1 milvus 简介
Milvus 是一款开源的向量相似度搜索引擎,支持针对 TB 级向量的增删改操作和近实时查询,具有高度灵活、稳定可靠以及高速查询等特点。Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型。此外,Milvus 还可以对标量数据进行过滤,进一步提高了召回率,增强了搜索的灵活性。
Milvus 服务器采用主从式架构 (Client-server model)。
在服务端,Milvus 由 Milvus Core 和 Meta Store 两部分组成:
Milvus Core 存储与管理向量和标量数据。
Meta Store 存储与管理 SQLite 和 MySQL 中的元数据,分别用于测试和生产。
在客户端,Milvus 还提供了基于 Python、Java、Go、C++ 的 SDK 和 RESTful API。
Milvus 在 Apache 2 License 协议下发布,于 2019 年 10 月正式开源,是 LF AI 基金会的孵化项目。Milvus 的源代码被托管于 Github。
应用场景
Milvus 在全球范围内已被数百家组织和机构所采用,广泛应用于以下场景:
- 图像、视频、音频等音视频搜索领域
- 文本搜索、推荐和交互式问答系统等文本搜索领域
- 新药搜索、基因筛选等生物医药领域
2 milvus_cpu 部署
前置条件:安装docker,具体可参考笔者博文: docker笔记7–Docker常见操作
2.1 基于sqlite部署milvus
- 下载镜像和配置文件
docker pull milvusdb/milvus:0.11.0-cpu-d101620-4c44c0
mkdir -p /disk0/milvus/conf
mkdir -p /disk0/milvus/db
mkdir -p /disk0/milvus/logs
mkdir -p /disk0/milvus/wal
cd /disk0/milvus/conf
wget https://raw.githubusercontent.com/milvus-io/milvus/0.11.0/core/conf/demo/milvus.yaml
- docker 启动milvusdb 服务
sudo docker run -d --name milvus_cpu_0.11.0 \
-p 19530:19530 \
-p 19121:19121 \
-v /disk0/milvus/db:/var/lib/milvus/db \
-v /disk0/milvus/conf:/var/lib/milvus/conf \
-v /disk0/milvus/logs:/var/lib/milvus/logs \
-v /disk0/milvus/wal:/var/lib/milvus/wal \
milvusdb/milvus:0.11.0-cpu-d101620-4c44c0
Milvus 监听的端口号: 默认19530,一般可用于客户端连接
Milvus HTTP 服务器监听的端口号:默认19121,一般可用于 http或者RESTful api 请求
docker logs milvus_cpu_0.11.0 查看启动日志,发现正常启动: 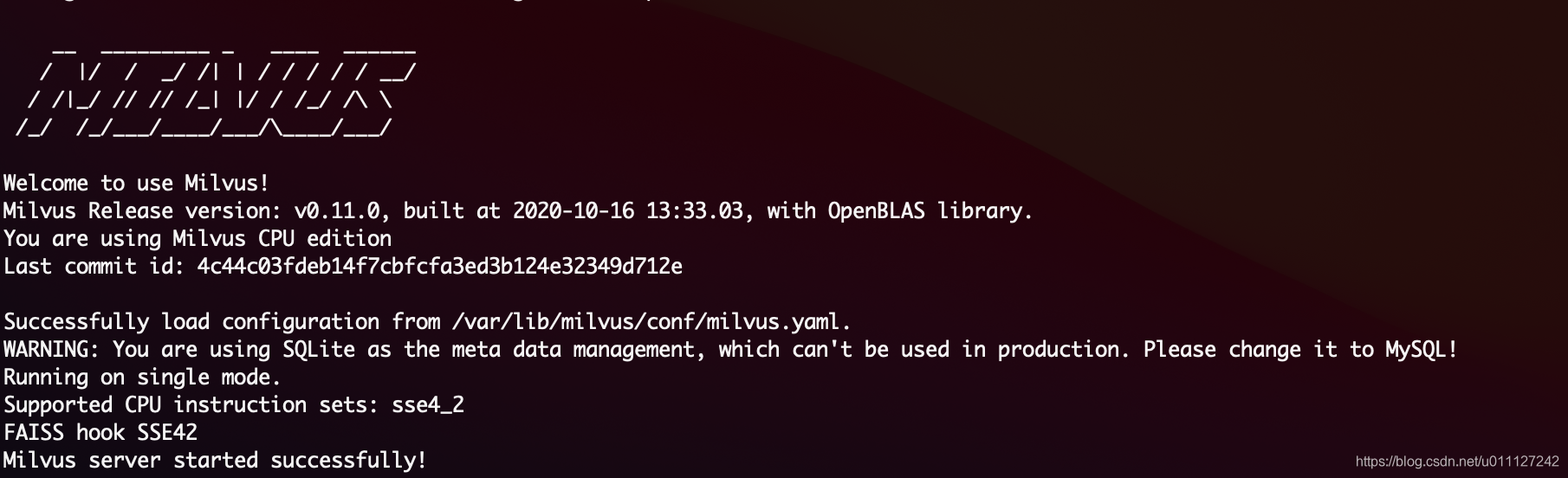
2.2 基于mysql部署milvus
基于mysql的部署方式和上面差异不太大,只是需要更改 meta_uri 为mysql的地址即可, 以下在部署sqlite版本的基础上更新为mysql存储元数据;
mysql 配置方式可以参考笔者博文: docker笔记5–配置MySQL
- 使用 docker 启动mysql
1)初始化MYSQL文件夹
mkdir -p /disk0/mysql
mkdir -p /disk0/mysql/logs
mkdir -p /disk0/mysql/conf
2)创建 mysql
docker run \
--name mysql-5.7 \
-p 3306:3306 \
-v /disk0/mysql/data:/var/lib/mysql \
-v /disk0/mysql/logs:/logs \
-v /disk0/mysql/conf:/etc/mysql \
-e MYSQL_ROOT_PASSWORD=111111 \
-d mysql:5.7
- 更新mysql 配置并重启milvus
1·)创建 milvus 数据库
docker exec -it mysql-5.7 bash
mysql -u root -p
输入密码111111
create database milvus;
退出 mysql
2)更新 milvus.yaml 中 meta_uri 为mysql
docker stop milvus_cpu_0.11.0 先停止milvus
vim /disk0/milvus/conf 修改 milvus.yaml 中的 原始sqlite 为 mysql
# meta_uri: sqlite://:@:/
meta_uri: mysql://root:111111@10.120.75.102:3306/milvus
3)启动milvus
docker stop milvus_cpu_0.11.0
4)此时在mysql冲创建了一系列tables
mysql> use milvus;
Database changed
mysql> show tables;
+------------------+
| Tables_in_milvus |
+------------------+
| Collection |
| CollectionCommit |
| Field |
| FieldCommit |
| FieldElement |
| PartitionCommit |
| Partitions |
| SchemaCommit |
| Segment |
| SegmentCommit |
| SegmentFile |
+------------------+
11 rows in set (0.00 sec)
3 常见命令
注意:若本地下载的是 pymilvus==0.3.0 的pip3包,若拉取 pymilvus git repo 后,需要切换到0.3.0 的版本中,否则执行会报错(不同版本pip包存在不兼容现象);
切换到0.3.0分支,和pip包相对应
git checkout -b origin/0.3.0 remotes/origin/0.3.0
3.1 api 案例
- 安装pip 包
pip3 install pymilvus==0.3.0
- 下载py 测试代码
wget https://raw.githubusercontent.com/milvus-io/pymilvus/0.3.0/examples/example.py
- 运行测试代码
python3 example.py --------get collection info--------
{'auto_id': False,
'fields': [{'indexes': [{}],
'name': 'duration',
'params': {'unit': 'minute'},
'type': <DataType.INT32: 4>},
{'indexes': [{}],
'name': 'release_year',
'params': {},
'type': <DataType.INT32: 4>},
{'indexes': [{}],
'name': 'embedding',
'params': {'dim': 8},
'type': <DataType.FLOAT_VECTOR: 101>}],
'segment_row_limit': 4096}
----------list partitions----------
['American', '_default']
----------insert----------
Films are inserted and the ids are: [1, 2, 3]
----------flush----------
There are 0 films in collection `demo_films` before flush
There are 3 films in collection `demo_films` after flush
----------get collection stats----------
{'data_size': 22268,
'partition_count': 2,
'partitions': [{'data_size': 0,
'id': 1,
'row_count': 0,
'segment_count': 0,
'segments': None,
'tag': '_default'},
{'data_size': 22268,
'id': 2,
'row_count': 3,
'segment_count': 1,
'segments': [{'data_size': 22268,
'files': [{'data_size': 4124,
'field': '_id',
'name': '_raw',
'path': '/C_1/P_2/S_1/F_1'},
......
{'data_size': 4196,
'field': 'embedding',
'name': '_raw',
'path': '/C_1/P_2/S_1/F_3'}],
'id': 1,
'row_count': 3}],
'tag': 'American'}],
'row_count': 3}
----------get entity by id = 1, id = 200----------
> id: 1,
> duration: 208m,
> release_years: 2001,
> embedding: [0.8846436142921448, 0.30038607120513916, 0.1741494983434677, 0.839633047580719, 0.6289502382278442, 0.4159392714500427, 0.4668292999267578, 0.64024418592453]
----------search----------
- id: 3
- distance: 2.251066207885742
- release_year: 2003
- duration: 252
- embedding: [0.22678761184215546, 0.10217451304197311, 0.45235690474510193, 0.8751530051231384, 0.07362151145935059, 0.2575174868106842, 0.002853699494153261, 0.9267576932907104]
----------delete id = 1, id = 2----------
Get 0 entities by id 1, 2
There are 1 entities after delete films with 1, 2
3.2 RESTful api
github RESTful api, 0.11.0/core/src/server/web_impl
api 1:
curl -X GET "http://127.0.0.1:19121/state" -H "accept: application/json"
{"message":"Success","code":0}
api 2:
curl -X GET "http://127.0.0.1:19121/collections?offset=0&page_size=1" -H "accept: application/json"
{"code":0,"data":{"collections":[],"total":0},"message":"OK"
api 3:
curl -X POST "http://127.0.0.1:19121/collections" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"collection_name\":\"test_collection\",\"dimension\":1,\"index_file_size\":10,\"metric_type\":\"L2\"}"
{"message":"OK","code":0}
api 4:
curl -X GET "http://127.0.0.1:19121/collections/test_collection" -H "accept: application/json"|python -m json.tool
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 98 100 98 0 0 49000 0 --:--:-- --:--:-- --:--:-- 49000
{
"data": {
"auto_id": true,
"collection_name": "test_collection",
"count": 0,
"segment_row_limit": 524288
}
}
4 说明
参考文档:
milvus 官网
milvus 安装概述
milvus github
笔者系统为 ubuntu1804 server,Docker version 19.03.14