转载:https://www.zhihu.com/question/20829671/answer/205421638
第一阶段,基于User-Video图游历算法,2008年[1]。
在这个阶段,YouTube认为应该给用户推荐曾经观看过视频的同类视频,或者说拥有同一标签的视频。然而此时,YouTube的视频已是数千万量级,拥有标签的部分却非常小,所以如何有效的扩大视频标签,被其认为是推荐的核心问题。解决方案的核心有两块,一是基于用户共同观看记录构建的图结构(Video Co-View Graph); 二是基于此数据结构的算法,被称为吸附算法(Adsorption Algorithm)。
图1.User-Video Graph
视频的共同观看关系构建的图,可以从两个角度观察,一是视频构成的图,一是视频-用户构成的图,“视频”图可以看成由“视频用户”图(图1)抽取出。而视频之间的边,可以是同时观看过两个视频的用户个数,或者是在同一个Session中被同时观看的次数,甚至可以将顺序也考虑于其中。
那么到底如何给视频扩大标签呢?标签可以看成是一个分类,所谓“近朱者赤,近墨者黑”,在图结构中,一个节点的信息与属性可以通过其周围的节点得到。“标签”也不例外。Adsorption Algorithm的核心思想是,部分节点将拥有一些标签,每一次迭代,可以将标签传递给相邻的节点,如此不停迭代,直到标签稳定分布在节点中。伪代码如下:

其中V为节点集合,E为边集合,W为节点与边之间的权重,L为标签集合,VL为V中拥有标签的节点,每一个视频都对应一个标签的分布概率Lv。每一轮迭代,将重新为所有节点计算标签分布。节点对应的标签分布由其连接的相邻节点关系强度,以及标签在相邻节点的分布概率乘积后累加得到。
本算法与PageRank接近,也类似马尔可夫链的游走过程,由于每个节点中Label权重来自于周围节点对应权重的线性组合,也与线性系统近似。另外,论文并未花篇幅陈述如何利用本算法进行推荐备选生成,只说可以将经过迭代稳定后的图结构中用户的标签作为备选(生成的依据),或者说是连接备选视频的纽带。同样的,也并没有花篇幅论文如何进行最终排序,以及如何归并多种备选结果,虽然在这个阶段的YouTube的推荐体系已经具备了这个模块。
笔者认为,本算法可以划为“用户画像”推荐方法类别。以标签为视频以及用户的描述,通过某种方式挖掘用户与视频的标签信息,作为相互连接的纽带。YouTube对比了本方法与热门结果以及简单的协同,均取得了完胜。其试验方法也较为初步:采用完全离线的方式进行效果评价,无法对新用户进行评测,也无法对新产生内容的价值进行衡量;另外对于视频来讲,以点击作为衡量标准也是不够的,播放时长是必须要考量的因素。
第二阶段,基于Video-Video图游历算法,2010年[2]。
在这个阶段,YouTube认为需要将用户观看过的视频的相似视频推荐给用户。而什么是相似视频?主要以用户行为对其进行界定,可以是:
1. 被一定量用户共同观看的视频;
2. 在同一个Session中经常被同时观看的视频;
3. 考虑顺序信息的,在同一个Session中经常被同时观看的视频。
如上这几种选择,信息的有效性逐渐更好,但数据则逐渐稀疏,YouTube更加偏好第二种方式。相似视频的形式化定义如下:
其中Cij为所有被共同观看的次数,而F(vi,vj)是一个规整化函数,试图消歧视频的流行度,因为Vi跟Vj中一旦存在比较Popular的结果Cij往往会偏大,一种简单的方案是将两个视频被观看的次数相乘。

初步的推荐备选结果即是用户消费过视频的相似视频。如上公式,S是用户消费的视频集合,Vi为S中的某一个视频,Ri则是Vi对应的相似视频集。最终的备选集合C,则是所有Ri的并集。一般而言这种方式生成的结果作为备选的量充足的,但往往内容聚焦难以为用户找到新视频,也有备选结果不充足的情况。在这种情况下,相似视频集合可以继续扩展,从“相似视频”扩展到“相似视频的相似视频”,以此类推迭代一定的次数,得到最终的备选集合。
备选生成后是排序阶段,主要考量两类因素。一是视频的质量,包含视频的播放数量,评分等;二是用户的需求信息,包含用户观看历史中的一些信息,例如视频观看数量,以及观看时间等;用一个线性公式可以对这两类因素进行综合考量(此处并未提及线性公式如何而来,应该不会是拍脑袋吧—_—#)。最终只能呈现比较小数量的备选结果,所以只能从中挑选部分数据,而这个过程,则需要处理多样性问题:将标签类似的数据进行去除,或者将属于同一个频道的数据去掉,进一步的基于聚类与内容分析的方法也可以采用。
文章也陈述了具体系统实现方案。因为每个用户的备选结果在一定时间内可以完全保持不变,所以选用了离线计算的方式。但这样做将导致实效性不佳,所以YouTube优化了数据生成的环节,做到了每天数次数据更新。其系统架构主要分为数据收集,备选生成,推荐服务三个部分。用户日志被抽取后,存储入BigTable中,然后基于MapReduce生成备选,最终得到的生成结果存储入提供线上服务的BigTable服务器。推荐服务不涉及太多实时计算,延迟时间更多的是网络传输。
为了确认本方法的有效性,YouTube选择了在线A/B测试的方法,主要指标包括CTR,Long CTR(观看超过一定时长的有效点击),Session的平均观看时间,第一次观看时间,以及推荐的覆盖率。
第三阶段,基于搜索以及协同过滤,2014年[3]。
本文陈述了“相关视频”的优化方法,即用户在观看某一个视频时推荐的视频。但实质上是定义了一种相似或者相关视频的计算方式。而“相似对象”的定义是推荐的核心问题,有了不同的计算方法,也意味着有了新的推荐方法。
为什么要有一个新的“相关视频”计算方法呢?协同过滤是当时最好的方法,但其适用于有了一定用户观看记录的视频,但对于新视频以及长尾视频,并不能良好应用。

图2.视频主题描述示意图
我们来看看YouTube是怎么做的。首先,视频通过<主题,权重>集合进行描述。如上图,《World War Z》电影包含了四个主题以及对应权重。主题名从视频的描述信息,上传者定义的关键词,被搜索后的观看记录对应的检索词,播单名字等等抽取而来。
第二步,计算视频与视频之间的相似度。主要通过两个主题集合进行计算得到。文章主要提出了两个方法,第一个方法借鉴传统信息检索排序理论,将视频VW与VR 的相似度定义为:
其中,c(t, V) 表示视频V与包含主题t的视频集合被“共同观看”的次数,也就意味着t与V之间的接近程度。而df(t)则是t出现的文档频率,log(1 + df(t))用来对流行度太高的主题进行惩罚,与著名的IDF类似。Ts(t)是一个阀门,如果t出现在文档中的次数超过阀值,则本值为0,也就是不考虑此t的影响,反之为1,将其纳入考虑。q(VR) 则代表视频VR的质量,通过上传时间,上传者,点赞与差评的数量进行构建。
第二种方法,主要思想是试图借助用户行为优化主题词的权重。文中以《World War Z》电影为例,其中“World War Z”Topic的权重最高,高于Topic“惊悚片”。但是,基于“World War Z”主题出来的结果,可能将过度的拟合本电影,导致出的结果更多的是本电影相关的内容。但实际上同一类电影可能更好。也就是说“惊悚片”在这个场景下比“World War Z”主题更有用。
主题权重训练算法借鉴PairWise排序方法。基本思想如下,被推荐的视频分为两类,一类被用户点击与观看,一类并未被点击与观看。在排序时,将后者放在了前者的前面,则生成了一个错误的排序对,对应着一条训练数据X。而X的长度为主题个数,当某一个主题出现在这个Pair对应的两条视频上,则对应的值为0,如果只出现在被消费过的视频上,则为1,如果只出现在没有被消费的视频上,则为-1。被优化的参数W,则是X的对应系数,即主题的权重,优化的目标是在训练集合上错误最小,并加入正则化:
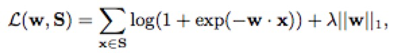

实验阶段,YouTube主要采用在线实验的方式验证效果优劣。指标包括观看时长,观看完成率(度量有多少视频被从头到位看完),以及丢弃率,即没有任何相关视频被观看的比例(在这种情况下,用户行为终止)。从这三个指标来看,本文的方法与协同过滤联合后,效果有明显提升,并且,基于主题权重重新训练的方法要好于借鉴搜索理论的人工拟合排序公式方法。
值得一提的是,本文提出的相似度的计算方式与基于用户行为的方式(例如协同过滤)有着根本不同,对用户行为的依赖更小,适用于新数据以及长尾数据,可以极大的克制马太效应。同时,本文也提供了成熟的实现方案:基于搜索底层进行备选生成。通过正在被观看的视频主题信息构建检索句,到倒排索引中进行查询。再者,也提到通过再排序模块,与协同过滤方法的备选集合进行融合,将更进一步提升效果:
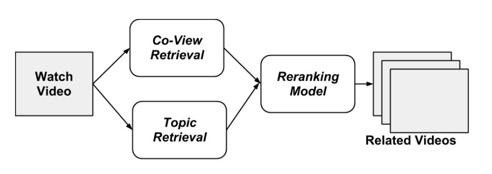
图3.相关视频系统架构图
第四阶段,基于深度神经网络,2016年[4]。
YouTube转用深度学习做推荐系统,也许有跟风的意味,希望跟随谷歌“using deep
learning as a general-purpose solution for nearly all learning problems”也就是将深度学习作为几乎所有机器学习问题通用解决方案。所幸这样的方法是成功的,带来了推荐系统的“Dramatic Improvement”。
本文陈述了YouTube推荐系统的三大难点:一是规模太大,简单的推荐算法在如此大规模数据量上可能是失效的;二是实效性,即新数据不断产生,需要将其良好的呈现给用户,以平衡旧有的好内容以及新内容;三是噪音问题,用户行为与视频描述均有噪音,并且只能获得充满噪音的用户隐含反馈,而不能直接获取用户满意度。
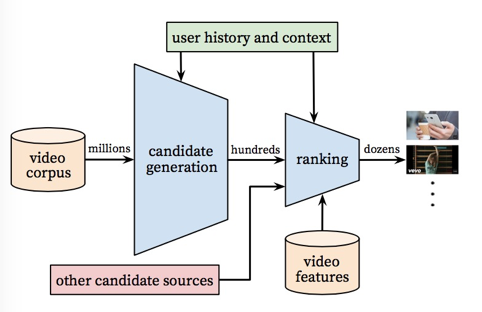
图4.YouTube基于深度学习推荐系统架构图
本文呈现的推荐系统解决方案分为两个部分,一个是备选生成(Candidate Generation),其目标是初选结果,从海量数据中选择出符合其个人需求偏好的百级别数据。一个则是排序(Ranking),通过更加丰富的用户,视频乃至场景信息,对结果进行精细化排序,得到呈现给用户的备选。
在本文中,推荐系统的建模方式有了实质性不同,即将推荐系统定义为一个多分类器,其职责是确定某个用户,在某个场景与时间下,将从系统的视频中选择消费哪一个视频。具体的方法是,将用户与视频全部转化为Embedding描述,即一个向量,最终用户消费某个视频的概率通过如下方式计算得到:
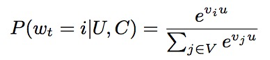
首先获取视频的Embedding描述,将视频的文本放入Embedding工具即可(例如Word2Vec,但TensorFlow自带)即可。构建用户的Embedding,则是通过训练而来。以SoftMax分类为最终优化对象,将用户观看视频的Embedding整合值,搜索记录,其它信息如年龄性别等作为特征。中间为数层ReLU。能利用除了用户行为外的其它信息,也是神经网络相对于普通MF类算法的优势。
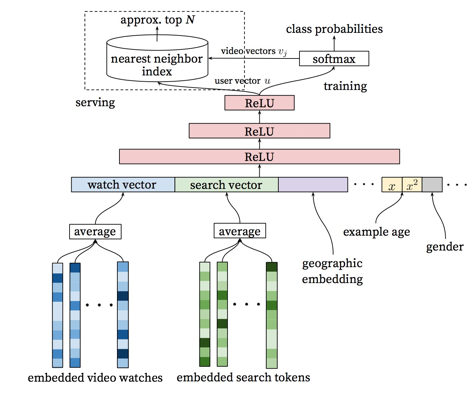
图5.YouTube推荐备选生成阶段架构
对于YouTube产品层来讲,鼓励内容产生毫无疑问是至关重要的,所以推荐系统也希望对用户上传的新内容的有所偏好。然而幸运的是,即使损失一部分相关性,视频的消费者也偏好新内容。也就是说,新内容的价值可以良好的通过其带来的吸引力呈现出来,并不需要平台刻意而为之。本文讲到了机器学习系统对于处理这实效性特征所犯的惯常的错误,由于训练行为往往发生在行为之后,但视频信息在这个阶段中并非保持不变,尤其是实效性信息,所以应该将数据的上传时间在动作发生时候的瞬时值作为训练特征。这样的处理方式偏好了新内容,并明显的提升了效果。
YouTube选择用户观看记录作为训练数据的初始来源,即完成观看视频记录为正样本。主要原因是用户观看记录相对于用户的显性行为例如点赞收藏要多得多。还有一些非常有参考价值的推荐系统实现方案,例如需要对于推荐系统保留一些信息输入,以防止过渡拟合“代理问题”(即推荐系统所优化的具体指标,例如点击率),例如用户往往会顺着一个检索结果页或者用户发布者浏览页进行顺序观看,然而将检索结果页面或者用户发布视频界面直接作为推荐结果呈现给用户是非常不好的。所以此处,YouTube做了一些处理规避这个问题,例如选择放弃检索句的序列信息,并其打散成词袋。另外,YouTube发现,用户进行视频阅读往往是有序的,例如用户会按照剧集的顺序进行观看,而用户进行信息发现的过程往往也由流行到自己的喜好。于是,去预估用户的下一个观看记录,比预估用户的观看记录中中间的某一个更好,这一点也有别于传统的协同过滤。
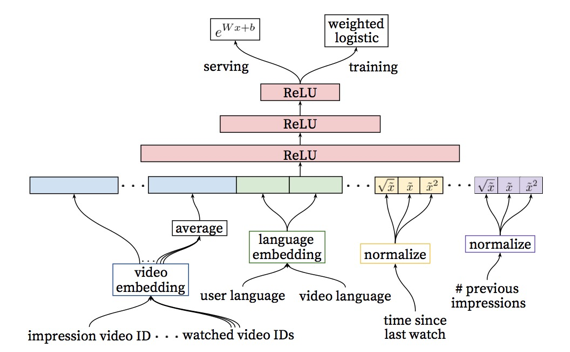
图6.YouTube推荐排序阶段架构
备选生成的下一个阶段是排序,排序模块更多的是面向“场景”的,说的简单一点,就是界面。用户可能在某一地方愿意点击某一条数据,但是在别的地方则不会愿意,可能在某一时间愿意点击某一条数据,但在另一个时间不会。用户观看了一个推荐界面,但是并未在这个界面上进行操作,那么随之应该进行对应内容的降级,所以对上一个推荐界面的浏览信息也可以进入到本模型中。排序的另一个职能是将各种备选联合起来。此处,需要纳入到模型中的信息更多,例如,用户最近的一次搜索词,用户最近观看的同一个主题下的视频数量,用户上一次观看同主题视频的时间,用户所使用的语言等。其架构跟备选生成阶段类似,将所有排序模型中的信息输入后,进入多层ReLU,最终进行优化的是一个加权逻辑回归层,阳性样本的权重是其观看时间。在这一层,也可以看到其推荐“代理问题”的转化,由点击行为转为了点击与观看行为结合。
总结
总体上讲,YouTube的推荐系统在采用深度学习之前,多数基于用户画像(说的高大上一丢丢其实就是标签)与协同过滤。第一篇本质是基于图的画像挖掘算法,第二篇则是对协同数据的深度利用,即不仅仅将“相似视频”作为备选,也将“相似视频的相似视频”同样纳入备选集合。第三篇,则对用户画像法进一步深化,提出了用户画像法经典的基于搜索架构的实现方式,以及如何通过用户行为进一步克服文本画像所带来的相关性计算偏差。这三篇在不同的地方也提到过,给用户进行结果呈现之前,还需要做最终排序,但是这并未被深入论述。最终,采用深度网络方法,在之前扎实工作基础上,进一步升华。