http://idning.github.io/ssd-cache.html
http://blog.163.com/zbr_4690/blog/static/126613593200910312346337/
http://blog.chinaunix.net/uid-26575352-id-3159215.html
Tokyo Cabinet简介
Tokyo Cabinet 是日本人 Mikio Hirabayashi开发的一款 DBM 数据库,该数据库读写非常快,哈希模式写入100万条数据只需0.643秒,读取100万条数据只需0.773秒,是 Berkeley DB 等 DBM 的几倍。
Tokyo Cabinet 是一个DBM的实现。这里的数据库由一系列key-value对的记录构成。key和value都可以是任意长度的字节序列,既可以是二进制也可以是字符串。这里没有数据类型和数据表的概念。
当做为Hash表数据库使用时,每个key必须是不同的,因此无法存储两个key相同的值。提供了以下访问方法:提供key,value参数来存储,按key删除记录,按key来读取记录,另外,遍历key也被支持,虽然顺序是任意的不能被保证。这些方法跟Unix标准的DBM,例如GDBM,NDBM等等是相同的,但是比它们的性能要好得多(因此可以替代它们)
当按B+树来存储时,拥用相同key的记录也能被存储。像hash表一样的读取,存储,删除函数也都有提供。记录按照用户提供的比较函数来存储。可以采用顺序或倒序的游标来读取每一条记录。依照这个原理,向前的字符串匹配搜索和整数区间搜索也实现了。另外,B+树的事务也是可用的。
As for database of fixed-length array, records are stored with unique natural numbers. It is impossible to store two or more records with a key overlaps. Moreover, the length of each record is limited by the specified length. Provided operations are the same as ones of hash database.
对于定长的数组,记录按自然数来标记存储。不能存储key相同的两条或更多记录。另外,每条记录的长度受到限 制。读取方法和hash表的一样。
Tokyo Cabinet是用C写的,同时提供c,perl,ruby,java的API。Tokyo Cabinet在提供了POSIX和C99的平台上都可用,它以GNU Lesser Public License协议发布。
Tokyo Tyrant 是由同一作者开发的 Tokyo Cabinet 数据库网络接口。它拥有Memcached兼容协议,也可以通过HTTP协议进行数据交换。
Tokyo Tyrant 加上 Tokyo Cabinet,构成了一款支持高并发的分布式持久存储系统,对任何原有Memcached客户端来讲,可以将Tokyo Tyrant看成是一个Memcached,但是,它的数据是可以持久存储的。
上面是我从网上摘录的部分介绍~~
用Tokyo Tyrant 加上 Tokyo Cabinet,他们支持双向的M/M同步,也支持单向的M/S同步,可以为网站提供非常可靠的持久化的分布式数据高速Cache,没有了Memcached对内存大小的依赖,而且速度还是飞快.
计算一下,按100w每秒的速度,那么每天可以支持最高100w*1440*60 = 8640000w的查询总量.这样的速度对于任何一个网站都是足够用的了.
近期将对Tokyo Tyrant + Tokyo Cabinet的使用做一些测试,结果出来再与大家分享!!
Tokyo Cabinet介绍
Tokyo Cabinet是由一个名叫平林幹雄的日本人开发的一个管理数据库程序库,作者开发了一系列的开源程序。包括:
Tokyo Cabinet
tokyotyrant
QDBM(Quick Database Manager),
Hyper Estraier(a full-text search system for communities),
Estraier(a personal full-text search system)
Diqt:Multilingual Dictionary Searcher等。
现工作于日本的第一大社交网站mixi。
Tokyo Cabinet是一个DBM数据库,在整个数据库中它既没有数据表的概念也没有数据类型的概念,它由一系列的key-value对的记录构成,key和vlaue既可以是二进制数据也可以为字符数据,它们的长度可以是任意长度的字节序列,所有的记录都保存在文件中。所有记录由hash表,b+树或定长的数组组成。
Tokyo Cabinet基于GNU Lesser General Public License协议发布,采用C语言开发,它可以运行在任何支持C99和POSIX平台上使用。
相比一般的DBM数据库有以下几个特点:空间小,效率高,性能高,可靠性高,多种开发语言的支持(现已提供C,Perl,Ruby,Java,Lua的API),支持64位操作系统。
它的官方首页是:http://tokyocabinet.sourceforge.net/index.html
最新版本:tokyocabinet-1.4.14
稍后我将推出他在mixi开发者blog上发表一系列有关于tokyocabinet的文档
PHP操作tokyo Cabinet
Posted: – 上午3:03
上篇我介绍了tokyo Cabinet,这篇我介绍通过php操作tokyo cabinet。需要的工具有php扩展模块Net_Tokyo_Tyrant,Tokyo Tyrant。
首先安装Tokyo Cabinet,安装方法
curl -O http://tokyocabinet.sourceforge.net/tokyocabinet-1.4.16.tar.gz
./configure
make
make install
安装tokyotyrant
curl -O http://tokyocabinet.sourceforge.net/tyrantpkg/tokyotyrant-1.1.23.tar.gz
./configure
make
make install
为php添加Net_Tokyo_Tyrant模块
/usr/local/php/bin/pear channel-discover openpear.org
/usr/local/php/bin/pear install openpear/Net_TokyoTyrant-beta
现为beta版,当有正式版请使用
/usr/local/php/bin/pear install openpear/Net_TokyoTyrant
启动服务
/usr/local/sbin/ttservctl start
说明:启动后的监听的端口为1978
编写php文件
<?php
include_once 'Net/TokyoTyrant.php';
$tt = new Net_TokyoTyrant();
$tt->connect( 'localhost', 1978 );
$tt->put('test', 'PHP connet to Tokyo cabinet');
echo $tt->get('test');
$tt->close();
?>
执行刚刚的php文件,你将看到如下的文字
PHP connet to Tokyo cabinet
以上就完成第一个php对Tokyo cabinet的操作
当在memcache中保存数据时,重启memcache服务,所有的数据全部丢失
当在tokyo cabinet中保存数据时,服务器重启数据不丢失。
下面通过一个例子证明这点
/usr/local/sbin/ttservctl restart
编写php文件
<?php
include_once 'Net/TokyoTyrant.php';
$tt = new Net_TokyoTyrant();
$tt->connect( 'localhost', 1978 );
//$tt->put('test', 'PHP connet to Tokyo cabinet');
echo $tt->get('test');
$tt->close();
?>
执行php脚本,得到的结果还是
PHP connet to Tokyo cabinet
说明它的数据全部保存在磁盘上而不是内存中。
下期将推出,比较memcache与tokyo cabinet的执行效率
php操作Tokyo Cabinet与操作memcache效率比较
先说我的服务器环境,1G内存,双核Xeon 2.00的CPU,服务器采用rpm方式部署apahce,php
Tokyo Cabinet的安装方法及PHP操作Tokyo Cabinet方法请见上篇
在测试之前,先安装一个php模块--Benchmark,安装方法如下
/usr/local/php/bin/pear install Benchmark
下面写一个脚本分别对tokyo cabinet进行一万次插入,一万次查询,一万次更新
一万次删除操作
脚本的内容如下
<?php
include_once( 'Benchmark/Timer.php' );
$timer = new Benchmark_Timer();
include_once( 'Net/TokyoTyrant.php' );
$tt = new Net_TokyoTyrant();
$tt->connect( 'localhost', 1978 );
$timer->start();
for ( $i = 0; $i < 10000; $i++) $tt->put( 'test_'.$i, $i );
$timer->setMarker('TOKYO CABINET - INSERT 10,000 RECOREDS');
for ( $i = 0; $i < 10000; $i++) $tt->get( 'test_'.$i );
$timer->setMarker('TOKYO CABINET - SELECT 10,000 RECOREDS');
for ( $i = 0; $i < 10000; $i++) $tt->put( 'test_'.$i, $i );
$timer->setMarker('TOKYO CABINET - UPDATE 10,000 RECOREDS');
for ( $i = 0; $i < 10000; $i++) $tt->out( 'test_'.$i );
$timer->setMarker('TOKYO CABINET - DELETE 10,000 RECOREDS');
$timer->stop();
$timer->display();
$tt->close();
?>
执行脚本得到的结果如下图
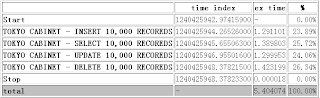
下面对memcache进行测试,为测试方便在同一台机器上执行一下脚步
memcached -d -m 256 -l 127.0.0.1 -p 11211 -u root
以root用户对memcahe分配256M的内存,分配的端口号为11211
下面再写一个脚本分别对memcahe进行一万次插入,一万次查询,一万次更新
一万次删除操作,脚本内容如下:
<?php
include_once( 'Benchmark/Timer.php' );
$timer = new Benchmark_Timer();
$memcache = new Memcache;
$memcache->connect('localhost', 11211);
$timer->start();
for ( $i = 0; $i <10000; $i++ ) $memcache->set( 'test_'.$i, $i );
$timer->setMarker('MEMCACHE - INSERT 10,000 RECOREDS');
for ( $i = 0; $i <10000; $i++ ) $memcache->get( 'test_'.$i );
$timer->setMarker('MEMCACHE - SELECT 10,000 RECOREDS');
for ( $i = 0; $i <10000; $i++ ) $memcache->replace( 'test_'.$i, $i );
$timer->setMarker('MEMCACHE - UPDATE 10,000 RECOREDS');
for ( $i = 0; $i <10000; $i++ ) $memcache->delete( 'test_'.$i );
$timer->setMarker('MEMCACHE - DELETE 10,000 RECOREDS');
$timer->stop();
$timer->display();
$memcache->close();
?>
执行的结果如下:
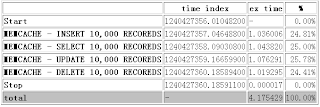
从上面测试的结果来看,tokyo cabinet的速度非常快,比memcahe稍差。
在执行1万次操作所花费的时间在1.2s左右,而memcahe所花的时间比tokyo cabinet快了0.2秒,但是memcache down掉后数据全部丢失,而tokyo cabinet即使重启了,db文件不坏掉,数据就不会丢失。
Tokyo Tyrant备份和还原
Posted: 2009年4月23日 星期四 – 下午10:52
人为的误操作,机器的不可靠性导致数据的丢失,这是会经常发生在我们的身边。为减少数据的丢失,定期的备份可以解决部分数据丢失的可能。
Tokyo Tyrant(以下简称tt)提供备份还原机制实现高可靠性的功能。
只需要简单简单的把数据库文件进行拷贝,就能完成备份功能,具体实现方法见下图
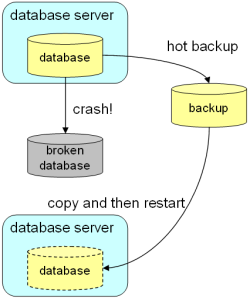
下面通过简单的实例进行测试:
在同一台机器上启动2个终端,在终端A中启动服务
ttserver /tmp/casket.tch
在终端B中插入测试数据
tcrmgr put localhost TTTest TestByZLJ
在终端B中查询刚刚插入的测试数据
tcrmgr get localhost TTTest
在终端B中备份数据库文件
tcrmgr copy localhost /tmp/backup.tch
模拟服务down掉,在终端A中按下ctrl-c键
模拟数据库文件丢失,在终端A中删除数据库文件
rm /tmp/casket.tch
还原数据库文件
cp /tmp/backup.tch /tmp/casket.tch
在终端A中重新启动服务
ttserver /tmp/casket.tch
在终端B中检索数据
tcrmgr get localhost TTTest
最后我们得到的结果还是:TestByZLJ,说明成功的还原了数据
以上只是通过简单的文件复制完成了数据备份与还原,这种方法有它的缺点就是,在上面的文件备份过程中更新的数据有可能就得不到还原。下面将通过另外一个功能解决以上的缺点
在mysql 可以通过binary log的方式恢复数据,oracle也有redo log的方式恢复数据,
tt同样也有通过更新log的方式恢复数据,也就是说,所有对db的更新操作在log中都有操作记录,通过tt自有的log还原数据机制能把数据还原回来。
下面通过简单的实例进行测试:
在同一台机器上启动2个终端,建立一个目录用来保持log
mkdir /tmp/ulog
在终端A中启动服务
ttserver -ulog /tmp/ulog /tmp/casket.tch
在终端B中插入测试数据
tcrmgr put localhost TTTest TestByZLJ
在终端B中查询刚刚插入的测试数据
tcrmgr get localhost TTTest
模拟服务down掉,在终端A中按下ctrl-c键
模拟数据库文件丢失,在终端A中删除数据库文件
rm /tmp/casket.tch
备份更新log文件
mv /tmp/ulog /tmp/ulog-back
在终端A中重新启动服务
ttserver /tmp/casket.tch
通过更新log还原数据
tcrmgr restore localhost /tmp/ulog-back
在终端B中检索数据
tcrmgr get localhost TTTest
最后我们得到的结果还是:TestByZLJ,说明成功的还原了数据。
它有个缺点:每次操作都有log记录,慢慢的文件就会变得越来越大,很容易磁盘用尽,可以通过备份数据库文件和保存部分更新log文件,两者一起解决这个问题,具体做法:定期备份数据文件和更新log,对很老的备份更新log进行删除,当需要还原数据时,先通过还原备份数据库文件,由于在还原数据时写入的数据会写更新log文件,还原后再通过更新log文件
进行还原数据库时写入的数据,就可以完全的还原数据,具体做法看下图
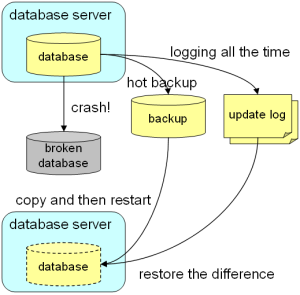
搭建Tokyo Tyrant replication
Posted: 2009年4月24日 星期五 – 上午2:37
篇介绍了Tokyo Tyrant(以下简称tt)的备份和还原,保证了数据完整性,由于它不是实时备份,因而不能保证数据的完整性,当磁盘坏掉了,而这时数据没有备份,因而导致数据的不完整性。
为解决上述问题,大家知道mysql中有个replication机制可以解决数据的完整性,同样tt也有replication机制保证数据的完整性,具体实现方法,数据库服务器把本机的更新log,分批次的实时传输到别的数据库服务器,传输更新log的服务器就是我们常说的主服务器,接收更新log的服务器就是我们常说的辅服务器。replication的好处就是,管理者配置好服务器,
主辅DB服务器自动保持数据的一致性。当主服务器down后,可以把辅服务器变为主服务器
提供服务,而保证不间断服务,同时也使管理员有时间重新为辅服务器添加一个新辅服务器,重新搭建replication。
具体实现方法见下图
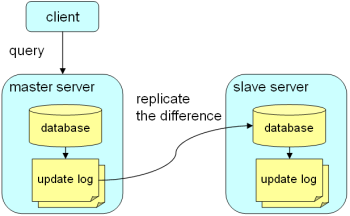
通过上图看到,平时辅服务器几乎不接受请求,因而造成资源浪费,特别在大压力的情况下
主服务器的负荷很重,而辅服务器几乎没有负荷。由于主服务器的数据几乎是同步的,可以采用读写分离的方式,分散服务器的压力。这也是许多高负荷系统对DB采取的一种方式。
具体实现如下图
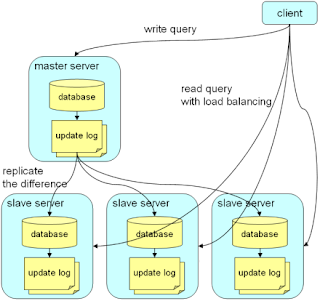
下面通过一个实例来介绍通过tt实现replication
在同一台机器上启动3个终端
在终端A中创建主DB更新log文件夹
mkdir /tmp/ulog-master
在终端A中启动服务
ttserver -port 1978 -ulog /tmp/ulog-master /tmp/casket-master.tch
在终端A中创建辅DB更新log文件夹
mkdir /tmp/ulog-master
在终端B中启动辅DB
ttserver -port 1979 -ulog /tmp/ulog-slave -mhost localhost -mport 1978 -rts /tmp/slave.rts /tmp/casket-slave.tch
在终端C中对主DB插入测试数据
tcrmgr put -port 1978 localhost TTTest TestByZLJ
在终端C中查询主DB
tcrmgr get -port 1978 localhost TTTest
在终端C中查询辅DB
tcrmgr get -port 1979 localhost TTTest
查询主DB跟查询辅DB得到同样的结果‘TTTestByZLJ’,虽然只是对主db进行了数据插入操作
但是查询辅db得到了同样的结果,这样的话就不用担心服务器磁盘坏了没有备份了。
但是replication也不是万能的,它也有它的缺点,主DB与辅DB的之间的传输有数10微秒到数100微秒的延迟,在大并发下,延迟期间,主DB down掉了,有可能在延迟时产生的数据就丢失了。同时主DB down掉以后,它不能自动的切换到辅DB,而需要人工的参与,不能实现自动化运维。
搭建Tokyo Tyrant的故障转移
Posted: 2009年4月27日 星期一 – 上午5:41
以前写了一篇关于tokyo tyrant的replication实现了高可靠性,文中最后说了它的几个缺点,本文中将通过tokyo tyrant更高级的特性,故障转移机制,解决这些问题。本文介绍tokyo tyrant的的故障转移机制,有点像lvs的主从机制。当主DB down掉的时候,自动的把备份DB转为主db,提供服务,而不需要人工的干预。同时采用tokyo tyrant的replication机制,保证数据完整性的同时,还具有遇到故障自动切换主从服务器,实现高可靠性。
下面是一个tokyo tyrant的故障转移的实例,现看实现原理图
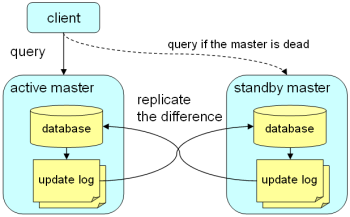
在同一台机器上打开3个窗口。
在终端A中创建主DB更新log文件夹
mkdir /tmp/ulog-a
在终端A中启动服务
ttserver -port 1978 -ulog /tmp/ulog-a -sid 1 -mhost localhost -mport 1979 -rts /tmp/a.rts /tmp/casket-a.tch
在终端B中创建辅DB更新log文件夹
mkdir /tmp/ulog-b
在终端B中启动辅DB
ttserver -port 1979 -ulog /tmp/ulog-b -sid 2 -mhost localhost -mport 1978 -rts /tmp/b.rts /tmp/casket-b.tch
在终端C中对主DB插入测试数据
tcrmgr put -port 1978 localhost TTTest TestByZLJ
在终端C中查询主DB
tcrmgr get -port 1978 localhost TTTest
在终端C中查询辅DB
tcrmgr get -port 1979 localhost TTTest
模拟主DB down掉,在终端A中按下Ctrl+C
在终端C中对辅db进行数据插入操作
tcrmgr put -port 1979 localhost test TTTest
在终端C中对辅DB进行数据检索操作
tcrmgr get -port 1979 localhost test
在终端A中重新启动主DB
ttserver -port 1978 -ulog /tmp/ulog-a -sid 1 -mhost localhost -mport 1979 -rts /tmp/a.rts /tmp/casket-a.tch
在终端C中对主DB进行数据检索
tcrmgr get -port 1978 localhost test
最后查询得到的结果还是TTTest,在对辅DB进行插入操作的时候主DB已经down掉了,而当主DB重新起来后,对主DB再次进行查询得到了我们想要的结果。也就是说主DB重新起来后自动的从辅DB进行数据同步操作,保证数据的完整性,同时也为SA有时间去处理这类故障。





