这篇文章基于ESPCN提出了针对视频重建任务的网络结构VESPCN。ESPCN在图像和视频重建任务上都相比先前的方法都有一定的提升,但ESPCN只能对单帧图像进行重建,并不能利用视频多帧图像的时间相关性信息。该模型由对齐网络和融合时空亚像素网络组成,能够有效利用时间冗余,提高重建精度,同时保持实时速度。
文章连接:Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
参考目录:
超分之VESPCN
Pytorch源码
VESPCN:Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
- Abstract
- 1 Introduction
- 2 Method
- 2.1 Spatial transformer motion compensation
- 2.2 Spatio-temporal networks
- 2.2.1 Early fusion
- 2.2.2 Slow fusion
- 2.2.3 3D convolutions
- 3 Experiments
- 4 Conclusion
Abstract
这篇文章是ESPCN的升级版本,ESPCN是一种SISR方法,但也可以针对视频做超分(视频只不过是连续多帧的图像)。它利用亚像素卷积实现了非常高效的性能,但其只能处理独立帧,对视频的简单扩展未能利用帧间冗余,也无法实现时间一致性。
对此,作者提出了能够利用时间冗余信息的时空亚像素卷积网络VESPCN,该方法主要针对视频超分,将ESPCN结构扩展成时序空间网络结构(Spatio-temporal Network),将时间信息加入到网络中,可以有效地利用时间冗余信息,提高重建精度,同时保持实时速度。
- 提出了一种新的
联合运动补偿算法,该算法比其他方法效率高几个数量级,依赖于一个端到端可训练的快速多分辨率空间变换模块。 - 提出了
多帧的融合方法,分别使用早期融合、慢速融合和3D卷积融合对多个连续视频帧进行联合处理,通过实验研究三种方法的优劣。
1 Introduction
单图像SR中 :利用局部相关性的图像空间冗余,通过施加约束或其他类型的图像统计信息来恢复丢失的高频细节。
在多图像SR(视频)中 :假设同一场景的不同观测值可用,因此可以使用共享的时间冗余来约束问题。
从图像到视频的转换意味着加入一个具有高度相关性的额外数据维度(时间),可以利用它来提高准确性和效率。
- 在网络对齐部分,引入运动估计和补偿,是进一步约束问题和保留时间相关性的重要机制。运动补偿机制使用的是空间转换网络STN,其本身能够获取两幅图像之间的空间映射关系,且它是一个独立的网络,可以与针对其他目标任务的网络无缝结合并共同训练,以提高其性能。
- 网络融合部分,研究了早期融合、慢速融合和3D卷积融合对时间维度的不同处理。
在本文中,作者将亚像素卷积的效率与时空网络结合起来,提出了一种基于空间变换的运动补偿和三种不同的融合多个相邻帧的方法,是一种端到端可训练的高效解决方案。
本文的主要贡献是:
- 提出了一种基于亚像素卷积和时空网络的实时视频SR方法VESPCN,提高了SR重建的准确性和时间一致性。
- 比较早期融合、慢速融合和3D卷积融合三种方法。
- 提出了一种基于多尺度空间变换网络的密集帧间运动补偿方法。
- 将提出的运动补偿技术与时空模型相结合,提供了一种高效、端到端可训练的运动补偿视频SR算法。
2 Method
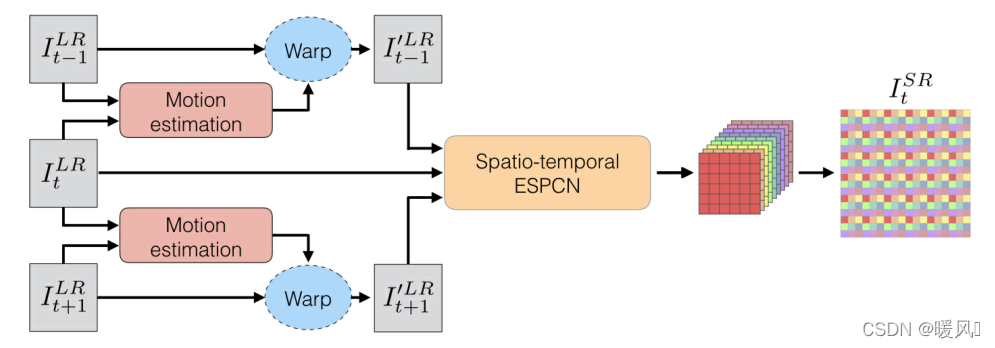
VESPCN主要由Motion-Estimation网络和Spatio-Temporal网络组成。(对齐+融合)
运动补偿网络: 以STN网络为基础,预测出前后帧的像素值。
时序空间网络: Spatio-Temporal网络是以ESPCN为基础的SR网络,其主要利用亚像素卷积层来进行上采样,此外该模块需要结合early fusion、slow fusion或者3D卷积来将时间信息加入进来。
由于STN网络本身就是可导的,因此整个运动补偿+时序空间网络的训练是一个端对端的训练。VESPCN中整个运动补偿网络在VSR中本质就是个时间对齐网络,其基于Flow-based方法,属于Image-wise。
事实上没有运动补偿模块,仅靠时序空间网络,也能够实现比较好的重建性能,但运动补偿使得前后帧内容上更加对齐增强了相关性,在时间上更连续。作者在实验部分也证实了这一点。
★★★简单梳理一下整个网络结构:★★★ 按图中:
- 输入三帧图像,当前帧
I
t
L
R
I_t^{LR}
ItLR作为参考帧,前后两帧作为支持帧,前一帧
I
t
−
1
L
R
I_{t-1}^{LR}
It−1LR和后一帧
I
t
+
1
L
R
I_{t+1}^{LR}
It+1LR分别与当前帧
I
t
L
R
I_t^{LR}
ItLR做一个运动补偿得到两张warp后的图像
I
t
−
1
′
L
R
I_{t-1}'^{LR}
It−1′LR和
I
t
+
1
′
L
R
I_{t+1}'^{LR}
It+1′LR。
这个过程的目的是使前一帧
I
t
−
1
L
R
I_{t-1}^{LR}
It−1LR尽量变换到当前帧
I
t
L
R
I_t^{LR}
ItLR的位置。当然后一帧也是相同。这也就是前面一直说的对齐。把三张图像减少偏移,尽量保持一致,这样在内容上有更多的相关性,时间上也更加连续。因为支持帧不可能变换到与参考帧完全一样的,还是会有所差别,只是差别变小了,可以看成是两张图中间插入新的一帧,所以运动的连贯性被大大加强了。图中的ME模块是以STN为基础的一个加入时间元素的变体TSTN。后面会详细介绍。
- 将得到的三张warp后更加相近的图像输入时序空间网络中进行融合,其实就是结合三张图像一起提取特征,最后使用亚像素卷积层Pixel-Shuffle上采样重建图像输出
I
t
S
R
I_t^{SR}
ItSR。
这个融合的过程有三种方式:early fusion、slow fusion、 3D卷积。最简单的早期融合early fusion其实就是直接在时间维度上拼接三张图像,然后一起提取特征。融合部分其实是指用怎样的方式结构时间信息去提取特征。
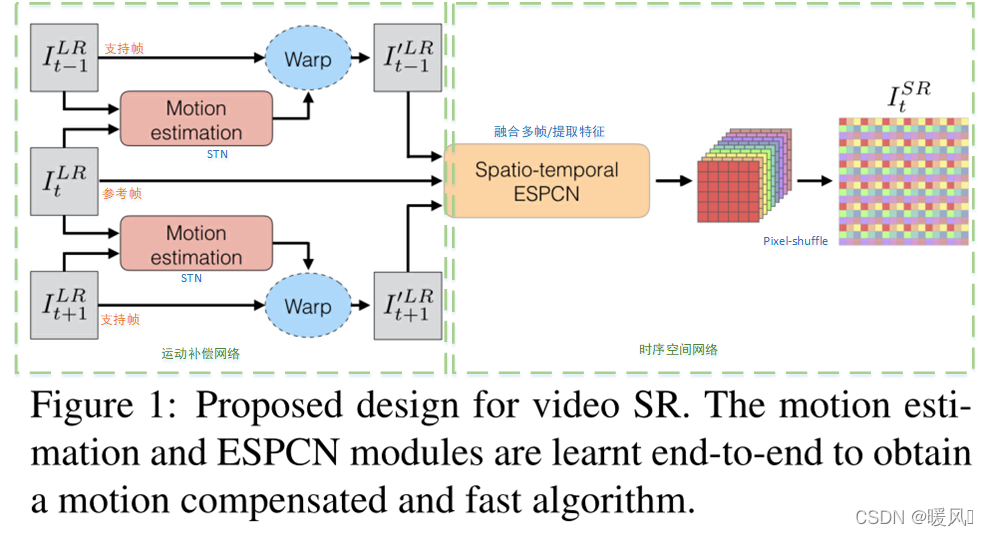
以下三点介绍顺序和论文中不同,是按照网络前后顺序进行介绍的。
2.1 Spatial transformer motion compensation
首先使用高效的空间变换网络来补偿帧之间的运动再将结果输入SR网络。空间变换器可以有效地对光流进行编码,适用于运动补偿。首先在两个帧之间引入运动补偿。
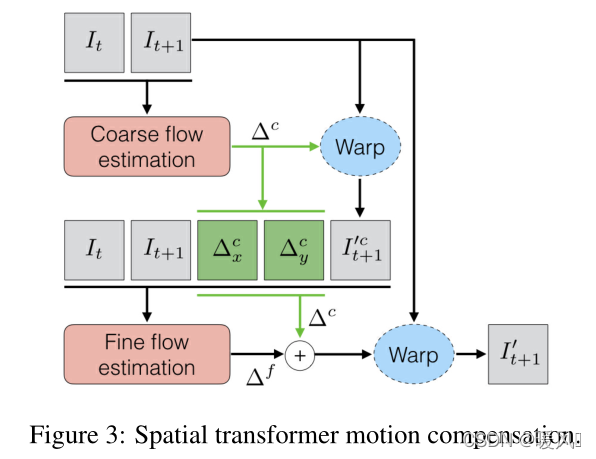
粗略估计:
当前帧
I
t
I_t
It和后一帧
I
t
+
1
I_{t+1}
It+1同时输入,首先做一个粗略光流估计,计算两张图像的运动矢量
Δ
c
Δ^c
Δc,在当前帧
I
t
I_t
It的基础上加上运动矢量后得到
I
t
+
1
I_{t+1}
It+1的坐标图(此处做的是一个坐标位置的转换计算,不涉及像素值),这一步中会产生很多小数,像素位置都是整数值,所以我们需要利用双线性插值来获得对应位置的像素值。这一步也就是重采样warp。得到粗略估计后的
I
t
+
1
′
c
I_{t+1}'^c
It+1′c,如下图,这里借用博主Ton的图。
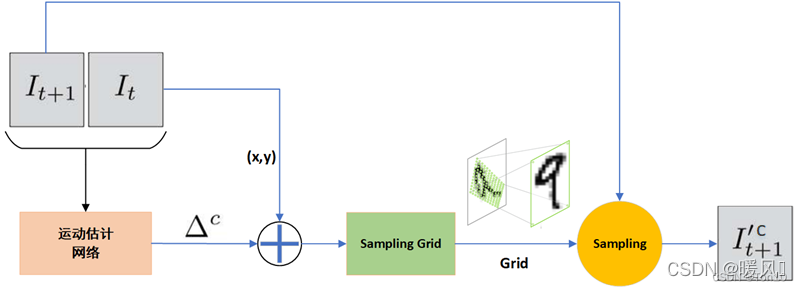
精确估计:
将得到的粗略估计后的
I
’
t
+
1
c
I’_{t+1}^c
I’t+1c和
I
t
I_t
It、
I
t
+
1
I_{t+1}
It+1以及得到的
Δ
x
c
Δ^c_x
Δxc、
Δ
y
c
Δ^c_y
Δyc一起输入到精确光流估计模块中,得到一个
Δ
f
Δ^f
Δf,这是一个用以修正
Δ
c
Δ^c
Δc的一个差值,将它和
Δ
c
Δ^c
Δc相加,获得精确的运动矢量,重新估计
I
t
+
1
I_{t+1}
It+1,进行重采样warp,得到最后的精确估计
I
t
+
1
′
I'_{t+1}
It+1′。
★ 这一步到这为止,很可能理解上真的是按精确估计
I
t
+
1
I_{t+1}
It+1为目的走的。但是想一想我们前面说了,目的是使支持帧(前后相邻帧)对齐到参考帧,也就是说要网络要去学习如何减少偏移量
Δ
c
Δ^c
Δc,所以可以看到损失函数求的是精确估计
I
t
+
1
′
I'_{t+1}
It+1′和当前帧
I
t
I_t
It的差。这一环节的公式:(后面一项是正则化项)
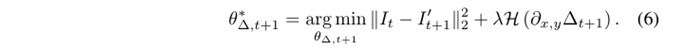
2.2 Spatio-temporal networks
这一节我觉得是VESPCN最重要的部分,如何去利用时间信息。时序空间网络分为两块:提取特征(融合)+ Pixel-shuffle上采样。
本文主要讲述如何进行特征提取,Pixel-shuffle部分可以参看ESPCN。
在一张图像本身,我们利用图像内空间冗余信息来进行特征提取;而在多张连续图像,我们就要充分考虑到时间上的连续性,产生很多冗余的时间信息。利用时间上的冗余我们可以更快更好的重建SR图像。
作者提出的时序空间网络就是一个添加了时间信息的ESPCN升级版。我们前面所说的融合就是指用什么样的方式利用时间信息去提取多张相邻图像的特征。
图像层面的特征提取本质是利用了图像中的空间冗余性质,采用一个卷积核去逐步提取图像的特征信息;而对于视频来说,除了像素间的空间冗余特性,还有相邻帧之间的时间冗余特性。因此在时序空间网络中我们引入时间维度
D
l
D_l
Dl,其表示第
l
l
l层时间的深度,比如连续3帧进行合并之后,
D
l
=
3
D_l=3
Dl=3。在论文中,作者设置初始时间深度为
D
0
D_0
D0 (奇数),表示输入端有
D
0
D_0
D0帧图像,故时序半径为
R
=
D
0
−
1
2
R=\frac{D_0-1}{2}
R=2D0−1,所以输入端的LR图像组可以表示为
I
[
t
−
R
,
t
+
R
]
L
R
∈
R
H
×
W
×
D
0
I^{LR}_{[t-R,t+R]}\in\mathbb{R}^{H\times W\times D_0}
I[t−R,t+R]LR∈RH×W×D0,于是LR图像
I
L
R
I^{LR}
ILR重建成HR图像
I
S
R
I^{SR}
ISR的公式可以表示为:
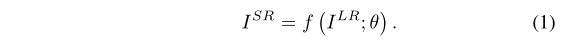
其中
θ
\theta
θ是SR模型的参数,
f
(
⋅
)
f(\cdot)
f(⋅)表示
S
R
→
H
R
SR\to HR
SR→HR的映射关系。第
l
l
l层滤波器参数
W
l
W_l
Wl的shape为
d
l
×
n
l
−
1
×
n
l
×
k
l
×
k
l
d_l\times n_{l-1}\times n_l\times k_l\times k_l
dl×nl−1×nl×kl×kl,其中
d
l
d_l
dl 表示滤波器每次卷积的时间帧数。彩色图像表示feature map拥有时间维度,其具有多种时间信息的融合,而灰色图代表只具备一种时间信息(时间维度为1)或者忽略时间信息。
作者提出了三种融合方式:Early fusion、3D convolutions、Slow fusion。作者在后面的实验中也对比了使用不同融合方式带来的性能优劣。
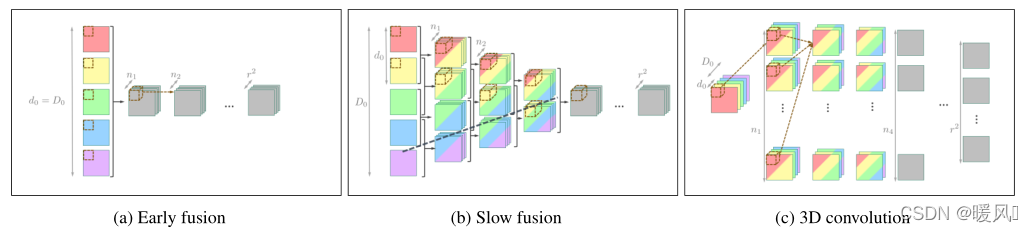
2.2.1 Early fusion

Early fusion是最简单的一种时序融合方式,如上图所示,它只需要在卷积之前的输入层直接concat不同时序的信息(这种就是通常的多通道卷积),图中
D
0
=
5
D_0 = 5
D0=5表示输入是相邻的5帧图像。而之后就像对待普通图像一样去用卷积来提取特征即可。
2.2.2 Slow fusion
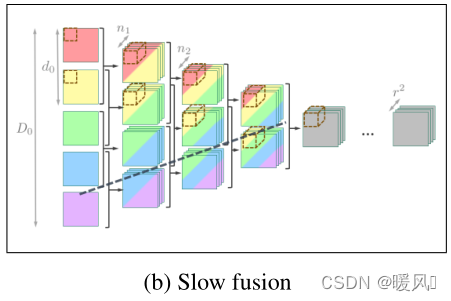
缓慢融合是指每次融合指定帧数的图像,早期融合是缓慢融合的一个特例,早期融合是一下子所有帧都融合。如图
d
l
=
2
,
d
l
∈
[
1
,
D
0
)
d_l=2,d_l\in [1,D_0)
dl=2,dl∈[1,D0),其表示第
l
l
l层需要融合2个时间帧并做特征提取。每层都要指定帧数融合,每次都按帧数进行concat然后进行卷积,直到最后维度缩小到了1,后面就和普通卷积一样提取特征。Slow fusion从头到尾一直保留着时间信息,不同帧的卷积参数是不共享的。
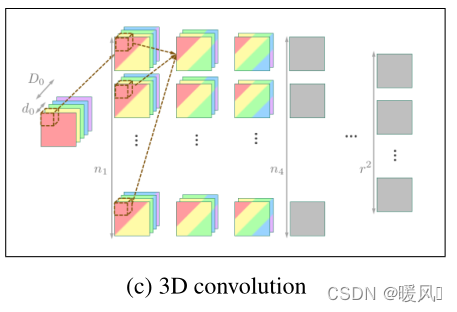
2.2.3 3D convolutions
慢速融合的另一个变体是强制在时间维度上共享权重,这种架构相当于使用3D卷积。也就是说3D卷积是Slow fusion的权重共享版本,3D卷积核在时间维度上共享参数,因此能够节约很多运算资源。多通道卷积的滤波器只是在2D平面上左右上下移动,而3D卷积可以在2D平面以及时间轴上移动。3D卷积的对象是
C
×
T
×
H
×
W
C\times T\times H\times W
C×T×H×W,因此可以看成是
C
C
C个
T
×
H
×
W
T\times H\times W
T×H×W的立方体,对于每个立方体都用一个小立方体滤波器去抽取特征,并且共享同一组参数,不同通道才使用不同的滤波器参数,3D卷积只是其本身卷积核存在一个“深度”,其卷积核是个3D窗口,因此就会造成和多通道2D卷积因深度不同而产生不同参数相对应,从而就有了3D卷积权重共享这种说法。(摘自博主Ton)
Note:
- 3D卷积的PyTorch实现Conv3d:输入图像:
(
N
,
C
,
D
,
H
,
W
)
(N,C,D,H,W)
(N,C,D,H,W),3D卷积核参数:
(
C
,
o
u
t
_
c
h
a
n
n
e
l
s
,
F
D
,
F
H
,
F
W
)
(C,out\_channels, FD, FH, FW)
(C,out_channels,FD,FH,FW),其中
o
u
t
_
c
h
a
n
n
e
l
s
out\_channels
out_channels为输出通道数,
(
F
D
,
F
H
,
F
W
)
(FD,FH,FW)
(FD,FH,FW)为3D滤波器卷积核。例如
nn.Conv3d(3, 16, kernel_size=(3,3,3), stride=1, padding=1)中的
W
W
W参数就是一个size为
(
16
,
3
,
3
,
3
,
3
)
(16, 3, 3, 3, 3)
(16,3,3,3,3)的张量,而
b
b
b参数就是一个
(
16
,
)
(16, )
(16,)的张量,从中可以看出3D卷积核需要
16
×
3
16\times 3
16×3个
3
×
3
×
3
3\times 3\times 3
3×3×3的卷积核。 (所以一共有
C
×
o
u
t
_
c
h
a
n
n
e
l
s
C×out\_channels
C×out_channels个卷积核,记得每层都要拼接)。
经过融合多帧图像特征提取后我们都能得到输出维度为
r
2
r^2
r2大小为
H
×
W
H×W
H×W的feature map。最后一层亚像素卷积层会在输出的
r
2
r^2
r2 张feature map的基础上(即
n
L
−
1
=
r
2
n_{L-1}=r^2
nL−1=r2)进行PixelShuffle,来达到
(
b
a
t
c
h
,
r
2
,
H
,
W
)
→
(
b
a
t
c
h
,
1
,
r
H
,
r
W
)
(batch, r^2, H, W)\to (batch, 1, rH, rW)
(batch,r2,H,W)→(batch,1,rH,rW)的效果,从而完成上采样操作输出
r
H
×
r
W
rH\times rW
rH×rW格式的高分辨率图像。
VESPCN的运动补偿模块直接和后面的SR网络(时序空间网络)相连,并且TSTN和spatio-temporal network都是可以训练的,从而两者可相连形成一个端对端的网络。VESPCN的总体loss由SR网络的loss和运动补偿模块的loss共同组成,整体的训练Loss如下:
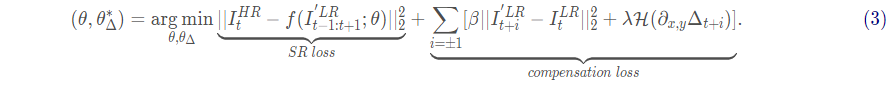
3 Experiments
setting:
论文中的数据集采用CDVL数据集,这是一个包含115个高清(HD)无压缩的视频,作者挑选其中100个视频作为训练集,并对每个视频随机选取30个样本,组成3000个
H
R
−
L
R
HR-LR
HR−LR对;其中150个作为验证集,剩余2850个作为训练集;其余的15个高清视频作为测试集。
卷积核大小都为
k
l
=
(
3
,
3
)
k_l=(3,3)
kl=(3,3)
batch个
33
×
33
33\times 33
33×33的视频输入。
Adam优化方式且学习率为
1
0
−
4
10^{-4}
10−4
batch初始设置为1,每过10个epochs,就翻一倍。
在spatio-temporal network中,当第
l
l
l层的时间深度为1的时候,设置
n
l
=
24
n
n_l=24n
nl=24n;当
l
>
0
l>0
l>0时,
n
l
=
24
/
D
l
n_l=24/D_l
nl=24/Dl。
作者分两个部分进行了对比实验,具体实验可以看超分之VESPCN的讲解
- 针对时序空间网络,都不使用ME。对比了三种融合方式的网络表现力。
- 探究运动补偿模块的功能和对网络的影响。
4 Conclusion
本文提出的VESPCN模型由两方面组成:时序空间网络和运动补偿机制。
- 结合了亚像素卷积和
时间融合策略的效率优势,提出了视频SR的时序空间模型。与独立的单帧处理相比,所使用的时空模型有助于提高重建精度和时间一致性,或降低计算复杂度。 - 通过
基于空间变换网络的运动补偿机制进行了扩展,该机制对于视频SR来说是有效的,并且是可联合训练的。
网络整体结构:对齐网络 + 融合SR网络 :
将多帧相邻图像通过基于STN的运动补偿模块对齐到参考帧,再输入以ESPCN为基础的时序空间网络将时间信息融合提取特征,最后使用亚像素卷积层上采样完成SR重建。融合过程有三种方式:early fusion、slow fusion或者3D卷积。
本文主要学习的模块是:三种融合方式、基于STN的运动补偿。
最主要是学习VSR的结构思想,关键就是怎么利用好时间信息。
最后祝各位科研顺利,身体健康,万事胜意~
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)