select * from 表1,表2
此查询方式的实质是笛卡尔积的应用,即表1有x行,表2有y行,得到的结果就是x*y行。因此非等值查询在应对数据量较小的情况时可以选择,但当数据量庞大时,采用非等值查询方式会造成大量的数据,从而降低效率,因此不推荐使用非等值查询。
等值查询语法:
select * from 表1,表2 where 表1.字段1 = 表2.字段2....
等值查询是通过where 后面的判断条件去获取自己需要的数据,可以分为以下三种:
左连接: left join
select * from 表1
left join 表2
on 表1.字段1 = 表2.字段1
以left join 左边的表(表1)为主表,从左表中返回所有的记录,即便在右表(表2)中没有匹配的行。
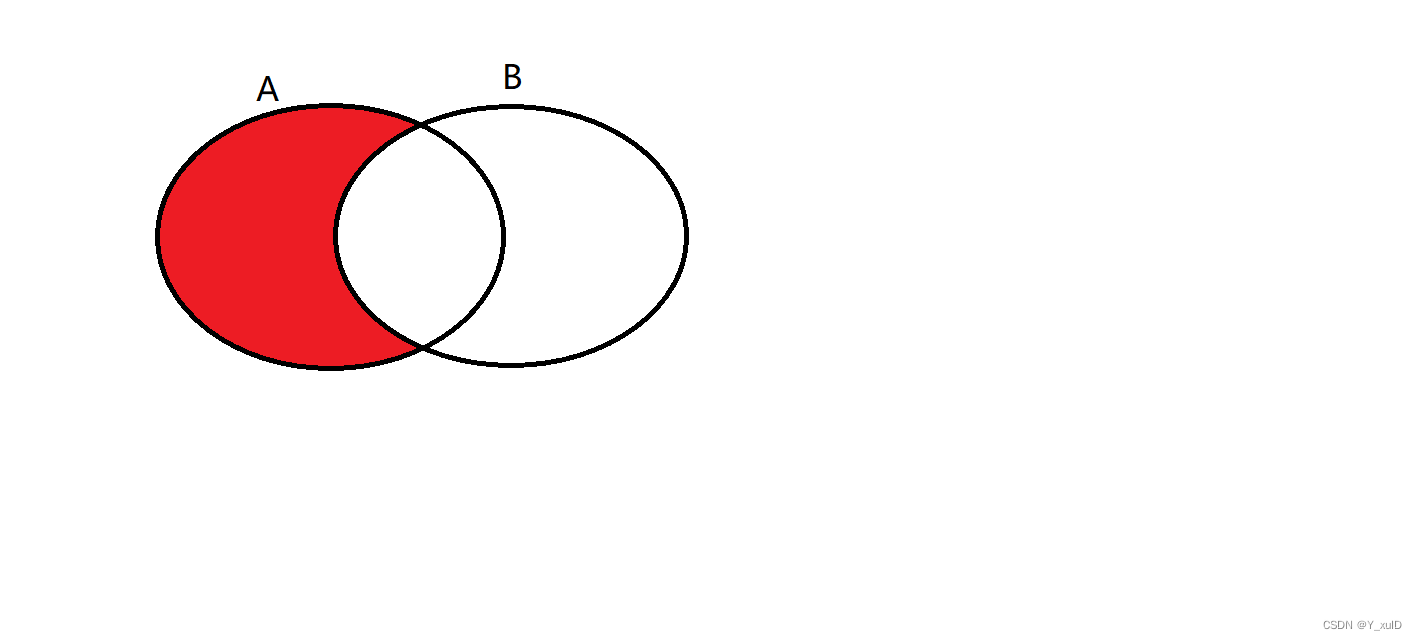
取左表中独有的数据:
on 的后面,根据条件进行过滤筛选,再生成临时查询结果。
where 的后面,从临时查询结果中再根据条件进行筛选,生成最终结果。
select * from A
left join B
on A.id = B.id
where B.id is null
如果是三张表,则可通过两个 left join 来连接,即把前面两张表先 left join 之后当成一张表(虚拟表),然后再与第三张表 left join。
右连接:right join
select * from 表1
right join 表2
on 表1.字段1 = 表2.字段1
与 left join 相对应,右边的表(表2)为主表,从右表中返回所有的记录,即便在左表(表1)中没有匹配的行。
取右表独有的数据:
select * from A
right join B
on A.id = B.id
where A.id is null
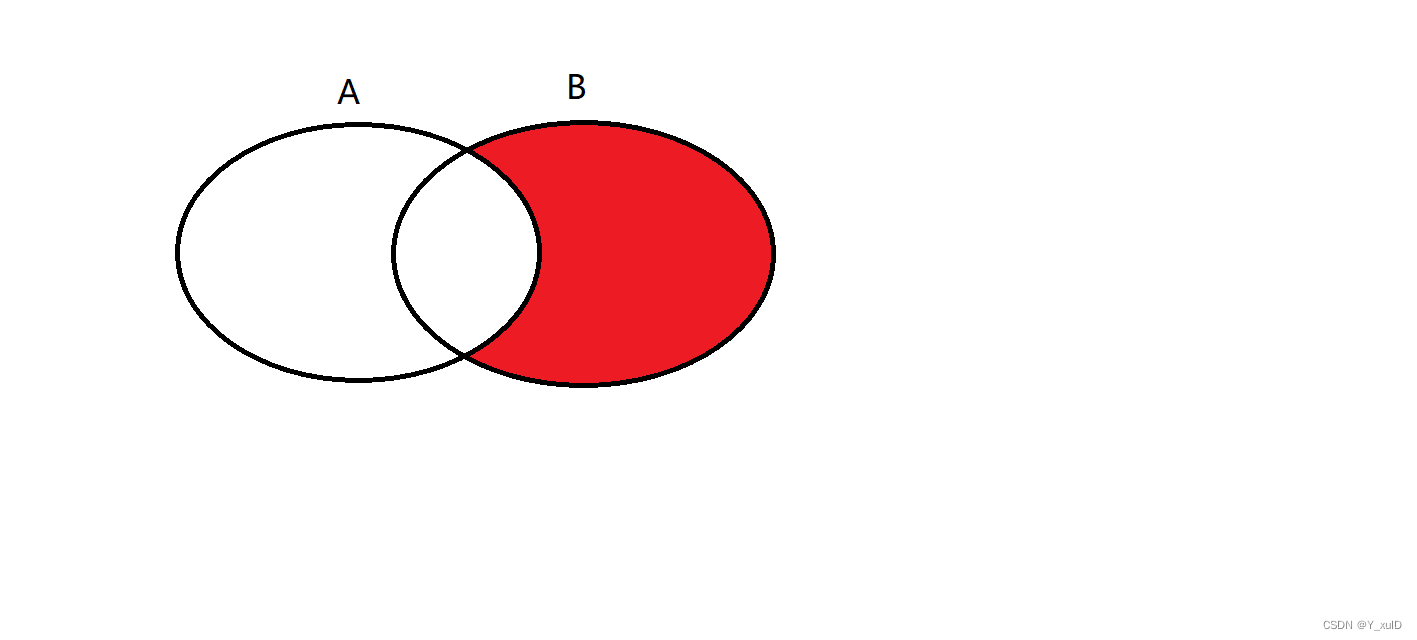
其运行过程与左表同理
交集:inner join
组合两个表中的记录,只要在公共字段中有相符合的值,都会被取到,即在表中至少一个匹配时,就会返回记录,实际结果为两张或多张表的交集。
select * from 表1
inner join 表2
on 表1.字段名 = 表2.字段名
取两表共有的数据
select * from A
inner join B
on A.id = B.id

值得注意的是,inner join不会统计空值
并集:union与union all
union与union all都是求多表的并集,但两种方式得到的结果截然不同,具体如下。
union 语法:
select * from A
union
(select * from B)

可以看到,union合并的是结果集,不区分来自于哪一张表,所有可以合并多张表查询出来的数据,但是会过滤掉重复的数据。
注意:
1.当表列名不一致时,会以第一张表的表头为准
2.不同数据类型可以并到一个列中
3.如果查询的表的列数量不相等是,就会报错
4.每个字句中的的排序是没有意义的,mysql在进行合并的适合会忽略掉,如需要排序,可以对合并后的整张表进行排序
union all 语法:
select * from A
union all
(select * from B)

可以看到,union all 得到的结果也是结果的并集,但是不会把重复的数据过滤掉,而是全部显示出来。
除了以上几种大类之外,在查询中还有许多的子查询,这里暂时不做过多的叙述,虽然我们在做多表联查时可以使用left join,right join,inner join等查询方式,但是阿里巴巴Java开发手册中规定,超过三个表禁止使用join,因为数据量过大时,mysql查询不出来,因此在使用时我们需要注意。
