lxml模块
lxml 库是一款 Python 数据解析库,参考重要文档在 lxml - Processing XML and HTML with Python,项目开源地址在:GitHub - lxml/lxml: The lxml XML toolkit for Python
在Python中,为了使用XPath,需要安装一个第三方库:lxml,使用lxml才能从html通过xpath方法读取内容
import lxml.html
selector=lxml.html.fromstring(html2)
content=selector.xpath('//div[contains(@id,"-key")]/text()')
Xpath语法
xpath的核心思想是写地址
获取文本:

获取属性值

//开始为绝对路径,从需要提取的内容往上找标签,找到一个拥有“标志性属性值”的标签为止。
<div class="userful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="strange">我需要的信息3</li>
</ul>
</div>
如这段内容,//div[@class='useful']/ul/li/text()就能得到三个文本信息。
以相同字符串开头
如果只需要提取某些属性开头的内容,可用如下方法
//标签[starts-with(@属性名,"相同的开头部分")]
html2="""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div id="test1111">需要的内容1</div>
<div id="test2-key">需要的内容2</div>
<div id="asssss">不需要的内容1</div>
</body>
</html>
"""
import lxml.html
selector=lxml.html.fromstring(html2)
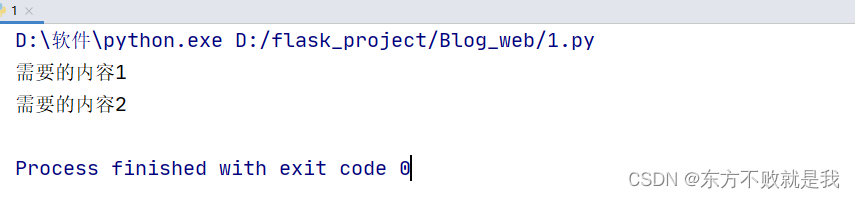
content=selector.xpath('//div[starts-with(@id,"test")]/text()')
for each in content:
print(each)
属性值包含相同字符串
如果提取内容属性值包含相同字符串,可以用contains方法
html2="""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div id="abc -key">需要的内容1</div>
<div id="1234 -key">需要的内容2</div>
<div id="asssss">不需要的内容1</div>
</body>
</html>
"""
import lxml.html
selector=lxml.html.fromstring(html2)
content=selector.xpath('//div[contains(@id,"-key")]/text()')
for each in content:
print(each)

对XPath返回的对象执行XPath
XPath也支持先抓大再抓小
html2="""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div class="userful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="strange">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>
"""
import lxml.html
selector=lxml.html.fromstring(html2)
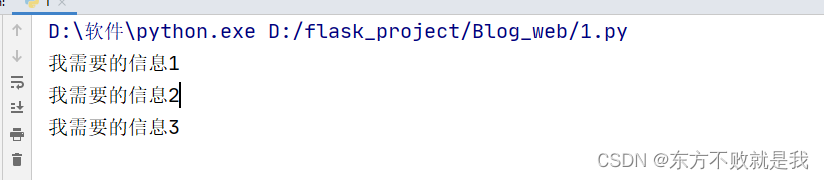
content=selector.xpath('//div[@class="userful"]/ul/li/text()')
for each in content:
print(each)
也可以:
html2="""
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>测试</title>
</head>
<body>
<div class="userful">
<ul>
<li class="info">我需要的信息1</li>
<li class="test">我需要的信息2</li>
<li class="strange">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>
"""
import lxml.html
selector=lxml.html.fromstring(html2)
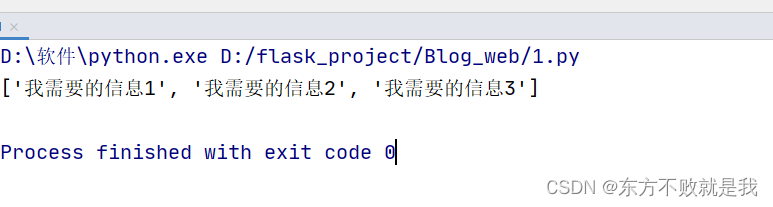
useful=selector.xpath('//div[@class="userful"]')#这里返回一个列表
infolist=useful[0].xpath('ul/li/text()')
print(infolist)
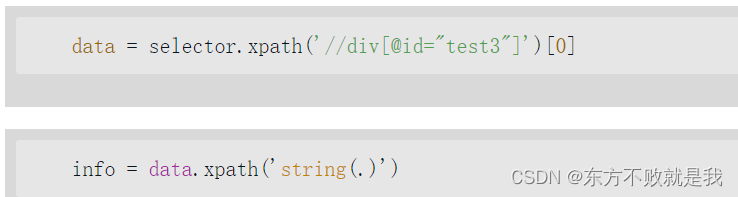
同时提取子标签文字
先获取节点,再对节点使用xpath,用string(.)函数提取。