用于千兆像素全切片病理图像生存预测的多模态下跨模态注意机制的transformer
概念:
premutation invariance(置换不变):指输入顺序的改变不会影响输出值
permutation-equivariant(置换等边):与premutation invariance 相反,输出与输入的顺序有关。
Visual Question Answer (VQA) 是对视觉图像的自然语言问答,作为视觉理解 (Visual Understanding) 的一个研究方向


什么叫做模态(Modality):每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉,听觉,视觉,嗅觉;信息的媒介,有语音、视频、文字等
1、摘要
在计算病理学中,生存结果的预测一直是比较有挑战的若监督任务、有序回归任务,它涉及到在千兆WSI的肿瘤微观环境中模拟复杂的相互作用。尽管在最近的多实例学习中将wsi转化为包的形式取得了一定的进展,但是对于整个WSI的表示学习仍然是一个开放的,有挑战性的问题,尤其是在一下几个方面:
- 在大的包中特征聚合的计算复杂度
- 对于纳入生物先验知识(例如基因测量)的数据异质性差异大
所以在这项工作中,作者提出了一个多模式共同注意力机制的transformer(MCAT)框架,该框架在WSIs和基因特征组成的嵌入空间学习有解释性的,密集的共同注意映射。
受到视觉问答(Visual question answering VQA)的启发:该方法可以确定,在回答问题时,单词嵌入是如何关注图像中的突出对象;当预测病人的生存情况时,MCAT学习病理图像是如何与基因相关的。除了可视化的多模式交互,1) 作者的共同注意力transformer减少了 WSI bags的空间复杂度,2)这也使得transformer 层在多实例学习中能够作为通用的编码器主干。作者将他们的方法运用在5个不同的癌症数据集上,实验结果证明,与最先进的方法相比,该方法始终取得最优异的性能。
1、Introduction
在许多学科中,深度学习已经彻底改变了计算机视觉任务,但是在计算病理学中,数千兆的wsi仍然是一个复杂有障碍的计算机视觉领域任务,这些障碍使得当前的方法对于有监督的学习任务(如癌症预后)不可行。在自然图像的分类任务中,我们的目标通常是指定一个图片级别的标签给一些尺寸接近256256这样更小的图片,标签在图像中清晰可见并很好地表示。
在病理学中,WSIs 打破了这些假设,因为图像表现了巨大的异质性,大小可达1500002像素。根据问题的不同,切片级标签可能是:1)定位在占总图像很小比例的小像素区域中。(一个大海捞针的问题,比如区分正常组织和微转移瘤);2)贯穿于整个WSI的组成部分,并且依赖于组成部分的交互(怎么理解呢,也就是这个切片级的标签,可能单看某一部分无法判断其标签,要整体去评价,充分利用他们的上下文信息。)一个精细的视觉识别问题,例如涉及了解基质、肿瘤聚集、免疫细胞和其他视觉概念的复杂环境的问题。
由于WSI具有巨大的上千兆分辨率,许多方法采用两阶段的多实例学习来解决WSI的表示学习,在MIL中,1)随机在WSI中采用图片并提取他们的实例级别的特征表示,2)然后在实例级别组成的包中运用全局聚合策略去获得WSI级别的表示来进行后续的监督任务。虽然在实例级之间不能去建立这种复杂的相互反应,但是,多实例学习(MIL)可以解决病理学中许多大海捞针的问题(needle-in-a-haystack problems),例如正常组织和微转移的分类,它仅依赖于区分二元实例级的视觉感念(也就是不需要上下文信息),
1.2、然而生存分析是一个有挑战的有序回归任务,它旨在去预测癌症死亡的相对风险,它适用于后续的精细度视觉识别问题。
1.3、相比于那种大海捞针的问题(去找有没有,比较小、少的目标),生存结果预测需要对肿瘤微环境中的各种视觉概念进行建模,而传统的MIL方法无法区分这些概念,例如对肿瘤细胞和淋巴细胞的共同定位可以得到一个良好的预后结果,而这需要对WSI中实例之间的中长期相互作用进行建模。
1.4、虽然通常仅使用千兆像素WSIs作为弱监督任务,但生存结果预测传统上被视为多模式学习任务,其中基因组信息可作为监督或整合的附加模式,在当前最先进的技术中,病理学家对组织学和基因组学的手动评估是患者分类、风险评估和分层到治疗组的金标准(人的标准还是金标准)。**在利用多模式融合机制进一步扩展弱监督学习的过程中,由于WSIs和基因组学之间的巨大数据异质性差距,生存预测面临着额外的挑战:**由WSI形成的 包包含数万个图片实例,而基因组特征通常是一些1*1的表格属性。因此,**许多方法后期使用融合机制进行特征融合,但这也阻碍了学习到中国要的多模态交互信息。**总的来说,利用WSI进行癌症预测既是一个困难的弱监督学习问题,也是一个多模式学习问题,也是许多癌症亚型疾病进展表征方面的一个巨大挑战
1.5 为了解决这些挑战,本文提出了一个可解释的,若监督的多模式学习框架(MCAT),它可以在WSI和基因之间学习一个密集的、共注意力机制的映射,以此来解释生存预测。受到深度学习在视觉问答应用上的启发,该方法学习在回答问题时单词嵌入是如何处理图像中突出对象的关系。在这篇文中,但预测病人的生存情况时,实例级别的病理 图像如何关注基因信息,这篇文章的一个主要贡献是:文中使用一个跨模态的注意力机制(cross-modality attention, co-attention),也被称为基因指导的跨模态的注意力机制,以此来作为早期的融合策略,他使用基因组特征作为查询从大型置换不变集中识别信息实例,这个生存分析带来了两个好处:
- 与后期通过拼接WSI级别包的表示和基因特征进行融合相比,GCA(基因指导的跨模态的注意力机制)捕获了多模态相互作用,这些相互作用将基于组织学的视觉概念与类似于VQA(视觉问答)的基因嵌入联系起来
- 本文展示了GCA层是如何将WSI包的有效”序列长度“从M个实例级特征减少到N个基因引导的视觉概念。N是基因嵌入的有效序列长度集合(M>>N),这也使得我们能够使用self-attention 和Transformers进行监督训练开发更复杂的功能聚合策略,这在以前是不可能的。另外,我们在基于集合的数据结构(包)上运行的多实例学习和transformer之间建立和联系(简言之就是将多实例学习和transformer联系起来)
1.5、从表1 来看,MCAT超越了使用wsi来进行生存分析的现存最先进的若监督方法,和多模态网络(在后期融合的时候,很传统的将WSI和基因信息进行聚合。作者在五大公开的癌症数据集上进行了消融研究,与之前所有的方法相比,始终提高3.0%—6.87%。最后作者将基因指导的视觉概念可视化为热图,以此来分析WSI和基因之间特征的相互作用。并评估形态特征如何影响每个基因的模态
2、相关工作
2.1、在千兆像素图片上的若监督学习
在使用多实例学习和其他基于集合的深度学习和其他基于集合的深度学习方法进行千兆像素图片中的学习任务方面,取得了显著的进展。Edwards、Storkey、 Zaheer等人提出了第一个用于集合监督学习的神经网络体系结构,随后Llse等人扩展了基于集合的深度学习作为MIL的一般框架,并应用于病理学。
2.2、自从Vaswani等人开创性的工作依赖,注意力机制已经被广泛应用于神经机器翻译之外的许多不懂领域,例如语言模型预训练,视觉识别,视觉问答,图神经网络和点云方面。语言建模之外,Lee等人开发了集合transformer 框架,他将原始的语言transformer扩展到一般的结构集合(set-structured)的数据结构上,例如,点云数据,计数问题等。Dosovistskiy 提出使用transformer的框架在自然图像上进行图像的预训练,在这个方法 中,224224的图片被有序的展成1616的image patches.最近Kalra 等人使用set transformer 来进行肺癌(lung cancer)的亚分类,在这个方法中,包(bag)是随机从病理切片采样的100个patches,对于一个完成的WSI来说,是一个尺度很大的(large-scale)表示学习,虽然可以很自然的将WSI转化为patch的序列(sequence)或是包(bag),但是相比于单词嵌入来说,单词嵌入最大长度最多512dim,而对于一个20倍放大下的wsi,他的包的尺寸包含大约15000个256*256的image patches,最大的序列长度有200,000个patch,由WSI巨大的空间复杂性,使用Transformer 和一些其他的堆叠的自注意力的网络框架,在相应的MIL任务中,是一个计算行不通的。
2.3、多模态的深度学习
由于跨多模态的统计特性和噪声水平的异构型,通过多模态深度学习,学习联合表示是一项具有挑战性的任务,为学习到一些共享的表示,一些融合操作比如特征拼接,逐元素相加、相乘
,双线性池化,跨模态的注意力机制通常被应用于一些多模态学习任务中,像VQA(视觉问答),情绪分析(sentiment analysis),生存分析还有一些其他的机器学习任务。在病理学中,Mobadersany使用特征拼接来对病理学特征和基因特征进行聚合,然后做生存预测;Chen等使用kronecker product 来对image,graph,和基于基因的特征进行聚合,虽然都是多模态,但是许多方法都是基于后期融合的,特征只融合到了倒数第二层网络,并且提供了有限的多模态交互解释能力。此外,与VQA(视觉问答)中使用跨模态注意学习将图像特征与单词嵌入联系起来的多模态融合方法相比,当前使用WSIs的多模式工作没有类似的解释机制,可以将WSIs中的组织学特征与基因组学联系起来。
3、方法
在3.1中使用一个实例级别的特征提取器将WSI和基因的表示组成一个包(bag),在3.2中提出了本文的核心方法,基因指导的跨模态的注意力层(Gennomic Guided co-attention layer),t他可以在WSI和基因的包的表示中学习一个密集的跨模态注意机制映射,并且可视化多模态的相互作用,作者也证明了这个GCA层是如何可以减少WSI bags的空间复杂度,在多实例学习中,作者使用基于集合的Transformers 来进行生存结果预测;在3.4中,详细讨论了实施细节,关于生存损失函数的进一步描述在附件材料里。
3.1 WSI 和基因包的构建
问题表述(problem formulation):多实例学习是一个若监督的学习任务,这种框架是在基于集合的数据结构上进行操作,这种基于集合的数据结构也称作包,每一个 包是一个无序的实例集合(具有置换不变性,permutation-invariant),这些包的大小可能不同,实例级别的标签不完整。对于单标签分类,给定一个包X = {x 1 ,…,x M },目标是学习一个置换不变函数来预测这个包的标签,而不需要一些详细的实例知识;一般形式如下:

生存模型并不直接估计OS,而是输出通过累计分布函数获得的顺序风险值,
实例级别的特征提取器
为了将病人的WSI表示为一个单一的包,作者模仿传统多实例学习中包的构建,作者也是从wsi的patch中去提取特征,但是和传统的方法不同的是,本文构建这样的包用到了所有可用的wsi中的patch(一个病人可能有多个wsi),而不是在ROI中去采样patch,对于patch切割的方式,采用不重叠的切割(大小为256*256),然后用一个Resnet-50+ fc(在ImageNet上预训练)的模型进行特征提取。在跨多个WSI利用整个组织微观环境的过程中,训练和推理期间,平均包的大小包括115231个实例,而最大的包包含230,000个实例。从这一步开始,传统方法运用加法等进行全局聚合形成最后的特征输出,然后后面跟一个拼接或是双线性池化和基因进行融合
在嵌入空间表述基因(formulating genes in an embedding space),
基因组特征(如基因突变状态、拷贝数变化和大量RNA序列丰度)通常量化为1×1测量值或属性,仅此一项不包含任何语义信息来描述基因在生物系统中的功能影响。
基因特征包括六类:1) Tumor Supression(肿瘤抑制)2)瘤形成 3)蛋白激酶类 4)细胞分化 5)转录 6)细胞因子与生长
3.2、基因指导的跨模态注意力层
直观的说,对于单个基因嵌入,GCA层去计算该基因嵌入和所有的patch特征的相似度,记作:
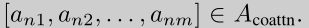
这样的相似度分数被用来去计算一个新的patch嵌入。举一个简单的例子,如果Gin是表达潜在的生物通路的基因嵌入(这个通路负责肿瘤形成),那个这个相似度分数将会聚焦定位在含有肿瘤区域的图像上,并高度关注这个图像,然后聚合这些特征作为WSI级别的表示
5、总结
作者提出了MCAT来对病理图像进行生存结果的预测,这个方法将wsi和基因的特征转化为置换不变集合,从这里面,作者在多实例学习中通过transformer attention开发了更复杂的特征聚合策略。当前工作的一个限制是使用的特征是以前整理的基因集合,该基因集合具有潜在的重叠功能影响(用人话说就是这些基因集合中可能有的基因表达的功能是重叠的,多个基因可能表达同一个功能),所以未来的工作将侧重于研究WSI与更细粒度、更独特的生物基因集的早期融合,进一步量化表型-基因型的对应关系。